- Ubuntu 58
- GNU/Linux 45
- Software 33
- debian 32
- linux 14
- programming 12
- Recursos 10
- Scripts 10
- Anuncios 9
- General 9
- Python 9
- Local 8
- Programación 8
- Perl 7
- Seguridad 7
- elixir 7
- software+libre 7
- CSS 6
- Charlas 6
- django 6
- Noticias 5
- WordPress 5
- planet 5
- trac 5
- (X)HTML 4
- Distribuciones 4
- GIMP 4
- Universidad 4
- javascript 4
- miniblog 4
- subversion 4
- ula 4
- Ingeniería del Software 3
- Internet 3
- Literatura 3
- Ocio 3
- campaign 3
- dapper 3
- planetalinux 3
- security 3
- wireless 3
- apache 2
- bittorrent 2
- blogging 2
- bug 2
- cnti 2
- cpan 2
- feedjack 2
- gnome 2
- gnu 2
- java 2
- jquery 2
- layout 2
- pylint 2
- tips 2
- xmms 2
- Duke 1
- Enlightenment 1
- Humor 1
- Kubuntu 1
- Opinión 1
- Personal 1
- akismet 1
- alsa 1
- amigas 1
- apt-get 1
- audioconverter 1
- azureus 1
- bad-behavior 1
- beamer 1
- beryl 1
- blog 1
- bluefish 1
- books 1
- browser 1
- canaima 1
- charla 1
- chile 1
- cms 1
- cntlm 1
- conac 1
- conocimiento+libre 1
- cowbell 1
- cracklib 1
- csv 1
- cultura 1
- dbconfig-common 1
- debconf 1
- dell 1
- design 1
- dictionary 1
- dijkstra 1
- documental 1
- drake 1
- edubuntu 1
- emerald 1
- entities 1
- etch 1
- fedora 1
- feed 1
- femfox 1
- find 1
- firefox 1
- flickr 1
- flisol 1
- foro 1
- framework 1
- freeloader 1
- gedit 1
- glamour 1
- gnickr 1
- gnupg 1
- goobuntu 1
- google 1
- google+evil 1
- graph 1
- graphviz 1
- grub 1
- grunt 1
- gulmer 1
- hardware 1
- html 1
- hwinfo 1
- icons 1
- ifdown 1
- ifup 1
- inkscape 1
- instalinux 1
- intel 1
- ipw3945 1
- iso 1
- iwl3945 1
- jigdo 1
- jsdoc 1
- k2 1
- kernel 1
- latex 1
- lenovo 1
- logitech 1
- lug 1
- m1210 1
- magazine 1
- marketing 1
- merida 1
- mkpasswd 1
- mongodb 1
- mp3 1
- mp3splt 1
- mp3wrap 1
- mplayer 1
- music 1
- nautilus 1
- ndiswrapper 1
- network-manager 1
- nvidia 1
- pam 1
- pbuilder 1
- perl 1
- postgresql 1
- presentaciones 1
- proxy 1
- python 1
- root 1
- rss 1
- rufus 1
- scm 1
- scripting 1
- solve 1
- spam 1
- spam-karma 1
- stardict 1
- suse 1
- sysadmin 1
- tecnologia 1
- tecnologia+libre 1
- testing 1
- transmission 1
- trucos 1
- turpial 1
- ubuntuchannel 1
- ulanix 1
- utw 1
- velug 1
- venezuela 1
- video 1
- vim 1
- vlc 1
Ubuntu
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
StarDict: El diccionario que buscaba
Leyendo el ejemplar #14 de la revista Tux Magazine me encuentro con un interesante artículo, Learning Foreign Languages with jVLT and StarDict, la segunda aplicación descrita en dicho artículo, StartDict, llamó mi atención, así que a continuación se dará una breve revisión de la aplicación en cuestión.
¿Qué es StarDict?
StarDict es un diccionario internacional multiplataforma escrito en Gtk2, puede ser utilizado sin conexión a la web.
Características
-
Búsqueda de patrones: Usted puede buscar patrones de cadenas o caracteres usando comodines, por ejemplo, podrá usar el comodín
*para buscar una cadena arbitraria, el resultado puede ser vacío, mientras que con el uso del comodín?buscará una coincidencia con un carácter arbitrario. e.g. Suponiendo que tiene instalado el diccionario Inglés – Español, al buscar el patrón hell? encontrará como resultado la traducción de hello, mientras que con el uso del patrón hell* encontrará todas aquellas posibles coincidencias que comiencen con la cadena hell, hell (infierno en inglés), hell (suerte en noruego), los resultados encontrados dependerá de los diccionarios que haya instalado. - Búsqueda difusa: Si usted por casualidad no recuerda exactamente como deletrear una palabra, podrá intentar realizar dicha búsqueda desde StarDict, éste utilizará el algoritmo de la Distancia de Levenshtein El algoritmo de la Distancia de Levenshtein o la distancia de edición entre dos cadenas, se refiere al número mínimo de operaciones necesarias para transformar una cadena en otra, bajo éste algoritmo se considera una operación a la inserción, eliminación o substitución de un carácter. Para mayor información le recomiendo leer el artículo Levenshtein Distance, in Three Flavors.. Para utilizar esta característica simplemente comience la búsqueda con el carácter /, e.g., suponga que tiene instalado el diccionario Español – Inglés, usted cree que la palabra acero realmente se escribe así: asero, simplemente introduzca en el formulario la cadena /asero, obtendrá el resultado deseado.
-
Búsqueda por palabras seleccionadas:
 Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada.
Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada. -
Manejo de diccionarios:
 StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen).
StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen). - ¿No encuentra lo que necesita?: StarDict le permite realizar búsquedas en la web, solo deberá seleccionar el botón de búsqueda en Internet y escoger cualquiera de las 10 opciones actuales de búsqueda.
{kind=link}
Ahora bien, seguramente esta aplicación resultará útil para muchas personas, si usted es uno de ellos y está interesado en instalarlo, es muy sencillo.
¿Cómo instalar StarDict?
Si usted es tan afortunado como yo, debe estar usando Debian, así que simplemente tendrá que hacer:
# aptitude install stardict
Ahora bien, si usted utiliza por ejemplo, Ubuntu, también puede instalarlo fácilmente, ¿cómo?, en primer lugar debe activar el repositorio universe (recuerde actualizar la lista de paquetes disponibles), posteriormente debe hacer:
$ sudo aptitude install stardict
Si usted utiliza otra distribución de GNU+Linux o es usuario de Windows, lea la documentación de la página oficial del proyecto, lamento informarle que este artículo es una revisión breve de la aplicación StarDict.
¿Cómo instalar diccionarios?
Primero que nada, debe descargar los diccionarios que necesite, para ello le recomiendo ir a la página de Descarga de Diccionarios del proyecto.
Una vez que haya descargado los diccionarios, debe proceder como sigue:
tar -C /usr/share/stardict/dic -x -v -j -f \\
diccionario.tar.bz2
Personalizando la aplicación
 Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Una característica de StarDict que puede resultar realmente molesta es cuando se encuentra activo el modo Scan, es decir, toda palabra o frase resaltada con el ratón generará un cuadro de dialogo con la definición de dicha palabra o frase, si usted desea controlar este comportamiento, le recomiendo activar las siguientes casillas de verificación:
- Only do scanning while modifier key being pressed.
- Hide floating window when modifier key pressed.
Las casillas de verificación previamente mencionadas podrá encontrarlas bajo la sección Dictionary -> Scan Selection.
Si usted esta inconforme con las opciones de búsqueda en Internet, puede agregar las que usted desea desde la sección Main Window -> Search Website.
Actualizado Planeta #ubuntu-es
El hecho de haber dejado de utilizar ubuntu, como lo he manifestado en entradas anteriores, no implica que deba dejar de lado a los amigos del canal #ubuntu-es en el servidor Freenode, además, tampoco debo dejar de cumplir mis deberes de administrador del Planeta #ubuntu-es, por ello, he realizado los siguientes cambios:
- Se actualiza WordPress a su versión 2.0.2.
- Se actualiza el plugin FeedWordPress, basicamente este plugin es un agregador de contenidos Atom/RSS.
- Ahora el dominio principal del Planeta #ubuntu-es es http://www.ubuntuchannel.org/, aunque se han establecido reglas de redirección en el fichero .htaccess para hacer el cambio lo menos traumático posible.
Aún faltan muchos detalles, en este preciso instante no puedo resolverlos debido a un viaje que debo realizar fuera del estado dentro de una hora, el lunes cuando regrese a casa continuare la labor, mientras tanto, le agradezco que si percibe algún error en el nuevo sitio o tiene alguna sugerencia en particular, por favor deje un comentario en esta entrada.
Para quienes deseen suscribirse al Planeta #ubuntu-es, el URI del feed ha cambiado a http://www.ubuntuchannel.org/feed/. Para aquellas personas que estaban suscritas, este cambio no debería afectarles, puesto que se han establecido reglas de redirección.
Si deseas ser miembro, por favor envia un mensaje a través de la sección de contacto del Planeta #ubuntu-es.
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Ubuntu Dapper Drake Flight 6
Flight 6, es la última versión alpha disponible de Ubuntu Dapper Drake, esta versión ha sido probada razonablemente, pero recuerde que a pesar de ello todavía es una versión alpha, así que no se recomienda su uso en medios en producción. Esta versión puede descargarla desde:
- Europa:
- Reino unido y el resto del mundo:
- Bittorent: Se recomienda su uso si es posible.
- Sitios Espejos: Una lista de sitios espejos puede encontrarse en: Ubuntu Mirror System.
Una lista con los cambios notables en esta sexta versión alpha pueden ser encontrados en Dapper Flight 6.
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
Libro oficial de Ubuntu
La primera edición del libro The Official Ubuntu Book estará lista para el día 4 de Agosto de este mismo año y contará con 320 páginas; la información anterior puede encontrarse en la preventa del libro realizada en Amazon.
Los autores del libro The Official Ubuntu Book son los siguientes:
- Benjamin Mako Hill: Autor del famoso libro Debian GNU/Linux 3.x Bible, desarrollador debian/ubuntu.
- Jono Bacon: Co-autor del libro Linux Desktop Hacks, publicado por O’Reilly, entre otras cosas, Jono colabora con el proyecto KDE.
- Corey Burger: Administrador del proyecto Ubuntu Documentation Project.
- Otros autores: Entre ellos se encuentran Ivan Krstic y Jonathan Jesse.
Este libro tendrá una licencia Creative Commons.
nVIDIA en Ubuntu 6.04
Hace unos días actualicé mi Ubuntu 5.10 a una de sus últimas versiones de testing: Flight 5. Debo admitir que quedé anonadado por lo cambios en la distribución, ya que con todas las mejoras que tiene parece que hubiera pasado, no sólo 6 meses sino años. El Dapper Drake (Flight 5, Ubuntu 6.04) es mucho mejor que sus antecesores. Pero la razón por la cual me decidí a escribir éste artículo es otra: la instalación de los drivers de mi tarjeta nVIDIA y su puesta en funcionamiento a punto.
Cuando actualicé mi sistema no hubo ningún problema, y lo digo en serio, ningún problema de ninguna índole. Toda mi configuración de escritorio quedó intacta; pero empecé a notar que la configuración de la tarjeta de video no se cargaba con el sistema. Entonces supe que, por alguna razón, los drivers de la tarjeta habían cambiado, es decir, el sistema asignó el driver por defecto para la tarjeta, más no los drivers de la tarjeta misma. Entonces tuve que ponerme a configurar la tarjeta.
Lo primero que hice fué verificar que los drivers vinieran con la distribución. Lo hice con la siguiente línea:
$ sudo aptitude search nvidia
Con lo cual obtuve lo siguiente:
i nvidia-glx - NVIDIA binary XFree86 4.x/X.Org driver
v nvidia-kernel-1.0.7174 -
v nvidia-kernel-1.0.8178 -
i nvidia-kernel-common - NVIDIA binary kernel module common files
Entonces ya sabía que los drivers venían con la distro, lo cual me pareció fascinante, ya que en realidad el Flight 5, no es la versión definitiva del Dapper Drake. Luego procedí a verificar la documentación de dicho paquete. Ésto lo hice con la siguiente línea de comandos:
$ sudo aptitude show nvidia-glx
Esto lo hice para verificar que no haya alguna clase de conflictos con otros paquetes, pero en realidad no es un paso necesario, ya que aptitude resuelve todo tipo de conflictos y dependencias. Después de verificar que todo estaba en orden me decidí a instalar los drivers. Ésto lo hice con la siguiente linea de comandos:
$ sudo aptitude install nvidia-glx
Con lo cual quedaron instalados los drivers de la tarjeta de manera trasparente y rápida. Lo siguiente que debía hacer, era activar la configuración de la tarjeta. Lo cual hice con la siguiente línea de comandos:
$ sudo nvidia-glx-config enable
Una vez hecho ésto ya podía configurar la tarjeta. Algo que hay que hacer notar es que, para las distribuciones anteriores de Ubuntu, había que instalar de manera separada el paquete nvidia-glx y el nvidia-settings, sin embargo, aquí queda todo instalado de una vez. Lo que sigue es iniciar la configuración de la tarjeta, lo cual hice con la siguiente línea de comandos:
$ nvidia-settings
Y ya tenía acceso a la configuración de mi tarjeta. Sin embargo, al hacer todo ésto, la configuración no se carga al iniciar el sistema, pero no fué problema, porque lo solucioné colocando en los programas de inicio del gnome-session-manager los siguiente:
nvidia-settings -l
Este comando carga la configuración de nvidia-settings que tengamos actualmente. Es lo mismo que, una vez que haya cargado el sistema, ejecutemos en la consola éste comando, sólo que ahora se va a ejecutar apenas inicie el sistema operativo.
Otros ajustes…
Si quieren colocar un lanzador en los menús del panel de gnome deben hacer los siguiente:
$ sudo gedit /usr/share/applications/NVIDIA-Settings.desktop
Y luego insertar lo siguiente en dicho fichero:
[Desktop Entry]
Name=Configuración nVIDIA
Comment=Abre la configuración de nVIDIA
Exec=nvidia-settings
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya tendrán un lanzador en los menús del panel de gnome. Una opción sería utilizar el editor de menús Alacarte.
nvidia-xconf
nvidia-xconf es una utilidad diseñada para hacer fácil la edición de la configuración de X. Para ejecutarlo simplemente debemos escribir en nuestra consola lo siguiente:
$ sudo nvidia-xconfig
Pero en realidad, ¿qué hace nvidia-xconfig? nvidia-xconfig, encontrará el fichero de configuración de X y lo modificará para usar el driver nVIDIA X. Cada vez que se necesite reconfigurar el servidor X se puede ejecutar desde la terminal. Algo interesante es que cada vez que modifiquemos el fichero de configuración de X con nvidia-xconfig, éste hará una copia de respaldo del fichero y nos mostrará el nombre de dicha copia. Algo muy parecido a lo que sucede cada vez que hacemos:
dpkg-reconfigure xserver-xorg
Una opción muy útil de nvidia-xconfig es que podemos añadir resoluciones al fichero de configuración de X simplemente haciendo:
$ sudo nvidia-xconfig --mode=1280x1024
…por ejemplo.
Vulnerabilidad grave corregida en ubuntu
La vulnerabilidad en ubuntu donde cualquiera con acceso al shell podía ver la contraseña del instalador del sistema ha sido reparada.
Los paquetes afectados son base-config y passwd en Ubuntu 5.10 (Breezy Badger), el problema puede ser corregido al actualizar los paquetes afectados a las versiones 2.67ubuntu20 (base-config) y 1:4.0.3-37ubuntu8 (passwd). En general, una actualización del sistema es suficiente para que los cambios surtan efecto.
La vulnerabilidad en donde era posible ver la constraseña del instalador de ubuntu y así tener acceso a privilegios de superusuario (por supuesto, si la contraseña no había sido cambiada desde la instalación) fue descubierta por Karl Øie, el instalador de Ubuntu 5.10 falla en la limpieza de contraseñas en los ficheros de registros de instalación. Dichos ficheros pueden ser leidos por cualquiera, de este modo cualquier usuario local pudiese ver las contraseñas del primer usuario, el cual tiene privilegios por completo en una instalación por defecto.
El paquete actualizado eliminará las contraseñas almacenadas en texto plano en los ficheros de registro de instalación y adicionalmente hará que los registros sean leídos únicamente por el superusuario.
Esta vulnerabilidad no afecta a los instaladores de las versiones 4.10, 5.04, o la que está por llegar, 6.04. Sin embargo, considere necesario aplicar el parche si usted ha actualizado su sistema desde Ubuntu 5.10 a la actual versión en desarrollo 6.04 (Dapper Drake), en este caso verifique que ha actualizado el paquete passwd a la versión 1:4.0.13-7ubuntu2.
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
 Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
Vulnerabilidad en el kernel Linux de ubuntu
Este problema de seguridad únicamente afecta a la distribución Ubuntu 5.10, Breezy Badger.
Los paquetes afectados son los siguientes:
linux-image-2.6.12-10-386linux-image-2.6.12-10-686linux-image-2.6.12-10-686-smplinux-image-2.6.12-10-amd64-genericlinux-image-2.6.12-10-amd64-k8linux-image-2.6.12-10-amd64-k8-smplinux-image-2.6.12-10-amd64-xeonlinux-image-2.6.12-10-iseries-smplinux-image-2.6.12-10-itaniumlinux-image-2.6.12-10-itanium-smplinux-image-2.6.12-10-k7linux-image-2.6.12-10-k7-smplinux-image-2.6.12-10-mckinleylinux-image-2.6.12-10-mckinley-smplinux-image-2.6.12-10-powerpclinux-image-2.6.12-10-powerpc-smplinux-image-2.6.12-10-powerpc64-smplinux-patch-ubuntu-2.6.12
El problema puede ser solucionado al actualizar los paquetes afectados a la versión 2.6.12-10.28. Posterior al proceso de actualización debe reiniciar el sistema para que los cambios logren surtir efecto.
Puede encontrar mayor detalle acerca de esta información en el anuncio Linux kernel vulnerability hecho por Martin Pitt a la lista de correos de avisos de seguridad en Ubuntu.
Goobuntu, Google y los rumores…
Todo comenzo el día martes de esta misma semana, al ser publicado el artículo Google at work on desktop Linux en The Register, para mí todo aquello tenía la esencia de un nuevo rumor acerca Google, no en el sentido de utilizar una adaptación, denominada Goobuntu, de Ubuntu para las personas que laboran dentro de Google, sino en el hecho que el artículo enfatizaba la posibilidad de distribuir al público en general la adaptación de Ubuntu hecha por Google.
En el artículo mencionado al comienzo del párrafo anterior nos encontramos con afirmaciones tales como las siguientes:
Google is preparing its own distribution of Linux for the desktop, in a possible bid to take on Microsoft in its core business - desktop software.
Un poco más tarde nos encontramos con esto.
But it’s possible Google plans to distribute it to the general public, as a free alternative to Windows.
La posible distribución de “Goobuntu” al público fue desmentida pocas horas después de publicada la noticia, el responsable de proyectos open source de Google, Chris DiBona, lo aclara en este comentario hecho en Slashdot [Vía], en donde afirma lo siguiente:
Goobuntu is our internal desktop distribution. It’s awesome, but we’re not going to be releasing it. Unless you work here it wouldn’t work anyway.
Una de las cosas que me impresionó de todo esto, fué lo rápido que se extendió esta noticia. Estaba por todos lados, en los blogs que comúnmente leo, en Technorati, bajo el tag ubuntu, solo se hablaba de ello. Más y más sitios se unían rápidamente a este grupo.
Me da la impresión que cada vez que termina un rumor acerca del probable Google OS o Google Browser comienza uno nuevo, ¿esto acabará algún día?, ¿es sano adorar tanto a Google?, acaso Google es tan cool que le hace olvidar a las personas los malos productos que ha sacado últimamente, pareciese que sí.
Siguiendo con el tema, llegados a este punto, ¿alguien recuerda el lanzamiento de Google Analytics?, este servicio de estadísticas gratis para sitios web desde el mismo día de su lanzamiento no dejó de dar problemas, fué un total desastre, ¿era muy difícil prever que este servicio iba a tener una demanda excesiva?, no lo creo, su rendimiento daba lastima, los servidores estaban saturados, páginas en mantenimiento después del lanzamiento, ¿acaso Google estaba jugando con nosotros?.
Supongo que Google ha olvidado esa parte de la mercadotecnia en donde se logra satisfacer las necesidades y requisitos de los consumidores, al fin y al cabo es una empresa que intenta responder a una economía de mercado, pero lo está haciendo mal.
Google ha demostrado su interes en el escritorio, aplicaciones como Google Desktop Search, Google Talk, Google Earth, Google Pack dan fé de ello. No puedo dar mi opinión acerca de estas últimas aplicaciones, puesto que no los he probado al ser solo para sistemas Windows, pero con los antecedentes que se está ganando últimamente Google, pareciese que no hace falta probarlos para sacar una conclusión de ellos. Sebastian Delmont puede aclarar un poco esta situación en el artículo El paquete de Google decepciona.
mp3wrap: Concatenando ficheros mp3
mp3wrap es una utilidad en línea de comando que nos permite fusionar o concatenar dos o más ficheros mp3, todo esto sin perder los nombres de ficheros y la información de los ID3, estándar que permite la inclusión de metadatos en contenedores multimedia. También es posible añadir otros ficheros que no sean mp3, como por ejemplo, listas de reproducción, ficheros de información, imágenes de portada. Claro, este proceso es posible revertirlo gracias a mp3splt, el cual describiré en un próximo artículo.
Con mp3wrap, usted puede fácilmente fusionar hasta un máximo de 255 ficheros en uno solo, lo cual pareciese ser suficiente para la mayoría. De igual manera, como se mencionó previamente, usted puede añadir ficheros que no sean mp3, pero hay algunas consideraciones al respecto.
- Si el fichero es de texto, como pueden ser las listas de reproducción, los ficheros de información, entre otros, se recomienda que estos se ubiquen al principio del fichero a generar, puesto que el reproductor los descartará rápidamente.
- Si el fichero es binario, como las imágenes por ejemplo, usted debe colocarlas al final del fichero a generar, de esta manera el reproductor se los encontrará después de reproducir y no los confundirá con ficheros
mp3.
Instalación del programa
Para poder instalar esta aplicación en Ubuntu, en primer lugar debemos tener activo en nuestro fichero /etc/apt/sources.list el repositorio universe, después de haber verificado esto procedemos a instalarlo.
$ sudo aptitude install mp3wrap
A continuación explicaré el uso de mp3wrap a través de un ejemplo.
En primer lugar, mostraré la lista de ficheros a fusionar.
$ ls
01.mp3 02.mp3 03.mp3 04.mp3
Ahora fusionaré las 2 primeras canciones.
$ mp3wrap album.mp3 01.mp3 02.mp3
He obviado el mensaje que nos muestra mp3wrap para evitar extender más de lo necesario este artículo. También es importante acotar que el fichero generado no se llamará album.mp3 (lo que pareciese lógico), sino album_MP3WRAP.mp3, es recomendable no borrar la cadena MP3WRAP, ésta le indicará al programa mp3splt, el cual nos permite separar de nuevo los ficheros fusionados, que dicho fichero fué fusionado utilizando mp3wrap, lo anterior nos facilitará su extracción con mp3splt, en caso de darse.
Ahora bien, voy a añadir las otras dos canciones, que conste que este paso lo hago solamente para demostrar como añadir otros ficheros a una compilación previamente hecha con mp3wrap.
$ mp3wrap -a album_MP3WRAP.mp3 03.mp3 04.mp3
Si deseamos conocer cuales son los archivos que contiene el fichero generado por mp3wrap, simplemente debemos hacer lo siguiente.
mp3wrap -l album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
01.mp3
02.mp3
03.mp3
04.mp3
Si en la instrucción anterior hubiesemos hecho uso de la opción -v (verbose), mp3wrap nos mostraría información adicional acerca de los ficheros. Por ejemplo:
mp3wrap -lv album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
# Size Name
--- -------- --------
1) 6724962 01.mp3
2) 9225205 02.mp3
--- -------- --------
15950240 2 files
Pueden observar en el ejemplo anterior que se nos muestra el tamaño en bytes de cada uno de los ficheros, así como el número total de ficheros que han sido fusionados y su tamaño correspondiente en bytes.
Como se ha podido ver a través del articulo el uso de mp3wrap es bastante sencillo, si tiene alguna duda acerca de su uso consulte el manual de mp3wrap, man mp3wrap, o la sección de preguntas mas frecuentes acerca de mp3wrap.
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
Cowbell: Organiza tu música
Cowbell, es una aplicación que te permite organizar tus compilaciones musicales de una manera fácil y divertida, ya no tienes que aburrirte por horas al intentar organizar tus colección musical manualmente.
Una de las cosas que me han agradado de este programa es que aparte de poder editar las etiquetas manualmentede en una interfaz bastante agradable y sencilla, también puedes obtener toda la información necesaria a través de Amazon Web Services, lo anterior incluye: Número, Título, Año, Estilo, Portada y demás información relacionada con las canciones. Al utilizar este servicio cuentas con una amplia bases de datos, lo anterior en realidad permite ahorrar mucho tiempo.
Dentro de las preferencias de este programa nos encontraremos con opciones que nos permitirán renombrar ficheros de acuerdo a un patrón, el cual lo podemos generar al combinar cualquiera de las siguientes palabras claves.
- Artist
- Album
- Title
- Track
- Genre
- Year
Las palabras claves anteriores se explican por sí solas. Simplemente escoge el patrón que más se ajuste a tus necesidades. Entre otras de las características de este programa, cabe mencionar la posibilidad de generar un fichero de lista de reproducción del álbum.
¿Tienes una larga colección de música cuyas etiquetas debes arreglar?, no te preocupes, Cowbell también puedes usar desde la línea de comandos, la manera de invocar el comando es la siguiente:
$ cowbell --batch /ruta/a/tu/musica
Donde evidentemente debes modificar el directorio /ruta/a/tu/musica de acuerdo a tus necesidades.
Para instalar esta aplicación en ubuntu debes tener activo el repositorio universe en tu fichero /etc/apt/sources.list. Una vez actualizada la lista de repositorios, puedes instalar Cowbell de la siguiente manera:
$ sudo aptitude cowbell
Integridad del CD de Ubuntu
Recientemente un amigo (de ahora en adelante lo llamaré pepito) al que le regalé un par de CD’s de Ubuntu, me preguntó después de unos días lo siguiente: Milton, ¿cómo puedo verificar la integridad del CD de instalación de Ubuntu?.
En primer lugar, estaba muy contento porque pepito deseaba en realidad migrar a GNU/Linux. Pero la idea de este artículo no es hablarles de pepito, sino describir lo más detalladamente posible la respuesta que le dí.
Aprovechar las opciones que nos brinda el CD de instalación
El mismo CD de instalación de ubuntu nos brinda una opción que nos permite verificar la integridad del disco, para ello debemos realizar lo siguiente:
- Colocar el CD de instalación de Ubuntu en la unidad de CD-ROM correspondiente, seguidamente proceder a reiniciar, recuerde que en la configuración de la BIOS debe tener como primera opción de arranque la unidad de CD-ROM que corresponda en su caso.
- Al terminar la carga del CD usted podrá apreciar un mensaje de bienvenida similar al siguiente:
The default installation is suitable for most desktop or laptops systems. Press F1 for help and advanced installation options.
To install only the base system, type “server” then ENTER. For the default installation, press ENTER.
boot:_
Lo anterior, traducido a nuestro idioma sería similar a:
La instalación por defecto es conveniente para la mayoría de los sistemas de escritorio o portátiles. Presione F1 para ayuda y opciones de instalación avanzadas.
Para instalar solo el sistema base, escriba “server” luego ENTER. Para la instalación por defecto, presione ENTER.
- Para este artículo, se realizará el modo de instalación por defecto, lo anterior quiere decir que solamente debemos presionar la tecla ENTER, enseguida observaremos la carga del kernel.
- Desde el cuadro de dialogo Choose Language, primero en aparecer, presionaremos la tecla Tab y seguidamente debemos seleccionar la opción Go back
- El paso anterior nos llevará al menú principal de la instalación de Ubuntu (Ubuntu installer main menu), una vez ubicados acá, simplemente debemos seleccionar la opción Check the CD-ROM(s) Integrity.
- Al finalizar el paso anterior nos llevará a un cuadro de dialogo de confirmación, pero antes podremos notar una pequeña advertencia:
Warning: this check depends on your hardware and may take some time.
Check CD-ROM integrity?
Lo anterior, traducido a nuestro idioma sería similar a:
Advertencia: Esta revisión depende de su hardware y puede tomar cierto tiempo.
Revisar la integridad del CD-ROM?
A la pregunta anterior respondemos Sí
- Si lo prefiere, salga de su casa, tome un poco de sol y regrese ;)
- Si el CD-ROM no tiene fallo alguno, podrá observar un mensaje al final de la revisión similar al siguiente:
Integrity test successful the CD-ROM. Integrity test was successful.
The CD-ROM is valid
Si la revisión de la integridad del CD-ROM es satisfactoría, puede continuar con el proceso de instalación.
Suerte y bienvenido al mundo GNU/Linux ;)
Ubuntu (Dapper Drake) Flight 3
La tercera versión alpha de Ubuntu 6.04 (Dapper Drake), continúa mostrando mejoras e incluye nuevo software.
Las mejoras incluyen una actualización en el tema, el cual desde la segunda versión alpha es manejado por gfxboot.

Ademas se incluye X Window System versión X11R7, GNOME 2.13.4, también se observan mejoras y simplificación de los menús, algunas nuevas aplicaciones como XChat-GNOME, un LiveCD más rápido y que permite almacenar nuestras configuraciones.
También se notan algunas mejoras estéticas en el cuadro de dialógo de cierre de sesión.

En cuanto a la mejora y simplificación de los menús, la idea básicamente es obviar aquellas opciones que pueden llegar a ser confusas para los usuarios, también se evita la duplicación de opciones, esto permite que exista un solo punto para acceder a cada función del sistema, mejorando de esta manera la usabilidad en nuestro escritorio favorito.
Se ha creado un nuevo dialógo que indica cuando es necesario reiniciar el sistema, esto sucede cuando se realizan importantes actualizaciones al sistema, en donde es recomendable reiniciar el sistema para que dichas actualizaciones surtan efecto.

¿Qué mejoras incluye la versión LiveCD?
Quién haya usado alguna vez en su vida un LiveCD puede haberse percatado que éstos presentan ciertos problemas, uno de ellos es la lentitud en el tiempo de carga del sistema, en este sentido se han realizado algunas mejoras en el cargador utilizado en el arranque, el tiempo de carga se ha reducido aproximadamente de unos 368 segundos a 231 segundos, esta mejora es bastante buena, aunque se espera mejorar aún mas este tiempo de carga del LiveCD.
Otro de los problemas encontrados en los LiveCD, es que el manejo de los datos no es persistente, esta nueva versión incluye una mejora que permite recordar las configuraciones, esto quiere decir que la siguiente vez que usted utilice el LiveCD dichas configuraciones serán recordadas. Esto es posible ya que el LiveCD permite guardar sus cambios en un dispositivo externo (al CD) como por ejemplo un llavero usb. Por lo tanto, si usted especifica el parámetro persistent cuando usted esta iniciando el LiveCD, éste buscará el dispositivo externo que mantiene las configuraciones que usted ha almacenado. Si desea conocer más acerca de esta nueva funcionalidad en el LiveCD vea el documento LiveCDPersistence.
Si usted desea descargar esta tercera versión alpha de Ubuntu 6.04, puede hacerlo en Ubuntu (Dapper Drake) Flight CD 3.
Mayor detalle acerca de las nuevas características que presenta esta nueva versión en el documento DapperFlight3.
Nota: Esta versión no es recomendable instalarla en entornos de producción, la versión estable de Dapper Drake se espera para Abril de este mismo año.
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
Vulnerabilidad en Apache
Según un anuncio hecho el día de hoy por Adam Conrad a la lista de seguridad de ubuntu existe una vulnerabilidad que podría permitirle a una página web maligna (o un correo electrónico maligno en HTML) utilizar técnicas de Cross Site Scripting en Apache. Esta vulnerabilidad afecta a las versiones: Ubuntu 4.10 (Warty Warthog), Ubuntu 5.04 (Hoary Hedgehog) y Ubuntu 5.10 (Breezy Badger).
De manera adicional, Hartmut Keil descubre una vulnerabilidad en el módulo SSL (mod_ssl), que permitiría realizar una denegación de servicio (DoS), lo cual pone en riesgo la integridad del servidor. Esta última vulnerabilidad solo afecta a apache2, siempre y cuando esté usando la implementación “worker” (apache2-mpm-worker).
Los paquetes afectados son los siguientes:
apache-commonapache2-commonapache2-mpm-worker
Los problemas mencionados previamente pueden ser corregidos al actualizar los paquetes mencionados.
Vulnerabilidad en Perl
Las siguientes versiones se encuentran afectadas ante este fallo de seguridad:
- Ubuntu 4.10 (Warty Warthog)
- Ubuntu 5.04 (Hoary Hedgehog)
- Ubuntu 5.10 (Breezy Badger)
En particular, los siguientes paquetes se encuentran afectados:
libperl5.8perl-base
El problema puede ser corregido actualizando los paquetes a sus últimas versiones en las respectivas versiones de Ubuntu. En general, el modo estándar de actualizar la distribución será mas que suficiente.
$ sudo aptitude dist-upgrade
La actualización pretende solucionar una vulnerabilidad del interprete Perl, el cual no era capaz de manejar todos los posibles casos de una entrada malformada que podría permitir la ejecución de código arbitrario, así que es recomendable actualizar su sistema de inmediato.
Sin embargo, es importante hacer notar que esta vulnerabilidad puede ser aprovechada en aquellos programas inseguros escritos en Perl que utilizan variables con valores definidos por el usuario en cadenas de caracteres y en donde no se realiza una verificación de dichos valores.
Si desea mayor detalle, le recomiendo leer el anuncio hecho por Martin Pitt en [USN-222-1] Perl vulnerability.
edubuntu es adaptable al ambiente familiar?
Es importante hacer notar que el objetivo primordial de edubuntu es ofrecer una alternativa para el ambiente escolar (puede ser igualmente usable por los niños en casa), ofreciendo dos modos de instalación (servidor y estación de trabajo), el primero de los modos de instalación es ideal para ambientes escolares donde existen laboratorios, se provee LTSP (Linux Terminal Server Project), el cual permite que otros ordenadores (los cuales fungen como clientes) se conecten al servidor y utilicen los recursos de éste para ejecutar sus aplicaciones de escritorio.
Lo anterior resulta muy interesante porque permite mantener todas las aplicaciones en un solo lugar (el servidor), cualquier actualización que se haga ocurrirá únicamente en éste. Por lo tanto, cada vez que un cliente inicie sesión, automáticamente estará ejecutando un sistema actualizado.
La aclaración anterior viene dada por el artículo Review: Is Edubuntu truly the operating system for families?, redactado por Jay Allen, en donde el autor hace una revisión de uno de los sabores de ubuntu, edubuntu, pensando que éste estaba orientado exclusivamente a los niños de la casa.
El autor intenta dar su punto de vista como un padre de familia con pocos conocimientos de informática y no como el desarrollador de software que ha sido por 12 años.
| Muchos de los lectores seguramente sabrán que los sabores orientados a los usuarios de casa son: Ubuntu, Kubuntu y quizás Xubuntu, pero no le podemos decir a un padre de familia que tiene pocos conocimientos en el área lo suguiente: Instala (X | K)ubuntu y seguidamente procede a instalar el paquete edubuntu-desktop. Esta opción quedará descartada en el siguiente artículo ya que desde el punto de un padre con pocos conocimientos en informática pero que esté preocupado por la educación de sus hijos preferirá tener el sistema que el realmente desea en un instante, en vez de tener que instalar ciertos paquetes para obtener lo que él en realidad necesita. |
Edubuntu brinda un sistema operativo lleno de paquetes educacionales, juegos, herramientas de publicación, edición gráfica y más. Todo lo descrito previamente de manera gratuita (sin cargo alguno y comprometido con los principios del Software Libre y el Código de Fuente Abierta), se realiza un gran trabajo para ofrecer una excelente infraestructura de accesibilidad, incluso para aquellos usuarios que no están acostumbrados al manejo de ordenadores, dentro de esa infraestructura de accesibilidad se considera el lenguaje, edubuntu brinda un sistema operativo que se adapta a cualquier usuario sin importar su lenguaje.
Edubuntu puede ser la respuesta a aquellas familias con pocos recursos económicos, en donde el tener acceso a un ordenador de altas prestaciones es un lujo, o en aquellos casos donde se tenga que pagar altas sumas de dinero anualmente por mantener un sistema operativo ineficiente y lleno de problemas.
Edubuntu le brindaría a estos niños (y familias) todo el poder y flexibilidad que ofrecen los sistemas *nix, todos estos beneficios a muy bajos costos.
He considerado importante esta revisión hecha por Jay Allen acerca de edubuntu, porque no es difícil imaginar que esos millones (espero) de niños que utilizan edubuntu en sus escuelas por horas, también quisieran tener ese sistema operativo tan agradable en sus casas.
Según la opinion del autor de la revisión, Jay Allen, después de experimentar con edubuntu por un día con sus hijos Neve, Jaxon, Veda de 8, 6 y 4 años respectivamente, afirma que edubuntu aún no está totalmente listo para aquellas familias con pocos conocimientos en el campo de la tecnología, pero con las características que ofrece hasta ahora es capaz de mantener satisfechos tanto a adultos como niños.
Puntos a favor para edubuntu
- Edubuntu es ideal para ordenadores de bajos recursos, por ejemplo, el autor de la revisión instaló edubuntu en una máquina con procesador Celeron a 550 MHz, 17 GB de disco duro, 4 GB en un disco duro secundario y con 192 MB de RAM.
- Respecto al punto anterior, edubuntu es capaz de brindar una mejor experiencia para los niños en un ordenador de bajos recursos que tenga instalado por ejemplo Windows 98.
- Una vez instalado edubuntu, éste ofrece una interfaz sencilla, usable y muy rápida.
- El sistema viene precargado con una serie de características muy amenas para los niños. De igual manera, se ofrecen características muy atractivas para los adultos de la casa, entre las que se encuentran, una suite ofimática realmente completa, herramientas para la manipulación de imágenes, visualización de películas y videos.
- Mozilla Firefox es incluido por defecto en la instalación, así que si está acostumbrado a él en otros ambientes, la transición no será traumática.
- Algunos de sus niños ni siquiera se dará cuenta del cambio, tal es el caso de Veda, el menor de los hijos de Jay Allen, ni siquiera se percató que su padre secretamente reemplazó Windows XP por edubuntu.
- Al pasar las semanas y sus hijos se hayan acostumbrado al sistema, puede mostrarle características más avanzadas de edubuntu sin mucha dificultad, es más, seguramente ellos ya las sepan, recuerde que los niños son muy curiosos.
Puntos en contra para edubuntu
- ¿Cuántos padres o madres en realidad entenderán lo que significan cada uno de los modos de instalación que ofrece edubuntu?, sobretodo si éstos optan por el modo de instalación por defecto, el cual es modo servidor (server), cuando en realidad deben elegir el modo de estación de trabajo (workstation).
- Muchos de los mensajes que muestra el asistente para la instalación contienen un lenguaje técnico, lo cual no es ideal en aquellos padres o madres con pocos o nulos conocimientos al respecto.
- El asistente de instalación ofrece la creación de una única cuenta, la cual puede en cualquier instante tener permisos administrativos a través del comando
sudo(acerca de ello explico un poco en el artículo ¿Es necesario activar la cuenta root en Ubuntu?), esto puede ser terrible en esos casos donde los padres o madres posean pocos o nulos conocimientos respecto a la creación de usuarios desde la cuenta predeterminada, permisos administrativos, entre otras cuestiones. Según la opinión de Jay Allen, preferiría alguna de las siguientes opciones, que el mismo asistente le dé la oportunidad de crear otra cuenta con permisos limitados o que pueda crear una cuenta para cada uno de sus hijos. - Otro punto en contra es el uso de nombre un tanto crípticos en la suite de educación KDE, incluso, la hija de Jay Allen, Neve (8 años de edad), se preguntaba en voz alta el por qué de la existencia del prefijo K en los nombres de las aplicaciones de la suite, para ella simplemente no tenía sentido. En este caso, lo más lógico sería colocar nombres más explicativos en las aplicaciones. Por lo tanto, no tendría que ser necesario abrir una aplicación solamente para saber de que trata o que soluciones puede brindarle.
- Otro punto en contra es el hecho que el programa Mozilla Firefox no traiga por defecto una sección que permita de cierta manera controlar la navegación de sus hijos, para evitar que estos últimos vean contenido explícito para adultos. Respecto a este punto en particular no es responsabilidad de edubuntu como tal, debido a que el nombre Firefox es una marca registrada (esto puede ser conveniente para el control de calidad de la aplicación como tal), a pesar que el proyecto de la Fundación Mozilla es código abierto, no se pueden realizar cambios a la aplicación original y distribuirla bajo el mismo nombre. Por lo tanto, los desarrolladores de edubuntu deben elegir entre dejar de usar el reconocido nombre Firefox, o no incluir ninguna extensión útil. Más adelante se darán detalles acerca de como solucionar este problema.
Propuestas
De la revisón hecha por Jay Allen, han salido algunas propuestas, entre ellas, una de las que me llamó la atención fué la de distribuir de manera separada los dos modos de instalación de edubuntu, lo anterior sería ideal en esos casos (que deben ser cientos) donde el padre (o madre) no posea muchos conocimientos acerca del tema, éste no sabrá que opción elegir, cuando él (o ella) ni siquiera sabe lo que significa instalación en modo servidor o modo estación de trabajo. También podría considerarse cambiar el modo de instalación por defecto, en vez de ser servidor, cambiarlo por estación de trabajo.
Otra propuesta interesante es la necesidad de proporcionar tutoriales interactivos que de alguna manera introduzcan a los niños de diversas edades en las características, capacidades y beneficios que les proporciona el sistema que manejan.
Si edubuntu no quiere prescindir del conocido nombre Firefox, debe facilitar después de la instalación una guía que indique los pasos necesarios para establecer el control de la navegación de los niños. Sería ideal colocar una guía para instalar dicha extensión o plugin en la página inicial de Firefox, o proporcionar un acceso directo a esta guía de “Primeros Pasos” desde el escritorio de la cuenta predeterminada.
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
Videos educacionales de ubuntu
Chris Del Checcolo y Ricky Hussmann, estudiantes miembros de la ACM en la WVU, han hecho públicos un par de videos educacionales (algo graciosos, no puedo negarlo) en los que explican como instalar software en Ubuntu Linux, ya sea haciendo uso del Gestor de paquetes Synaptic o desde las fuentes. De manera adicional explican como puede convivir Ubuntu Linux con un sistema Windows previamente instalado haciendo uso de Dual Boot.
- Ubuntu Linux / Windows Dual Boot Instructional Video (inglés).
- Installing Software on Ubuntu Linux (inglés).
Vía: The Fridge.
Reproducir de manera automática los CDs o DVDs con XMMS y VLC
Si desea reproducir automáticamente los CDs de audio (o DVDs) al ser insertados con XMMS (o con VLC) simplemente cumpla los siguientes pasos:
En primer lugar diríjase a Sistema -> Preferencias -> Unidades y soportes extraíbles, desde la lengüeta Multimedia proceda de la siguiente manera:
Si desea reproducir automáticamente un CD de sonido al insertarlo:
- Marque la casilla de verificación Reproducir CD de sonido al insertarlo
- En la sección de comando escriba lo siguiente:
xmms -p /media/cdrom0
Si desea reproducir automáticamente un DVD de vídeo al insertarlo
- Marque la casilla de verificación Reproducir DVD de vídeo al insertarlo
- En la sección de comando escriba lo siguiente:
wxvlc dvd:///dev/dvd
Nota: En XMMS puede ser necesario configurar el plugin de entrada de audio que se refiere al Reproductor de CD de audio (libcdaudio.so), puede configurarlo desde las preferencias del programa.
Cómo cambiar entre versiones de JAVA bajo Breezy
Si usted tiene instaladas múltiples versiones de JAVA bajo Breezy, puede cambiar fácilmente entre dichas versiones cuando usted lo desee.
Simplemente debe hacer uso del comando update-alternatives --config java y luego podrá escoger su versión de java preferida.
$ sudo update-alternatives --config java
There are 3 alternatives which provide `java'.
Selection Alternative
-----------------------------------------------
1 /usr/bin/gij-wrapper-4.0
+ 2 /usr/lib/jvm/java-gcj/bin/java
* 3 /usr/lib/j2re1.5-sun/bin/java
Press enter to keep the default[*], or type selection number:
Si usted es amante de las soluciones gráficas, no se preocupe, existe una alternativa, con galternatives podrá elegir qué programa le prestará un servicio en particular, para instalar galternatives debe teclear el siguiente comando:
$ sudo aptitude install galternatives
Para ejecutarlo debe hacer lo siguiente:
$ sudo galternatives
Su interfaz de uso es muy sencilla, si desea cambiar la versión de JAVA que desea utilizar simplemente escoga java en la sección de alternativas, seguidamente seleccione la versión que más crea conveniente en la sección de opciones
Restaurando la vieja barra de localización en nautilus
Si usted al igual que yo no le gusta la nueva manera en que se presenta la barra de localización en nautilus bajo Breezy, en donde se emplean las barras de rutas, es posible regresar a la vieja configuración (tal cual como en Hoary) en donde se especificaba de manera textual la ruta actual en la barra de localización.
Si ud. quiere cambiar este comportamiento, es tan sencillo como dirijirse a /apps/nautilus/preferences/ y proceder a marcar la casilla de verificación always_use_location_entry.
Lo anterior lo puede hacer desde el Editor de configuración, el cual lo puede encontrar en Aplicaciones -> Herramientas del Sistema.
Ctrl + Alt + Supr en Ubuntu
Si usted alguna vez llegó a preguntarse como lograr abrir el Monitor del Sistema al presionar las teclas Ctrl + Alt + Supr, comportamiento similar bajo sistemas Windows, en el Blog de Bairsairk responden dicha inquietud.
Simplemente debe utilizar los siguientes comandos bajo el Terminal.
$ gconftool-2 -t str --set /apps/metacity/global_keybindings/run_command_9 "<Control><alt>Delete"
$ gconftool-2 -t str --set /apps/metacity/keybinding_commands/command_9 "gnome-system-monitor"
Simplemente copie y pegue :)
deskbar-applet, realiza tus búsquedas desde el escritorio

deskbar-applet es una de esas aplicaciones que parecen no tener mucho sentido en un principio, pero desde el mismo momento en que comienzas a utilizarla se te facilitan muchas actividades cotidianas.
deskbar-applet provee una versátil interfaz de búsqueda, incluso, puede abrir aplicaciones, ficheros, búsquedas locales (se integra complemente con beagle si lo tienes instalado) o directamente en internet; aquellos términos que desee buscar, simplemente tendrá que escribirlos dentro de la casilla correspondiente en el panel. En caso de escribir una dirección de correo electrónico en la barra de búsqueda se le brindará la opción de escribir un correo al destinario que desee.
Si desea probarlo es muy sencilla su instalación. En primer lugar debe tener activa la sección universe en su lista de repositorios.
deb http://us.archive.ubuntu.com/ubuntu breezy universe
deb-src http://us.archive.ubuntu.com/ubuntu breezy universe
Una vez que haya editado el fichero /etc/apt/sources.list debe actualizar la nueva lista de paquetes.
$ sudo aptitude update
Seguidamente puede proceder a instalar el paquete deskbar-applet, para ello simplemente haga.
$ sudo aptitude install deskbar-applet
Una vez culminado el proceso de instalación debe activar deskbar-applet (esta aplicación aparece en la sección de Accesorios) para que aparezca en el panel que desee, recuerde que para agregar un elemento al panel simplemente debe hacer click con el botón derecho del mouse y seleccionar la opción Añadir al panel.
Su uso es muy sencillo, posee una combinación de teclas (Alt + F3) que le facilitará enfocar la casilla de entrada, inmediatamente podrá comenzar a escribir.
Los Repositorios
Contenido:
- Definición
- ¿Cómo funcionan los Repositorios?
- ¿Cómo establecer Repositorios? 1. Los Repositorios Automáticos 2. Los Repositorios Triviales
- ¿Cómo crear ficheros Index?
- ¿Cómo crear ficheros Release?
- ¿Cómo crear Estanques? 1. Herramientas
- ¿Cómo usar los Repositorios?
Los Repositorios (definición)
Un repositorio es un conjunto de paquetes Debian organizados en un directorio en árbol especial, el cual también contiene unos pocos ficheros adicionales con los índices e información de los paquetes. Si un usuario añade un repositorio a su fichero sources.list, él puede ver e instalar facilmente todos los paquetes disponibles en éste al igual que los paquetes contenidos en Debian.
¿Cómo funcionan los repositorios?
Un repositorio consiste en al menos un directorio con algunos paquetes DEB en él, y dos ficheros especiales que son el Packages.gz para los paquetes binarios y el Sources.gz para los paquetes de las fuentes. Una vez que tu repositorio esté listado correctamente en el sources.list, si los paquetes binarios son listados con la palabra clave deb al principio, apt-get buscará en el fichero índice Packages.gz, y si las fuentes son listadas con las palabras claves deb-src al principio, éste buscará en el fichero indice Sources.gz. Ésto se debe a que en el fichero Packages.gz se encuentra toda la información de todos los paquetes, como nombre, version, tamaño, descripción corta y larga, las dependencias y alguna información adicional que no es de nuestro interés. Toda la información es listada y usada por los Administradores de Paquetes del sistema tales como dselect o aptitude. Sin embargo, en el fichero Sources.gz se encuentran listados todos los nombres, versiones y las dependencias de desarrollo (esto es, los paquetes necesitados para compilar) de todos los paquetes, cuya información es usada por apt-get source y herramientas similares.
Una vez que hayas establecido tus repositorios, serás capaz de listar e instalar todos sus paquetes junto a los que vienen en los discos de instalación Debian; una vez que hayas añadido el repositorio deberás ejecutar en la consola:
$ sudo apt-get update
Ésto es con el fin de actualizar la base de datos de nuestro APT y así el podrá “decirnos” cuales paquetes disponemos con nuestro nuevo repositorio. Los paquetes serán actualizados cuando ejecutemos en consola.
$ sudo apt-get upgrade
¿Cómo establecer Repositorios?
Existen dos tipos de repositorios: los complejos, que es donde el usuario sólo tiene que especificar la ruta base de el repositorio, la distribución y los componentes que él quiera (APT automáticamente buscará los paquetes correctos para la arquitectura correspondiente, si están disponibles), y los más simples, donde el usuario debe especificar la ruta exacta (aqui APT no hará magia para encontrar cuales de los paquetes son los indicados). El primero es más difícil de establecer, pero es más fácil de utilizar, y siempre debería ser usado para repositorios complejos y/o plataformas cruzadas; el último, es más fácil de establecer, pero sólo debería ser usado para repositorios pequeños o de una sola arquitectura.
Aunque no es realmente correcto, aquí llamaré al primero Repositorios Automáticos y al último Repositorios Triviales.
Repositorios Automáticos
La estructura del directorio de un repositorio automático con las arquitecturas estándares de Debian y sus componentes se asemeja mucho a ésto:
(tu repositorio root)
|
+-dists
|
|-stable
| |-main
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| |-contrib
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| +-non-free
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|
|-testing
| |-main
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| |-contrib
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| +-non-free
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|
+-unstable
|-main
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|-contrib
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
+-non-free
|-binary-alpha
|-binary-arm
|-binary-...
+-source
Los paquetes libres van en el directorio main; los que no son libres van en el directorio non-free y los paquetes libres que dependen de los que no son libres van en el directorio contrib.
Existen también otros directorios poco comunes que son el non-US/main que contienen paquetes que son libres pero que no pueden ser exportados desde un servidor en los Estados Unidos y el directorio non-US/non-free que contiene paquetes que tienen alguna condición de licencia onerosa que restringe su uso o redistribución. No pueden ser exportados de los Estados Unidos porque son paquetes de software de cifrado que no están gestionados por el procedimiento de control de exportación que se usa con los paquetes de main o no pueden ser almacenados en servidores en los Estados Unidos por estar sujetos a problemas de patentes.
Actualmente Debian soporta 11 tipos de arquitecturas; en éste ejemplo se han omitido la mayoría de ellas por el bien de la brevedad. Cada directorio binary-* contiene un fichero Packages.gz y un fichero opcional Release; cada directorio fuente contiene un fichero Sources.gz y también contiene un fichero opcional Release.
Nota que los paquetes no tienen que estar en el mismo directorio como los ficheros índices, porque los ficheros índices contienen las rutas a los paquetes individuales; de hecho, podrían estar ubicados en cualquier lugar en el repositorio. Ésto hace posible poder crear estanques.
Somos libres de crear tantas distribuciones como componentes y llamarlos como queramos; las que se usan en el ejemplo son, justamente las usadas en Debian. Podríamos, por ejemplo, crear las distribuciones current y beta (en vez de stable, unstable y testing, y que los componentes sean foo, bar, baz y qux (en lugar de main, contrib y non-free).
Ya que somos libres de llamar los componentes como queramos, siempre es recomendable usar las distribuciones estándar de Debian, porque son los nombres que los usuarios de Debian esperan.
Repositorios Triviales
Los repositorios triviales, consisten en un directorio raíz y tantos sub-directorios
como deseemos. Como los usuarios tienen que especificar la ruta a la raíz del repositorio
y la ruta relativa entre la raíz y el directorio con los ficheros indices en él, somos libres de hacer lo que queramos (inclusive, colocar todo en la raíz del repositorio; entonces, la ruta relativa simplemente sería /. Se parecen mucho a ésto:
(your repository root)
|
|-binary
+-source
¿Cómo crear ficheros Index?
dpkg-scanpackages es la herramienta con la que podemos generar el fichero Packages y con la herramienta dpkg-scansources creamos los ficheros Sources. Ellos pueden enviar sus salidas a stout; por consiguiente, para generar ficheros comprimidos, podemos usar una cadena de comandos como ésta:
$ dpkg-scanpackages arguments | gzip -9c > Packages.gz
Las dos herramientas trabajan de la misma manera; ambas toman dos argumentos (en realidad son más, pero aquí no hablaremos de eso; puedes leerte las páginas del manual si quieres saber más); el primer argumento es el directorio en cual están los paquetes, y el segundo es el fichero predominante. En general no necesitamos los ficheros predominantes para repositorios simples, pero como éste es un argumento requerido, simplemente lo pasamos a /dev/null. dpkg-scanpackages escanea los paquetes .deb, sin embargo, dpkg-scansources escanea los ficheros .dsc, por lo tanto es necesario colocar los ficheros .orig.gz, .diff.gz y .dsc juntos. Los ficheros .changes no son necesarios. Así que, si tienes un repositorio trivial como el mostrado anteriormente, puedes crear los dos ficheros indice de la siguiente manera:
$ cd my-repository
$ dpkg-scanpackages binary /dev/null | gzip -9c > binary/Packages.gz
$ dpkg-scansources source /dev/null | gzip -9c > source/Sources.gz
Ahora bien, si tienes un repositorio tan complejo como el mostrado en el primer ejemplo, tendrás que escribir algunos scripts para automatizar éste proceso. También puedes usar el argumento pathprefix de las dos herramientas para simplificar un poco la sintaxis.
¿Cómo crear ficheros Release?
Si quieres permitirle a los usuarios de tu repositorio usar el pinning con tu repositorio, entonces deberás incluir un fichero Release en cada directorio que contenga un fichero Index. (Puedes leer más acerca del pinning en el COMO APT). Los ficheros Release son ficheros de texto simple y cortos que tienen una forma muy parecida a la que sigue:
Archive: archivo
Component: componente
Origin: TuCompañia
Label: TuCompañia Debian repositorio
Architecture: arquitectura
- Archive: El nombre de la distribución de Debian. Los paquetes en éste directorio pertenecen a (o estan diseñados para), por ejemplo,
stable,testingounstable. - Component: Aquí van los componentes de los paquetes en el directorio, por ejemplo,
main,non-freeocontrib. - Origin: El nombre de la persona que hizo los paquetes.
- Label: Algunas etiquetas adecuadas para los paquetes de tu repositorio. Usa tu imaginación.
- Architecture: La arquitectura de lo paquetes en éste directorio, como
i386por ejemplo,sparco fuente. Es importante que se establezcanArchitectureyArchivede manera correcta, ya que ellos son más usados para hacerpinning. Los otros, sin embargo, son menos importantes en éste aspecto.
¿Cómo crear estanques?
Con los repositorios automáticos, distribuir los paquetes en los diferentes directorios puede tornarse rápidamente en una bestia indomable, además también se gasta mucho espacio y ancho de banda, y hay demasiados paquetes (como los de la documentación, por ejemplo) los cuales son los mismos para todas las arquitecturas.
En éstos casos, una posible solución es un estanque. Un estanque es un directorio adicional dentro del directorio raíz del repositorio, que contiene todos los paquetes (los binarios para todas las arquitecturas, distribuciones y componente y todas las fuentes). Se pueden evitar muchos problemas, a través de una combinación inteligente de ficheros predominantes (tema que no se toca en éste documento) y de scripts. Un buen ejemplo de un reposotorio “estancado” es el propio repositorio de Debian.
Los estanques sólo son útiles para repositorio grandes. Nunca he hecho uno y no creo que lo haga en un futuro cercano y ésa es la razón por la cual no se explica como hacerlo aquí. Si tu crees que esa sección debería ser añadida siéntete libre de escribir una y contáctame luego.
Herramientas
Existen varias herramientas para automatizar y facilitar la creación de ficheros Debian. A continuación son listados los más importantes:
-
apt-ftparchive: Es la línea de comandos de la herramienta usada para generar los ficheros indice que APT utiliza para accesar a la fuente de una distribución. -
apt-move: Es usado para mover una colección de ficheros paquetes de Debian a un fichero jerárquico como el usado en el fichero oficial Debian. Éste es parte del paqueteapt-utils.
¿Cómo usar los repositorios?
Usar un repositorio es muy sencillo, pero ésto depende de el tipo de repositorio que hayas creado, ya sea binario o de fuentes, automático o trivial. Cada repositorio ocupa una línea en el fichero sources.list. Para usar un repositorio binario solo tenemos que usar deb al principio de la línea y para usar un repositorio de
fuentes, en vez de deb, sólo tenemos que agregrar deb-src. Cada línea tiene la siguiente sintaxis:
deb|deb-src uri distribución [componente1] [componente2] [...]
El URI es el Identificador Universal de Recursos de la raíz del repositorio, como por ejemplo: ftp://ftp.tusitio.com/debian, http://tusitio.com/debian, o, para ficheros locales, file::///home/joe/mi-repositorio-debian/. Donde la barra inclinada es opcional. Para repositorios automáticos, tienes que especificar la distribución y uno o más componentes; la distribución no debe terminar con una inclinada.
A continuación unos ejemplos de repositorios:
deb ftp://sunsite.cnlab-switch.ch/mirror/debian/ unstable main contrib non-free
deb-src ftp://sunsite.cnlab-switch.ch/mirror/debian/ unstable main contrib non-free
deb file:///home/aisotton/rep-exact binary/
deb-src file:///home/aisotton/rep-exact source/
Donde los dos primeros se corresponden con repositorios de tipo Automático y los dos últimos Triviales.
Lista de paquetes en la distribución estable de Debian. Lista de paquetes en la distribución testing de Debian Lista de paquetes en la distribución inestable de Debian
Artículo original Debian Repository HOWTO por Aaron Isotton
El fichero sources.list
La mayoría de los entusiastas de sistemas Linux, tarde o temprano llegan a toparse con ésta interrogante. En una forma bastante general, podríamos definir a éste fichero como la lista de recursos de paquetes que es usada para localizar los ficheros del sistema de distribución de paquetes usado en el sistema. Este fichero de control está ubicado en la carpeta /etc/apt/ de nuestro sistema. El fichero es un simple documento de texto sencillo que puede ser modificado con cualquier editor de textos.
Dentro de éste fichero nos vamos a encontrar una serie de líneas, que no son más que las procedencias de los recursos ubicados en los repositorios que elijamos. Éstas líneas de procedencias tienen una forma general que es: tipo, uri, distribución y complementos.
Entonces, las formas generales de las líneas de procedencias sería así:
deb uri distribución [componente1] [componente2] [...]
deb-src uri distribución [componente1] [componente2] [...]
¿Qué debo saber sobre el sources.list?
Debemos tener en cuenta varios aspectos sobre éste fichero tan importante. Por ejemplo, hay algo que muchos no saben e ignoran, y es que ésta lista de procedencias está diseñada para soportar cualquier número y distintos tipos de procedencias, por supuesto, la demora del proceso de actualización de la base de datos del APT va a ser proporcional al número de procedencias, ya que mientras más procedencias, mayor es la cantidad de paquetes a añadir a la base de datos, y también va a durar un poco más de tiempo, dependiendo de nuestra velocidad de conexión.
El fichero lista una procedencia por línea, con la procedencia de mayor prioridad en la primera línea, como por ejemplo, cuando tenemos los paquetes en discos CD-ROM, entonces ubicamos éste de primero. Como ya mencioné, el formato de cada línea es:
tipo uri distribución complementos
Donde:
-
tipo: Determina el formato de los argumentos, que pueden ser de dos tipos:debydeb-src. El tipodebhace referencia a un típico archivo de Debian de dos niveles, que son distribución y componente, sin embargo, el tipodeb-srchace referencia al código fuente de la distribución y tiene la misma sintaxis que las de tipodeb. Las líneas de tipodeb-srcson necesarias si queremos descargar un índice de los paquetes que tienen el código fuente disponible, entonces de ésta forma obtendremos los códigos originales, más un fichero de control, con extensión.dscy un fichero adicionaldiff.gz, que contiene los cambios necesario para debianizar el código. -
uri: Identificador Universal de Recursos, ésto es, el tipo de recurso de la cual estamos obteniendo nuestros paquetes. Pero ¿Cuáles son los tipos deurique admite nuestra lista de procedencias? A continuación hago mención de las más populares, por así decirlo: *CD-ROM: El cdrom permite a APT usar la unidad de CD-ROM local. Se puede usar el programaapt-cdrompara añadir entradas de un cdrom al ficherosources.listde manera automática, en modo consola.-
FTP: Especifica un servidor FTP como archivo. *HTTP: Especifica un servidor HTTP como archivo. -
FILE: Permite considerar como archivo a cualquier fichero en el sistema de ficheros. Esto es útil para particiones montadas mediante NFS (sistema de ficheros usado para montar particiones de sistemas remotos) y réplicas locales.
-
-
distribución: Aquí especificamos la distribución en la cual estamos trabajando, bien sea Debian, Ubuntu, Kubuntu, Gnoppix,Knoppix y otras, basadas en sistemas Debian GNU/Linux.distribucióntambién puede contener una variable,$(ARCH), que se expandirá en la arquitectura de Debian usada en el sistema (i386,m68k,powerpc,…). Esto permite quesources.listno sea dependiente de la arquitectura del sistema. -
componentes: Los componentes son los tipos de repositorios clasificados según las licencias de los paquetes que contienen. Dentro de los componentes tenemosmain,contribynon-free, para usuarios Debian; sin embargo para usuarios Ubuntu, por ejemplo, también existenuniverse,multiverserestricted. Ahora la decisión de cuales repositorios utilizar, eso va más allá de lo pueda ser explicado acá, ya que eso le concierne a su persona.
Entonces, la forma de una línea de procedencias quedaría algo así:
# deb http://security.ubuntu.com/ubuntu breezy-security main restricted
# deb-src http://security.ubuntu.com/ubuntu breezy-security main restricted
Ahora bien, se preguntarán ¿Por qué el carácter # (almohadilla) al principio de la línea? Bueno, la respuesta es muy simple. Éste caracter se utiliza para indicarle al APT cuando ignorar, por así decirlo, las líneas que contengan dicho caracter al principio, pues lo que hace en realidad es tomarlas como comentarios de lenguaje y simplemente no las interpreta, por lo tanto, si queremos que el APT tome o no en cuenta una línea de procedencias, entonces quitamos o añadimos el caracter, respectivamente.
Nota del autor: Algunas partes de este artículo fueron tomadas del manual de Debian.
Flock, el nuevo navegador social
Flock, es un nuevo navegador que toma sus bases en Mozilla Firefox, su objetivo es captar la atención de usuarios que suelen usar herramientas de comunicación social que están en boga, como por ejemplo:
- del.icio.us: Almacena y comparte tus enlaces favoritos.
- Flickr: Almacena y comparte tus imágenes.
- Technorati: Entérate acerca de lo que se habla actualmente en los blogs. Colección de enlaces a bitácoras organizados por etiquetas o tags.
- Sistemas de Blogging: Entre ellos: WordPress, Blogger, Movable Type, entre otros.
Sistema de publicación
Respecto a la posibilidad de publicar entradas o posts en tu blog desde el mismo navegador, Flock le ofrece una ventana aparte, tendrá que rellenar apropiadamente las distintas opciones que se le muestran para configurar el programa y de esa manera comenzar a redactar sus noticias, artículos, entre otros.
 Siguiendo con el tema de la publicación de artículos, Flock, le permite
conectarse con su cuenta en Flickr y añadir fotos, esta posibilidad no se
restringe solo a las cuentas de Flickr, podrá incluir fotos que se muestren en
otros sitios, solamente deberá arrastrar dicha imagen a la interfaz que le
proporciona el editor en cuestión.
Siguiendo con el tema de la publicación de artículos, Flock, le permite
conectarse con su cuenta en Flickr y añadir fotos, esta posibilidad no se
restringe solo a las cuentas de Flickr, podrá incluir fotos que se muestren en
otros sitios, solamente deberá arrastrar dicha imagen a la interfaz que le
proporciona el editor en cuestión.
De igual manera lo explicado en el párrafo anterior puede aplicarse al texto, podrá arrastrar a la zona de edición cualquier texto disponible en la web, tambien Flock ofrece una opción denominada blog this, su funcionamiento es muy sencillo, solamente deberá seleccionar un texto que le interese publicar, seguidamente proceda a dar click con el botón derecho del mouse blog this, el texto en cuestión aparecerá en la zona de edición como una cita.
El sistema de publicación que le ofrece Flock le permite guardar sus artículos como borradores o marcarlos para su publicación inmediata, otra característica que cabe resaltar es la posibilidad de indicar explícitamente con cuales etiquetas o tags desea que se almacene la entrada para su clasificación en Technorati.
Favoritos
 El sistema de favoritos se integra con tu cuenta en del.icio.us, gestor de
enlaces favoritos o bookmarks comunitario. y organizado por etiquetas o
tags.
El sistema de favoritos se integra con tu cuenta en del.icio.us, gestor de
enlaces favoritos o bookmarks comunitario. y organizado por etiquetas o
tags.
Lectura de feeds
 Flock nos indica cuando un blog o bitácora dispone de un feed, la manera de
indicarlo es muy agradable a la vista, simplemente muestra un icono al lado
derecho de la ventana de la URL. Si lo desea, puede ver el contenido del feed
desde el mismo Flock, que le ofrece un visualizador de feeds, en él podrá
ordenar las entradas por fechas o por la fuente, de manera adicional podrá
contraer o expander todas las noticias, si decide contraer (o expander) las
noticias de acuerdo al orden que haya elegido (por fecha o por fuente), puede ir
expandiendo (o contrayendo) dichas noticias una por una.
Flock nos indica cuando un blog o bitácora dispone de un feed, la manera de
indicarlo es muy agradable a la vista, simplemente muestra un icono al lado
derecho de la ventana de la URL. Si lo desea, puede ver el contenido del feed
desde el mismo Flock, que le ofrece un visualizador de feeds, en él podrá
ordenar las entradas por fechas o por la fuente, de manera adicional podrá
contraer o expander todas las noticias, si decide contraer (o expander) las
noticias de acuerdo al orden que haya elegido (por fecha o por fuente), puede ir
expandiendo (o contrayendo) dichas noticias una por una.
¿Desea probar Flock?
Si lo desea, puede probar fácilmente Flock al hacer uso de los ficheros binarios que se ofrecen, en ubuntu (aplicable en otras distribuciones) debe hacerse lo siguiente:
En primer lugar deberá descargar el paquete binario que se ofrece para la plataforma Linux desde la sección Developer de Flock.
Antes de continuar, debe saber que Flock está compilado haciendo uso de
libstdc++ en su versión 5, si, se encuentra en
Breezy, debe instalarla de la
siguiente manera:
$ sudo aptitude install libstdc++5
Una vez que se haya completado la transferencia del paquete binario de Flock, debe ubicarse en el directorio destino de la descarga y proceder a descompimir y desempaquetar el paquete en cuestion, para ello, debe hacer lo siguiente.
$ tar xvzf flock-0.4.10.en-US.linux-i686.tar.gz
Por supuesto, es de suponerse que en este ejemplo particular el paquete que se
descargó fué flock-0.4.10.en-US.linux-i686.tar.gz, usted debe ajustar este
argumento de acuerdo al fichero que haya descargado.
Una vez culminado el paso anterior lo que sigue es sencillo, debe entrar en el
directorio generado y ejecutar el comando flock, más o menos similar a lo que
sigue a continuacion.
$ cd flock
$ ./flock
Recuerde que en Breezy usted puede generar una entrada al menú haciendo uso de Herramientas del Sistema -> Applications Menu Editor, seguidamente seleccione el submenu Internet y genere una nueva entrada con las siguientes propiedades.
- Name: Flock
- Comment: Internet Browser
- Command: /directorio_donde_esta_flock/flock
- Icon: /directorio_donde_esta_flock/icons/mozicon128.png
Referencias
Planeta ubuntu-es
El día de hoy me siento muy contento por poder anunciarles un proyecto en el que me había animado en hacer desde hace ya un tiempo, estuve en conversaciones con varias personas y al darme muestras de apoyo decidí aventurarme.
El proyecto del que les hablo es Planeta ubuntu-es, sitio en el cual se pretende recopilar toda la información aportada por bloggers (personas que mantienen blogs o bitácoras) amigos y colaboradores de la Comunidad de Ubuntu Linux es castellano y que desean de una u otra manera compartir sus experiencias, críticas y temas relacionados con la distribución.
Cualquier blogger que le interese el tema puede contribuir, solamente se requiere cumplir ciertos requerimientos. El primero de ellos es tener cualquiera de las siguientes categorías en su blog.
- ubuntu
- kubuntu
- edubuntu
- xubuntu
Lo anterior se solicita para brindar mayor organización en los archivos de las entradas proporcionadas por los bloggers contribuyentes.
Como segundo requerimiento se tiene, aunque parezca evidente, redactar artículos acerca de Ubuntu Linux, sus derivados o noticias relacionadas. Al cumplir con los requisitos mencionados previamente puede ponerse en contacto con nosotros, puede hacernos llegar sus inquietudes, críticas, comentarios, sugerencias; así como también puede manifestarnos su intención de unirse al proyecto. Una vez que su solicitud haya sido aceptada, sus artículos comenzarán a aparecer en Planeta ubuntu-es.
Planeta ubuntu-es agradece a sus contribuyentes brindándoles promoción, en primer lugar, nuestra página principal mostrará enlaces de todos nuestros colaboradores, a su vez, los comentarios (al igual que los pings) en nuestro sitio han sido desactivados. Por lo tanto, los lectores que deseen discutir acerca de un tema en particular deberán hacerlo en los sitios de origen (sitios de los contribuyentes) de los artículos. De igual manera, todos los títulos de los artículos apuntarán a los sitios de origen. En resúmen, tanto lectores como bloggers se benefician del proyecto.
El proyecto tiene como meta reunir bloggers y lectores que tienen intereses en común, en este caso particular, la distribución ubuntu, sus derivados y noticias relacionadas. Por lo tanto, estaremos contribuyendo de alguna manera a la difusión y aceptación del Software Libre y el Open Source como soluciones reales en nuestros días, de igual manera, se busca la aceptación de Ubuntu como la distribución por excelencia tanto para usuarios no iniciados así como también aquellos usuarios expertos en sistemas GNU/Linux.
Para mayor información del proyecto, puede visitar las secciones:
Se añaden 3 arquitecturas en ubuntu
El mismo día 13 de Octubre, día del lanzamiento de Breezy, el equipo encargado de portar Ubuntu a otras arquitecturas anunció que Breezy puede usarse ahora en 3 pequeñas arquitecturas.
Ubuntu ahora esta disponible para las arquitecturas IA64, HPPA (1.1 y posterior) y SPARC (solamente UltraSPARC). Dichas arquitecturas muchas veces no son tomadas en cuenta por otras distribuciones.
Ninguna de estas nuevas arquitecturas son oficialmente soportadas por el equipo de Ubuntu. Sin embargo, si se logra tener una gran base de usuarios, esta situación podría cambiar.
Mientras que en estas nuevas arquitecturas usted podrá disfrutar de la gran variedad de software que le ofrece Ubuntu, esta características aún no ha sido finalizada.
Como obtener cualquier de estas arquitecturas
Si lo desea, puede ver el Anuncio Oficial hecho por Fabio Massimo Di Nitto.
COMO instalar e17 desde los repositorios de shadoi en Breezy
Nota: Antes que nada es importante resaltar que E17 está todavía en desarrollo. Si desea intentar utilizar E17, sepa que este software es todavía un versión pre-alfa, que aún esta en constante desarrollo y por tanto su uso puede implicar algunos riesgos.
Enlightenment DR17 combina características presentes en los manejadores de ventanas como en los manejadores de ficheros. Provee una interfaz gráfica de usuario que le permitirá manejar los elementos del escritorio, al igual que ficheros y ventanas. El entorno gráfico de Enlightenment es realmente impresionante, es muy agradable para el usuario, también es muy configurable.
Después de una breve introducción, vamos a entrar en acción.
Hace ya algunos días atrás shadoi anunciaba lo siguiente:
Once that new server is in place and all the sites have been moved over, I’ll be quickly adding support for more Debian architectures, distributions and derivatives like Ubuntu.
Posteriormente shadoi (aka Blake Barnett) confirma la noticia.
Ahora para instalar E17 solo necesitará de 4 pasos. La información que será mostrada a continuación es tomada del wiki de shadoi.
Paso #1
Agregar la siguiente línea al fichero /etc/apt/sources.list:
deb http://soulmachine.net/breezy/ unstable/
También debe agregar lo siguiente al fichero /etc/apt/preferences (si no
existe dicho fichero proceda a crearlo).
Package: enlightenment
Pin: version 0.16.999*
Pin-Priority: 999
Package: enlightenment-data
Pin: version 0.16.999*
Pin-Priority: 999
Paso #2
Instalar la clave pública del repositorio, para ello desde la consola escriba lo siguiente:
$ wget soulmachine.net/public.key
$ sudo apt-key add public.key
Paso #3
Actualice la lista de paquetes disponibles, para ello desde la consola escriba lo siguiente:
$ sudo aptitude update
Paso #4
Instale enligtenment, para ello desde la consola escriba lo siguiente:
$ sudo aptitude install <ins datetime="2005-12-10T05:54:58+00:00">enlightenment=0.16.999.018-1 enlightenment-data</ins>
Notas
Aunque shadoi ha anunciado que el paquete de evidence (gestor de ficheros especialmente desarrollado para ser usado con enlightenment) pronto lo tendrá listo, por ahora puede hacer uso de esta versión, después de finalizada la descarga debe escribir en consola lo siguiente:
$ sudo dpkg -i evidence_0.9.8-20050305-hoaryGMW_i386.deb
El paquete que se ha instalado previamente aunque fue construido en principio para la versión de Ubuntu Hoary, funciona en Breezy. Para la versión reciente de Ubuntu aún no está construido este paquete en particular.
También es importante resaltar que E17 brinda soporte al castellano.
Comprobando las imágenes de ubuntu
Si usted es de las personas que ha descargado la última versión de Ubuntu, para el momento en el que se redactó esta entrada es Breezy Badger, es importante que verifique la autenticidad de la imagen que posee, para ello comprobaremos las sumas de control MD5.
En primer lugar, debe poseer un fichero que posea las sumas de control MD5 de la distribución, normalmente desde el sitio donde descarga las distintas versiones se ubuntu se dispone de uno, en el caso de la versión Breezy Badger disponemos del fichero MD5SUMS, la cual puede encontrar en el sitio de descargas de Breezy Badger.
Una vez descargado debemos compararlo con las sumas de control MD5 generadas para la imagen que poseemos de la versión en nuestro medio de almacenamiento, p.ej. disco duro.
En el ejemplo que presentaré a continuación el fichero que posee las sumas de
control MD5 que he descargado desde el sitio oficial de ubuntu se encuentra en
el directorio /mnt/backup/distros/, en este mismo directorio tengo la imagen
de ubuntu, ubuntu-5.10-install-i386.iso, en resumidas cuentas, el comando a
utilizar para la comprobación de las sumas MD5 es el md5sum, el modo de uso es
el siguiente.
milmazz@omega:/mnt/backup/distros$ <kbd>md5sum -cv MD5SUMS</kbd>
En este caso, la opción -c nos permite comprobar la suma de control MD5 para
todos los archivos listados en el fichero MD5SUMS, la opción -v nos permite
obtener más detalle de la operación, por ejemplo:
ubuntu-5.10-install-i386.iso Correcto
El fichero MD5SUMS posee todas las sumas de control MD5 de las distintas
imágenes que ofrece ubuntu, tanto las imágenes que poseen las versiones
instalables como los LiveCD, en las distintas arquitecturas. Si lo desea,
puede editar el fichero, simplemente haciendo uso de vi, por ejemplo:
$ vi MD5SUMS
Una vez dentro de vi, debe eliminar las lineas que no desee, para ello
simplemente haga uso de dd, una vez eliminadas todas las entradas que no
desee, guarde los cambios, para ello, presione la tecla Esc y seguidamente
escriba :wq y presione la tecla Enter.
Repositorios de Ubuntu
Desde hace unas horas hasta hace poco el servidor principal que mantiene los archivos de los paquetes binarios y fuentes estaba caído.
Obteniendo respuesta desde http://archive.ubuntu.com/ubuntu.
<code>$ wget http://archive.ubuntu.com
--09:56:27-- http://archive.ubuntu.com/
=> `index.html'
Resolving archive.ubuntu.com... 82.211.81.151, 82.211.81.182
Connecting to archive.ubuntu.com[82.211.81.151]:80... failed: Connection refused.
Connecting to archive.ubuntu.com[82.211.81.182]:80... failed: Connection refused.</code>
En cambio, el servicio por ftp si estaba habilitado. Obteniendo respuesta
desde ftp://archive.ubuntu.com/ubuntu
<code>$ wget ftp://archive.ubuntu.com
--09:58:24-- ftp://archive.ubuntu.com/
=> `.listing'
Resolving archive.ubuntu.com... 82.211.81.182, 82.211.81.151
Connecting to archive.ubuntu.com[82.211.81.182]:21... connected.
Logging in as anonymous ... Logged in!
==> SYST ... done. ==> PWD ... done.
==> TYPE I ... done. ==> CWD not needed.
==> PASV ... done. ==> LIST ... done.
[ < => ] 64 --.--K/s
09:58:24 (48.75 KB/s) - `.listing' saved [64]
Removed `.listing'.
Wrote HTML-ized index to `index.html' [302].</code>
Ahora bien, en este caso simplemente bastaba con cambiar la entrada http por
ftp en el fichero /etc/apt/sources. Para evitar cualquier tipo de
inconvenientes en el futuro, es recomendable hacer uso de sitios espejo o
mirrors.
En https://wiki.ubuntu.com/Archive encontrará toda la información necesaria, si utiliza los repositorios del proyecto Ubuntu Backport es recomendable que vea su sección de las URL de los Repositorios.
NOTA: Siempre es recomendable hacer uso de sitios espejos puesto que estos presentan menos demanda que los sitios oficiales de los proyectos.
Cambiando la ubicación del cache de apt
El día 21 de Septiembre Jorge Villarreal preguntó en la entrada Creando un repositorio local lo siguiente:
… tengo un laptop lentisimo , ahora mi pregunta ya que puedo navegar desde la oficina y en ella solo tienen windows como hago para descargar actualizaciones y llevarlas en una pen o en cd?. a como anexo en las tardes navego con cd-live ubuntu, me pregunto si podre bajar virtualmente desde ahi?
Mi respuesta es la siguiente:
Sí, en efecto puedes descargar los paquetes desde tu LiveCD de Ubuntu, de hecho, existen dos maneras para mí, las expongo a continuación.
Primer método
La primera es usar la memoria que dispones, la cual es limitada, recuerda que
los ficheros que descarga la interfaz apt (o aptitude) se almacenan en el
directorio /var/cache/apt/archives, como te mencione anteriormente, este método
puede ser limitado.
Veamos ahora el segundo método, te recomiendo éste porque vamos a escribir en el disco duro.
Segundo método
Ya que en la oficina utilizas Windows, el único requisito que se necesita es disponer de una partición cuyo formato de ficheros sea FAT, asumiré en el resto de mi respuesta que dicha partición se encuentra en /dev/hdb1 y se ha montado en /mnt/backup. Por lo tanto:
$ sudo mount -t vfat /dev/hdb1 /mnt/backup
Posteriormente se debe crear el fichero /etc/apt.conf, esto se puede hacer fácilmente con cualquier editor. Dicho fichero debe contener lo siguiente:
DIR "/"
{
Cache "mnt/backup/apt/" {
Archives "archives/";
srcpkgcache "srcpkgcache.bin";
pkgcache "pkgcache.bin";
};
};
Lo anterior simplemente está cambiando el directorio usual
(/var/cache/apt/archives) del cache, de ahora en adelante se estará
escribiendo de manera permanente en disco duro. Previamente debes haber creado
el directorio /mnt/backup/apt/archives/. Seguidamente tienes que crear el
fichero lock y el directorio partial. Resumiendo tenemos:
$ mkdir -p /mnt/backup/apt/archives/partial
$ touch /mnt/backup/apt/archives/lock
Pasos comunes en ambos métodos
Recuerda que sea cual sea el método que decidas usar, debes editar el fichero /etc/apt/sources.list, mejora la lista de repositorios que se presentan, luego de guardar los cambios en el fichero, ejecuta el siguiente comando.
$ sudo aptitude update
El comando anterior actualizará tú lista de paquetes con los que se encuentran en los repositorios que añadiste previamente. Ahora bien, para almacenar ficheros en el directorio cache haz uso del comando.
$ sudo aptitude --download-only install <em>packages</em>
Cuando me refiero a packages recuerda que son los nombres de los paquetes.
Seguidamente puedes seguir los pasos que se te indican en la entrada Creando un
repositorio local, por
supuesto, si cambias la dirección del cache que hará uso la interfaz apt (o
aptitude) debes hacer los ajustes necesarios. Espero te sirva la información.
Si alguien desea realizar un aporte bienvenido será.
Automatiza el uso de pastebin desde la línea de comandos
Si deseas colocar gran cantidad de código en un canal IRC, Chat o haciendo uso de la mensajería instantánea, es realmente recomendable que haga uso de un sistema pastebin, por ejemplo, pastebin.com, el cual es una herramienta colaborativa que permite depurar código.
Además, siguiendo esta metodología se evita incurrir en el conocido flood, el cual consiste en el envio de gran cantidad de información a un usuario o canal, la mayoría de las ocasiones con el fin de molestar, incluso, puede lograr desconectar a otros usuarios. Este tipo de prácticas se castigan en muchos canales IRC.
Si no está familiariazado con la idea de los sistemas pastebin, un resúmen le puede ayudar en algo:
- Envie un fragmento de código al sistema pastebin de su preferencia, obtendrá
una dirección similar a
http://pastebin.com/1234 - Informe de la URL obtenida en los canales IRC o a través de la conversación que mantenga por mensajería instantánea.
- Cualquier persona puede leer su código, a su vez, pueden enviar modificaciones de éste.
- Si no se da cuenta de las modificaciones a primera vista, puede hacer uso de las opciones que le muestran las diferencias entre los ficheros de manera detallada.
Existe un script hecho en Python que le permite de manera automática y fácil el colocar la salida del terminal o de otros programas hechos en Python al sitio de pastebin que usted prefiera.
Instalación
Ejecute los siguientes pasos:
$ wget http://www.ubuntulinux.nl/files/pastebin
$ chmod +x pastebin
$ sudo ./pastebin --install
El comando anterior instalará el script dentro del directorio /usr/bin/ con permisos de ejecución.
Uso
pastebin [--name Autor] [--pid Entrada_Padre] [--bin URL_Pastebin]
Los valores entre corchetes son opcionales, cada uno significa lo siguiente:
-
--name: Recibe como valor el nombre del autor del código. -
--pid: Debe usarlo cuando está dando una respuesta o corrección a alguna entrada. Normalmente es el número que le sigue inmediatamente al nombre del servidor por ejemplo: Si usted tiene una URL de este tipo,http://pastebin.com/2401, elpidsería2401. -
--bin: Recibe como valor el sistema pastebin que esté usando.
Si no desea estar especificando a todo momento el nombre del autor (--name) y
el servicio pastebin que usa (--bin), puede crear un fichero en
/etc/pastebinrc o en ~/.pastebinrc. El primero aplica a todos los usuarios y
el segundo a un usuario local. En cualquiera de los casos, dicho fichero debe
contener lo siguiente:
poster = Nombre Autor
pastebin = Servicio Pastebin
Por ejemplo, en mi caso particular, el contenido del fichero /etc/pastebinrc
es el siguiente:
poster = [MilMazz]
pastebin = paste.ubuntulinux.nl
Haciendo uso de la tubería o pipe
Colocando la salida estándar
`$ comando | pastebin`
Colocando la salida estándar y los posibles errores
`$ comando 2>&1 | pastebin`
Recuerde que debe sustituir comando en los dos ejemplos mostrados previamente por el nombre real del comando del cual desea obtener una respuesta.
Vía: Ubuntu Blog.
Conozca la temperatura de su disco duro
Si desea conocer cual es el valor en grados centígrados de la temperatura de su
disco duro, simplemente instale el paquete hddtemp desde el repositorio
universe haciendo lo siguiente:
$ sudo aptitude install hddtemp
Después, siempre que desee conocer la temperatura actual de su disco duro, proceda de la siguiente manera:
$ sudo hddtemp /dev/hdb
Por supuesto, recuerde que en la línea anterior /dev/hdb es el identificador
de mi segundo disco duro, proceda a cambiarlo si es necesario.
Mi temperatura actual en el segundo disco duro es de:
milmazz@omega:~$ sudo hddtemp /dev/hdb
/dev/hdb: ST340014A: 46°C
Antes de finalizar, es importante resaltar que hddtemp le mostrará la
temperatura de su disco duro IDE o SCSI solamente si éstos soportan la
tecnología SMART (acrónimo de: Self-Monitoring, Analysis and Reporting
Technology).
SMART simplemente es una tecnología que de manera automática realiza un monitoreo, análisis e informes, ésta tiene un sistema de alarma que en la actualidad viene de manera predeterminada en muchos modelos de discos duros, lo anterior puede ayudarle a evitar fallas que de una u otra manera pueden afectarle de manera contundente.
En esencia, SMART realiza un monitoreo del comportamiento del disco duro y si éste presenta un comportamiento poco común, será analizado y reportado al usuario.
Vía: Ubuntu Blog.
Registro de la segunda charla en el canal #ubuntu-es
Ya se encuentra disponible el registro de la segunda charla dada en el canal #ubuntu-es del servidor FreeNode. En esta charla se discutió lo siguiente:
- Ventajas y desventajas del uso de
aptitudefrente aaptysynaptic. - Resumen de comandos en
aptitude,apt,dpkg. - ¿Qué es un repositorio?.
- Agregando nuevos repositorios.
- Proyecto Ubuntu Backports.
- Editando el fichero
/etc/apt/sources.list. - Estructura de los repositorios.
- Ejemplos de uso de
aptitude. - Como actualizar de manera segura su sistema.
- ¿Es importante la firma de paquetes?.
- ¿Como verificamos la autencidad de los paquetes?.
- Como se importa la llave pública desde un servidor GPG.
- Como se exporta la llave pública y se añade a nuestra lista de claves seguras.
- Sesión de preguntas y respuestas.
Puede ver el registro de la charla al seguir el enlace anterior.
En ubuntuchannel.org estamos haciendo todo lo posible por mejorar cada día más, si está interesado en informarse acerca de las siguientes charlas puede ver como siempre nuestra sección de Eventos.
Recientemente nos hemos dedicado a realizar una especie de listado alfabético de
los comandos en GNU/Linux, dicha información se encuentra disponible en la
sección de Comandos, si desea
colaborar, su ayuda es bien recibida, solo recuerde comunicarse previamente
conmigo, para ello puede hacer uso del formulario de
contacto, para ponernos de acuerdo al
respecto. También puede recibir información de manera interactiva acerca del
proyecto en el canal IRC #ubuntu-es del
servidor FreeNode, sino me encuentro conectado (nick
[MilMazz]) en ese instante puede preguntarle al operador del canal (si se
encuentra conectado claro está), P3L|C4N0 con gusto le atenderá.
Charlas en #ubuntu-es
El día de ayer se llevo a cabo la primera de la serie de charlas que se
emitirán por el canal #ubuntu-es del servidor FreeNode, en esta oportunidad
el ponente ha sido zodman, el tema que abordo zodman
fue acerca de Cómo montar un servidor casero haciendo uso de Ubuntu Linux como
plataforma, en el transcurrir de la charla se explico como configurar y
establecer un servidor con los siguientes servicios.
- Apache2
- MySQL
- PHP4
- FTP
- SSH
También se hablo acerca de la configuración de dominios .com, .net y .org sin hacer uso de bind, aplicando dichas configuraciones en el servidor que se está estableciendo.
Si desgraciadamente no pudo estar presente en el evento, no se preocupe, ya he habilitado un registro de la charla. Por motivos de tiempo se decidio dividir la charla en dos partes, si le interesa asistir a la segunda parte de esta charla, esté atentos a los cambios en la sección de Eventos en Ubuntuchannel.org.
Ubuntu 5.10 (Breezy Badger)
Se anuncia la versión previa a la salida oficial de Ubuntu 5.10, cuyo nombre clave es Breezy Badger, esta versión previa incluye tanto un CD instalable como un CD en “vivo” (Live CD) para tres arquitecturas en específico: Intel x86 (PC), PowerPC (Mac) y AMD64 (PC de 64 bits).
Ubuntu Linux es una distribución orientada al escritorio, aunque también es funcional para servidores, ofrece una instalación fácil y rápida, emisión regular de nuevas versiones, selección exhaustiva de excelentes paquetes instalados de manera predeterminada, además, existe un compromiso de ofrecer actualizaciones de seguridad por un lapso de 18 meses para cada una de las versiones.
¿Qué ofrece Ubuntu 5.10 en el escritorio?
-
GNOME 2.12, cuyo lanzamiento ocurrio ¡ayer!.
-
OpenOffice.org 2.0 (beta 2).
-
X.org 6.8.2, con excelente soporte de hardware.
-
Se ofrece una herramienta que facilita enormemente la instalación de nuevas aplicaciones, se puede ver en el menú System Administration -> Add/Remove Programs
-
Una nueva herramienta (Language Selector) que le permitirá instalar fácilmente el soporte para un idioma determinado.
-
Los menús en GNOME son editables.
-
Se ofrece soporte para la grabación de CDs, se utiliza la aplicación Serpentine.
-
Ahora podrá ver una barra de progreso (USplash) mientras su sistema se inicia.
Ubuntu 5.10 tambien ofrece algunos avances en cuanto a la rama de servidores y modos de instalación, en cuanto a los avances en el soporte de hardware nos encontramos con ciertos puntos interesantes, como por ejemplo.
-
Kernel 2.6.12.5 con actualizaciones de drivers provenientes de terceras partes.
-
Mejora en el soporte de hardware para portátiles.
-
Soporte (todo en uno) para los dispositivos (impresoras y scanners) HP.
-
Soporte para dispositivos Bluetooth de entrada (como teclados o ratones).
-
Mejoras en cuanto al manejo de dispositivos de sonido.
-
Disponibilidad del kernel para la arquitectura PowerPC (64 bits).
Puede seleccionar una imagen de la versión previa a la salida oficial de Ubuntu 5.10 al seguir el enlace Ubuntu 5.10 (Breezy Badger) Preview, si es posible realice la descarga usando Bittorrent, evitando la sobrecarga de los servidores.
Ubuntu lightweight
Si usted es de esas personas que le gusta obtener el mayor rendimiento, con la
menor carga de procesador posible, a pesar de no contar con hardware de última
generación. Seguramente este artículo le interesará puesto que trataré de
explicarle detalladamente la instalación del entorno de escritorio XFCE,
partiendo de una instalación server, la cual instala el sistema base
únicamente, sin entorno gráfico, todo esto por supuesto implementado en Ubuntu
Linux.
Existen 4 opciones para instalar Ubuntu, son las siguientes:
-
linux:Esta es la opción de instalación por defecto. -
expert:Inicia la instalación en modo experto, ofrece mayor control sobre la instalación. -
server,server-expert:Ofrece una instalación mínima del sistema, este tipo de instalación es ideal para servidores, en donde regularmente el administrador instalará el software que realmente necesita, bajo esta opción de instalación no se instalará entorno gráfico.
La información anterior la puede verificar al pulsar la tecla F1 en la pantalla de presentación que aparece al iniciar el sistema con el CD de instalación de Ubuntu Linux, seguidamente deberá presionar la tecla F3 para consultar dichas opciones, la tecla F3 se refiere a methods for special ways of using this CD-ROM.
La opción que eligiremos será server, con ello instalaremos el sistema base y
posteriormente nos dedicaremos a levantar el entorno gráfico XFCE.
No se entrará en mucho detalle acerca de la instalación en modo server porque
el asistente nos va guiando de manera muy intuitiva, quizás la parte más
díficil (y no lo es en lo absoluto) sea el particionamiento del disco,
acerca de este último punto tampoco entrare en detalle puesto que en la red
existen infinidad de documentos que hacen referencia a métodos de
particionamiento, yo prefiero hacerlo manualmente, quizás a otros no les guste
el método anterior, pero prefiero tener el control sobre lo que uso. También
existe la posibilidad de realizar un particionamiento automático, asi que no hay
que asustarse.
Una vez finalizada la instalación del sistema base de ubuntu procedemos de la siguiente manera.
Estableciendo los repositorios
En primer lugar, vamos a activar y añadir algunos repositorios, para ello
necesitamos editar el fichero /etc/apt/sources.list, en mi caso he activado
todos los fuentes deb que vienen por defecto en el fichero, por ahora dejo
comentado los deb-src. De manera adicional he agregado a la lista un nuevo
repositorio.
<code>deb http://www.os-works.com/debian testing main</code>
Una vez que haya guardado los cambios en el fichero /etc/apt/sources.list
recuerde que debe autenticar el origen de los ficheros binarios o fuentes de
manera transparente, esto se explico con anterioridad en el artículo COMO
actualizar de manera segura su
sistema, el
ejemplo que se expone en dicho artículo aplica perfectamente para los
repositorios de www.os-works.com.
Puede bajar una muestra de mi sources.list si lo prefiere.
Puede que usted no esté de acuerdo en utilizar el repositorio del grupo os-cillation, yo voy a exponer las razones por las cuales he decidido elegir dicho repositorio, el equipo os-cillation mantiene de manera no oficial paquetes para el entorno de escritorio Xfce, estos paquetes son constantemente actualizados, de hecho, estos paquetes compilados son usados para la creación de la distribución Xfld Live-Linux. Estos paquetes binarios son para la arquitectura i386, compilados en una maquina con Debian testing (sarge).
Estableciendo las preferencias para los repositorios
Seguidamente crearemos el fichero /etc/apt/preferences, recuerde que el
fichero lo puede crear haciendo uso del editor nano o vi, lo importante es
que el fichero contenga lo siguiente:
<code>Package: *
Pin: origin www.os-works.com
Pin-Priority: 999</code>
Después de guardar los cambios del fichero /etc/apt/preferences actualice la
lista de paquetes y la distribución.
Actualizando el sistema actual
<code>$ sudo aptitude update
$ sudo aptitude dist-upgrade</code>
Este proceso puede requerir de cierto tiempo, dependiendo de su ancho de banda.
Instalando xfce, el display manager y los componentes básicos del sistema X Window
Teniendo actualizada la distribución proceda a instalar los siguientes paquetes, al igual que el paso anterior, el tiempo de espera dependera de su ancho de banda.
<code>$ sudo aptitude install x-window-system-core xdm xfld-desktop</code>
Es importante recalcar que le paquete xfld-desktop instalará el entorno de
escritorio completo, incluyendo el emulador del
terminal, el manejador de ficheros
ROX, el reproductor
Xfmedia y otros plugins para
el panel. En el caso en que usted desea solo instalar los componentes básicos
del entorno de escritorio Xfce, el paquete a instalar debe ser xfce4. Asi que
sustiyendo el paquete anterior, el comando quedaría de la siguiente forma.
<code>$ sudo aptitude install x-window-system-core xdm xfce4</code>
Observación: Este paquete (xfce4) también se encuentra disponible en la
sección universe de los repositorios de ubuntu, en este último caso no es
necesario hacer uso de los repositorios de os-works, aunque como mencione
anteriormente, los repositorios de os-works pueden ofrecerle un paquete más
actualizado.
Iniciando Xfce
Finalmente en su directorio personal cree un fichero oculto .xsession.
<code>$ nano ~/.xsession</code>
El fichero .xsession debe contener lo siguiente:
<code>#!/bin/sh
exec /usr/bin/startxfce4</code>
Ahora, cada vez que vaya a iniciar sesión, lo hará en modo gráfico de manera
automática, si no desea reiniciar para ver los resultados, utilice el comando
startx.
Espero en los siguientes días ir informando acerca del desempeño de Ubuntu con el entorno de escritorio Xfce en una laptop de bajos recursos. Seguidamente espero poder exponer una instalación bastante ligera pero utilizando el entorno de escritorio Enligtenment.
Referencias
Proyecto Inclusión Digital
 Inclusión
Digital, es un estupendo proyecto que en principio ha sido promovido por la
Fundación Assis Gurgacz y por la Asesoria de Asuntos Comunitarios de la
Prefectura de Cascavel/Paraná, Brasil.
Inclusión
Digital, es un estupendo proyecto que en principio ha sido promovido por la
Fundación Assis Gurgacz y por la Asesoria de Asuntos Comunitarios de la
Prefectura de Cascavel/Paraná, Brasil.
¿En qué consiste el proyecto Inclusión Digital?
El proyecto consiste en un omnibus con doce (12) ordenadores, que recorrerá varios barrios de la ciudad, ofreciendo cursos de inclusión digital a personas de bajos recursos. En este momento se prevee ofertar cursos de Internet y OpenOffice.org en los turnos de la mañana y noche. En el espacio de la tarde se permitirá a quien lo desee el utilizar los ordenadores para navegar y utilizar OpenOffice.org, siempre estando acompañados por algún profesor o guía.
¿Qué distribución está implementando el proyecto Inclusión Digital?

La distribución que se está utilizando actualmente en los doce (12) ordenadores y en el servidor es Ubuntu Linux. Los doce (12) ordenadores están conectados al servidor (IBM 206 xSeries).
Según Daniel Kühl, quien trabaja para la Facultad Assis Gurgacz, localizada en Cascavel/Paraná, la distribución Ubuntu Linux cumple con los requerimientos del proyecto, puesto que brinda facilidad de uso y está orientada al usuario final.

Este proyecto cuenta con el apoyo del Gobierno Federal, lo cual nos hace pensar que el proyecto podría expandirse aún más. La idea en principio es poder brindar más de 3 omnibuses de este tipo, adicionalmente, se brindará especial atención a los trabajadores jóvenes y adultos, los cuales pueden certificarse en cursos IT y no solamente en cursos informática básica.
Un buen comienzo…
Este tipo de iniciativas hay que brindarles el mayor apoyo posible, solo espero que esta idea se extienda y se aplique en otros países, de este modo es posible que la brecha digital se reduzca, por supuesto, este indice de reducción dependerá del alcance y expansión que logren tener estos proyectos, por eso es tan importante el apoyo de los gobiernos nacionales, ya que estos últimos de una manera u otra pueden y deben brindar una infraestructura de telecomunicaciones e informática adecuada, como bien es sabido por todos, la brecha digital es una consecuencia social de un alcance político, este problema se refiere al la abrumadora diferencia socioeconómica entre las sociedades que poseen acceso a internet y aquellas que no, esto, de una manera u otra repercute en el acceso a ciertas Tecnologías de Información y Comunicación (TIC).
Un ejemplo claro que explica lo anterior es el acceso a documentos digitales, en muchos casos éstos poseen información más actualizada, adicionalmente al haber mayor existencia de este tipo de documentos tenemos distintas opciones, cualificar de cierta manera la objetividad y calidad de dichos documentos. De cierta manera no existen limitaciones como sucede en los documentos impresos, para ser más claro con este último argumento, hágase la siguiente pregunta: ¿Dónde cree que se sienta más limitado para conseguir documentos de cierto tipo?, ¿en la biblioteca pública de su ciudad (si existe) o en internet?.
Vía: Ubuntuforums.org.
COMO actualizar de manera segura su sistema
Antes de comenzar es importante hacer notar que esta guía se enfocará al mundo Debian GNU/Linux y sus derivadas, en donde por supuesto se incluye Ubuntu Linux. Después de hacer la breve aclaratoria podemos comenzar.
¿Es importante la firma de los paquetes?
La firma de los paquetes es una funcionalidad fundamental para evitar el posible cambio adrede en los ficheros binarios o fuentes distribuidos a través de sitios espejos (mirrors), de esta manera nos libramos de la posibilidad de un ataque man in the middle, el cual básicamente consiste en la intercepción de la comunicación entre el origen y el destino, el atacante puede leer, insertar y modificar los mensajes (en este caso particular, los ficheros) compartidos entre las partes sin que cada una de ellas se percate que la comunicación se ha visto comprometida.
Nuestro objetivo
Un sistema automatizado de actualización de paquetes, también es sumamente importante eliminar cualquier posibilidad de amenaza que pueda surgir al aprovecharse de la automatización del proceso de actualización, por ejemplo, debemos evitar a toda costa la distribución de troyanos que comprometarán la integridad de nuestros sistemas.
Un poco de historia…
No fue sino hasta la aparición de la versión 0.6 de la interfaz apt en donde se realiza la autenticación de ficheros binarios y fuentes de manera transparente haciendo uso de una Infraestructura de clave pública (en inglés, Public Key Infrastructure o PKI). La PKI se basa en el modelo GNU Privacy Guard (GnuPG) y se ofrece un enorme despliegue de keyservers internacionales.
Detectando la autenticidad de los paquetes
Como se menciono anteriormente desde la versión 0.6 de la interfaz apt se maneja de manera transparente el proceso de autentificación de los paquetes. Asi que vamos a hacer una prueba, voy a simular la instalación del paquete clamav.
$ sudo aptitude --simulate install clamav
Obteniendo por respuesta lo siguiente:
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado extendido
Inicializando el estado de los paquetes... Hecho
Se instalarán automáticamente los siguientes paquetes NUEVOS:
arj clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
Se instalarán los siguiente paquetes NUEVOS:
arj clamav clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
0 paquetes actualizados, 7 nuevos instalados, 0 para eliminar y 0 sin actualizar.
Necesito descargar 3248kB de ficheros. Después de desempaquetar se usarán 4193kB.
¿Quiere continuar? [Y/n/?] Y
The following packages are not AUTHENTICATED:
clamav clamav-freshclam clamav-base libclamav1
Do you want to continue? [y/N] N
Cancela.
Si nos fijamos bien en la respuesta anterior notaremos que ciertos paquetes no han podido ser autentificados. A partir de este punto es responsabilidad del administrador del sistema el instalar o no dichos paquetes, por supuesto, cada quien es responsable de sus acciones, yo prefiero declinar mi intento por el momento y asegurarme de la autenticidad de los paquetes, para luego proceder con la instalación normal.
Comienza la diversión
Ahora bien, vamos a mostrar la secuencia de comandos a seguir para agregar las llaves públicas dentro del keyring por defecto. Antes de entrar en detalle es importante aclarar que el ejemplo agregará la llave pública del grupo os-cillation, quienes se encargan de mantener paquetes para el entorno de escritorio Xfce (siempre actualizados y manera no-oficial) para la distribución Debian GNU/Linux (también sirven para sus derivadas, como por ejemplo Ubuntu Linux).
Importando la llave pública desde un servidor GPG
$ gpg --keyserver hkp://wwwkeys.eu.pgp.net --recv-keys 8AC2C0A6
El comando anterior simplemente importara la llave especificada (8AC2C0A6) desde el servidor con el cual se ha establecido la comunicación, el valor de la opción --keyserver sigue cierto formato, el cual es: esquema:[//]nombreservidor[:puerto], los valores ubicados entre corchetes son opcionales, cuando hablamos del esquema nos referimos al tipo de servidor, regularmente utilizaremos como esquema hkp para servidores HTTP o compatibles.
Si el comando anterior se ejecuto de manera correcta, el proceso nos arrojará una salida similar a la siguiente:
gpg: key 8AC2C0A6: public key "os-cillation Debian Package Repository
(Xfld Package Maintainer) <[email protected]>" imported
La instrucción anterior solamente variará de acuerdo al keyserver y la clave que deseemos importar. En www.pgp.net está disponible un buscador que le facilitará la obtención de los datos necesarios.
Exportando y añadiendo la llave pública
$ gpg --armor --export 8AC2C0A6 | sudo apt-key add -
Con el comando anterior procedemos a construir la salida en formato ASCII producto de la exportación de la llave especificada y a través del pipe capturamos la salida estándar y la utilizamos como entrada estándar en el comando apt-key add, el cual simplemente agregará una nueva llave a la lista de llaves confiables, dicha lista puede visualizarse al hacer uso del comando apt-key list.
Aunque parezca evidente la aclaratoria, recuerde que si usted no puede hacer uso de sudo, debe identificarse previamente como superusuario.
Finalmente…
Para finalizar recuerde que debe actualizar la lista de paquetes.
$ sudo aptitude update
Ahora podemos proceder a instalar los paquetes desde el repositorio que hemos añadido como fuente confiable.
aptitude, ¿aún no lo usas?
Si usted es de los que piensa que aptitude por ser simplemente un frontend de apt no puede aportar alguna ventaja al manejo óptimo de paquetes, trataré en lo posible en este artículo hacerle cambiar de parecer, o por lo menos mostrarle que en realidad aptitude si ofrece ciertas ventajas sobre apt.
La útil y avanzada herramienta que le permite manejar cómodamente los paquetes, apt (y dpkg) no lleva un registro (ni hace distinciones) de las aplicaciones que se instalan de manera explícita y las que se instalan de manera implícita por consecuencia del primer punto (es decir, para establecer la resolución de dependencias). Esta característica genera ciertos inconvenientes a la hora de desinstalar un paquete que posee dependencias que no son empleadas por otros programas, al momento de realizar la desinstalación lo más seguro es que no queden las cosas muy “limpias” en el sistema.
Un remedio que en principio puede servirle es hacer uso de deborphan (también puede hacer uso de orphaner, un frontend para deborphan); una herramienta de mayor potencia es debfoster, el primero de los mencionados busca librerias huérfanas (como se explico en un artículo anterior) y al pasarle estos resultados al apt-get remove se puede resolver de cierta manera el problema.
El problema de deborphan es que su campo de acción es limitado, por lo que la “limpieza” puede no ser muy buena del todo. En cambio debfoster si hace la distinción de la cual hablaba al principio de este artículo, los paquetes instalados de manera explícita y aquellos que son instalados de manera implícita para resolver las dependencias, por lo tanto debfoster eliminará no solamente las librerias huérfanas tal cual lo hace deborphan si no que también eliminará aquellos paquetes que fueron instalados de manera implícita y que actualmente ningún otro programa dependa de él, también serán eliminados en el caso en que se de una actualización y ya la dependencia no sea necesaria.
Ahora bien, se presenta otra alternativa, aptitude, este frontend de apt si recuerda las dependencias de un programa en particular, por lo que el proceso de remoción del programa se da correctamente. Ya anteriormente había mencionado que apt y dpkg no hacen distinción de las aplicaciones instaladas y Synaptic apenas lleva un histórico, esto en realidad no cumple con las espectativas para mantener un sistema bastante “limpio”.
Aparte de lo mencionado previamente, otra ventaja que he encontrado en la migración a aptitude es que tienes dos opciones de manejo, la linea de comandos, la cual ha sido mi elección desde el comienzo, debido a la similitud de los comandos con los de apt y porque consigo lo que deseo inmediatamente, la interfaz gráfica no me llama la atención, pero quizás a usted si le guste. Adicionalmente, aptitude maneja de manera más adecuada el sistema de dependencias.
Para lograr ejecutar la interfaz gráfica de aptitude simplemente debe hacer:
$ sudo aptitude
De verdad le recomiendo emplear aptitude como herramienta definitiva para el manejo de sus paquetes, primero, si es usuario habitual de apt, el cambio prácticamente no lo notará, me refiero al tema de la similitud de los comandos entre estas dos aplicaciones, segundo, no tendrá que estar buscando “remedios” para mantener limpio el sistema, aptitude lo hará todo por usted.
Creando un repositorio local
Planteamiento del Problema:
Mantener actualizada una laptop (u ordenador de escritorio) de bajos recursos, con varios años de uso, el caso que se presenta es que el laptop en cuestión posee solo un puerto para conexiones por modem de velocidades topes de 56kbps, lo anterior puede ser traumático al realizar actualizaciones del sistema.
Consideraciones:
Nos aprovecharemos del hecho de la disponibilidad de un puerto USB en el ordenador de bajos recursos, el cual nos facilita en estos tiempos el almacenamiento masivo de paquetes, en caso de no tener puerto USB, podemos recurrir a unidades de CD como medio de almacenamiento masivo.
Adicionalmente, aprovecharemos conexiones de gran bando de ancha, lo cual nos facilitará la descarga de los paquetes necesarios desde los repositorios disponibles en la red.
Posible solución:
Después de plantear las consideraciones anteriores, una posible alternativa para mantener actualizados nuestros ordenadores de bajos recursos es utilizar dispositivos de almacenamiento masivo como repositorios locales, almacenando en ellos solo los paquetes que sean realmente necesarios.
En los siguientes puntos trataré de ampliar la manera de crear un repositorio local valiéndonos del uso de un Pen Drive.
Comenzamos:
En primer lugar vamos a respaldar los paquetes *.deb que se ubican en /var/cache/apt/archives, esta actividad la vamos a realizar en el ordenador que dispone de una conexión banda ancha.
$ mkdir $HOME/backup
$ sudo cp /var/cache/apt/archives/*.deb $HOME/backup
Después de respaldar los paquetes, vamos a remover todos los ficheros *.deb que han sido descargados al directorio cache que almacena los paquetes, usualmente esto quiere decir, eliminar todos los paquetes *.deb ubicados en /var/cache/apt/archives, para ello hacemos lo siguiente:
$ sudo aptitude clean
Ahora que se encuentra limpio el directorio cache procederemos a descargar (sin instalar) los paquetes que sean necesarios para nuestro ordenador de bajos recursos. Para ello hacemos lo siguiente:
$ sudo aptitude -d install <paquetes>
El comando anterior simplemente descargará la lista de paquetes especificada
(recuerde que debe sustituir
Para trabajar mas cómodamente crearemos una carpeta temporal y desde allí procederemos a crear nuestro repositorio local en cuestión, el cual finalmente se guardará en el medio de almacenamiento masivo correspondiente.
$ mkdir /tmp/debs
$ mv /var/cache/apt/archives/*.deb /tmp/debs/
$ cd /tmp
Estando ubicados en el directorio /tmp realizaremos una revisión de los paquetes que se ubican en el directorio debs/ y crearemos el fichero comprimido Packages.gz (el nombre del fichero debe ser exacto, no es cuestión de elección personal).
$ dpkg-scanpackages debs/.* | gzip > debs/Packages.gz
Guardando el repositorio en un dispositivo de almacenamiento masivo
En nuestro caso procederé a explicar como almacenar el repositorio en un Pen Drive, por ciertas cuestiones prácticas, primero, facilidad de movilidad que presentan, la capacidad de almacenamiento, la cual regularmente es mayor a la de un CD.
En la versión actual (Hoary) de Ubuntu Linux los Pen Drive son montados automáticamente, si esto no ocurre, puede realizar lo siguiente:
$ sudo mount -t vfat /dev/sda1 /media/usbdisk
Recuerde ajustar los argumentos de acuerdo a sus posibilidades. Luego de montado el dispositivo de almacenamiento masivo proceda a copiar de manera recursiva el directorio debs/.
$ cp -r /tmp/debs/ /media/usbdisk
Estableciendo el medio de almacenamiento masivo como un repositorio.
Si ha decidido utilizar un Pen Drive como medio de almacenamiento.
Después de copiar los ficheros en el medio de almacenamiento masivo, proceda a
desmontarlo (en nuestro caso: $ sudo umount /media/usbdisk) y conectelo a su
ordenador de bajos recursos, recuerde que si el ordenador de bajos recursos no
monta automáticamente el dispositivo, debe montarlo manualmente como se explico
anteriormente.
Después de haber sido reconocido el dispositivo de almacenamiento masivo en el ordenador de bajos recursos proceda a editar el fichero /etc/apt/sources.list y agregue la linea deb file:/media/usbdisk debs/. Comente los demás repositorios existentes, recuerde que para ello simplemente debe agregar el carácter almohadilla (#) al principio de la linea que especifica a dicho repositorio.
Si ha decidido utilizar un CD como medio de almacenamiento
Simplemente haciendo uso de apt-cdrom add le bastará, esto añadirá el medio a
la lista de recursos del fichero sources.list
Finalizando…
Para finalizar deberá actualizar la lista de paquetes disponibles y proceder con la instalación de dichos paquetes en el ordenador de bajos recursos, para ello, simplemente bastará con hacer lo siguiente:
$ sudo aptitude update
$ sudo aptitude install <paquetes>
Recuerde restaurar en el ordenador que dispone de conexión banda ancha los paquetes que se respaldaron previamente.
$ sudo mv $HOME/backup/*.deb /var/cache/apt/archives/
¡Que lo disfrute! :D
Organizando nuestros proyectos web
Antes de plantearme el rediseño de este sitio, pensé en organizar ciertas cosas para no complicarme la vida. En primera instancia procedi a instalar el servidor Apache, el soporte del lenguaje PHP, el servidor de bases de datos MySQL y finalmente el phpMyAdmin.
Lo anterior se resume de la siguiente manera en mi querido Ubuntu Linux.
$ sudo aptitude install apache2
$ sudo aptitude install mysql-server
$ sudo aptitude install php4
$ sudo aptitude install libapache2-mod-auth-mysql
$ sudo aptitude install php4-mysql
$ sudo /etc/init.d/apache2 restart
$ sudo aptitude install phpmyadmin
Recuerde después de instalar el servidor de bases de datos MySQL establecer la contraseña del usuario root de dicho servidor por seguridad. Si no sabe como hacerlo a través de la línea de comandos existe la alternativa de establecer la contraseña utilizando phpMyAdmin.
Por defecto el servidor Apache habilita el directorio /var/www/ como directorio principal, el problema que se plantearía el trabajar en dicho directorio es que cada vez que tuviese que realizar cambios a los ficheros tendría que hacer uso de la cuenta de superusuario o root, lo cual no me agrada mucho, así que para evitar lo mencionado previamente tenía dos opciones.
La primera de ellas era modificar el fichero /etc/apache2/apache.conf y habilitar que todos los usuarios tuviesen la posibilidad de publicar sus documentos dentro del directorio /home/*/public_html, esta opción no me llamaba mucho la atención, adicionalmente, la dirección queda de cierta manera algo extensa (p.ej. http://localhost/~usuario/proyectoweb), así que opte por recurrir a una segunda opción, la cual describiré detalladamente a continuación.
En primera instancia creé dos directorios, public_html como subdirectorio de $HOME, el segundo, milmazz como subdirectorio de public_html.
$ mkdir $HOME/public_html
$ mkdir $HOME/public_html/milmazz
Seguidamente procedi a crear el fichero /etc/apache2/sites-enabled/001-milmazz, este fichero contendrá las directivas necesarias para nuestro proyecto desarrollado en un ambiente local.
<VirtualHost *>
DocumentRoot "/home/milmazz/public_html/milmazz/"
ServerName milmazz.desktop
<Directory "/home/milmazz/public_html/milmazz/">
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order deny,allow
Deny from all
Allow from 127.0.0.0/255.0.0.0 ::1/128
</Directory>
</VirtualHost>
Ahora bien, necesitamos crear el host para que la directiva realmente redireccione al directorio /home/milmazz/public_html/milmazz/ simplemente tecleando milmazz.desktop en la barra de direcciones de nuestro navegador preferido. Por lo tanto, el siguiente paso es editar el fichero /etc/hosts y agregar una línea similar a 127.0.0.1 milmazz.desktop, note que el segundo parámetro especificado es exactamente igual al especificado en la directiva ServerName.
Seguidamente procedi a instalar WordPress (Sistema Manejador de Contenidos) en el directorio $HOME/public_html/milmazz y todo funciona de maravilla.
Evitando el acceso de usuarios no permitidos
Si queremos restringir aún más el acceso al directorio que contendrá los ficheros de nuestro proyecto web, en este ejemplo, el directorio es $HOME/public_html/milmazz/, realizaremos lo siguiente:
$ touch $HOME/public_html/milmazz/.htaccess
$ nano $HOME/public_html/milmazz/.htaccess
Dentro del fichero .htaccess insertamos las siguientes lineas.
AuthUserFile /var/www/.htpasswd
AuthGroupFile /dev/null
AuthName "Acceso Restringido"
AuthType Basic
require valid-user
Guardamos los cambios realizados y seguidamente procederemos a crear el fichero que contendrá la información acerca de los usuarios que tendrán acceso al directorio protegido, también se especificaran las contraseñas para validar la entrada. El fichero a editar vendra dado por la directiva AuthUserFile, por lo tanto, en nuestro caso el fichero a crear será /var/www/.htpasswd.
htpasswd -c /var/www/.htpasswd milmazz
Seguidamente introducimos la contraseña que se le asignará al usuario milmazz, la opción -c mostrada en el código anterior simplemente se utiliza para crear el fichero /var/www/.htpasswd, por lo tanto, cuando se vaya a autorizar a otro usuario cualquiera la opción -c debe ser ignorada.
Estableciendo la contraseña del usuario root del servidor de bases de datos a través de phpMyAdmin.
Si usted no sabe como establecer en línea de comandos la contraseña del usuario root en el servidor de bases de datos MySQL es posible establecerla en modo gráfico haciendo uso de phpMyAdmin.
A continuacion se describen los pasos que deberá seguir:
- Acceder a la interfaz del phpMyAdmin, para lograrlo escribe en la barra de direcciones de tu navegador http://localhost/phpmyadmin.
- Selecciona la opción de Privilegios, ésta se ubica en el menú principal.
- Debemos editar los dos últimos registros, uno representa el superusuario cuyo valor en el campo servidor será equivalente al nombre de tu máquina, el otro registro a editar es aquel superusuario cuyo valor en el campo servidor es igual a localhost. Para editar los registros mencionados anteriormente simplemente deberá presionar sobre la imagen que representa un lapíz.
- Los únicos campos que modificaremos de los registros mencionados previamente son aquellos que tienen relación con la contraseña. Recuerde que para guardar los cambios realizados al final debe presionar el botón Continúe. Si deseas evitar cualquier confusión en cuanto al tema de las contraseñas es recomendable que establezcas la misma en ambos registros.
Agradecimientos
A José Parella por sus valiosas indicaciones.
Instalar JAVA en Ubuntu
Debido a diversos motivos que no se expondrán en este artículo me he visto obligado a desarrollar ciertas aplicaciones en JAVA, por todos es bien sabido que JAVA es un formato restrictivo, a pesar del formato abierto del API en sí, hasta ahora las únicas implementaciones de JAVA en GNU/Linux con una amplia compatibilidad se derivan de la implementación de Sun Microsystem, ésta implementación lleva consigo términos de licencias no libres.
A pesar de la existencia de proyectos que buscan crear implementaciones libres de JAVA, estos aún no son comparables en rendimiento, acabado y compatibilidad con la implementación de Sun Microsystem.
Estos proyectos son:
Así que procederé a describir el método más elegante que he encontrado hasta ahora para instalar la implementación de JAVA de Sun Microsystem.
Obtenga la versión más reciente del fichero binario desde la página de descargas de Sun. Seleccione cualquiera de los enlaces de acuerdo a sus necesidades, ya sea para JDK o JRE. Recuerde que JDK soporta la creación de aplicaciones para plataforma de desarrollo J2SE, es decir, ideal para desarrolladores, mientras que JRE permite a los usuarios finales ejecutar aplicaciones JAVA.
Una vez culminada la descarga, ejecute las siguientes sentencias:
$ sudo apt-get install java-package fakeroot
$ fakeroot make-jpkg jdk-1_5_0_02-linux-i586.bin
$ sudo dpkg -i sun-j2sdk1.5_1.5.0+update02_i386.deb
Es importante aclarar que en las sentencias anteriores se asume que el paquete descargado ha sido el jdk-1_5_0_02-linux-i586.bin, evidentemente usted debe sustituir el nombre del paquete por el cual corresponda.
Si desea verificar la correcta instalación de JAVA, proceda de la siguiente manera:
$ java -version
Después de la sentencia anterior usted debe recibir un mensaje similar al siguiente:
java version "1.5.0_02"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_02-b09)
Java HotSpot(TM) Client VM (build 1.5.0_02-b09, mixed mode, sharing)
Lo anterior solo ha sido probado bajo Ubuntu Linux versión Hoary y Breezy. Una pequeña nota antes de culminar, en el caso de aparecerle el mensaje /java-web-start.applications: Permission denied mientras contruye el paquete .deb, no tiene mayor relevancia, puede ser ignorado.
Nota para los usuario de Breezy
Si al ejecutar el comando java -version obtiene algo similar a lo mostrado a continuación:
$ java -version
java version "1.4.2"
gij (GNU libgcj) version 4.0.2 20050808 (prerelease) (Ubuntu 4.0.1-4ubuntu9)
Copyright (C) 2005 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
No se preocupe, simplemente cambie la versión de JAVA por omisión, para ello lea el artículo Como cambiar entre versiones de JAVA bajo Breezy.
Referencias:
- Trampa JAVA (español)
- JAVA, Formato Restrictivo (inglés)
- Instalando Java 1.5 (inglés)
Smeg, simple editor del menú para GNOME
Smeg, es un simple editor del menú para Gnome. Esta herramienta le permitirá agregar entradas al menú de opciones, de igual manera podrá ordenarlo, agregar separadores, hasta editar el menú de aplicaciones de superusuario. Smeg aún no ofrece soporte completo para los entornos de escritorio KDE y XFCE.
Para los usuarios de Ubuntu Linux (versión
Hoary) se encuentra disponible un script que realizará la instalación de
Smeg de manera automática.
También puede hacer uso del .deb más reciente para Smeg. Si usted no utiliza Ubuntu
Linux, no se preocupe, Smeg también está disponible en
.tar.gz, lo cual le
facilitará la instalación en otras distribuciones.
Los usuarios de Gentoo ya pueden hacer uso de Smeg vía portage.
En Ubuntu Forums podrá discutir todo lo relacionado con éste editor del menú en la sección exclusiva para Smeg.
KDE 3.4.1 disponible en Kubuntu
KDE 3.4.1 ahora está disponible en
Kubuntu, distribución que integra todas las
características de Ubuntu Linux, pero está basada en el entorno de escritorio
KDE. Puedes descargar los paquetes necesarios al agregar al fichero
/etc/apt/sources.list el siguiente repositorio.
<code>deb http://kubuntu.org/hoary-kde341 hoary-updates main</code>
Tienes a disposición otra alternativa.
<code>deb http://download.kde.org/stable/3.4.1/kubuntu hoary-updates main</code>
Estos paquetes también están disponibles para la versión en desarrollo Breezy.
Guía Ubuntu Hoary Hedgedog
Sergio Blanco Cuaresma (actual presidente de la Asociación GPL Tarragona) ha publicado una guía orientada al uso de Ubuntu Hoary Hedgehog (5.04). No quería recomendar el recurso hasta haberlo leido completamente, como ya lo he hecho, tengo que decir que en realidad es una referencia en cuanto al tema para todos aquellos usuarios que recien comienzan con esta distribución, las explicaciones son bastante detalladas y sencillas, el autor evita hacer uso del lenguaje técnico, lo cual disminuye la posibilidad de generar en algunas ocasiones confusiones al lector. La guía está protegida por la licencia Creative Commons, bajo la rama: Reconocimiento, No Comercial, Compartir Igual. Podrá encontrar mayor información acerca de las especificaciones de la licencia en el resumen legible del texto legal en castellano.
El autor presenta una breve introducción a la historia del Software Libre, tanto las ventajas y desventajas de este modelo frente al propuesto por el modelo del software privativo, hace algunas distinciones entre los puntos de vista de la OSI y la FSF, se hace mención de otros tipos de licencias en el transcurso de la guía. Si aún no instala Ubuntu, le recomiendo que mientras lo va instalando puede aprovechar el tiempo de espera leyendo esta parte de la guía.
Posteriormente se describe los origenes de las distribución Ubuntu Linux y su filosofia, las arquitecturas que soporta, el uso de Ubuntu LiveCD, seguidamente se describe paso a paso la instalación de Ubuntu Linux en el disco duro.
Siguiendo con la temática, el autor describe de manera muy detallada todos y cada uno de los componentes del escritorio GNOME en Ubuntu, comenzando por los paneles inferior y superior y seguidamente se adentra en la descripción de cada una de las funciones de las distintas opciones en el menú principal.
Desde mi punto de vista las explicaciones dadas en el tema Gestor de paquetes Synaptic son excelentes, considero que hasta para un usuario no iniciado en el mundo GNU/Linux será comprensible esta sección. La sección de Aplicaciones es igualmente recomendable.
La guía de Ubuntu Linux Hoary Hedgehog (5.04) la puede encontrar en la sección de publicaciones de Marble Station.
Beagle
Beagle es una poderosa herramienta de búsqueda escrita en C# usando Mono y Gtk# que le permitirá buscar hasta en lo más recóndito de su espacio personal y de esta manera encontrar lo que está buscando. Beagle también puede buscar en distintos dominios.
Usando Beagle ud. fácilmente podrá encontrar.
- Documentos.
- Correos electrónicos.
- Historial web.
- Conversaciones de Mensajería Instantánea o del IRC.
- Código fuente.
- Imagénes.
- Ficheros de audio.
- Aplicaciones.
- Otros…
Beagle puede extraer información desde:
- Evolution, tanto los correos electrónicos como de la libreta de contactos.
- Gaim, desde los registros de mensajería instantánea.
- Firefox, páginas web.
- Blam y Liferea, agregadores RSS.
- Tomboy, notas.
De manera adicional Beagle soporta los siguientes formatos.
- OpenOffice.org
- Microsoft Office (
doc,ppt,xls). - HTML.
- PDF.
- Imágenes (jpeg, png).
- Audio (mp3, ogg, flac).
- AbiWord.
- Rich Text Format (RTF).
- Texinfo.
- Páginas del manual (man pages).
- Código Fuente (C, C++, C#, Fortran, Java, JavaScript, Pascal, Perl, PHP, Python).
- Texto sin formato.
Beagle aún se encuentra en una etapa temprana de desarrollo, así que aún faltan muchas características que le darían un plus a esta herramienta, por ejemplo, agregar el soporte a los sistemas de ficheros: NFS, Reiser4, NTFS y FAT.
En el caso de los sistemas de ficheros tipo FAT, muchos usuarios aún emplean este tipo de particiones para compartir datos entre los mundos GNU/Linux y Windows, por lo que sería conveniente el hecho de agregar esta funcionalidad a esta estupenda herramienta.
Si desea comenzar con esta herramienta, le recomiendo leer los primeros pasos del wiki de Beagle. A los usuarios de Ubuntu Linux le recomiendo la serie de pasos mostrados en el tema ¿Cómo instalar el buscador Beagle? de guia-ubuntu.org.
Existen algunas demostraciones sobre el uso de Beagle, propuestas por Nat Friedman, en una de ellas se podrá apreciar la funcionalidad de “búsqueda en vivo”, para ello es necesario activar el soporte de Inotify.
Inotify es un sistema de notificación de ficheros para el núcleo (kernel) de Linux. Actualmente esta característica no es incluida en la serie estable del núcleo de Linux, por lo que es muy probable que deba añadir esta característica al núcleo por si solo para poder utilizarlo. Existen algunas versiones del núcleo para distribuciones que si incluyen el soporte a Inotify.
Beagle como tal no requiere de Inotify para funcionar, solamente se recomienda su uso puesto que mejora la experiencia del usuario. Sin el soporte de Inotify, Beagle no podrá detectar automáticamente (en vivo) todos los cambios en su directorio personal, por lo que no podrá indexar los datos de manera oportuna.
De manera oportuna, los usuarios de Ubuntu Linux tienen cierta ventaja, no será necesario reparar el núcleo ni compilarlo, solamente hay que añadir la opción de Inotify en el fichero de configuración de Grub, de la manera siguiente:
$ sudo vi /boot/grub/menu.lst
title Ubuntu, kernel 2.6.10-5-k7
root (hd0,5)
kernel /vmlinuz-2.6.10-5-k7 root=/dev/hda8 ro quiet splash <strong>inotify</strong>
initrd /initrd.img-2.6.10-5-k7
savedefault
boot
Luego de hacer los cambios al fichero de configuración del gestor de arranque Grub, procedemos a actualizarlo.
$ sudo update-grub
Si utilizas Firefox y deseas que Beagle indexe las páginas que vas navegando, seguramente desearás instalar esta extensión.
¿Es necesario activar la cuenta root en Ubuntu?
Los desarrolladores de Ubuntu Linux en un principio querían que el proceso de instalación fuese lo más fácil posible, el hecho de desactivar de manera predeterminada la cuenta de usuario root permitía obviar algunos pasos en el proceso de instalación. Esto para muchos es un inconveniente, pues Ubuntu Linux “difiere” en cuanto al modelo de seguridad que se maneja comúnmente en sistemas GNU/Linux, el modelo que plantea Ubuntu Linux es simplemente no recomendar hacer uso extensivo del usuario root (por eso ha desactivado la cuenta). Debido a que esta distribución está orientada hacia usuarios que quizás no han tenido un contacto extenso con sistemas GNU/Linux, el modelo propuesto me parece bastante lógico.
Por supuesto, este modelo presenta ventajas y desventajas, desde mi punto de vista son más ventajas que desventajas, ¿por qué?, a continuación detallo mis argumentos.
- Ubuntu Linux está orientada hacia usuarios finales que no han tenido tanto contacto con el mundo GNU/Linux, seguramente estos nuevos usuarios no están adaptados al modelo de seguridad que se maneja en estos sistemas, por lo que seguramente se generen más olvidos a la hora de recordar la contraseña que se utiliza para fines administrativos, puesto que esta cuenta es pocas veces usadas por ellos. Con el uso de sudo (Super User DO) esto no pasa, puesto que se maneja la misma contraseña del usuario principal (o aquellos que estén autorizados) para fines administrativos.
- Seguramente el hecho de introducir la contraseña para realizar cambios administrativos te detenga a pensar en lo que estas haciendo realmente, lo cual puede reducir la tasa de errores en la administración del sistema.
- Puedes ver un registro de las actividades que se realizan con el comando
sudoen/var/log/auth.log, lo cual puede ayudar a administrar tu sistema eficientemente.
He escuchado argumentos de personas que dicen que el usar sudo es tedioso, puesto que debes introducir la constraseña a cada instante, eso no es cierto, la primera vez que introduzcas la contraseña, ésta se almacenará por quince (15) minutos, después de transcurrido ese tiempo y si necesitas hacer alguna actividad administrativa se te volverá a solicitar.
Quizás la mayor desventaja de este modelo es que el mantener una contraseña “diferente” para el superusuario existe mayor protección en el caso en que las contraseñas de los usuarios con derehos administrativos se vean comprometidas. Pero esto puede ser evitado al ponerle mayor cuidado a las cuentas de usuarios con derechos administrativos, la debilidad es allí y no en el modelo en cuestión.
Lo cierto es que el uso de sudo puede considerarse para ejecutar pocos comandos administrativos, mientras que su generalmente es utilizado para ejecutar múltiples tareas administrativas, el problema es que su puede dejar “abierta” indefinidamente una shell con derechos de superusuario, esto último es un gran inconveniente para la seguridad del sistema. En cambio sudo limita estas cosas, como se menciono anteriormente, al menos tienes quince (15) minutos de derechos de superusuario.
Si a pesar de lo que he mencionado hasta ahora, ud. considera conveniente activar la cuenta de superusuario en Ubuntu Linux, aca está la serie de pasos que deberá seguir:
- sudo passwd root
- Cambiar la configuración de sudo, para evitar que el usuario principal haga uso de él, este paso puede ser opcional, aunque es recomendable hacerlo si realmente se desea hacer la “separación” a la cual estamos acostumbrados en los sistemas GNU/Linux.
- Cambiar las entradas del menú que hacen uso de
gksudo(comúnmente aquellas aplicaciones con fines administrativos) porgksu, para que realmente pidan la contraseña de root y no la del usuario principal.
Como conclusión, desde mi punto de vista considero innecesario tomarse tantas molestias para activar al usuario root en Ubuntu Linux cuando el mecanismo propuesto (sudo) funciona perfectamente.
deborphan, eliminando librerias huérfanas
deborphan simplemente se encarga de buscar librerias huérfanas. Se mostrará un listado de paquetes que posiblemente no fueron desinstalados en su momento y que actualmente no son requeridas en el sistema por ningún otro paquete o aplicación. Esta aplicación es realmente útil para mantener “limpio” el sistema en caso de ser necesario.
Para instalar deborphan en nuestro sistema simplemente debe proceder como sigue:
sudo apt-get install deborphan
Para remover todos los paquetes huérfanos encontrados simplemente debemos proceder como sigue:
sudo deborphan | sudo xargs apt-get remove -y
Esta aplicación me ha sido realmente útil, sobretodo por la reciente actualización que he realizado en la versión mi distribución Ubuntu Linux, la versión anterior era Warty Warthog (v.4.10), la nueva es Hoary Hedgehog (v.5.04). En dicha actualización ocurrieron muchos “rompimientos” de dependencias, muchas librerias quedaron huérfanas, con esta aplicación he depurado el sistema.
GNU/Linux
Fortaleciendo nuestras contraseñas
Si una de las promesas que tiene para este cierre de año es fortalecer las
contraseñas en sus equipos personales, cambiarlas mensualmente y no repetir la
misma contraseña en al menos doce cambios. En este artículo se le explicará como
hacerlo sin tener que invertir una uva en ello, todo esto gracias al paquete
libpam-cracklib en Debian, el procedimiento mostrado debe aplicarse a otras
distribuciones derivadas de Debian.
Pareciese lógico que algunas de las mejores prácticas para el fortalecimiento de las contraseñas son las siguientes:
- Cambiar las contraseñas periódicamente.
- Establecer una longitud mínima en las contraseñas.
- Establecer buenas reglas para las nuevas contraseñas, es decir, mezcla entre letras mayúsculas, minúsculas, dígitos y caracteres alfanuméricos.
- Mantener un histórico de las contraseñas usadas previamente, de ese modo, alentamos a los usuarios establecer nuevas contraseñas.
- Indicarle a los usuarios que es inaudito que se anoten las contraseñas en un post-it y se dejen pegadas en los monitores o incluso en las gavetas de sus archivadores.
El primer paso es instalar el paquete libpam-cracklib
# apt-get install libpam-cracklib
A partir de la versión 1.0.1-6 de PAM se recomienda manejar la configuración vía
pam-auth-update. Por lo tanto, por favor tome un momento y lea la sección 8
del manual del comando pam-auth-update para aclarar su uso y ventajas.
$ man 8 pam-auth-update
Ahora establezca una configuración similar a la siguiente, vamos primero con la
exigencia en la fortaleza de las contraseñas, para ello edite o cree el fichero
/usr/share/pam-configs/cracklib.
Name: Cracklib password strength checking
Default: yes
Priority: 1024
Conflicts: unix-zany
Password-Type: Primary
Password:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
Password-Initial:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
NOTA: Le recomiendo leer la sección 8 del manual de pam_cracklib para
encontrar un mayor numero de opciones de configuración. Esto es solo un ejemplo.
En versiones previas el modulo pam_cracklib hacia uso del fichero
/etc/security/opasswd para conocer si la propuesta de cambio de contraseña no
había sido utilizada previamente. Dicha funcionalidad ahora corresponde al nuevo
modulo pam_pwhistory
Definamos el funcionamiento de pam_pwhistory a través del fichero
/usr/share/pam-configs/history.
Name: PAM module to remember last passwords
Default: yes
Priority: 1023
Password-Type: Primary
Password:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
Password-Initial:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
NOTA: Para mayor detalle de las opciones puede revisar la sección 8 del
manual de pam_pwhistory
Seguidamente proceda a actualizar la configuración de PAM vía pam-auth-update.

Una vez cubierta la fortaleza de las contraseñas nuevas y de evitar la reutilización de las ultimas 12, de acuerdo al ejemplo mostrado, resta cubrir la definición de los periodos de cambio de las contraseñas.
Para futuros usuarios debemos ajustar ciertos valores en el fichero
/etc/login.defs
#
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 30
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Las reglas previas no aplicaran para los usuarios existentes, pero para este
tipo de usuarios podremos hacer uso del comando chage de la siguiente manera:
# chage -m 0 -M 30 -W 5 ${user}
Donde el valor de ${user} debe ser reemplazo por el username.
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Recuperando una antigua Logitech Quickcam Express
No se porque motivo o razón comencé a revisar en unas cajas de mi cuarto, cuando de repente me encontré con la primera cámara web que compre, de hecho, vino como accesorio a mi máquina de escritorio Compaq Presario 5006LA. Así que me pregunté, ¿será que todavía funciona esta reliquia?.
Lo primero que hice fue conectar el dispositivo en cuestión a mi portátil actual, enseguida ejecuté el comando:
$ lsusb | grep -i logitech
Bus 002 Device 002: ID 046d:0840 Logitech, Inc. QuickCam Express</code>
Una vez conocido el PCI ID (046d:0840) del dispositivo realicé una búsqueda rápida en Google y llegué a un sitio muy interesante, en donde podemos obtener una descripción de los dispositivos USB para Linux, al usar la función de búsqueda en la base de datos del sitio mencionado previamente ingreso el dato correspondiente al Vendor ID (en mi caso, 046d), posteriormente filtre los resultados por el Product ID (en mi caso, 0840), sentía que ya estaba dando con la solución a mi problema, había encontrado información detallada acerca de mi Logitech Quickcam Express. Al llegar acá descubrí el Linux QuickCam USB Web Camera Driver Project.
En la página principal del Linux QuickCam USB Web Camera Driver Project observo que mi vejestorio de cámara es soportada por el driver qc-usb.
Con la información anterior decido hacer uso del manejador de paquetes aptitude y en los resultados avisté el nombre de un paquete qc-usb-source, así que definitivamente nuestra salvación es module-assistant.
# aptitude install qc-usb-source \\
build-essential \\
module-assistant \\
modconf \\
linux-headers-`uname -r`
# m-a update
# m-a prepare
# m-a a-i qc-usb
Una vez realizado el paso anterior recurro a la utilidad de configuración de módulos en Debian modconf e instalo el módulo quickcam, el cual se encuentra en /lib/modules/2.6.18-4-686/misc/quickcam.ko y verificamos.
# tail /var/log/messages
May 14 21:16:57 localhost kernel: Linux video capture interface: v2.00
May 14 21:16:57 localhost kernel: quickcam: QuickCam USB camera found (driver version QuickCam USB 0.6.6 $Date: 2006/11/04 08:38:14 $)
May 14 21:16:57 localhost kernel: quickcam: Kernel:2.6.18-4-686 bus:2 class:FF subclass:FF vendor:046D product:0840
May 14 21:16:57 localhost kernel: quickcam: Sensor HDCS-1000/1100 detected
May 14 21:16:57 localhost kernel: quickcam: Registered device: /dev/video0
May 14 21:16:57 localhost kernel: usbcore: registered new driver quickcam
Como puede observarse el dispositivo es reconocido y se ha registrado en /dev/video0. En este instante que poseemos los módulos del driver qc-sub para nuestro kernel, podemos instalar la utilidad qc-usb-utils, esta utilidad nos permitirá modificar los parámetros de nuestra Logitech QuickCam Express.
# aptitude install qc-usb-utils
Ahora podemos hacer una prueba rápida de nuestra cámara, comienza la diversión, juguemos un poco con mplayer.
$ mplayer tv:// -tv driver=v4l:width=352:height=288:outfmt=rgb24:device=/dev/video0:noaudio -flip
A partir de ahora podemos probar más aplicaciones ;)
Network Manager: Facilitando el manejo de redes inalámbricas
 En la entrada previa, Establecer red inalámbrica en Dell m1210, comencé a describir el proceso que seguí para lograr hacer funcionar la tarjeta Broadcom Corporation Dell Wireless 1390 WLAN Mini-PCI Card (rev 01) en una portátil Dell m1210. El motivo de esta entrada se debe a que muchos usuarios hoy día no les interesa ni debe interesarles estar lidiando con la detección de redes inalámbricas, por eso les pasaré a comentar acerca de NetworkManager.
En la entrada previa, Establecer red inalámbrica en Dell m1210, comencé a describir el proceso que seguí para lograr hacer funcionar la tarjeta Broadcom Corporation Dell Wireless 1390 WLAN Mini-PCI Card (rev 01) en una portátil Dell m1210. El motivo de esta entrada se debe a que muchos usuarios hoy día no les interesa ni debe interesarles estar lidiando con la detección de redes inalámbricas, por eso les pasaré a comentar acerca de NetworkManager.
NetworkManager es una aplicación cuyo objetivo es que el usuario nunca tenga que lidiar con la línea de comandos o la edición de ficheros de configuración para manejar sus redes (ya sea cableada o inalámbrica), haciendo que la detección de dichas redes simplemente funcione tanto como se pueda y que interrumpa lo menos posible el flujo de trabajo del usuario. De manera que cuando usted se dirija a áreas en las cuales usted ha estado antes, NetworkManager se conectará automáticamente a la última red que haya escogido. Asimismo, cuando usted esté de vuelta al escritorio, NetworkManager cambiará a la red cableada más rápida y confiable.
Por los momentos, NetworkManager soporta redes cifradas WEP, el soporte para el cifrado WPA está contemplado para un futuro cercano. Respecto al soporte de VPN, NetworkManager soporta hasta ahora vpnc, aunque también está contemplado darle pronto soporte a otros clientes.
Para hacer funcionar NetworkManager en Debian los pasos que debemos seguir son los siguientes. En primera instancia instalamos el paquete.
# aptitude -r install network-manager-gnome
Que conste que NetworkManager funciona para entornos de escritorios como GNOME, KDE, XFCE, entre otros. En este caso particular estoy instalando el paquete disponible en Debian para GNOME en conjunto con sus recomendaciones.
De acuerdo al fichero /usr/share/doc/network-manager/README.Debian NetworkManager consiste en dos partes: uno a nivel del demonio del sistema que se encarga de manejar las conexiones y recoge información acerca de las nuevas redes. La otra parte es un applet que el usuario emplea para interactuar con el demonio de NetworkManager, dicha interacción se lleva a cabo a través de D-Bus.
En Debian por seguridad, los usuarios que necesiten conectarse al demonio de NetworkManager deben estar en el grupo netdev. Si usted desea agregar un usuario al grupo netdev utilice el comando adduser usuario netdev, luego de ello tendrá que recargar dbus haciendo uso del comando /etc/init.d/dbus reload.
Es necesario saber que NetworkManager manejará todos aquellos dispositivos que no estén listados en el fichero /etc/network/interfaces, o aquellos que estén listados en dicho fichero con la opción auto o dhcp, de esta manera usted puede establecer una configuración para un dispositivo que sea estática y puede estar seguro que NetworkManager no tratará de sobreescribir dicha configuración. Para mayor información le recomiendo leer detenidamente el fichero /usr/share/doc/network-manager/README.Debian.
Si usted desea que NetworkManager administre todas las interfaces posibles en su ordenador, lo más sencillo que puede hacer es dejar solo lo siguiente en el fichero /etc/network/interfaces.
$ cat /etc/network/interfaces
auto lo
iface lo inet loopback
Una vez que se ha modificado el fichero /etc/network/interfaces reiniciamos NetworkManager con el comando service network-manager restart. El programa ahora se encargará de detectar las redes inalámbricas disponibles. Para ver una lista de las redes disponibles, simplemente haga clic en el icono, tal como se muestra en la figura al principio de este artículo.
Había mencionado previamente que NetworkManager se conectará automáticamente a las redes de las cuales tiene conocimiento con anterioridad, pero usted necesitará conectarse manualmente a una red al menos una vez. Para ello, simplemente seleccione una red de la lista y NetworkManager automáticamente intentará conectarse. Si la red requiere una llave de cifrado, NetworkManager le mostrará un cuadro de dialogo en el cual le preguntará acerca de ella. Una vez ingresada la llave correcta, la conexión se establecerá.
Para cambiar entre redes, simplemente escoja otra red desde el menú que le ofrece el applet.
Establecer red inalámbrica en Dell m1210
Hace ya algunos días Ana me comentaba que no le estaba funcionando la configuración que tenía para su red inalámbrica, eso ocurrió una vez que actualizó la versión del kernel de linux, espero entrar en detalle acerca de los pasos que seguí para configurarle todo como se debe bajo Debian Etch.
Lo primero que debía saber era el tipo de componente PCI al que me estaba enfrentando.
$ lspci -nn | grep Wireless
0c:00.0 Network controller [0280]:
Broadcom Corporation Dell Wireless 1390
WLAN Mini-PCI Card [14e4:4311] (rev 01)
Lo anterior dice que nos estamos enfrentando ante una Broadcom cuyo chipset id es el 4311, debemos saber que el módulo para linux de estos chips es el bcm43xx y ha sido incluido al kernel de linux desde la versión 2.6.17-rc2Fuente: http://bcm43xx.berlios.de/, al revisar la lista de dispositivos soportados me percaté que el soporte para este chipset id aún es inestable, así que el siguiente paso era eliminar su presencia si aplicaba.
$ lsmod | grep bcm43xx
bcm43xx 148500 0
ieee80211softmac 40704 1 bcm43xx
ieee80211 39112 2 bcm43xx,ieee80211softmac
Como se puede observar en este caso aplica, así que comenzamos a eliminar su presencia.
# grep -q '^blacklist bcm43xx' /etc/modprobe.d/blacklist \\
|| tee -a 'blacklist bcm43xx' /etc/modprobe.d/blacklist
La inclusión de la línea blacklist bcm43xx al fichero /etc/modprobe.d/blacklist si aplica me permite indicar que dicho módulo no debe cargarse como resultado de la expansión de su alias, es decir, bcm43xx, esto se hace con el propósito de evitar que el subsistema hotplug lo carge, aunque esto no evita que el módulo se carge automáticamente por el kernel.
Luego verifique el fichero /etc/modules, el cual contiene los nombre de los módulos que serán cargados a la hora del inicio del sistema, no había entrada para el módulo bcm43xx, ahora es necesario remover dicho módulo, para lo cual hacemos:
# modprobe -r bcm43xx
Una vez culminado este proceso es necesario hacer uso de ndiswrapper, el cual es un módulo que me permite cargar y ejecutar drivers propietarios de Windows para tarjetas inalámbricas.
# aptitude -r install build-essential \\
module-assistant ndiswrapper-common
# m-a update
# m-a prepare
# m-a a-i ndiswrapper
# modprobe ndiswrapper
Una vez cargado el módulo ndiswrapper es necesario instalar el nuevo driver propietario, para ello debemos encontrar el fichero con extensión inf, este fichero especifica que ficheros necesitan estar presentes o descargarse para que el componente funcione correctamente, para dicho driver. Al consultar en la lista de tarjetas que funcionan con ndiswrapper me percato que han habido problemas de seguridad en algunos de los drivers recomendados para esta tarjeta, así que para asegurarme de obtener las versiones más recientes ingreso al sitio oficial de Dell, bajo la sección USA -> Support search: “m1210” -> Drivers and Downloads -> Network & Internet -> Network Driver, ingreso el campo correspondiente al service tag, y finalmente descargo el fichero R151517.EXE.
El siguiente paso es extraer los ficheros que se encuentran dentro de R151517.EXE, para ello:
unzip R151517.EXE
Ahora nos interesa el fichero bcmwl5.inf que está dentro del directorio DRIVER.
$ tree R151517/DRIVER/
R151517/DRIVER/
|-- bcm43xx.cat
|-- bcm43xx64.cat
|-- bcmwl5.inf
|-- bcmwl5.sys
`-- bcmwl564.sys
Una vez extraídos los ficheros, procedemos a cargar el driver, para ello hacemos lo siguiente:
# ndiswrapper -i R151517/DRIVER/bcmwl5.inf
Comprobamos que el driver se ha instalado correctamente.
# ndiswrapper -l
installed drivers:
bcmwl5 driver installed, hardware (14E4:4324) present (alternate driver: bcm43xx)
Luego verificamos nuestro trabajo al ejecutar el comando dmesg, tal como se muestra a continuación:
$ dmesg
[44093.473325] ndiswrapper version 1.27 loaded (preempt=no,smp=yes)
[44095.311236] ndiswrapper (link_pe_images:577): fixing KI_USER_SHARED_DATA address in the driver
[44093.482777] ndiswrapper: driver bcmwl5 (Broadcom,03/23/2006, 4.40.19.0) loaded
[44093.483250] ACPI: PCI Interrupt 0000:0c:00.0[A] -> GSI 17 (level, low) -> IRQ 177
[44093.483367] PCI: Setting latency timer of device 0000:0c:00.0 to 64
[44093.491760] ndiswrapper: using IRQ 177
[44094.162703] wlan0: vendor:
[44094.162708] wlan0: ethernet device 00:18:f3:6b:fc:3b using NDIS driver bcmwl5, 14E4:4311.5.conf
[44094.162772] wlan0: encryption modes supported: WEP; TKIP with WPA, WPA2, WPA2PSK; AES/CCMP with WPA, WPA2, WPA2PSK
[44094.166554] usbcore: registered new driver ndiswrapper
[44094.167390] ndiswrapper: changing interface name from 'wlan0' to 'eth1'
En este preciso instante el comando ifconfig -a debe mostrarnos la nueva interfaz, y el comando iwlist eth1 scan al ejecutarse como superusuario devolverá la lista de redes que han sido detectadas.
Recuerde que para que todo esto siga funcionando aún después de reiniciar el sistema, es necesario cargar el módulo de ndiswrapper, para ello hago uso del comando modconf.
*[PCI]: Peripheral Component Interconnect
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
Identificar el Hardware de tu PC en Debian GNU/Linux
Bien, lo que vamos a hacer a continuación es muy fácil, tán fácil como instalar un paquete, luego ejecutarlo y leer la información que él nos “escupe” (me encanta como suena :) ). Como sabrán, soy usuario de Debian GNU/Linux en su versión Etch para la arquitectura AMD64, pero ésto en realidad no es tan relevante ya que el paquete se encuentra tanto en Testing como en Stable para la mayoría de las arquitecturas y en la sección main de los repositorios.
Lo que vamos a instalar es el paquete lshw-gtk, que bien como dice en la descripción del paquete: “es una pequeña herramienta que provee información detallada de la configuración de hardware de la máquina. Puede reportar la configuración exacta de la memoria, versión de firmware, configuración de la tarjeta madre, versión del procesador y su velocidad, configuración de la caché, velocidad del bus, etc. en sistemas x86 con soporte DMI, en algunas máquinas PowerPC (se sabe de su funcionamiento en las PowerMac G4) y ADM64”.
Como ya sabrán, para instalar el paquete es tan sencillo como abrir una terminal y escribir en modo superusuario los siguiente:
# aptitude install lshw-gtk
El paquete no es muy pesado, de hecho, con todo y dependencias a penas ha de superar el mega de información, por lo que el proceso de instalación es rápido (si se tiene una conexión decente claro).
Una vez instalado el paquete no tenemos que hacer más que ejecutarlo. Para poder ejecutarlo debemos hacerlo desde una terminal, ya que según tengo entendido, no se instala en los menús del Gnome. Así que debemos escribir en una terminal (en modo superusuario):
# lshw-gtk
y listo, se ejecutará perfectamente, dejándonos navegar por unos paneles donde se encuentran los distintos componentes de nuestro sistema.
Si lo que quieres es tener un lanzador en los menús del Gnome, es muy sencillo, sólo deberás crear uno de la siguiente manera. Abre una terminal en modo superusuario y escribe lo siguiente:
gedit /usr/share/applications/LSHW.desktop
luego de presionar la tecla Enter se abrirá una ventana con el gedit en la cual deberás pegar el siguiente texto:
[Desktop Entry]
Name=LSHW
Comment=Identifica el hardware del sistema
Exec=gksu lshw-gtk
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya con eso deberías tener tu lanzador en el menú Aplicaciones –> Herramientas del sistema. Vas a necesitar de permisos de superusuario para poder ejecutarlo.
Acá una imagen de como se ve el lshw-gtk:
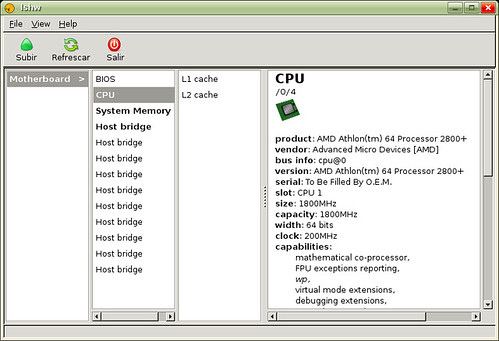
Creando un chroot en Etch AMD64
Bien la cosa es que tratando de instalar el Google Earth en mi Debian me he encontrado que no existe un paquete nativo para AMD64 (¿qué raro no?), por lo que me las he tenido que ingeniar para instalarlo. Nunca tuve la necesidad de hacer un chroot en el sistema ya que lo único que lo ameritaba era el Flash, pero no pensaba hacerme un chroot expresamente para el Flash y malgastar el espacio en mi disco, pero a la final siempre he tenido que hacerme uno!
Para aquellos que dominan el inglés se pueden leer el Debian GNU/Linux AMD64 HOW-TO ya que los pasos para crear el chroot los he seguido de ahí. Claro que para aquellos que no tengan mucho tiempo o no sientan la necesidad de hacer un chroot siempre existe una manera rápida de hacer funcionar las cosas en un apuro.
Para aquellos que todavía no saben qué es un chroot les recomiendo que le echen un ojo a la Guía de referencia Debian, de todas formas acá les cito textualmente de dicha guía lo que ellos definen como un chroot:
…el programa chroot, nos permite ejecutar diferentes instancias de un entorno GNU/Linux en un único sistema, simultáneamente y sin reiniciar…
El chroot en mi caso, está pensado para poder ejecutar aplicaciones a 32bits en un entorno 64 bits. El chroot es necesario ya que no se puede mezclar aplicaciones 32 bits con librerías 64 bits, por lo que se necesitan las librerías a 32 bits para correr dichas aplicaciones.
Lo que se hace en el chroot es instalar un sistema base para la arquitectura x86. Ésto lo puedes lograr haciendo en una terminal:
# debootstrap --arch i386 sid /var/chroot/sid-ia32 http://ftp.debian.org/debian/
…para lo cual, posiblemente, vas a necesitar el paquete debootstrap. Ahora bien, ¿qué hace el debootstrap?; debootstrap es usado para crear un sistema base debian from scratch (es algo como, desde la nada) sin tener que recurrir a la disponibilidad de dpkg ó aptitude. Todo ésto lo logra descargando los .deb de un servidor espejo y desempaquetándolos a un directorio, el cual, eventualmente sera utilizado con el comando ` chroot`. Por lo tanto la línea de comandos que introduciste anteriormente hace todo eso, sólo que lo vas a hacer para la rama unstable ó sid, en el directorio /var/chroot/sid-ia32 y desde el servidor espejo específicado.
El proceso anterior puede demorar según sea la velocidad de tu conexión. No pude saber cuánto demoro el proceso en mi caso porque cuando empecé a hacerlo eran altas horas de la madrugada y me quedé dormido :(. Lo que tienes que saber es que cuando éste proceso finalice, ya tendrás un sistema base x86 o 32 bits en un disco duro en el directorio /var/chroot/sid-ia32. Una vez finalizado deberías instalar algunas librerías adicionales, pero para hacerlo deberás moverte al chroot y hacerlo con aptitude:
# chroot /var/chroot/sid-ia32
…y luego instalas las librerías adicionales:
# aptitude install libx11-6
Para poder ejecutar aplicaciones dentro del chroot deberás tener también algunas partes del árbol de tu sistema 64 bits, lo cual puedes hacerlo mediante un montaje enlazado. El ejemplo a continuación, enlaza el directorio /tmp a el chroot para que éste pueda utilizar los “sockets” del X11, los cuales están en el /tmp de nuestro sistema 64 bits; y también enlaza el /home para que podamos accesarlo desde el chroot. También es aconsajable enlazar los directorios /dev, /proc y /sys. Para lograr ésto deberás editar tu fstab que se encuentra en /etc y añadir lo siguiente:
# sid32 chroot
/home /var/chroot/sid-ia32/home none bind 0 0
/tmp /var/chroot/sid-ia32/tmp none bind 0 0
/dev /var/chroot/sid-ia32/dev none bind 0 0
/proc /var/chroot/sid-ia32/proc none bind 0 0
…y luego montarlas:
# mount -a
Bien ya vamos llegando a final, unos cuántos pasos más y listo. Lo que necesitamos hacer a continuacióne es establecer los usuarios importantes en el chroot. La forma más rápida (sobretodo si tienes muchos usuarios) es copiar tus directorios /etc/passwd, /etc/shadow y /etc/group al chroot, a menos claro que quieras tomarte la molestia de añadirlos manualmente.
ADVERTENCIA! Cuando enlazas tu directorio /home al chroot, y borras éste último, todos tus datos personales se borrarán con éste, por consiguiente serán totalmente perdidos, por lo tanto debes recordar desmontar los enlaces antes de borrar el chroot.
Corriendo aplicaciones en el chroot
Después de hacer todos los pasos anteriores, ya deberías poder ejecutar aplicaciones desde el chroot. Para poder ejecutar aplicaciones desde el chroot debes hacer en una terminal (en modo root):
# chroot /var/chroot/sid-ia32
Luego deberás cambiarte al usuario con el que quieres ejecutar la aplicación:
# su - usuario
Establecer $DISPLAY:
# export DISPLAY=:0
Y finalmente ejecutar la aplicación que quieras, como por ejemplo, el firefox con el plugin de flash! Por supuesto deberás instalar la aplicación antes de ejecutarla, recuerda que lo que has instalado es un sistema base y algunas librerías adicionales.
Compilar aMSN en Debian Etch AMD64
Bien, sin mucho preámbulo, lo primero que debemos hacer es descargar el tarball de la página de amsn. Luego deberás descomprimirlo en la carpeta de tu preferencia, en mi caso está en ~/Sources/amsn-0.96RC1/. Una vez que lo descomprimes abre una terminal y obtén derechos de administrador (modo root); cuando tengas privilegios de root ubícate en el directorio donde descomprimiste el tarball y escribe lo siguiente:
$ ./configure
$ make
$ make install
Debes asegurarte de cumplir todos los requisitos cuando haces el ./configure, ya que te pide varias “dependencias” por así decirlo, como por ejemplo, tls y tk. Una vez que hayas hecho el make install quedará automágicamente instalado el amsn en tu sistema. Deberás poder verlo en Aplicaciones –> Internet –> aMSN. Bien eso es todo en lo que respecta al proceso de compilado, ¿nunca antes fué tan fácil verdad?.
Un problema que me dió una vez que lo compilé y lo ejecuté fué que no me permitía iniciar sesión porque me decía que no tenía instalado el módulo TLS. Entonces abrí una terminal e hice lo siguiente:
$ aptitude install tcltls
…pero ésto no me solucionó el problema, entonces me puse a indagar por la web y me encontré con la siguiente solución: editar el archivo /usr/lib/tls1.50/pkgIndex.tcl y ubicar la línea que dice algo como: package ifneeded tls 1.5 para entonces modificarla por package ifneeded tls 1.50 y listo :D
Smartmontools: aprendiendo a chequear tu disco duro…
Los discos duros modernos (y no tan modernos) vienen equipados con una tecnología conocida como S.M.A.R.T., el cual le permite al disco monitorear de manera contínua su propio estado de “salud” y alertar al usuario si es detectada alguna anormalidad, para que luego pueda ser corregida.
ADVERTENCIA: antes de continuar, sería recomendable hacer una copia de respaldo de todos sus datos importantes a pesar de todo lo que diga el S.M.A.R.T. Éste sistema es muy confiable pero no obstante, ésta información en alguno de los casos podría ser imprecisa, de hecho, los discos duro se dañan de manera inesperada, inclusive si el S.M.A.R.T te ha dicho que algo anda mal, posiblemente no tengas tiempo para respaldar tus datos o moverlos a un lugar más seguro.
¿Cómo instalar SMARTMONTOOLS?
Lo primero que debemos hacer, preferiblemente antes de instalar el SMT es chequear si nuestro disco duro soporta éste tipo de tecnología, lo cual puedes hacer visitando la página del fabricante de tu disco. De todas formas, si lo compraste después del año 1992, lo más seguro es que posea ésta tecnología.
Lo segundo, y no menos importante, es activar o asegurarte que en el BIOS de la tarjeta madre este activada ésta función. Lo puedes conseguir ya que luce algo como:
S.M.A.R.T for Hard Disk: Enable
Algunos BIOS no tienen ésta opción y reportan el S.M.A.R.T como inactivo, pero no te preocupes que el smartcl, uno de los dos programas de utilidad que tiene el Smartmontools, puede activarlo. Una vez que estemos seguros de todo ésto podemos proceder a instalar el Smartmontools, el cual, en la distribución que uso, Debian, es tan fácil como escribir en una terminal:
$ aptitude install smartmontools
Y de esa manera ya queda automágicamente instalado el paquete el sistema. Si quieres verificar si ya lo tienes instalado, entonces tendrías que escribir en una terminal lo siguiente:
$ aptitude show smartmontools
Y verificar que el atributo Estado se corresponda con Instalado. Una vez hecho ésto procedemos a verificar si nuestro disco soporta S.M.A.R.T con la siguiente línea de comandos:
$ smartctl -i /dev/hda
En caso que tu disco sea SATA tendrías que escribir la siguiente línea:
$ smartctl -i -d ata /dev/sda
La información se vería algo así:
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar family
Device Model: WDC WD1200BB-00RDA0
Serial Number: WD-WMANM1700779
Firmware Version: 20.00K20
User Capacity: 120,034,123,776 bytes
Device is: In smartctl database [for details use: -P show]
ATA Version is: 7
ATA Standard is: Exact ATA specification draft version not indicated
Local Time is: Sun Sep 24 22:27:09 2006 VET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Si tu disco es SATA pero tiene el soporte S.M.A.R.T desactivado, entonces deberás usar la siguiente línea de comandos para activarlo:
$ smartctl -s on -d ata /dev/sda
Aprendiendo a usar SMT
Estado de “salud” de nuestro disco duro
Para leer la información que SMT ha recopilado acerca de nuestro disco, debemos escribir la siguiente linea de comandos:
$ smartctl -H /dev/hda
Para discos SATA no es suficiente con sustituir hda con sda, sino que debemos añadir las opciones extras que usamos anteriormente para obtener la información del disco. La línea de comandos entonces quedaría así:
$ smartctl -d ata -H /dev/sda
Si lees PASSED al final de la información, no tienes que preocuparte. Pero si lees FAILED deberías empezar a hacer respaldo de tus datos inmediatamente, ya que ésto quiere decir que tu disco ha presentado fallas anteriormente o es muy probable que falle dentro de un lapso de aproximadamente 24 horas.
Bitácora de errores de SMT
Para chequear la bitácora de errores de SMT debemos escribir la siguiente línea de comandos:
$ smartctl -l error /dev/hda
De manera análoga al caso anterior, añadimos los comandos extras si nuestro disco es SATA. La línea de comandos quedaría así:
$ smartctl -d ata -l error /dev/sda
Si leemos al final de la información No errors logged todo anda bien. Si hay varios errores pero éstos no son muy recientes, deberías empezar a preocuparte e ir comprando los discos para el respaldo. Pero si en vez de ésto hay muchos errores y una buena cantidad son recientes entonces deberías empezar a hacer respaldo de tus datos, inclusive antes de terminar de leer ésta línea. Apurate! :D
A pesar que smartctl nos da una información muy valiosa acerca de nuestros discos, el tan solo revisar ésta no es suficiente, realmente se deben hacer algunas pruebas específicas para corroborar los errores que conseguimos en la información anterior, dichas pruebas las menciono a continuación.
Pruebas con SMT
Las pruebas que se van a realizar a continuación no interfieren con el funcionamiento normal del disco y por lo tanto pueden ser realizadas en cualquier momento. Aquí solo describiré como ejecutarlas y entender los errores. Si quieres saber más te recomiendo que visites ésta pagina o que leas las páginas del manual.
Lo primero sería saber cuáles pruebas soporta tu disco, lo cual logramos mediante la siguiente línea de comandos:
$ smartctl -c /dev/hda
De ésta manera puedes saber cuáles pruebas soporta tu disco y también cuanto tiempo aproximadamente puede durar cada una. Bien, ahora ejecutemos Immediate Offline Test ó Prueba Inmediata Desconetado (si está soportada, por supuesto), con la siguiente línea de comandos:
$ smartctl -t offline /dev/hda
Como ya sabemos, los resultados de ésta prueba no son inmediatos, de hecho el resultado de ésta linea de comandos te dirá que la prueba ha comenzado, el tiempo que aproximadamente va a demorar la prueba en terminar con una hora aproximada para dicha finalización, y al final te dice la línea de comandos para abortar la operación. En uno de mis discos, un IDE de 120Gb, demoró 1 hora, para que tengan una idea. Por los momentos sólo te queda esperar por los resultados. Ahora te preguntarás ¿Cómo puedo saber los resultados?, pues tan sencillo como ejecutar la línea de comandos para leer la bitácora del SMT y seguir las recomendaciones.
Ahora vamos a ejecutar Short self-test routine ó Extended self-test routine, Rutina corta de autoprueba y Rutina extendida de autoprueba, respectivamente (de nuevo, si están soportadas). Éstas pruebas son similares, sólo que la segunda, como su nombre lo indica, es más rigurosa que la primera. Una vez más ésto lo logramos con los siguientes comandos:
$ smartctl -t short /dev/hda
$ smartctl -t long /dev/hda
Luego vamos a chequear el Self Test Error Log ó Bitácora de errores de autopruebas:
$ smartctl -l selftest /dev/hda
Luego ejecutamos Conveyance Self Test ó Autoprueba de Transporte:
$ smartctl -t conveyance /dev/hda
Y por último chequeamos Self Test Error Log de nuevo.
Algo que tengo que resaltar es que el SMT tiene dos bitácoras, una de las cuales es la Bitácora de errores y la otra es la Bitácora de Errores de Autopruebas.
¿Cómo monitorear el disco duro automáticamente?
Para lograr ésto tendrás que configurar el demonio smartd para que sea cargado cuando se inicia el sistema. A continuación un pequeño HOWTO.
ADVERTENCIA: el siguiente HOWTO es para monitorear un disco IDE, programar todas las pruebas cada viernes de la semana, de 11:00 a.m a 2:00 p.m, y luego ejecutar un script de Bash si algún error es detectado. Éste script escribirá un reporte bien detallado y luego apagará el equipo para su propia protección.
El archivo de configuración de smartd se encuentra en /etc/smartd.conf, si éste no existe,
el cual sería un caso poco común, deberás crearlo en tu editor de elección.
...
#DEVICESCAN
...
/dev/hda \
-H \
-l error -l selftest \
-s (O/../../5/11|L/../../5/13|C/../../5/15) \
-m ThisIsNotUsed -M exec /usr/local/bin/smartd.sh
El script en Bash también puedes hacerlo en un editor de tu elección, y tendrá la siguiente forma:
#!/bin/bash
LOGFILE="/var/log/smartd.log"
echo -e "$(date)\n$SMARTD_MESSAGE\n" >> "$LOGFILE"
shutdown -h now
Luego de crear el script deberás hacerlo ejecutable cambiando sus atributos con la siguiente línea de comandos:
$ chmod +x /usr/local/bin/smartd.sh
Para probar todo, puedes agregar al final de tu /etc/smartd.conf la línea
-M test
y luego ejecutar el demonio. Nota que ésto apagará tu equipo, hayan errores o no. Luego si algo sale mal deberás chequear la bitácora del sistema en /var/log/messages con:
$ tail /var/log/messages
Y así corregir el problema. Ahora tendrás que quitar la línea
-M test
y guardar los cambios. Por último debes hacer que smartd sea cargado al momento del arranque, lo cual lo logras con la siguiente línea:
$ rc-update add smartd default
Algunos enlaces de interés:
- S.M.A.R.T en la Wikipedia
- Página Oficial de smartmontools
- Ejemplos de salidas del SMT
- Atributos usados para recuperar el estado físico/lógico de una unidad y mostrar su significado de una forma más entendible para un usuario final
Nota: Ésta artículo está basado en un HOWTO del Wiki de Gentoo
Audigy SE en Etch AMD64
Hace días me hice con una tarjeta de sonido Audigy SE de la marca Creative y la verdad tuve que dar bastante golpes para dar con la configuración correcta. ¿Cómo lo logré? Muy fácil: Googleando :).
Resulta que el sistema (Debian, of course) reconoce bien el dispositivo y carga de manera perfecta los módulos necesarios; de hecho el alsa-mixer me mostraba todos los canales de la tarjeta pero el único que parecía funcionar era el Analog Front y los otros parecían estar muertos. Casi daño el mouse de tando hacer clicks y darle hacia arriba y hacia abajo :). No podía creer que no funcionara!.
Googleando llegué a la página de la gente de Alsa y me encontré una manera de configurar los drivers. Ahi confirmé que el sistema me estaba cargando el módulo correcto, el snd-ca0106. Entonces, después de ver la pequeña lista de instrucciones, no voy a decir que me espanté y maldije a Creative, no, no lo hice, en ése momento miré al cielo y pregunté: ¡¿Acaso no existe una manera más fácil de lograr que suenen la benditas cornetas?! y la respuesta a mi pregunta vino del wiki de Gentoo, ¿qué cosas no? imagínense todo lo que googleé; bueno específicamente de la sección que dice VIA Envy24HT (ice1724) chip. Ahora se preguntarán.. ¿VIA? éste tipo está loco…. pues sí, VIA. ¿Y qué fué lo que hice? Abrí una terminal e hice lo siguiente:
$ gedit .asoundrc
Luego lo que hice fué copiar el contenido del segundo .asoundrc y pegarlo al mío, luego guardar los cambios y voilá, sistema de sonido 5.1 andando ;). Se preguntarán ¿Cómo hizo éste loco para saber que ese .asoundrc funciona con la Audigy SE?, bueno, con el proceso estándar, prueba error. Copiando y pegando cada uno de los ficheros.
Ahora que el sistema suena perfectamente bien me ha surgido una nueva interrogante, debido a que para poder graduar el volumen del sistema tengo que graduar los tres controles, y la pregunta es: ¿Habrá alguna forma de graduar el volumen para los tres controles al mismo tiempo? Que lo disfruten…
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
Debian: Bienvenido al Sistema Operativo Universal (Parte II)
Esta serie de anotaciones comenzo con la entrada Debian: Bienvenido al Sistema Operativo Universal (Parte I).
Después de escribir en la tabla de particiones el esquema de particionamiento descrito en la parte anterior, el sistema base Debian comenzo a instalarse. Posterior a la Bienvenida al nuevo sistema Debian, reinicie y comence a configurar el sistema base debian, en la sección de selección de programas Debian escogí la última opción que nos brinda el asistente, selección manual de paquetes, luego configure las fuentes de aptitude y enseguida inicie la instalación de paquetes puntuales, los cuales describiré a continuación, de manera breve.
Como lo que tenía a mano era el CD Debian GNU/Linux testing Sarge- Official Snapshot i386 Binary-1, lo primero que hice fue actualizar a Sarge, seguidamente cambie las fuentes del fichero /etc/apt/sources.list a Etch, actualice la lista de paquetes disponibles e inmediatamente hice un aptitude dist-upgrade, el cambio de una rama a otra fué de lo más normal, no genero problema alguno.
Nota: No he descrito el proceso de instalación del sistema base de manera detallada ya que existe suficiente información en el sitio oficial de Debian, si lo desea, puede ver este video tutorial de instalación de Debian Sarge (aprox. 54MB.), en este video se explica como instalar el Entorno de Escritorio predeterminado que ofrece el asistente, no es el caso que explico en esta entrada, puesto que vamos a generar un Entorno de Escritorio de acuerdo a nuestras necesidades particulares.
Si tiene alguna duda acerca de la funcionalidad de un paquete en particular, puede consultar la descripción del mismo al hacer uso del comando aptitude show _package-name_, en donde package-name es el nombre del paquete en cuestión.
En los siguientes pasos haré uso intensivo de aptitude, anteriormente ya he explicado las ventajas que presenta aptitude sobre los comandos apt-get y sobre la interfaz gráfica Synaptic, puede encontrar mayor información en los artículos:
Sistema X Window
Instalando los componentes esenciales para el Sistema X Window.
# aptitude install x-window-system-core
GNOME
Instalando los componentes esenciales para el entorno de escritorio GNOME.
# aptitude install gnome-core
GNOME Display Manager
Si usted hubiese instalado el paquete x-window-system, metapaquete que incluye todos los componentes para el Sistema X Window, se instalaría por defecto XDM (X Display Manager), normalmente debería recurrir a la línea de comandos para resolver los problemas de configuración de este manejador, mientras que con GDM (GNOME Display Manager) no debe preocuparse por ello, puede personalizarlo o solucionar los problemas sin recurrir a la línea de comandos. De manera adicional, puede mejorar su presentación con la instalación de temas.
# aptitude install gdm gdm-themes
Mensajería Instantánea, IRC, Jabber
GAIM
Todo lo anterior se puede encontrar al instalar GAIM.
# aptitude install gaim gaim-themes
irssi
Si le agrada utilizar IRC modo texto, puede instalar irssi.
# aptitude install irssi
Centericq
Centericq es un cliente de mensajería instantánea multiprotocolo, soporta ICQ2000, Yahoo!, AIM, IRC, MSN, Gadu-Gadu y Jabber.
# aptitude install centericq
Programas para la manipulación de imágenes
GIMP por defecto no puede abrir ficheros SVG, si desea manipularlos desde GIMP y no desde Inkscape puede hacer uso del paquete gimp-svg.
# aptitude install gimp gimp-python gimp-svg inkscape
Navegador Web
Definitivamente Firefox.
# aptitude install firefox firefox-locale-es-es
Creación de CDs y DVDs
# aptitude install k3b cdrdao
Para quienes quieran su version de K3b en español pueden instalar el paquete k3b-i18n, yo no lo considere necesario puesto que aporta 11,5MB, inútiles desde mi punto de vista.
Cliente Bittorrent
No le recomiendo instalar el cliente bittorrent Azureus, consume demasiados recursos, acerca de ello explico brevemente en el artículo Clientes Bittorrent.
# aptitude install freeloader
Lector de feeds
Normalmente utilizo Liferea. También cabe la posibilidad de utilizar el servicio que presta Bloglines.
# aptitude install liferea
Editor
# aptitude install vim-full
Cliente de correo electrónico
Para la fecha, a la rama testing de Debian no ingresa la versión 1.5 del cliente de correo Thunderbird (mi favorito), así que vamos a instalarlo manualmente.
En primer lugar deberá descargar (se asume que la descarga se realizará al escritorio) la última versión del cliente de correo, el paquete empaquetado y comprimido lo encontrará en el sitio oficial de Thunderbird.
Seguidamente, proceda con los siguientes comandos.
# tar -C /opt/ -x -v -z -f ~/Desktop/thunderbird*.tar.gz
# ln -s /opt/thunderbird/thunderbird /usr/bin/thunderbird
Instalar Diccionario en español
wget -c http://downloads.mozdev.org/dictionaries/spell-es-ES.xpi
Aplicaciones -> Herramientas del Sistema -> Root Terminal. Desde allí procedará a ejecutar el comando thunderbird.
Desde Thunderbird, seleccione la opción Extensiones del menú Herramientas. Seguidamente proceda a dar click en el botón Instalar y posteriormente busque la ruta del paquete que contiene el diccionario.
Thunderbird + GPG = Enigmail
Esta excelente extensión le permitira cifrar y descifrar correos electrónicos, a su vez, le permitirá autenticar usuarios usando OpenPGP.
wget -c http://releases.mozilla.org/pub/mozilla.org/extensions/enigmail/enigmail-0.94.0-mz+tb-linux.xpi
Como usuario normal, proceda a invocar el cliente de correo electrónico Thunderbird, seleccione la opción Extensiones del menú Herramientas y proceda a instalar la extensión en cuestión, similar al proceso seguido para lograr instalar el diccionario.
Reproductor de videos
Aunque existen reproductores muy buenos como el VLC y XINE, mi reproductor favorito es, sin lugar a dudas, MPlayer. La mejor opción es compilarlo, aún en la misma página oficial del proyecto MPlayer lo recomiendan, existe mucha documentación al respecto. Sin embargo, si no tiene tiempo para documentarse puede seguir los siguientes pasos, le advierto que el rendimiento quizá no sea el mismo que al compilar el programa.
# echo "deb ftp://ftp.nerim.net/debian-marillat/ etch main" >> /etc/apt/sources.list
# aptitude update
# aptitude install mplayer-386 w32codecs
Extensiones para Mozilla Firefox
Estas son las que he instalado hasta ahora, siempre uso un poco más, puede encontrarlas en la sección Firefox Add-ons del sitio oficial.
- Answers
- del.icio.us
- FireFoxMenuButtons
- Colorful Tabs
- Tab Mix Plus
Gestor de Arranque
Vamos a personalizar un poco el gestor de arranque GRUB.
# aptitude install grub-splashimages
$ cd /boot/grub/splashimages
En este instante le recomiendo escoger alguno de los motivos que incluye el paquete grub-splashimages, una vez hecho esto, proceda a realizar lo siguiente.
$ cd /boot/grub/
# ln -s splashimages/image.xpm.gz splash.xpm.gz
# update-grub
En donde, evidentemente, debe cambiar el nombre del fichero image.xpm.gz por el nombre de fichero de la imagen que le haya gustado en /boot/grub/splashimages.
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Vim al rescate
Al examinar el día de hoy el último fichero de respaldo de la base de datos de este blog, me percate que existe una cantidad inmensa de registros que en realidad no me hacen falta, sobretodo respecto a las estadísticas, es increible que los registros de una simple base de datos llegara a ocupar unos 24MB, dicha información no tiene mayor relevancia para los lectores puesto que dichos datos suelen ser visualizados en la interfaz administrativa del blog, pero al ocupar mayor espacio en la base de datos, pueden retardar las consultas de los usuarios. Por lo tanto, era necesario realizar una limpieza y eliminar unos cuantos plugins que generaban los registros de las estadísticas.
Ahora bien, imagínese abrir un documento de 266.257 líneas, 24.601.803 carácteres desde algun editor de textos gráfico, eso sería un crimen. ¿Qué podemos hacer?, la única respuesta razonable es utilizar Vim.
Vim es un avanzado editor de textos que intenta proporcionar todas las funcionalidades del editor de facto en los sistemas *nix, Vi. De manera adicional, proporciona muchas otras características interesantes. Mientras que Vi funciona solo bajo ambientes *nix, Vim es compatible con sistemas Macintosh, Amiga, OS/2, MS-Windows, VMS, QNX y otros sistemas, en donde por supuesto se encuentran los sistemas *nix.
A continuación detallo más o menos lo que hice:
En primer lugar respalde la base de datos del blog, enseguida procedí a descomprimir el fichero y revisarlo desde Vim.
$ vim wordpress.sql
Comence a buscar todos los CREATE TABLE que me interesaban. Para realizar esto, simplemente desde el modo normal de Vim escribí lo siguiente:
/CREATE TABLE <strong><Enter></strong>
Por supuesto, el
Con todo la información necesaria, lo único que restaba por hacer era copiar la sección que me interesaba en otro fichero, para ello debemos proceder como sigue desde el modo normal de Vim:
:264843,266257 w milmazz.sql
El comando anterior es muy sencillo de interpretar: Copia todo el contenido encontrado desde la línea 264.843 hasta la línea 266.257 y guardalo en el fichero milmazz.sql.
Inmediatamente restaure el contenido de mi base de datos y listo.
Algunos datos interesantes.
Fichero original
- Tamaño: 24MB
- Número total de líneas: 266.257
Fichero resultado
- Tamaño: 1.2MB
- Número total de líneas: 1.415
Tiempo aproximado de trabajo: 4 minutos.
¿Crees que tu editor favorito puede hacer todo esto y más en menos tiempo?. Te invito a que hagas la prueba ;)
That’s All Folks!
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
nVIDIA en Ubuntu 6.04
Hace unos días actualicé mi Ubuntu 5.10 a una de sus últimas versiones de testing: Flight 5. Debo admitir que quedé anonadado por lo cambios en la distribución, ya que con todas las mejoras que tiene parece que hubiera pasado, no sólo 6 meses sino años. El Dapper Drake (Flight 5, Ubuntu 6.04) es mucho mejor que sus antecesores. Pero la razón por la cual me decidí a escribir éste artículo es otra: la instalación de los drivers de mi tarjeta nVIDIA y su puesta en funcionamiento a punto.
Cuando actualicé mi sistema no hubo ningún problema, y lo digo en serio, ningún problema de ninguna índole. Toda mi configuración de escritorio quedó intacta; pero empecé a notar que la configuración de la tarjeta de video no se cargaba con el sistema. Entonces supe que, por alguna razón, los drivers de la tarjeta habían cambiado, es decir, el sistema asignó el driver por defecto para la tarjeta, más no los drivers de la tarjeta misma. Entonces tuve que ponerme a configurar la tarjeta.
Lo primero que hice fué verificar que los drivers vinieran con la distribución. Lo hice con la siguiente línea:
$ sudo aptitude search nvidia
Con lo cual obtuve lo siguiente:
i nvidia-glx - NVIDIA binary XFree86 4.x/X.Org driver
v nvidia-kernel-1.0.7174 -
v nvidia-kernel-1.0.8178 -
i nvidia-kernel-common - NVIDIA binary kernel module common files
Entonces ya sabía que los drivers venían con la distro, lo cual me pareció fascinante, ya que en realidad el Flight 5, no es la versión definitiva del Dapper Drake. Luego procedí a verificar la documentación de dicho paquete. Ésto lo hice con la siguiente línea de comandos:
$ sudo aptitude show nvidia-glx
Esto lo hice para verificar que no haya alguna clase de conflictos con otros paquetes, pero en realidad no es un paso necesario, ya que aptitude resuelve todo tipo de conflictos y dependencias. Después de verificar que todo estaba en orden me decidí a instalar los drivers. Ésto lo hice con la siguiente linea de comandos:
$ sudo aptitude install nvidia-glx
Con lo cual quedaron instalados los drivers de la tarjeta de manera trasparente y rápida. Lo siguiente que debía hacer, era activar la configuración de la tarjeta. Lo cual hice con la siguiente línea de comandos:
$ sudo nvidia-glx-config enable
Una vez hecho ésto ya podía configurar la tarjeta. Algo que hay que hacer notar es que, para las distribuciones anteriores de Ubuntu, había que instalar de manera separada el paquete nvidia-glx y el nvidia-settings, sin embargo, aquí queda todo instalado de una vez. Lo que sigue es iniciar la configuración de la tarjeta, lo cual hice con la siguiente línea de comandos:
$ nvidia-settings
Y ya tenía acceso a la configuración de mi tarjeta. Sin embargo, al hacer todo ésto, la configuración no se carga al iniciar el sistema, pero no fué problema, porque lo solucioné colocando en los programas de inicio del gnome-session-manager los siguiente:
nvidia-settings -l
Este comando carga la configuración de nvidia-settings que tengamos actualmente. Es lo mismo que, una vez que haya cargado el sistema, ejecutemos en la consola éste comando, sólo que ahora se va a ejecutar apenas inicie el sistema operativo.
Otros ajustes…
Si quieren colocar un lanzador en los menús del panel de gnome deben hacer los siguiente:
$ sudo gedit /usr/share/applications/NVIDIA-Settings.desktop
Y luego insertar lo siguiente en dicho fichero:
[Desktop Entry]
Name=Configuración nVIDIA
Comment=Abre la configuración de nVIDIA
Exec=nvidia-settings
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya tendrán un lanzador en los menús del panel de gnome. Una opción sería utilizar el editor de menús Alacarte.
nvidia-xconf
nvidia-xconf es una utilidad diseñada para hacer fácil la edición de la configuración de X. Para ejecutarlo simplemente debemos escribir en nuestra consola lo siguiente:
$ sudo nvidia-xconfig
Pero en realidad, ¿qué hace nvidia-xconfig? nvidia-xconfig, encontrará el fichero de configuración de X y lo modificará para usar el driver nVIDIA X. Cada vez que se necesite reconfigurar el servidor X se puede ejecutar desde la terminal. Algo interesante es que cada vez que modifiquemos el fichero de configuración de X con nvidia-xconfig, éste hará una copia de respaldo del fichero y nos mostrará el nombre de dicha copia. Algo muy parecido a lo que sucede cada vez que hacemos:
dpkg-reconfigure xserver-xorg
Una opción muy útil de nvidia-xconfig es que podemos añadir resoluciones al fichero de configuración de X simplemente haciendo:
$ sudo nvidia-xconfig --mode=1280x1024
…por ejemplo.
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
Planeta Linux
Hace tiempo que no revisaba algunas de las estadísticas del sitio, me he percatado que han llegado algunos enlaces desde Planeta Linux Venezuela. El principal objetivo de este sitio es:
Planeta Linux es un pequeño proyecto que pretende fomentar la comunicación e intercambio sencillo de información sobre cualquier usuario de GNU/Linux o software libre, en Venezuela. Con esta breve comunicación, podremos conformar una comunidad mucho má sólida, unificada e integral.
Lo anterior también es extensible para aquellas personas mexicanas, puesto que existe un Planeta Linux México.
¿Desea colaborar con el proyecto?
El proceso de registro es muy sencillo, solamente debes enviar un correo a lista de correos [email protected], si desea suscribirse a dicha lista solamente rellene los datos solicitados página de información de la lista de correos de Planeta Linux.
Para su admision usted debe suministrar los siguientes datos:
- Nombre completo
- Lugar de residencia
- URI del feed RSS/Atom
Opcionalmente puede enviar su Hackergotchi, imagen de un escritor que es utilizada como ícono para identificar al autor de un feed dado dentro de un agregador de blogs, ésta no debe exceder un ancho de 95 pixels y un alto de 95 pixels.
Conociendo un poco más acerca del proyecto
Me ha interesado mucho esta iniciativa, así que no dude en ponerme en contacto con David Moreno Garza (a.k.a. damog), él cual me ha contestado muy amablemente. En las siguientes líneas expongo nuestro intercambio de correos electrónicos.
- MilMazz: Hola David, en realidad no tengo el placer de conocerte personalmente, pero he notado recientemente algunos enlaces entrantes desde el Planeta Linux Venezuela, no se quien me dio de alta, se agradece, así que gracias.
- Damog: Hola Milton, no, al parecer no nos conocemos. Yo te di de alta en el rol debido a que José Parrella, a.k.a bureado, me pasó tu nombre y feed.
- MilMazz: El motivo de este mensaje es para pedirte un poco de informacion respecto al proyecto, para publicar un artículo en mi blog y así colaborar con la difusión de esta interesante idea.
- Damog: ¡Muchas gracias! Así es como el proyecto va ganando adeptos y más gente se va uniendo y leyendo el contenido de Planeta Linux.
- MilMazz: Espero no te molesten las siguientes preguntas, tomalo a manera de entrevista :)
- Damog: Desde luego que no, ¡bienvenidas! Antes que cualquier cosa, espero que no te importe que reenvíe este correo a la lista de Planeta Linux.
- MilMazz: ¿Quién o quienes se plantearon en principio la idea de crear Planeta Linux?, ¿quién lo llevaron a cabo?
- Damog: Debido al boom que han tenido los blogs entre usuarios y desarrolladores de software libre en el mundo, se ve la necesidad de crear nuevas herramientas para «monitorear» los contenidos dependiendo de los gustos de cada uno de los usuarios. Wieland Kublun, un mexicano radicado en Guadalajara, en el estado de Jalisco, en el occidente de México, alguna vez me comentó que estaría bien tener una especie de «planeta», como los que se han dado a conocer por proyectos grandes como Planet Debian o Planet GNOME. Creí que la idea era estupenda y empezamos a poner el agregador en marcha y añadiendo a nuestros conocidos al rol.
Otro factor que ha influído mucho en la gran proliferación de Planeta Linux es Jaws. Jaws es un proyecto, iniciado por Jonathan Hernández, radicado en Chihuahua, en el norte de México, de software libre para construir fácilmente un blog. El proyecto Jaws ha avanzado ya muchísimo, pues el software desarollado es altamente útil, funcional y bastante bonito. Por ende, muchos usuarios mexicanos empezaron a montar sus blogs en él y la mancha de usuarios blogueadores mexicanos creció mucho.
- MilMazz: Tengo entendido que el primer planeta de la “serie” fue el Planeta Linux Mexico, ¿desde cuando está en línea?
- Damog: Así es, fue el primero. Ha estado en línea desde octubre de 2004. Antes utilizábamos el dominio planetalinux.com.mx, pero recientemente abrimos el 2006 con el dominio, más genérico y permitible de expansión, planetalinux.org.
- MilMazz: ¿Por qué decidiste incluir a Venezuela como parte del Planeta Linux?, ¿alguna persona te pidio que lo hicieras?
- Damog: No. Personalmente tengo mucha relación con Venezuela, pues mi novia es de allá y tengo bastantes amigos, en el mundillo del software libre, allá. Quise lanzarlo por que empecé a conocer a gente que tenía un blog y llegó a un punto donde consideré pertinente lanzarlo, y donde la gente se interesaría por él. Mucha gente, hasta donde tengo entendido, ni siquiera sabe que está en el planeta. Como tú mismo, a muchas personas se han agregado teniendo conocimientos de ellos por terceras partes. Sin embargo, la forma de ver crecer un proyectito así es precisamente de boca en boca, de blog en blog.
- MilMazz: ¿Tienes pensado en el futuro incluir a mas paises?, si es así, ¿cuáles serían?
- Damog: Sí, la idea también era esa al iniciar con el dominio que usamos actualmente. Al principio creí que lo ideal sería empezar con México y Venezuela por razones ya explicadas, y además con Estados Unidos (sindicando a la gente latina que radica en ese país y que bloguea), usando la dirección us.planetalinux.org. Sin embargo, aún no se ha juntado suficiente gente para llevar a cabo tal subproyecto. En general cualquier país latinoamericano podría entrar mientras se junte suficiente gente y vaya creciendo como han ido creciendo los correspondientes a México y Venezuela. Creo que sería interesante seguirse luego con Brasil, donde hay una enorme actividad de software libre, o incluso en Argentina. Sin embargo, esto depende de la gente: Hace falta todavía escribir mucho contenido, hace falta escribir una especie de FAQ donde se explique qué pueden hacer si alguien quiere iniciar una instancia de Planeta Linux en un país donde no exista, hace falta hacer ese tipo de cosas y generar esos contenidos.
- MilMazz: Estaba por documentarme acerca de los lineamientos, al parecer el enlace de los lineamientos de Planeta Linux está roto por ahora, ¿cuáles serían los lineamientos que debe seguir un miembro del Planeta Linux?
- Damog: Bueno, como te digo, uno más de los contenidos inconclusos. Básicamente, los lineamientos establecerán algunos reglas o consejos, como que deberán hablar de Linux y Software Libre con cierta regularidad en su blog, que su feed debe ser válido, etc. Ese tipo de cosas.
- MilMazz: ¿Quienes pueden participar en el Planeta Linux?
- Damog: Cualquier persona que lleve un blog y toque periódicamente temas sobre Linux o Software Libre.
- MilMazz: ¿Deseas agregar algo más?
- Damog: Pues si alguien se quiere unir, es más que bienvenido. Simplemente escriban a la lista: [email protected] o suscríbanse.
Antes de culminar, quisiera agradecerle públicamente a José Parella por la sugerencia hecha a David Moreno Garza.
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
O3 Magazine
O3 Magazine es una revista distribuida de manera electrónica en formato PDF. El enfoque que pretende O3 es promover el uso/integración de programas basados en Software Libre y Código Abierto (FOSS) en ambientes empresariales.
O3 ha sido creada usando exclusivamente herramientas de código abierto. Como por ejemplo:
Scribus, permite crear publicaciones de escritorio profesionales, es usado para definir el layout y producir los PDFs. The Gimp, usado para la creación y manipulación de imágenes y Open Office, el cual es usado por los escritores para la creación de los artículos.
Cada edición de la revista O3 tratará de cubrir los siguientes tópicos:
- Seguridad
- Internet
- Tecnologías web
- Negocios
- Voz/Multimedia (VoIP)
- Redes
- Aplicaciones para redes
- Seguridad en redes
O3 Magazine pretende demostrar a sus lectores los beneficios y el ahorro que se genera al usar soluciones de código abierto en el ambiente de los negocios. También puede interesar a aquellos dueños de pequeñas y medianas empresas que estén interesados en una infraestructura IT fuerte, segura y escalable sin incurrir en altos costos.
Si desean tener la primera edición de O3 Magazine, pueden hacerlo en: Issue #1 (November 2005)
Como era de esperarse la publicación viene en inglés. De hecho, todas las revistas electrónicas que conozco y leo vienen en este idioma. Por lo descrito previamente me atrevo a preguntarles lo siguiente, ¿conocen alguna publicación electrónica de buena calidad que venga en español?.
Evolution y Gmail
Si desea configurar el cliente de correo Evolution (también brinda una agenda de contactos, calendario, entre otras funcionalidades) para manejar su cuenta de Gmail, estos son los pasos.
Habilitando el acceso POP en su cuenta de Gmail
- Identificarse en Gmail.
- Un vez dentro del sistema, ir a la opción de Configuración
- Seguidamente proceda a seleccionar Reenvío y correo POP del menú.
- Dentro de la sección Descargar correo POP encontramos tres derivaciones:
- La primera se refiere al Estado, en ella debemos habilitar cualquiera de las dos opciones que se muestran al principio, la primera permite Habilitar POP para todos los mensajes (incluso si ya se han descargado), la segunda opción permite Habilitar POP para los mensajes que se reciban a partir de ahora.
- La segunda derivación se refiere a qué debe hacer Gmail cuando se accede a los mensajes a través de POP, eliga la respuesta de su conveniencia, yo por lo menos tengo conservar una copia de Gmail en la bandeja de entrada.
- La tercera derivacion se refiere a como lograr configurar el cliente de correo electrónico, en nuestro caso, será Evolution.
- Guardar cambios.
Ahora vamos a configurar nuestra cuenta Gmail desde Evolution. En primer lugar veamos como configurar la recepción de correos.
Recibiendo Mensajes
- Tipo de servidor: POP
- Servidor:
pop.gmail.com - Usuario: [email protected], evidentemente debe cambiar la cadena nombredeusuario por su login verdadero, no olvide colocar seguido del nombre de usuario la cadena @gmail.com.
- Usar onexión segura: Siempre
- Tipo de autenticación: Password
Ahora veamos como configurar el envio de correos desde Evolution.
Enviando correos
- Tipo de servidor: SMTP
- Servidor: Puede usar las siguientes:
smtp.gmail.com,smtp.gmail.com:587ósmtp.gmail.com:465. Debe marcar la casilla de verificación El servidor requiere autenticación - Usar conexión segura: Cuando sea posible
- Tipo (dentro de la sección de autenticación): Login
- Usuario (dentro de la sección de autenticación): [email protected], recuerde sustituir la cadena nombredeusuario por el parámetro correspondiente, no olvide colocar después del nombre de usuario la cadena @gmail.com, es importante.
Finalmente revise las opciones que le brinda Evolution y comience una vida llena de placeres.
Repositorios de Ubuntu
Desde hace unas horas hasta hace poco el servidor principal que mantiene los archivos de los paquetes binarios y fuentes estaba caído.
Obteniendo respuesta desde http://archive.ubuntu.com/ubuntu.
<code>$ wget http://archive.ubuntu.com
--09:56:27-- http://archive.ubuntu.com/
=> `index.html'
Resolving archive.ubuntu.com... 82.211.81.151, 82.211.81.182
Connecting to archive.ubuntu.com[82.211.81.151]:80... failed: Connection refused.
Connecting to archive.ubuntu.com[82.211.81.182]:80... failed: Connection refused.</code>
En cambio, el servicio por ftp si estaba habilitado. Obteniendo respuesta
desde ftp://archive.ubuntu.com/ubuntu
<code>$ wget ftp://archive.ubuntu.com
--09:58:24-- ftp://archive.ubuntu.com/
=> `.listing'
Resolving archive.ubuntu.com... 82.211.81.182, 82.211.81.151
Connecting to archive.ubuntu.com[82.211.81.182]:21... connected.
Logging in as anonymous ... Logged in!
==> SYST ... done. ==> PWD ... done.
==> TYPE I ... done. ==> CWD not needed.
==> PASV ... done. ==> LIST ... done.
[ < => ] 64 --.--K/s
09:58:24 (48.75 KB/s) - `.listing' saved [64]
Removed `.listing'.
Wrote HTML-ized index to `index.html' [302].</code>
Ahora bien, en este caso simplemente bastaba con cambiar la entrada http por
ftp en el fichero /etc/apt/sources. Para evitar cualquier tipo de
inconvenientes en el futuro, es recomendable hacer uso de sitios espejo o
mirrors.
En https://wiki.ubuntu.com/Archive encontrará toda la información necesaria, si utiliza los repositorios del proyecto Ubuntu Backport es recomendable que vea su sección de las URL de los Repositorios.
NOTA: Siempre es recomendable hacer uso de sitios espejos puesto que estos presentan menos demanda que los sitios oficiales de los proyectos.
Cambiando la ubicación del cache de apt
El día 21 de Septiembre Jorge Villarreal preguntó en la entrada Creando un repositorio local lo siguiente:
… tengo un laptop lentisimo , ahora mi pregunta ya que puedo navegar desde la oficina y en ella solo tienen windows como hago para descargar actualizaciones y llevarlas en una pen o en cd?. a como anexo en las tardes navego con cd-live ubuntu, me pregunto si podre bajar virtualmente desde ahi?
Mi respuesta es la siguiente:
Sí, en efecto puedes descargar los paquetes desde tu LiveCD de Ubuntu, de hecho, existen dos maneras para mí, las expongo a continuación.
Primer método
La primera es usar la memoria que dispones, la cual es limitada, recuerda que
los ficheros que descarga la interfaz apt (o aptitude) se almacenan en el
directorio /var/cache/apt/archives, como te mencione anteriormente, este método
puede ser limitado.
Veamos ahora el segundo método, te recomiendo éste porque vamos a escribir en el disco duro.
Segundo método
Ya que en la oficina utilizas Windows, el único requisito que se necesita es disponer de una partición cuyo formato de ficheros sea FAT, asumiré en el resto de mi respuesta que dicha partición se encuentra en /dev/hdb1 y se ha montado en /mnt/backup. Por lo tanto:
$ sudo mount -t vfat /dev/hdb1 /mnt/backup
Posteriormente se debe crear el fichero /etc/apt.conf, esto se puede hacer fácilmente con cualquier editor. Dicho fichero debe contener lo siguiente:
DIR "/"
{
Cache "mnt/backup/apt/" {
Archives "archives/";
srcpkgcache "srcpkgcache.bin";
pkgcache "pkgcache.bin";
};
};
Lo anterior simplemente está cambiando el directorio usual
(/var/cache/apt/archives) del cache, de ahora en adelante se estará
escribiendo de manera permanente en disco duro. Previamente debes haber creado
el directorio /mnt/backup/apt/archives/. Seguidamente tienes que crear el
fichero lock y el directorio partial. Resumiendo tenemos:
$ mkdir -p /mnt/backup/apt/archives/partial
$ touch /mnt/backup/apt/archives/lock
Pasos comunes en ambos métodos
Recuerda que sea cual sea el método que decidas usar, debes editar el fichero /etc/apt/sources.list, mejora la lista de repositorios que se presentan, luego de guardar los cambios en el fichero, ejecuta el siguiente comando.
$ sudo aptitude update
El comando anterior actualizará tú lista de paquetes con los que se encuentran en los repositorios que añadiste previamente. Ahora bien, para almacenar ficheros en el directorio cache haz uso del comando.
$ sudo aptitude --download-only install <em>packages</em>
Cuando me refiero a packages recuerda que son los nombres de los paquetes.
Seguidamente puedes seguir los pasos que se te indican en la entrada Creando un
repositorio local, por
supuesto, si cambias la dirección del cache que hará uso la interfaz apt (o
aptitude) debes hacer los ajustes necesarios. Espero te sirva la información.
Si alguien desea realizar un aporte bienvenido será.
Automatiza el uso de pastebin desde la línea de comandos
Si deseas colocar gran cantidad de código en un canal IRC, Chat o haciendo uso de la mensajería instantánea, es realmente recomendable que haga uso de un sistema pastebin, por ejemplo, pastebin.com, el cual es una herramienta colaborativa que permite depurar código.
Además, siguiendo esta metodología se evita incurrir en el conocido flood, el cual consiste en el envio de gran cantidad de información a un usuario o canal, la mayoría de las ocasiones con el fin de molestar, incluso, puede lograr desconectar a otros usuarios. Este tipo de prácticas se castigan en muchos canales IRC.
Si no está familiariazado con la idea de los sistemas pastebin, un resúmen le puede ayudar en algo:
- Envie un fragmento de código al sistema pastebin de su preferencia, obtendrá
una dirección similar a
http://pastebin.com/1234 - Informe de la URL obtenida en los canales IRC o a través de la conversación que mantenga por mensajería instantánea.
- Cualquier persona puede leer su código, a su vez, pueden enviar modificaciones de éste.
- Si no se da cuenta de las modificaciones a primera vista, puede hacer uso de las opciones que le muestran las diferencias entre los ficheros de manera detallada.
Existe un script hecho en Python que le permite de manera automática y fácil el colocar la salida del terminal o de otros programas hechos en Python al sitio de pastebin que usted prefiera.
Instalación
Ejecute los siguientes pasos:
$ wget http://www.ubuntulinux.nl/files/pastebin
$ chmod +x pastebin
$ sudo ./pastebin --install
El comando anterior instalará el script dentro del directorio /usr/bin/ con permisos de ejecución.
Uso
pastebin [--name Autor] [--pid Entrada_Padre] [--bin URL_Pastebin]
Los valores entre corchetes son opcionales, cada uno significa lo siguiente:
-
--name: Recibe como valor el nombre del autor del código. -
--pid: Debe usarlo cuando está dando una respuesta o corrección a alguna entrada. Normalmente es el número que le sigue inmediatamente al nombre del servidor por ejemplo: Si usted tiene una URL de este tipo,http://pastebin.com/2401, elpidsería2401. -
--bin: Recibe como valor el sistema pastebin que esté usando.
Si no desea estar especificando a todo momento el nombre del autor (--name) y
el servicio pastebin que usa (--bin), puede crear un fichero en
/etc/pastebinrc o en ~/.pastebinrc. El primero aplica a todos los usuarios y
el segundo a un usuario local. En cualquiera de los casos, dicho fichero debe
contener lo siguiente:
poster = Nombre Autor
pastebin = Servicio Pastebin
Por ejemplo, en mi caso particular, el contenido del fichero /etc/pastebinrc
es el siguiente:
poster = [MilMazz]
pastebin = paste.ubuntulinux.nl
Haciendo uso de la tubería o pipe
Colocando la salida estándar
`$ comando | pastebin`
Colocando la salida estándar y los posibles errores
`$ comando 2>&1 | pastebin`
Recuerde que debe sustituir comando en los dos ejemplos mostrados previamente por el nombre real del comando del cual desea obtener una respuesta.
Vía: Ubuntu Blog.
Conozca la temperatura de su disco duro
Si desea conocer cual es el valor en grados centígrados de la temperatura de su
disco duro, simplemente instale el paquete hddtemp desde el repositorio
universe haciendo lo siguiente:
$ sudo aptitude install hddtemp
Después, siempre que desee conocer la temperatura actual de su disco duro, proceda de la siguiente manera:
$ sudo hddtemp /dev/hdb
Por supuesto, recuerde que en la línea anterior /dev/hdb es el identificador
de mi segundo disco duro, proceda a cambiarlo si es necesario.
Mi temperatura actual en el segundo disco duro es de:
milmazz@omega:~$ sudo hddtemp /dev/hdb
/dev/hdb: ST340014A: 46°C
Antes de finalizar, es importante resaltar que hddtemp le mostrará la
temperatura de su disco duro IDE o SCSI solamente si éstos soportan la
tecnología SMART (acrónimo de: Self-Monitoring, Analysis and Reporting
Technology).
SMART simplemente es una tecnología que de manera automática realiza un monitoreo, análisis e informes, ésta tiene un sistema de alarma que en la actualidad viene de manera predeterminada en muchos modelos de discos duros, lo anterior puede ayudarle a evitar fallas que de una u otra manera pueden afectarle de manera contundente.
En esencia, SMART realiza un monitoreo del comportamiento del disco duro y si éste presenta un comportamiento poco común, será analizado y reportado al usuario.
Vía: Ubuntu Blog.
Registro de la segunda charla en el canal #ubuntu-es
Ya se encuentra disponible el registro de la segunda charla dada en el canal #ubuntu-es del servidor FreeNode. En esta charla se discutió lo siguiente:
- Ventajas y desventajas del uso de
aptitudefrente aaptysynaptic. - Resumen de comandos en
aptitude,apt,dpkg. - ¿Qué es un repositorio?.
- Agregando nuevos repositorios.
- Proyecto Ubuntu Backports.
- Editando el fichero
/etc/apt/sources.list. - Estructura de los repositorios.
- Ejemplos de uso de
aptitude. - Como actualizar de manera segura su sistema.
- ¿Es importante la firma de paquetes?.
- ¿Como verificamos la autencidad de los paquetes?.
- Como se importa la llave pública desde un servidor GPG.
- Como se exporta la llave pública y se añade a nuestra lista de claves seguras.
- Sesión de preguntas y respuestas.
Puede ver el registro de la charla al seguir el enlace anterior.
En ubuntuchannel.org estamos haciendo todo lo posible por mejorar cada día más, si está interesado en informarse acerca de las siguientes charlas puede ver como siempre nuestra sección de Eventos.
Recientemente nos hemos dedicado a realizar una especie de listado alfabético de
los comandos en GNU/Linux, dicha información se encuentra disponible en la
sección de Comandos, si desea
colaborar, su ayuda es bien recibida, solo recuerde comunicarse previamente
conmigo, para ello puede hacer uso del formulario de
contacto, para ponernos de acuerdo al
respecto. También puede recibir información de manera interactiva acerca del
proyecto en el canal IRC #ubuntu-es del
servidor FreeNode, sino me encuentro conectado (nick
[MilMazz]) en ese instante puede preguntarle al operador del canal (si se
encuentra conectado claro está), P3L|C4N0 con gusto le atenderá.
Seleccionando el mejor mirror para debian
El día de ayer decidí instalar Debian Sarge en uno de los ordenadores de casa, la instalación base de maravilla, luego procedi a levantar el entorno gráfico de GNOME haciendo uso de aptitude, deje de lado muchas aplicaciones que no voy utilizar extensivamente. Mientras intento solucionar un problemita con el sonido me dispuse a indagar acerca de los repositorios que ofrece Debian.
Leyendo la lista de mirrors en el sitio
oficial de Debian se me ocurrio que debia existir una manera de medir la rapidez
de cada uno de ellos, quizá para muchos esto no es nuevo, para mí si lo es,
recien comienzo con esta
distro, aunque aún
mantengo Ubuntu (no se preocupen mis dos o tres
lectores que seguiré escribiendo acerca de esta excelente distro). Bueno, he
hecho uso de apt-spy, este paquete hace una serie de pruebas sobre los mirrors
de debian, midiendo la su ancho de banda y su latencia.
El paquete apt-spy por defecto reescribe el fichero /etc/apt/sources.list
con los servidores con los resultados más rápidos.
Para instalarlo simplemente hacer lo siguiente:
# aptitude install apt-spy
Leyendo el manual de esta aplicación se puede observar que existe la opción de seleccionar a cuales mirrors se les harán las pruebas de acuerdo a su localización geográfica.
Por ejemplo:
# apt-spy -d stable -a South-America -o mirror.txt
Lo anterior genera un fichero fichero, cuyo nombre será mirror.txt, la opción
-a indica un área, esta opción acepta los valores siguientes: Africa,
Asia, Europe, North-America, Oceania y South-America, aunque es
posible definir sus propias áreas. La opción -d indica la distribución, esta
opcion acepta los valores siguiente: stable, testing o unstable.
He obtenido como resultado lo siguiente:
milmazz@nautilus:~$ cat mirror.txt
deb http://ftp.br.debian.org/debian/ stable main
deb-src http://ftp.br.debian.org/debian/ stable main
deb http://security.debian.org/ stable/updates main
También he realizado una segunda prueba.
# apt-spy -d stable -e 10 -o mirror.txt
Obteniendo como respuesta lo siguiente:
milmazz@nautilus:~$ cat mirror.txt
deb http://ftp.tu-graz.ac.at/mirror/debian/ stable main
deb-src http://ftp.tu-graz.ac.at/mirror/debian/ stable main
deb http://security.debian.org/ stable/updates main
La opción -e es para detener el análisis después de haber completado 10 (o el
número entero indicado como parámetro en dicha opción) servidores.
Me he quedado con los mirrors de Brazil (los mostrados en la primera prueba) por su cercanía geográfica, los del segundo análisis resultan ser de Austria y entran en la categoría de mirrors secundarios.
Charlas en #ubuntu-es
El día de ayer se llevo a cabo la primera de la serie de charlas que se
emitirán por el canal #ubuntu-es del servidor FreeNode, en esta oportunidad
el ponente ha sido zodman, el tema que abordo zodman
fue acerca de Cómo montar un servidor casero haciendo uso de Ubuntu Linux como
plataforma, en el transcurrir de la charla se explico como configurar y
establecer un servidor con los siguientes servicios.
- Apache2
- MySQL
- PHP4
- FTP
- SSH
También se hablo acerca de la configuración de dominios .com, .net y .org sin hacer uso de bind, aplicando dichas configuraciones en el servidor que se está estableciendo.
Si desgraciadamente no pudo estar presente en el evento, no se preocupe, ya he habilitado un registro de la charla. Por motivos de tiempo se decidio dividir la charla en dos partes, si le interesa asistir a la segunda parte de esta charla, esté atentos a los cambios en la sección de Eventos en Ubuntuchannel.org.
LinuxMag
Después de concretar algunas negociaciones con la imprenta sale la primera edición de LinuxMag, la primera revista impresa orientada a los fanáticos de GNU/Linux en mi ciudad, por ahora la distribución es local, esperemos la mayor receptividad posible y esperamos expander, tanto en contenido como en número de ejemplares, nuestras ediciones posteriores.
Nuestra portada este mes.

¿Le ha parecido interesante lo que ha visto?, le invito a seguirnos de cerca. Si desea saber un poco más acerca de nosotros, puede consultar el uso de esta herramienta para generar covers de revistas y obtendrá muchas respuestas.
Antes de finalizar, debo agradecer públicamente a José Vicente Nuñez Zuleta, nos brindó su apoyo incondicional, este proyecto no se hubiese llevado a cabo sin su ayuda.
Versión Previa a Kubuntu Breezy
Una vez hecho el anuncio de la versión previa a Ubuntu 5.10 (Breezy Badger), era de esperarse otro anuncio por parte del proyecto relacionado Kubuntu.
¿Qué hay de nuevo en esta versión?
-
KDE 3.4.2
-
OpenOffice 2 (Beta 2)
-
X.org 6.8.2
Se incluyen otras características tentadoras, como por ejemplo editores de imágenes, una mejora en la usabilidad para el manejo de las preferencias del sistema, entre otras.
Al igual que Ubuntu, la versión previa a la salida oficial de Kubuntu Breezy está disponible tanto en CD instalable como en en LiveCD para tres arquitecturas: x86 (PC), AMD64 (PC 64 bits) y PowerPC (Mac).
Puede descargar la imagen de esta versión en Kubuntu 5.10 (Breezy Badger) Preview. Recuerde usar en la medida de lo posible BitTorrent, para evitar la sobrecarga del servidor.
Si lo desea, puede ver el anuncio de esta versión previa.
Ubuntu 5.10 (Breezy Badger)
Se anuncia la versión previa a la salida oficial de Ubuntu 5.10, cuyo nombre clave es Breezy Badger, esta versión previa incluye tanto un CD instalable como un CD en “vivo” (Live CD) para tres arquitecturas en específico: Intel x86 (PC), PowerPC (Mac) y AMD64 (PC de 64 bits).
Ubuntu Linux es una distribución orientada al escritorio, aunque también es funcional para servidores, ofrece una instalación fácil y rápida, emisión regular de nuevas versiones, selección exhaustiva de excelentes paquetes instalados de manera predeterminada, además, existe un compromiso de ofrecer actualizaciones de seguridad por un lapso de 18 meses para cada una de las versiones.
¿Qué ofrece Ubuntu 5.10 en el escritorio?
-
GNOME 2.12, cuyo lanzamiento ocurrio ¡ayer!.
-
OpenOffice.org 2.0 (beta 2).
-
X.org 6.8.2, con excelente soporte de hardware.
-
Se ofrece una herramienta que facilita enormemente la instalación de nuevas aplicaciones, se puede ver en el menú System Administration -> Add/Remove Programs
-
Una nueva herramienta (Language Selector) que le permitirá instalar fácilmente el soporte para un idioma determinado.
-
Los menús en GNOME son editables.
-
Se ofrece soporte para la grabación de CDs, se utiliza la aplicación Serpentine.
-
Ahora podrá ver una barra de progreso (USplash) mientras su sistema se inicia.
Ubuntu 5.10 tambien ofrece algunos avances en cuanto a la rama de servidores y modos de instalación, en cuanto a los avances en el soporte de hardware nos encontramos con ciertos puntos interesantes, como por ejemplo.
-
Kernel 2.6.12.5 con actualizaciones de drivers provenientes de terceras partes.
-
Mejora en el soporte de hardware para portátiles.
-
Soporte (todo en uno) para los dispositivos (impresoras y scanners) HP.
-
Soporte para dispositivos Bluetooth de entrada (como teclados o ratones).
-
Mejoras en cuanto al manejo de dispositivos de sonido.
-
Disponibilidad del kernel para la arquitectura PowerPC (64 bits).
Puede seleccionar una imagen de la versión previa a la salida oficial de Ubuntu 5.10 al seguir el enlace Ubuntu 5.10 (Breezy Badger) Preview, si es posible realice la descarga usando Bittorrent, evitando la sobrecarga de los servidores.
COMO actualizar de manera segura su sistema
Antes de comenzar es importante hacer notar que esta guía se enfocará al mundo Debian GNU/Linux y sus derivadas, en donde por supuesto se incluye Ubuntu Linux. Después de hacer la breve aclaratoria podemos comenzar.
¿Es importante la firma de los paquetes?
La firma de los paquetes es una funcionalidad fundamental para evitar el posible cambio adrede en los ficheros binarios o fuentes distribuidos a través de sitios espejos (mirrors), de esta manera nos libramos de la posibilidad de un ataque man in the middle, el cual básicamente consiste en la intercepción de la comunicación entre el origen y el destino, el atacante puede leer, insertar y modificar los mensajes (en este caso particular, los ficheros) compartidos entre las partes sin que cada una de ellas se percate que la comunicación se ha visto comprometida.
Nuestro objetivo
Un sistema automatizado de actualización de paquetes, también es sumamente importante eliminar cualquier posibilidad de amenaza que pueda surgir al aprovecharse de la automatización del proceso de actualización, por ejemplo, debemos evitar a toda costa la distribución de troyanos que comprometarán la integridad de nuestros sistemas.
Un poco de historia…
No fue sino hasta la aparición de la versión 0.6 de la interfaz apt en donde se realiza la autenticación de ficheros binarios y fuentes de manera transparente haciendo uso de una Infraestructura de clave pública (en inglés, Public Key Infrastructure o PKI). La PKI se basa en el modelo GNU Privacy Guard (GnuPG) y se ofrece un enorme despliegue de keyservers internacionales.
Detectando la autenticidad de los paquetes
Como se menciono anteriormente desde la versión 0.6 de la interfaz apt se maneja de manera transparente el proceso de autentificación de los paquetes. Asi que vamos a hacer una prueba, voy a simular la instalación del paquete clamav.
$ sudo aptitude --simulate install clamav
Obteniendo por respuesta lo siguiente:
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado extendido
Inicializando el estado de los paquetes... Hecho
Se instalarán automáticamente los siguientes paquetes NUEVOS:
arj clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
Se instalarán los siguiente paquetes NUEVOS:
arj clamav clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
0 paquetes actualizados, 7 nuevos instalados, 0 para eliminar y 0 sin actualizar.
Necesito descargar 3248kB de ficheros. Después de desempaquetar se usarán 4193kB.
¿Quiere continuar? [Y/n/?] Y
The following packages are not AUTHENTICATED:
clamav clamav-freshclam clamav-base libclamav1
Do you want to continue? [y/N] N
Cancela.
Si nos fijamos bien en la respuesta anterior notaremos que ciertos paquetes no han podido ser autentificados. A partir de este punto es responsabilidad del administrador del sistema el instalar o no dichos paquetes, por supuesto, cada quien es responsable de sus acciones, yo prefiero declinar mi intento por el momento y asegurarme de la autenticidad de los paquetes, para luego proceder con la instalación normal.
Comienza la diversión
Ahora bien, vamos a mostrar la secuencia de comandos a seguir para agregar las llaves públicas dentro del keyring por defecto. Antes de entrar en detalle es importante aclarar que el ejemplo agregará la llave pública del grupo os-cillation, quienes se encargan de mantener paquetes para el entorno de escritorio Xfce (siempre actualizados y manera no-oficial) para la distribución Debian GNU/Linux (también sirven para sus derivadas, como por ejemplo Ubuntu Linux).
Importando la llave pública desde un servidor GPG
$ gpg --keyserver hkp://wwwkeys.eu.pgp.net --recv-keys 8AC2C0A6
El comando anterior simplemente importara la llave especificada (8AC2C0A6) desde el servidor con el cual se ha establecido la comunicación, el valor de la opción --keyserver sigue cierto formato, el cual es: esquema:[//]nombreservidor[:puerto], los valores ubicados entre corchetes son opcionales, cuando hablamos del esquema nos referimos al tipo de servidor, regularmente utilizaremos como esquema hkp para servidores HTTP o compatibles.
Si el comando anterior se ejecuto de manera correcta, el proceso nos arrojará una salida similar a la siguiente:
gpg: key 8AC2C0A6: public key "os-cillation Debian Package Repository
(Xfld Package Maintainer) <[email protected]>" imported
La instrucción anterior solamente variará de acuerdo al keyserver y la clave que deseemos importar. En www.pgp.net está disponible un buscador que le facilitará la obtención de los datos necesarios.
Exportando y añadiendo la llave pública
$ gpg --armor --export 8AC2C0A6 | sudo apt-key add -
Con el comando anterior procedemos a construir la salida en formato ASCII producto de la exportación de la llave especificada y a través del pipe capturamos la salida estándar y la utilizamos como entrada estándar en el comando apt-key add, el cual simplemente agregará una nueva llave a la lista de llaves confiables, dicha lista puede visualizarse al hacer uso del comando apt-key list.
Aunque parezca evidente la aclaratoria, recuerde que si usted no puede hacer uso de sudo, debe identificarse previamente como superusuario.
Finalmente…
Para finalizar recuerde que debe actualizar la lista de paquetes.
$ sudo aptitude update
Ahora podemos proceder a instalar los paquetes desde el repositorio que hemos añadido como fuente confiable.
Creando un repositorio local
Planteamiento del Problema:
Mantener actualizada una laptop (u ordenador de escritorio) de bajos recursos, con varios años de uso, el caso que se presenta es que el laptop en cuestión posee solo un puerto para conexiones por modem de velocidades topes de 56kbps, lo anterior puede ser traumático al realizar actualizaciones del sistema.
Consideraciones:
Nos aprovecharemos del hecho de la disponibilidad de un puerto USB en el ordenador de bajos recursos, el cual nos facilita en estos tiempos el almacenamiento masivo de paquetes, en caso de no tener puerto USB, podemos recurrir a unidades de CD como medio de almacenamiento masivo.
Adicionalmente, aprovecharemos conexiones de gran bando de ancha, lo cual nos facilitará la descarga de los paquetes necesarios desde los repositorios disponibles en la red.
Posible solución:
Después de plantear las consideraciones anteriores, una posible alternativa para mantener actualizados nuestros ordenadores de bajos recursos es utilizar dispositivos de almacenamiento masivo como repositorios locales, almacenando en ellos solo los paquetes que sean realmente necesarios.
En los siguientes puntos trataré de ampliar la manera de crear un repositorio local valiéndonos del uso de un Pen Drive.
Comenzamos:
En primer lugar vamos a respaldar los paquetes *.deb que se ubican en /var/cache/apt/archives, esta actividad la vamos a realizar en el ordenador que dispone de una conexión banda ancha.
$ mkdir $HOME/backup
$ sudo cp /var/cache/apt/archives/*.deb $HOME/backup
Después de respaldar los paquetes, vamos a remover todos los ficheros *.deb que han sido descargados al directorio cache que almacena los paquetes, usualmente esto quiere decir, eliminar todos los paquetes *.deb ubicados en /var/cache/apt/archives, para ello hacemos lo siguiente:
$ sudo aptitude clean
Ahora que se encuentra limpio el directorio cache procederemos a descargar (sin instalar) los paquetes que sean necesarios para nuestro ordenador de bajos recursos. Para ello hacemos lo siguiente:
$ sudo aptitude -d install <paquetes>
El comando anterior simplemente descargará la lista de paquetes especificada
(recuerde que debe sustituir
Para trabajar mas cómodamente crearemos una carpeta temporal y desde allí procederemos a crear nuestro repositorio local en cuestión, el cual finalmente se guardará en el medio de almacenamiento masivo correspondiente.
$ mkdir /tmp/debs
$ mv /var/cache/apt/archives/*.deb /tmp/debs/
$ cd /tmp
Estando ubicados en el directorio /tmp realizaremos una revisión de los paquetes que se ubican en el directorio debs/ y crearemos el fichero comprimido Packages.gz (el nombre del fichero debe ser exacto, no es cuestión de elección personal).
$ dpkg-scanpackages debs/.* | gzip > debs/Packages.gz
Guardando el repositorio en un dispositivo de almacenamiento masivo
En nuestro caso procederé a explicar como almacenar el repositorio en un Pen Drive, por ciertas cuestiones prácticas, primero, facilidad de movilidad que presentan, la capacidad de almacenamiento, la cual regularmente es mayor a la de un CD.
En la versión actual (Hoary) de Ubuntu Linux los Pen Drive son montados automáticamente, si esto no ocurre, puede realizar lo siguiente:
$ sudo mount -t vfat /dev/sda1 /media/usbdisk
Recuerde ajustar los argumentos de acuerdo a sus posibilidades. Luego de montado el dispositivo de almacenamiento masivo proceda a copiar de manera recursiva el directorio debs/.
$ cp -r /tmp/debs/ /media/usbdisk
Estableciendo el medio de almacenamiento masivo como un repositorio.
Si ha decidido utilizar un Pen Drive como medio de almacenamiento.
Después de copiar los ficheros en el medio de almacenamiento masivo, proceda a
desmontarlo (en nuestro caso: $ sudo umount /media/usbdisk) y conectelo a su
ordenador de bajos recursos, recuerde que si el ordenador de bajos recursos no
monta automáticamente el dispositivo, debe montarlo manualmente como se explico
anteriormente.
Después de haber sido reconocido el dispositivo de almacenamiento masivo en el ordenador de bajos recursos proceda a editar el fichero /etc/apt/sources.list y agregue la linea deb file:/media/usbdisk debs/. Comente los demás repositorios existentes, recuerde que para ello simplemente debe agregar el carácter almohadilla (#) al principio de la linea que especifica a dicho repositorio.
Si ha decidido utilizar un CD como medio de almacenamiento
Simplemente haciendo uso de apt-cdrom add le bastará, esto añadirá el medio a
la lista de recursos del fichero sources.list
Finalizando…
Para finalizar deberá actualizar la lista de paquetes disponibles y proceder con la instalación de dichos paquetes en el ordenador de bajos recursos, para ello, simplemente bastará con hacer lo siguiente:
$ sudo aptitude update
$ sudo aptitude install <paquetes>
Recuerde restaurar en el ordenador que dispone de conexión banda ancha los paquetes que se respaldaron previamente.
$ sudo mv $HOME/backup/*.deb /var/cache/apt/archives/
¡Que lo disfrute! :D
Organizando nuestros proyectos web
Antes de plantearme el rediseño de este sitio, pensé en organizar ciertas cosas para no complicarme la vida. En primera instancia procedi a instalar el servidor Apache, el soporte del lenguaje PHP, el servidor de bases de datos MySQL y finalmente el phpMyAdmin.
Lo anterior se resume de la siguiente manera en mi querido Ubuntu Linux.
$ sudo aptitude install apache2
$ sudo aptitude install mysql-server
$ sudo aptitude install php4
$ sudo aptitude install libapache2-mod-auth-mysql
$ sudo aptitude install php4-mysql
$ sudo /etc/init.d/apache2 restart
$ sudo aptitude install phpmyadmin
Recuerde después de instalar el servidor de bases de datos MySQL establecer la contraseña del usuario root de dicho servidor por seguridad. Si no sabe como hacerlo a través de la línea de comandos existe la alternativa de establecer la contraseña utilizando phpMyAdmin.
Por defecto el servidor Apache habilita el directorio /var/www/ como directorio principal, el problema que se plantearía el trabajar en dicho directorio es que cada vez que tuviese que realizar cambios a los ficheros tendría que hacer uso de la cuenta de superusuario o root, lo cual no me agrada mucho, así que para evitar lo mencionado previamente tenía dos opciones.
La primera de ellas era modificar el fichero /etc/apache2/apache.conf y habilitar que todos los usuarios tuviesen la posibilidad de publicar sus documentos dentro del directorio /home/*/public_html, esta opción no me llamaba mucho la atención, adicionalmente, la dirección queda de cierta manera algo extensa (p.ej. http://localhost/~usuario/proyectoweb), así que opte por recurrir a una segunda opción, la cual describiré detalladamente a continuación.
En primera instancia creé dos directorios, public_html como subdirectorio de $HOME, el segundo, milmazz como subdirectorio de public_html.
$ mkdir $HOME/public_html
$ mkdir $HOME/public_html/milmazz
Seguidamente procedi a crear el fichero /etc/apache2/sites-enabled/001-milmazz, este fichero contendrá las directivas necesarias para nuestro proyecto desarrollado en un ambiente local.
<VirtualHost *>
DocumentRoot "/home/milmazz/public_html/milmazz/"
ServerName milmazz.desktop
<Directory "/home/milmazz/public_html/milmazz/">
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order deny,allow
Deny from all
Allow from 127.0.0.0/255.0.0.0 ::1/128
</Directory>
</VirtualHost>
Ahora bien, necesitamos crear el host para que la directiva realmente redireccione al directorio /home/milmazz/public_html/milmazz/ simplemente tecleando milmazz.desktop en la barra de direcciones de nuestro navegador preferido. Por lo tanto, el siguiente paso es editar el fichero /etc/hosts y agregar una línea similar a 127.0.0.1 milmazz.desktop, note que el segundo parámetro especificado es exactamente igual al especificado en la directiva ServerName.
Seguidamente procedi a instalar WordPress (Sistema Manejador de Contenidos) en el directorio $HOME/public_html/milmazz y todo funciona de maravilla.
Evitando el acceso de usuarios no permitidos
Si queremos restringir aún más el acceso al directorio que contendrá los ficheros de nuestro proyecto web, en este ejemplo, el directorio es $HOME/public_html/milmazz/, realizaremos lo siguiente:
$ touch $HOME/public_html/milmazz/.htaccess
$ nano $HOME/public_html/milmazz/.htaccess
Dentro del fichero .htaccess insertamos las siguientes lineas.
AuthUserFile /var/www/.htpasswd
AuthGroupFile /dev/null
AuthName "Acceso Restringido"
AuthType Basic
require valid-user
Guardamos los cambios realizados y seguidamente procederemos a crear el fichero que contendrá la información acerca de los usuarios que tendrán acceso al directorio protegido, también se especificaran las contraseñas para validar la entrada. El fichero a editar vendra dado por la directiva AuthUserFile, por lo tanto, en nuestro caso el fichero a crear será /var/www/.htpasswd.
htpasswd -c /var/www/.htpasswd milmazz
Seguidamente introducimos la contraseña que se le asignará al usuario milmazz, la opción -c mostrada en el código anterior simplemente se utiliza para crear el fichero /var/www/.htpasswd, por lo tanto, cuando se vaya a autorizar a otro usuario cualquiera la opción -c debe ser ignorada.
Estableciendo la contraseña del usuario root del servidor de bases de datos a través de phpMyAdmin.
Si usted no sabe como establecer en línea de comandos la contraseña del usuario root en el servidor de bases de datos MySQL es posible establecerla en modo gráfico haciendo uso de phpMyAdmin.
A continuacion se describen los pasos que deberá seguir:
- Acceder a la interfaz del phpMyAdmin, para lograrlo escribe en la barra de direcciones de tu navegador http://localhost/phpmyadmin.
- Selecciona la opción de Privilegios, ésta se ubica en el menú principal.
- Debemos editar los dos últimos registros, uno representa el superusuario cuyo valor en el campo servidor será equivalente al nombre de tu máquina, el otro registro a editar es aquel superusuario cuyo valor en el campo servidor es igual a localhost. Para editar los registros mencionados anteriormente simplemente deberá presionar sobre la imagen que representa un lapíz.
- Los únicos campos que modificaremos de los registros mencionados previamente son aquellos que tienen relación con la contraseña. Recuerde que para guardar los cambios realizados al final debe presionar el botón Continúe. Si deseas evitar cualquier confusión en cuanto al tema de las contraseñas es recomendable que establezcas la misma en ambos registros.
Agradecimientos
A José Parella por sus valiosas indicaciones.
Primer Congreso Nacional de Software Libre
El día de hoy se dió inicio en Mérida al Primer Congreso Nacional de Software Libre, el cual es auspiciado por el Grupo de Usuarios de GNU/Linux de Venezuela UNPLUG. El objetivo de este congreso es promocionar el uso, implementación, características y posibilidades del Software Libre en Venezuela, generando una estructura de soporte y apoyo a los diferentes Grupos de Usuarios de GNU/Linux y Software Libre en todo el territorio nacional.
Las charlas de día de hoy han sido:
- El Software Libre y GNU/Linux, Ponente: Octavio Rossell
- Diseño Gráfico Digital en Software Libre, Ponente: Leonardo Caballero
- ¿Por qué Open Office es la alternativa?, Ponente: Joskally Carrero
- La respuesta está en el Software Libre, Ponente: Francisco Palm
- Sistemas de Información Geográfica en GNU, Ponente: Damian Fossi
Las charlas del día de mañana serán:
- Fábrica del Software Libre, Ponente: Javier Riviera
- Software Libre como palanca para el desarrollo endógeno, Ponente: Mariángela Petrizzo
- El Software Libre en la Educación Universitaria, Ponente: Samuel Rojas
- Redes Inalámbricas bajo Software Libre, Ponente: Walter Vargas
- Metodología de Migración hacia el Software Libre, Ponente: Jorge González
- El escritorio en GNU/Linux, Ponente: Vladimir Llanos
Según anuncio Octavio Rossell al finalizar la jornada del día de hoy, la entrada el día de mañana será libre al público en general. La jornada del día de mañana comenzará a las 9:00 a.m. hora local.
En los próximos días trataré hacer un resúmen acerca de las charlas, ya estoy tomando notas.
Beagle
Beagle es una poderosa herramienta de búsqueda escrita en C# usando Mono y Gtk# que le permitirá buscar hasta en lo más recóndito de su espacio personal y de esta manera encontrar lo que está buscando. Beagle también puede buscar en distintos dominios.
Usando Beagle ud. fácilmente podrá encontrar.
- Documentos.
- Correos electrónicos.
- Historial web.
- Conversaciones de Mensajería Instantánea o del IRC.
- Código fuente.
- Imagénes.
- Ficheros de audio.
- Aplicaciones.
- Otros…
Beagle puede extraer información desde:
- Evolution, tanto los correos electrónicos como de la libreta de contactos.
- Gaim, desde los registros de mensajería instantánea.
- Firefox, páginas web.
- Blam y Liferea, agregadores RSS.
- Tomboy, notas.
De manera adicional Beagle soporta los siguientes formatos.
- OpenOffice.org
- Microsoft Office (
doc,ppt,xls). - HTML.
- PDF.
- Imágenes (jpeg, png).
- Audio (mp3, ogg, flac).
- AbiWord.
- Rich Text Format (RTF).
- Texinfo.
- Páginas del manual (man pages).
- Código Fuente (C, C++, C#, Fortran, Java, JavaScript, Pascal, Perl, PHP, Python).
- Texto sin formato.
Beagle aún se encuentra en una etapa temprana de desarrollo, así que aún faltan muchas características que le darían un plus a esta herramienta, por ejemplo, agregar el soporte a los sistemas de ficheros: NFS, Reiser4, NTFS y FAT.
En el caso de los sistemas de ficheros tipo FAT, muchos usuarios aún emplean este tipo de particiones para compartir datos entre los mundos GNU/Linux y Windows, por lo que sería conveniente el hecho de agregar esta funcionalidad a esta estupenda herramienta.
Si desea comenzar con esta herramienta, le recomiendo leer los primeros pasos del wiki de Beagle. A los usuarios de Ubuntu Linux le recomiendo la serie de pasos mostrados en el tema ¿Cómo instalar el buscador Beagle? de guia-ubuntu.org.
Existen algunas demostraciones sobre el uso de Beagle, propuestas por Nat Friedman, en una de ellas se podrá apreciar la funcionalidad de “búsqueda en vivo”, para ello es necesario activar el soporte de Inotify.
Inotify es un sistema de notificación de ficheros para el núcleo (kernel) de Linux. Actualmente esta característica no es incluida en la serie estable del núcleo de Linux, por lo que es muy probable que deba añadir esta característica al núcleo por si solo para poder utilizarlo. Existen algunas versiones del núcleo para distribuciones que si incluyen el soporte a Inotify.
Beagle como tal no requiere de Inotify para funcionar, solamente se recomienda su uso puesto que mejora la experiencia del usuario. Sin el soporte de Inotify, Beagle no podrá detectar automáticamente (en vivo) todos los cambios en su directorio personal, por lo que no podrá indexar los datos de manera oportuna.
De manera oportuna, los usuarios de Ubuntu Linux tienen cierta ventaja, no será necesario reparar el núcleo ni compilarlo, solamente hay que añadir la opción de Inotify en el fichero de configuración de Grub, de la manera siguiente:
$ sudo vi /boot/grub/menu.lst
title Ubuntu, kernel 2.6.10-5-k7
root (hd0,5)
kernel /vmlinuz-2.6.10-5-k7 root=/dev/hda8 ro quiet splash <strong>inotify</strong>
initrd /initrd.img-2.6.10-5-k7
savedefault
boot
Luego de hacer los cambios al fichero de configuración del gestor de arranque Grub, procedemos a actualizarlo.
$ sudo update-grub
Si utilizas Firefox y deseas que Beagle indexe las páginas que vas navegando, seguramente desearás instalar esta extensión.
ImageMagick
ImageMagick, es una suite de software libre, sirve para crear, editar y componer imágenes en mapa de bits. Puede leer, convertir y crear imágenes en una larga variedad de formatos (más de 90 formatos soportados). Las imágenes pueden ser cortadas, los colores pueden ser cambiados, ciertos efectos pueden ser aplicados, las imágenes pueden rotadas y combinadas, se pueden agregar a las imágenes, textos, líneas, polígonos, elipses, entre otros.
Es una suite realmente potente bajo la línea de comandos, puede ver una serie de ejemplos, esto le demostrará lo que puede llegar a hacer con esta eficaz aplicación.
Esta herramienta me ha facilitado enormemente el procesamiento de gran cantidad de imágenes que requieren el mismo tratamiento, solamente con una línea de comandos voy a establecer todas las opciones que deseo. Por ejemplo:
convert origen.jpg -resize 50% -bordercolor "#666"
-border 4 destino.png
Imagen Original -> Imagen modificada con ImageMagick.
{kind=link}
{kind=link}
Con esta simple línea de comandos estoy realizando las siguientes conversiones sobre la imagen origen.jpg, en primer lugar estoy reduciendo las proporciones de anchura y altura al 50%, posteriormente estoy designando el color del borde al valor hexadecimal (#666, gris), el ancho de dicho borde será de 4px, finalmente estoy cambiando el formato de la imagen, estoy convirtiendo de jpg a png, los resultados se podrán apreciar en la imagen destino.png. Ahora bien, imagínese procesar 500 imágenes desde una aplicación con interfaz gráfica que le brinde la rapidez que le ofrece ImageMagick, creo que hasta la fecha es imposible, por lo que resulta un buen recurso el emplear esta herramienta para el procesamiento de grandes lotes de imágenes.
Ahora vamos a “jugar” un poco para colocar una “marca de agua” a la imagen en cuestión.
convert origen.jpg -resize 50% -bordercolor "#666"
-border 4 -font "Bitstream Vera Sans" -pointsize 16 -gravity SouthEast
-fill "#FFF" -draw "text 10,10 'http://blog.milmazz.com.ve'" destino.png
Imagen Original -> Imagen modificada con ImageMagick.
{kind=link}
{kind=link}
Esta vez el número de opciones que he empleado han aumentado ligeramente. Vamos
a explicar brevemente cada una de ellas, la opción font nos permite elegir una
fuente, en el ejemplo he escogido la fuente Bitstream Vera Sans, la opción
pointsize permite escoger el tamaño de la fuente, la opción gravity nos permite
establecer la colocación horizontal y vertical del texto, he elegido la
primitiva SouthEast, la cual colocará el texto en la parte inferior derecha de
la imagen, la opción fill me permite establecer el color de relleno del texto
que se dibujará con la opción draw, esta última opción escribirá la cadena
http://blog.milmazz.com.ve.
Para mayor información acerca de las distintas opciones que puede manejar le recomiendo leer detenidamente la descripción de las herramientas en línea de comando de ImageMagick.
Elizabeth Garbeth
Elizabeth Garbeth, una niña de apenas 13 años de edad, dará este año una presentación en una conferencia de GNU/Linux en Australia, su presentación es Extending Tuxracer - Learning by Playing. En este seminario, Elizabeth describirá como crear nuevos recorridos para competir en Tuxracer y demostrará los pasos que están envueltos para realizar tal operación.
A pesar de los pocos años que ha vivido Elizabeth, ha tenido bastante contacto con los ordernadores y el mundo GNU/Linux desde muy pequeña, su historia es realmente impresionante.
I have had my own computer since I turned two. By the time I was nine, my computer ran Debian… and before I turned ten my dad convinced me to install Debian for him on the server that became raff.debian.org. That just proves that installing Debian really isn’t very hard, particularly when my Dad is around to answer questions! I also play the violin, am treasurer of my 4H club, and have performed in musicals at my school.
Bdale Garbee, Linux CTO para HP y sirve como lider del proyecto Debian, es el padre de Elizabeth, así que se podrán imaginar la influencia que ha generado éste en su hija, de hecho, Bdale le planteó el reto a su hija de aprender a como crear sus propios recorridos en el juego Tuxracer, puesto que Elizabeth le dijo que al igual que muchos juegos de computadora, al inicio Tuxracer es divertido, pero que eventualmente te fue cansando de recorrer los mismos caminos de siempre. Elizabeth no solamente cumplió el reto planteado por su padre, sino que ahora hará una presentación sobre ello.
deborphan, eliminando librerias huérfanas
deborphan simplemente se encarga de buscar librerias huérfanas. Se mostrará un listado de paquetes que posiblemente no fueron desinstalados en su momento y que actualmente no son requeridas en el sistema por ningún otro paquete o aplicación. Esta aplicación es realmente útil para mantener “limpio” el sistema en caso de ser necesario.
Para instalar deborphan en nuestro sistema simplemente debe proceder como sigue:
sudo apt-get install deborphan
Para remover todos los paquetes huérfanos encontrados simplemente debemos proceder como sigue:
sudo deborphan | sudo xargs apt-get remove -y
Esta aplicación me ha sido realmente útil, sobretodo por la reciente actualización que he realizado en la versión mi distribución Ubuntu Linux, la versión anterior era Warty Warthog (v.4.10), la nueva es Hoary Hedgehog (v.5.04). En dicha actualización ocurrieron muchos “rompimientos” de dependencias, muchas librerias quedaron huérfanas, con esta aplicación he depurado el sistema.
Renombrando ficheros con rename
Si ud. es una de esas personas que al igual que yo le gusta ahorrar tiempo en
esas tareas cotidianas que a veces se convierten en algo aburridas por lo
repetitivas que suelen ser, seguramente este breve artículo acerca del uso de
rename le va a interesar, puedo asegurarle que le facilitará la vida, claro,
siempre y cuando ud. regularmente modifique nombres de ficheros. Seguramente se
ha encontrado alguna vez que el formato de nombres de los ficheros de audio
(p.ej. mp3) no le parece el adecuado, en estas situaciones lo más recomendable
es recurrir a rename, ya que éste último le automátizara el renombrado de los
ficheros al indicarle un parámetro, el cual será una expresión regular de Perl.
Algunos ejemplos de esto son los siguientes:
milton@omega ~ $ ls
01 - Main Theme From Star Wars & Leia's Nightmare.mp3
milton@omega ~ $ rename 's/\ -\ /-/' *.mp3
Obtenemos como resultado lo siguiente:
milton@omega ~ $ ls
01-Main Theme From Star Wars & Leia's Nightmare.mp3
Como pudo haberse dado cuenta el comando rename 's/\ -\ /-/' *.mp3 simplemente
sustituyó la cadena “ - “ por ‘-‘, recuerde que los espacios en sistemas
GNU/Linux son “carácteres especiales”, por lo tanto, al carácter debe
precederle una barra invertida (**), los ficheros que modificará son aquellos
que posean la extensión **mp3.
También puede notar que en el nombre del fichero anterior aún existen espacios en blanco, si deseamos convertir dichos espacios en blanco por el carácter ‘_’, simplemente realizamos lo siguiente:
milton@omega ~ $ rename 'y/\ /_/' *.mp3<br></br>
milton@omega ~ $ ls<br></br>
01-Main_Theme_From_Star_Wars_&_Leia's_Nightmare.mp3
Como puede darse cuenta, el comando rename 'y/\ /_/' *.mp3 sustituirá
todos los carácteres que representan los espacios en blanco por el carácter ‘-‘
en todos los nombres ficheros con extensión mp3.
Otra posibilidad interesante que tenemos es la de convertir todos los carácteres en mayúsculas a mínusculas y viceversa.
milton@omega ~ $ ls
10_MOS_EISLEY_SPACEPORT.mp3
milton@omega ~ $ rename -v 'y/A-Z/a-z/' *.mp3
10_MOS_EISLEY_SPACEPORT.mp3 renamed as 10_mos_eisley_spaceport.mp3
Como vemos, el cambio es realmente sencillo, al utilizar la opción -v simplemente estamos habilitando la impresión de los nombres de los archivos que se han modificado correctamente, esta opción es bastante útil para percatarnos de los cambios que se han generado.
Este tratamiento también es aplicable para renombrar directorios, recuerde que los directorios en sistemas GNU/Linux son tratados de manera equivalente a los archivos, así que vamos a mostrar un ejemplo para aclarar la situación.
milton@omega ~ $ ls
Shadows of the Empire
Star Wars A New Hope
Star Wars Attack Of The Clones
Star Wars Return of the Jedi
Star Wars The Empire Striks Back
Star Wars The Phantom Menace
Arriba vemos los directorios que representan la mayoría de los álbumes de la colección de Star Wars, por comodidad, regularmente suelo hacer una estructura similar a la siguiente: Music » Artista » Título del Álbum » #Pista-Nombre de la Pista. Por lo que los títulos de los álbumes deben ser especificos, no deben contener el nombre del artista. En mi caso he cambiado los nombres de los directorios de la siguiente manera:
milton@omega ~ $ rename -v 's/Star\ Wars\ //' *
Star Wars A New Hope renamed as A New Hope
Star Wars Attack Of The Clones renamed as Attack Of The Clones
Star Wars Return of the Jedi renamed as Return of the Jedi
Star Wars The Empire Striks Back renamed as The Empire Striks Back
Star Wars The Phantom Menace renamed as The Phantom Menace
En el ejemplo anterior simplemente se ha eliminado la cadena “Star Wars “. Es de suponer que el directorio Shadows of the Empire no será renombrado ya que no cumple con las pautas necesarias.
Es importante aclarar, que éste no es el único método existente para la
modificación de los nombres de los ficheros, existen muchos otros, pero desde mi
punto de vista, el uso de rename me parece bastante adecuado y fácil de
implantar.
Software
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234

Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Sistema de manejo y seguimiento de proyectos: Trac
Trac es un sistema multiplataforma desarrollado y mantenido por Edgewall Software, el cual está orientado al seguimiento y manejo de proyectos de desarrollo de software haciendo uso de un enfoque minimalista basado en la Web, su misión es ayudar a los desarrolladores a escribir software de excelente calidad mientras busca no interferir con el proceso y políticas de desarrollo. Incluye un sistema wiki que es adecuado para el manejo de la base de conocimiento del proyecto, fácil integración con sistemas de control de versiones ((Por defecto Trac se integra con subversion)). Además incluye una interfaz para el seguimiento de tareas, mejoras y reporte de errores por medio de un completo y totalmente personalizable sistema de tickets, todo esto con el fin de ofrecer una interfaz integrada y consistente para acceder a toda información referente al proyecto de desarrollo de software. Además, todas estas capacidades son extensibles por medio de plugins o complementos desarrollados específicamente para Trac.
Breve historia de Trac
El origen de Trac no es una idea original, algunos de sus objetivos se basan en los diversos sistemas de manejo y seguimiento de errores que existen en la actualidad, particularmente del sistema CVSTrac y sus autores.
Trac comenzó como la reimplementación del sistema CVSTrac en el lenguaje de programación Python y como ejercicio de entretenimiento, además de utilizar la base de datos embebida SQLite ((Hoy día también se le da soporte a PostgreSQL, mayor detalle en Database Backend)). En un corto lapso de tiempo, el alcance de estos esfuerzos iniciales crecieron en gran medida, se establecieron metas y en el presente Trac presenta un curso de desarrollo propio.
Los desarrolladores de Edgewall Software esperan que Trac sea una plataforma viable para explorar y expandir el cómo y qué puede hacerse con sistemas de manejo de proyectos de desarrollo de software basados en sistemas wiki.
Características de Trac
A continuación se presenta una descripción breve de las distintas características de Trac.
Herramienta de código abierto para el manejo de proyectos
Trac es una herramienta ligera para el manejo de proyectos basada en la Web, desarrollada en el lenguaje de programación Python. Está enfocada en el manejo de proyectos de desarrollo de software, aunque es lo suficientemente flexible para usarla en muchos tipos de proyectos. Al ser una herramienta de código abierto, si Trac no llena completamente sus necesidades, puede aplicar los cambios necesarios usted mismo, escribir complementos o plugins, o contratar a alguien calificado que lo haga por usted.
Sistema de tickets

El sistema de tickets le permite hacer seguimiento del progreso en la resolución de problemas de programación particulares, requerimientos de nuevas características, problemas e ideas, cada una de ellas en su propio ticket, los cuales son enumerados de manera ascendente. Puede resolver o reconciliar aquellos tickets que buscan un mismo objetivo o donde más de una persona reporta el mismo requerimiento. Permite hacer búsquedas o filtrar tickets por severidad, componente del proyecto, versión, responsable de atender el ticket, entre otros.
Para mejorar el seguimiento de los tickets Trac ofrece la posibilidad de activar notificaciones vía correo electrónico, de este modo se mantiene informado a los desarrolladores de los avances en la resolución de las actividades planificadas.
Vista de progreso
Existen varias maneras convenientes de estar al día con los acontecimientos y cambios que ocurren dentro de un proyecto. Puede establecer hitos y ver un mapa del progreso (así como los logros históricos) de manera resumida. Además, puede visualizar desde una interfaz centralizada los cambios ocurridos cronológicamente en el wiki, hitos, tickets y repositorios de código fuente, comenzando con los eventos más recientes, toda esta información es accesible vía Web o de manera alternativa Trac le ofrece la posibilidad de exportar esta información a otros formatos como el RSS, permitiendo que los usuarios puedan observar esos cambios fuera de la interfaz centralizada de Trac, así como la notificación por correo electrónico.

Vista del repositorio en línea
Una de las características de mayor uso en Trac es el navegador o visor del repositorio en línea, se le ofrece una interfaz bastante amigable para el sistema de control de versiones que esté usando ((Por defecto Trac se integra con subversion, la integración con otros sistemas es posible gracias a plugins o complementos.)). Este visualizador en línea le ofrece una manera clara y elegante de observar el código fuente resaltado, así como también la comparación de ficheros, apreciando fácilmente las diferencias entre ellos.

Manejo de usuarios
Trac ofrece un sistema de permisología para controlar cuales usuarios pueden acceder o no a determinadas secciones del sistema de manejo y seguimiento del proyecto, esto se logra a través de la interfaz administrativa. Además, esta interfaz es posible integrarla con la definición de permisos de lectura y escritura de los usuarios en el sistema de control de versiones, de ese modo se logra una administración centralizada de usuarios.
Wiki
El sistema wiki es ideal para mantener la base de conocimientos del proyecto, la cual puede ser usada por los desarrolladores o como medio para ofrecerles recursos a los usuarios. Tal como funcionan otros sistemas wiki, puede permitirse la edición compartida. La sintaxis del sistema wiki es bastante sencilla, si esto no es suficiente, es posible integrar en Trac un editor WYSIWYG (lo que se ve es lo que se obtiene, por sus siglas en inglés) que facilita la edición de los documentos.
Características adicionales
Al ser Trac un sistema modular puede ampliarse su funcionalidad por medio de complementos o plugins, desde sistemas anti-spam hasta diagramas de Gantt o sistemas de seguimiento de tiempo.
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
Identificar el Hardware de tu PC en Debian GNU/Linux
Bien, lo que vamos a hacer a continuación es muy fácil, tán fácil como instalar un paquete, luego ejecutarlo y leer la información que él nos “escupe” (me encanta como suena :) ). Como sabrán, soy usuario de Debian GNU/Linux en su versión Etch para la arquitectura AMD64, pero ésto en realidad no es tan relevante ya que el paquete se encuentra tanto en Testing como en Stable para la mayoría de las arquitecturas y en la sección main de los repositorios.
Lo que vamos a instalar es el paquete lshw-gtk, que bien como dice en la descripción del paquete: “es una pequeña herramienta que provee información detallada de la configuración de hardware de la máquina. Puede reportar la configuración exacta de la memoria, versión de firmware, configuración de la tarjeta madre, versión del procesador y su velocidad, configuración de la caché, velocidad del bus, etc. en sistemas x86 con soporte DMI, en algunas máquinas PowerPC (se sabe de su funcionamiento en las PowerMac G4) y ADM64”.
Como ya sabrán, para instalar el paquete es tan sencillo como abrir una terminal y escribir en modo superusuario los siguiente:
# aptitude install lshw-gtk
El paquete no es muy pesado, de hecho, con todo y dependencias a penas ha de superar el mega de información, por lo que el proceso de instalación es rápido (si se tiene una conexión decente claro).
Una vez instalado el paquete no tenemos que hacer más que ejecutarlo. Para poder ejecutarlo debemos hacerlo desde una terminal, ya que según tengo entendido, no se instala en los menús del Gnome. Así que debemos escribir en una terminal (en modo superusuario):
# lshw-gtk
y listo, se ejecutará perfectamente, dejándonos navegar por unos paneles donde se encuentran los distintos componentes de nuestro sistema.
Si lo que quieres es tener un lanzador en los menús del Gnome, es muy sencillo, sólo deberás crear uno de la siguiente manera. Abre una terminal en modo superusuario y escribe lo siguiente:
gedit /usr/share/applications/LSHW.desktop
luego de presionar la tecla Enter se abrirá una ventana con el gedit en la cual deberás pegar el siguiente texto:
[Desktop Entry]
Name=LSHW
Comment=Identifica el hardware del sistema
Exec=gksu lshw-gtk
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya con eso deberías tener tu lanzador en el menú Aplicaciones –> Herramientas del sistema. Vas a necesitar de permisos de superusuario para poder ejecutarlo.
Acá una imagen de como se ve el lshw-gtk:
Compilar aMSN en Debian Etch AMD64
Bien, sin mucho preámbulo, lo primero que debemos hacer es descargar el tarball de la página de amsn. Luego deberás descomprimirlo en la carpeta de tu preferencia, en mi caso está en ~/Sources/amsn-0.96RC1/. Una vez que lo descomprimes abre una terminal y obtén derechos de administrador (modo root); cuando tengas privilegios de root ubícate en el directorio donde descomprimiste el tarball y escribe lo siguiente:
$ ./configure
$ make
$ make install
Debes asegurarte de cumplir todos los requisitos cuando haces el ./configure, ya que te pide varias “dependencias” por así decirlo, como por ejemplo, tls y tk. Una vez que hayas hecho el make install quedará automágicamente instalado el amsn en tu sistema. Deberás poder verlo en Aplicaciones –> Internet –> aMSN. Bien eso es todo en lo que respecta al proceso de compilado, ¿nunca antes fué tan fácil verdad?.
Un problema que me dió una vez que lo compilé y lo ejecuté fué que no me permitía iniciar sesión porque me decía que no tenía instalado el módulo TLS. Entonces abrí una terminal e hice lo siguiente:
$ aptitude install tcltls
…pero ésto no me solucionó el problema, entonces me puse a indagar por la web y me encontré con la siguiente solución: editar el archivo /usr/lib/tls1.50/pkgIndex.tcl y ubicar la línea que dice algo como: package ifneeded tls 1.5 para entonces modificarla por package ifneeded tls 1.50 y listo :D
StarDict: El diccionario que buscaba
Leyendo el ejemplar #14 de la revista Tux Magazine me encuentro con un interesante artículo, Learning Foreign Languages with jVLT and StarDict, la segunda aplicación descrita en dicho artículo, StartDict, llamó mi atención, así que a continuación se dará una breve revisión de la aplicación en cuestión.
¿Qué es StarDict?
StarDict es un diccionario internacional multiplataforma escrito en Gtk2, puede ser utilizado sin conexión a la web.
Características
-
Búsqueda de patrones: Usted puede buscar patrones de cadenas o caracteres usando comodines, por ejemplo, podrá usar el comodín
*para buscar una cadena arbitraria, el resultado puede ser vacío, mientras que con el uso del comodín?buscará una coincidencia con un carácter arbitrario. e.g. Suponiendo que tiene instalado el diccionario Inglés – Español, al buscar el patrón hell? encontrará como resultado la traducción de hello, mientras que con el uso del patrón hell* encontrará todas aquellas posibles coincidencias que comiencen con la cadena hell, hell (infierno en inglés), hell (suerte en noruego), los resultados encontrados dependerá de los diccionarios que haya instalado. - Búsqueda difusa: Si usted por casualidad no recuerda exactamente como deletrear una palabra, podrá intentar realizar dicha búsqueda desde StarDict, éste utilizará el algoritmo de la Distancia de Levenshtein El algoritmo de la Distancia de Levenshtein o la distancia de edición entre dos cadenas, se refiere al número mínimo de operaciones necesarias para transformar una cadena en otra, bajo éste algoritmo se considera una operación a la inserción, eliminación o substitución de un carácter. Para mayor información le recomiendo leer el artículo Levenshtein Distance, in Three Flavors.. Para utilizar esta característica simplemente comience la búsqueda con el carácter /, e.g., suponga que tiene instalado el diccionario Español – Inglés, usted cree que la palabra acero realmente se escribe así: asero, simplemente introduzca en el formulario la cadena /asero, obtendrá el resultado deseado.
-
Búsqueda por palabras seleccionadas: Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada.
-
Manejo de diccionarios: StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen).
- ¿No encuentra lo que necesita?: StarDict le permite realizar búsquedas en la web, solo deberá seleccionar el botón de búsqueda en Internet y escoger cualquiera de las 10 opciones actuales de búsqueda.
Ahora bien, seguramente esta aplicación resultará útil para muchas personas, si usted es uno de ellos y está interesado en instalarlo, es muy sencillo.
¿Cómo instalar StarDict?
Si usted es tan afortunado como yo, debe estar usando Debian, así que simplemente tendrá que hacer:
# aptitude install stardict
Ahora bien, si usted utiliza por ejemplo, Ubuntu, también puede instalarlo fácilmente, ¿cómo?, en primer lugar debe activar el repositorio universe (recuerde actualizar la lista de paquetes disponibles), posteriormente debe hacer:
$ sudo aptitude install stardict
Si usted utiliza otra distribución de GNU+Linux o es usuario de Windows, lea la documentación de la página oficial del proyecto, lamento informarle que este artículo es una revisión breve de la aplicación StarDict.
¿Cómo instalar diccionarios?
Primero que nada, debe descargar los diccionarios que necesite, para ello le recomiendo ir a la página de Descarga de Diccionarios del proyecto.
Una vez que haya descargado los diccionarios, debe proceder como sigue:
tar -C /usr/share/stardict/dic -x -v -j -f \\
diccionario.tar.bz2
Personalizando la aplicación
Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Una característica de StarDict que puede resultar realmente molesta es cuando se encuentra activo el modo Scan, es decir, toda palabra o frase resaltada con el ratón generará un cuadro de dialogo con la definición de dicha palabra o frase, si usted desea controlar este comportamiento, le recomiendo activar las siguientes casillas de verificación:
- Only do scanning while modifier key being pressed.
- Hide floating window when modifier key pressed.
Las casillas de verificación previamente mencionadas podrá encontrarlas bajo la sección Dictionary -> Scan Selection.
Si usted esta inconforme con las opciones de búsqueda en Internet, puede agregar las que usted desea desde la sección Main Window -> Search Website.
FeedJack: Ya está disponible
Ya había comentado acerca de ésta aplicación en la entrada FeedJack: Un Planet con esteroides, resulta que hace pocos días Gustavo Picón anunció la salida de la versión 0.9.6 bajo licencia BSD. Algunas de las características más resaltantes de esta aplicación son:
- Soporte de virtual hosts: Esto quiere decir que desde la misma instalación y la misma Base de Datos e interfaz de administración, se manejan múltiples planetas. Si hay feeds en común estos se bajan una sola vez para optimizar recursos.
- Temas (Themes): Cada sitio (virtual host) puede tener temas distintos.
- Soporte de folcsonomías (etiquetas o tags): Muy popular en las aplicaciones de la Web 2.0, se ha optimizado el algoritmo.
- Generación de páginas o feeds por folcsonomías: http://www.chichaplanet.org/tag/django/
- Generación de páginas o feeds por miembros: http://www.chichaplanet.org/user/1/
- Generación de páginas o feeds de una categoría en especial de un miembro particular: http://www.chichaplanet.org/user/1/tag/django/
- Generar un feed general: http://www.chichaplanet.org/feed/
- Histórico de entradas: Entre muchas otras cosas. La principal ventaja frente a Planet es el soporte de un histórico de entradas o posts, por el uso de una Base de Datos.
Para conocer los detalles acerca de los requerimientos, el proceso de instalación, configuración y la modificación de los temas lea con detenimiento la entrada Feedjack - A Django+Python Powered Feed Aggregator (Planet).
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Vim al rescate
Al examinar el día de hoy el último fichero de respaldo de la base de datos de este blog, me percate que existe una cantidad inmensa de registros que en realidad no me hacen falta, sobretodo respecto a las estadísticas, es increible que los registros de una simple base de datos llegara a ocupar unos 24MB, dicha información no tiene mayor relevancia para los lectores puesto que dichos datos suelen ser visualizados en la interfaz administrativa del blog, pero al ocupar mayor espacio en la base de datos, pueden retardar las consultas de los usuarios. Por lo tanto, era necesario realizar una limpieza y eliminar unos cuantos plugins que generaban los registros de las estadísticas.
Ahora bien, imagínese abrir un documento de 266.257 líneas, 24.601.803 carácteres desde algun editor de textos gráfico, eso sería un crimen. ¿Qué podemos hacer?, la única respuesta razonable es utilizar Vim.
Vim es un avanzado editor de textos que intenta proporcionar todas las funcionalidades del editor de facto en los sistemas *nix, Vi. De manera adicional, proporciona muchas otras características interesantes. Mientras que Vi funciona solo bajo ambientes *nix, Vim es compatible con sistemas Macintosh, Amiga, OS/2, MS-Windows, VMS, QNX y otros sistemas, en donde por supuesto se encuentran los sistemas *nix.
A continuación detallo más o menos lo que hice:
En primer lugar respalde la base de datos del blog, enseguida procedí a descomprimir el fichero y revisarlo desde Vim.
$ vim wordpress.sql
Comence a buscar todos los CREATE TABLE que me interesaban. Para realizar esto, simplemente desde el modo normal de Vim escribí lo siguiente:
/CREATE TABLE <strong><Enter></strong>
Por supuesto, el
Con todo la información necesaria, lo único que restaba por hacer era copiar la sección que me interesaba en otro fichero, para ello debemos proceder como sigue desde el modo normal de Vim:
:264843,266257 w milmazz.sql
El comando anterior es muy sencillo de interpretar: Copia todo el contenido encontrado desde la línea 264.843 hasta la línea 266.257 y guardalo en el fichero milmazz.sql.
Inmediatamente restaure el contenido de mi base de datos y listo.
Algunos datos interesantes.
Fichero original
- Tamaño: 24MB
- Número total de líneas: 266.257
Fichero resultado
- Tamaño: 1.2MB
- Número total de líneas: 1.415
Tiempo aproximado de trabajo: 4 minutos.
¿Crees que tu editor favorito puede hacer todo esto y más en menos tiempo?. Te invito a que hagas la prueba ;)
That’s All Folks!
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
mp3wrap: Concatenando ficheros mp3
mp3wrap es una utilidad en línea de comando que nos permite fusionar o concatenar dos o más ficheros mp3, todo esto sin perder los nombres de ficheros y la información de los ID3, estándar que permite la inclusión de metadatos en contenedores multimedia. También es posible añadir otros ficheros que no sean mp3, como por ejemplo, listas de reproducción, ficheros de información, imágenes de portada. Claro, este proceso es posible revertirlo gracias a mp3splt, el cual describiré en un próximo artículo.
Con mp3wrap, usted puede fácilmente fusionar hasta un máximo de 255 ficheros en uno solo, lo cual pareciese ser suficiente para la mayoría. De igual manera, como se mencionó previamente, usted puede añadir ficheros que no sean mp3, pero hay algunas consideraciones al respecto.
- Si el fichero es de texto, como pueden ser las listas de reproducción, los ficheros de información, entre otros, se recomienda que estos se ubiquen al principio del fichero a generar, puesto que el reproductor los descartará rápidamente.
- Si el fichero es binario, como las imágenes por ejemplo, usted debe colocarlas al final del fichero a generar, de esta manera el reproductor se los encontrará después de reproducir y no los confundirá con ficheros
mp3.
Instalación del programa
Para poder instalar esta aplicación en Ubuntu, en primer lugar debemos tener activo en nuestro fichero /etc/apt/sources.list el repositorio universe, después de haber verificado esto procedemos a instalarlo.
$ sudo aptitude install mp3wrap
A continuación explicaré el uso de mp3wrap a través de un ejemplo.
En primer lugar, mostraré la lista de ficheros a fusionar.
$ ls
01.mp3 02.mp3 03.mp3 04.mp3
Ahora fusionaré las 2 primeras canciones.
$ mp3wrap album.mp3 01.mp3 02.mp3
He obviado el mensaje que nos muestra mp3wrap para evitar extender más de lo necesario este artículo. También es importante acotar que el fichero generado no se llamará album.mp3 (lo que pareciese lógico), sino album_MP3WRAP.mp3, es recomendable no borrar la cadena MP3WRAP, ésta le indicará al programa mp3splt, el cual nos permite separar de nuevo los ficheros fusionados, que dicho fichero fué fusionado utilizando mp3wrap, lo anterior nos facilitará su extracción con mp3splt, en caso de darse.
Ahora bien, voy a añadir las otras dos canciones, que conste que este paso lo hago solamente para demostrar como añadir otros ficheros a una compilación previamente hecha con mp3wrap.
$ mp3wrap -a album_MP3WRAP.mp3 03.mp3 04.mp3
Si deseamos conocer cuales son los archivos que contiene el fichero generado por mp3wrap, simplemente debemos hacer lo siguiente.
mp3wrap -l album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
01.mp3
02.mp3
03.mp3
04.mp3
Si en la instrucción anterior hubiesemos hecho uso de la opción -v (verbose), mp3wrap nos mostraría información adicional acerca de los ficheros. Por ejemplo:
mp3wrap -lv album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
# Size Name
--- -------- --------
1) 6724962 01.mp3
2) 9225205 02.mp3
--- -------- --------
15950240 2 files
Pueden observar en el ejemplo anterior que se nos muestra el tamaño en bytes de cada uno de los ficheros, así como el número total de ficheros que han sido fusionados y su tamaño correspondiente en bytes.
Como se ha podido ver a través del articulo el uso de mp3wrap es bastante sencillo, si tiene alguna duda acerca de su uso consulte el manual de mp3wrap, man mp3wrap, o la sección de preguntas mas frecuentes acerca de mp3wrap.
Cowbell: Organiza tu música
Cowbell, es una aplicación que te permite organizar tus compilaciones musicales de una manera fácil y divertida, ya no tienes que aburrirte por horas al intentar organizar tus colección musical manualmente.
Una de las cosas que me han agradado de este programa es que aparte de poder editar las etiquetas manualmentede en una interfaz bastante agradable y sencilla, también puedes obtener toda la información necesaria a través de Amazon Web Services, lo anterior incluye: Número, Título, Año, Estilo, Portada y demás información relacionada con las canciones. Al utilizar este servicio cuentas con una amplia bases de datos, lo anterior en realidad permite ahorrar mucho tiempo.
Dentro de las preferencias de este programa nos encontraremos con opciones que nos permitirán renombrar ficheros de acuerdo a un patrón, el cual lo podemos generar al combinar cualquiera de las siguientes palabras claves.
- Artist
- Album
- Title
- Track
- Genre
- Year
Las palabras claves anteriores se explican por sí solas. Simplemente escoge el patrón que más se ajuste a tus necesidades. Entre otras de las características de este programa, cabe mencionar la posibilidad de generar un fichero de lista de reproducción del álbum.
¿Tienes una larga colección de música cuyas etiquetas debes arreglar?, no te preocupes, Cowbell también puedes usar desde la línea de comandos, la manera de invocar el comando es la siguiente:
$ cowbell --batch /ruta/a/tu/musica
Donde evidentemente debes modificar el directorio /ruta/a/tu/musica de acuerdo a tus necesidades.
Para instalar esta aplicación en ubuntu debes tener activo el repositorio universe en tu fichero /etc/apt/sources.list. Una vez actualizada la lista de repositorios, puedes instalar Cowbell de la siguiente manera:
$ sudo aptitude cowbell
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
deskbar-applet, realiza tus búsquedas desde el escritorio
deskbar-applet es una de esas aplicaciones que parecen no tener mucho sentido en un principio, pero desde el mismo momento en que comienzas a utilizarla se te facilitan muchas actividades cotidianas.
deskbar-applet provee una versátil interfaz de búsqueda, incluso, puede abrir aplicaciones, ficheros, búsquedas locales (se integra complemente con beagle si lo tienes instalado) o directamente en internet; aquellos términos que desee buscar, simplemente tendrá que escribirlos dentro de la casilla correspondiente en el panel. En caso de escribir una dirección de correo electrónico en la barra de búsqueda se le brindará la opción de escribir un correo al destinario que desee.
Si desea probarlo es muy sencilla su instalación. En primer lugar debe tener activa la sección universe en su lista de repositorios.
deb http://us.archive.ubuntu.com/ubuntu breezy universe
deb-src http://us.archive.ubuntu.com/ubuntu breezy universe
Una vez que haya editado el fichero /etc/apt/sources.list debe actualizar la nueva lista de paquetes.
$ sudo aptitude update
Seguidamente puede proceder a instalar el paquete deskbar-applet, para ello simplemente haga.
$ sudo aptitude install deskbar-applet
Una vez culminado el proceso de instalación debe activar deskbar-applet (esta aplicación aparece en la sección de Accesorios) para que aparezca en el panel que desee, recuerde que para agregar un elemento al panel simplemente debe hacer click con el botón derecho del mouse y seleccionar la opción Añadir al panel.
Su uso es muy sencillo, posee una combinación de teclas (Alt + F3) que le facilitará enfocar la casilla de entrada, inmediatamente podrá comenzar a escribir.
Flock, el nuevo navegador social
Flock, es un nuevo navegador que toma sus bases en Mozilla Firefox, su objetivo es captar la atención de usuarios que suelen usar herramientas de comunicación social que están en boga, como por ejemplo:
- del.icio.us: Almacena y comparte tus enlaces favoritos.
- Flickr: Almacena y comparte tus imágenes.
- Technorati: Entérate acerca de lo que se habla actualmente en los blogs. Colección de enlaces a bitácoras organizados por etiquetas o tags.
- Sistemas de Blogging: Entre ellos: WordPress, Blogger, Movable Type, entre otros.
Sistema de publicación
Respecto a la posibilidad de publicar entradas o posts en tu blog desde el mismo navegador, Flock le ofrece una ventana aparte, tendrá que rellenar apropiadamente las distintas opciones que se le muestran para configurar el programa y de esa manera comenzar a redactar sus noticias, artículos, entre otros.
Siguiendo con el tema de la publicación de artículos, Flock, le permite
conectarse con su cuenta en Flickr y añadir fotos, esta posibilidad no se
restringe solo a las cuentas de Flickr, podrá incluir fotos que se muestren en
otros sitios, solamente deberá arrastrar dicha imagen a la interfaz que le
proporciona el editor en cuestión.
De igual manera lo explicado en el párrafo anterior puede aplicarse al texto, podrá arrastrar a la zona de edición cualquier texto disponible en la web, tambien Flock ofrece una opción denominada blog this, su funcionamiento es muy sencillo, solamente deberá seleccionar un texto que le interese publicar, seguidamente proceda a dar click con el botón derecho del mouse blog this, el texto en cuestión aparecerá en la zona de edición como una cita.
El sistema de publicación que le ofrece Flock le permite guardar sus artículos como borradores o marcarlos para su publicación inmediata, otra característica que cabe resaltar es la posibilidad de indicar explícitamente con cuales etiquetas o tags desea que se almacene la entrada para su clasificación en Technorati.
Favoritos
El sistema de favoritos se integra con tu cuenta en del.icio.us, gestor de
enlaces favoritos o bookmarks comunitario. y organizado por etiquetas o
tags.
Lectura de feeds
Flock nos indica cuando un blog o bitácora dispone de un feed, la manera de
indicarlo es muy agradable a la vista, simplemente muestra un icono al lado
derecho de la ventana de la URL. Si lo desea, puede ver el contenido del feed
desde el mismo Flock, que le ofrece un visualizador de feeds, en él podrá
ordenar las entradas por fechas o por la fuente, de manera adicional podrá
contraer o expander todas las noticias, si decide contraer (o expander) las
noticias de acuerdo al orden que haya elegido (por fecha o por fuente), puede ir
expandiendo (o contrayendo) dichas noticias una por una.
¿Desea probar Flock?
Si lo desea, puede probar fácilmente Flock al hacer uso de los ficheros binarios que se ofrecen, en ubuntu (aplicable en otras distribuciones) debe hacerse lo siguiente:
En primer lugar deberá descargar el paquete binario que se ofrece para la plataforma Linux desde la sección Developer de Flock.
Antes de continuar, debe saber que Flock está compilado haciendo uso de
libstdc++ en su versión 5, si, se encuentra en
Breezy, debe instalarla de la
siguiente manera:
$ sudo aptitude install libstdc++5
Una vez que se haya completado la transferencia del paquete binario de Flock, debe ubicarse en el directorio destino de la descarga y proceder a descompimir y desempaquetar el paquete en cuestion, para ello, debe hacer lo siguiente.
$ tar xvzf flock-0.4.10.en-US.linux-i686.tar.gz
Por supuesto, es de suponerse que en este ejemplo particular el paquete que se
descargó fué flock-0.4.10.en-US.linux-i686.tar.gz, usted debe ajustar este
argumento de acuerdo al fichero que haya descargado.
Una vez culminado el paso anterior lo que sigue es sencillo, debe entrar en el
directorio generado y ejecutar el comando flock, más o menos similar a lo que
sigue a continuacion.
$ cd flock
$ ./flock
Recuerde que en Breezy usted puede generar una entrada al menú haciendo uso de Herramientas del Sistema -> Applications Menu Editor, seguidamente seleccione el submenu Internet y genere una nueva entrada con las siguientes propiedades.
- Name: Flock
- Comment: Internet Browser
- Command: /directorio_donde_esta_flock/flock
- Icon: /directorio_donde_esta_flock/icons/mozicon128.png
Referencias
Atajos Dinámicos en GIMP
Muchas de las opciones en GIMP no ofrecen una combinación de teclas o atajo (shortcut) que nos permita utilizar dichas opciones de manera rápida. En este artículo plantearemos la creación de atajos dinámicos en GIMP.
 En
primer lugar debemos tener abierto GIMP, parece evidente, ¿verdad?, seguidamente
nos vamos al menú de GIMP y seleccionamos Archivos -> Preferencias. Una vez
ubicados en la ventana de Preferencias seleccionamos la opción Interfaz de
la lista de categorías que se nos presenta. Seguidamente seleccionamos la
casilla de verificación que hace referencia a Usar combinaciones de teclas
dinámicas y aceptamos los cambios presionando el botón OK.
En
primer lugar debemos tener abierto GIMP, parece evidente, ¿verdad?, seguidamente
nos vamos al menú de GIMP y seleccionamos Archivos -> Preferencias. Una vez
ubicados en la ventana de Preferencias seleccionamos la opción Interfaz de
la lista de categorías que se nos presenta. Seguidamente seleccionamos la
casilla de verificación que hace referencia a Usar combinaciones de teclas
dinámicas y aceptamos los cambios presionando el botón OK.
 Una vez hecho lo anterior vamos a crear un nuevo fichero, no importan sus
medidas, la idea es asignarle un atajo a una opción cualquiera, o aquellas que
usamos comúnmente y que no disponen de una combinación de teclas, en este
artículo tomaré como ejemplo la opción Imagen -> Tamaño del lienzo…, el
atajo combinación de teclas que le asignaré a dicha opcion será Ctrl + F11. Para
lograr lo planteado anteriomente simplemente debe posicionarse con el cursor del
mouse en dicha opción, mientrás se encuentra encima de ella, proceda a
escribir la combinación de teclas que desee.
Una vez hecho lo anterior vamos a crear un nuevo fichero, no importan sus
medidas, la idea es asignarle un atajo a una opción cualquiera, o aquellas que
usamos comúnmente y que no disponen de una combinación de teclas, en este
artículo tomaré como ejemplo la opción Imagen -> Tamaño del lienzo…, el
atajo combinación de teclas que le asignaré a dicha opcion será Ctrl + F11. Para
lograr lo planteado anteriomente simplemente debe posicionarse con el cursor del
mouse en dicha opción, mientrás se encuentra encima de ella, proceda a
escribir la combinación de teclas que desee.
Programación Extrema
La Programación Extrema es ideal en aquellos proyectos en donde se requiere un desarrollo a corto plazo, en donde los requerimientos pueden ser cambiados en cualquier instante, de hecho, su principal objetivo es reducir los costos generados por los cambios en los requerimientos. Se propone como un paradigma en donde se proveen numerosas ventajas en la reutilización del código.
Se evita el diseño extensivo que presentan los modelos tradicionales, en donde los requerimientos del sistema son determinados al inicio del desarrollo del proyecto y a menudo son corregidos desde ese punto, esto implica que los costos ocasionados por los cambios de los requerimientos en una fase avanzada del proyecto sean bastante elevados, esto evidentemente es un problema para empresas que presentan cambios constantes.
Las prácticas principales en la Programación Extrema son aquellas que generalmente son aceptadas como buenas, pero en este paradigma se llevan al extremo.
La comunicación entre los desarrolladores y los clientes debe ser excelente. De hecho, se supone que un grupo de desarrollores tenga al menos un cliente en el sitio, que especifique y dé prioridad al trabajo que realizan los desarrolladores, que responda las preguntas tan pronto como se presenten.
Se busca la simplicidad en la escritura del código fuente, cuando éste se vuelve complejo, se recomienda una reescritura del código.
Las revisiones del código también se llevan al extremo, el paradigma de la Programación Extrema propone que los desarrolladores trabajen en parejas, compartiendo la pantalla y el teclado del ordenador, esto a la vez de promover la comunicación entre los desarrolladores permite que el código sea revisado mientras se escribe.
La Programación Extrema asegura la calidad en la aplicación desarrollada al momento de realizar lo que ellos llaman refactorización, el cual es un proceso de reestructuración del sistema, en donde se elimina la duplicación, se promueve simplificación y se le agrega flexibilidad sin cambiar la funcionalidad de operación del código.
Este paradigma funciona mejor en proyectos de pequeña o mediana escala (los grupos de desarrolladores no deben sobrepasar las 10 personas cada uno). Ideal en aquellas aplicaciones que necesitan una nueva versión cada 2 ó 3 semanas.
Evolution y Gmail
Si desea configurar el cliente de correo Evolution (también brinda una agenda de contactos, calendario, entre otras funcionalidades) para manejar su cuenta de Gmail, estos son los pasos.
Habilitando el acceso POP en su cuenta de Gmail
- Identificarse en Gmail.
- Un vez dentro del sistema, ir a la opción de Configuración
- Seguidamente proceda a seleccionar Reenvío y correo POP del menú.
- Dentro de la sección Descargar correo POP encontramos tres derivaciones:
- La primera se refiere al Estado, en ella debemos habilitar cualquiera de las dos opciones que se muestran al principio, la primera permite Habilitar POP para todos los mensajes (incluso si ya se han descargado), la segunda opción permite Habilitar POP para los mensajes que se reciban a partir de ahora.
- La segunda derivación se refiere a qué debe hacer Gmail cuando se accede a los mensajes a través de POP, eliga la respuesta de su conveniencia, yo por lo menos tengo conservar una copia de Gmail en la bandeja de entrada.
- La tercera derivacion se refiere a como lograr configurar el cliente de correo electrónico, en nuestro caso, será Evolution.
- Guardar cambios.
Ahora vamos a configurar nuestra cuenta Gmail desde Evolution. En primer lugar veamos como configurar la recepción de correos.
Recibiendo Mensajes
- Tipo de servidor: POP
- Servidor:
pop.gmail.com - Usuario: [email protected], evidentemente debe cambiar la cadena nombredeusuario por su login verdadero, no olvide colocar seguido del nombre de usuario la cadena @gmail.com.
- Usar onexión segura: Siempre
- Tipo de autenticación: Password
Ahora veamos como configurar el envio de correos desde Evolution.
Enviando correos
- Tipo de servidor: SMTP
- Servidor: Puede usar las siguientes:
smtp.gmail.com,smtp.gmail.com:587ósmtp.gmail.com:465. Debe marcar la casilla de verificación El servidor requiere autenticación - Usar conexión segura: Cuando sea posible
- Tipo (dentro de la sección de autenticación): Login
- Usuario (dentro de la sección de autenticación): [email protected], recuerde sustituir la cadena nombredeusuario por el parámetro correspondiente, no olvide colocar después del nombre de usuario la cadena @gmail.com, es importante.
Finalmente revise las opciones que le brinda Evolution y comience una vida llena de placeres.
COMO actualizar de manera segura su sistema
Antes de comenzar es importante hacer notar que esta guía se enfocará al mundo Debian GNU/Linux y sus derivadas, en donde por supuesto se incluye Ubuntu Linux. Después de hacer la breve aclaratoria podemos comenzar.
¿Es importante la firma de los paquetes?
La firma de los paquetes es una funcionalidad fundamental para evitar el posible cambio adrede en los ficheros binarios o fuentes distribuidos a través de sitios espejos (mirrors), de esta manera nos libramos de la posibilidad de un ataque man in the middle, el cual básicamente consiste en la intercepción de la comunicación entre el origen y el destino, el atacante puede leer, insertar y modificar los mensajes (en este caso particular, los ficheros) compartidos entre las partes sin que cada una de ellas se percate que la comunicación se ha visto comprometida.
Nuestro objetivo
Un sistema automatizado de actualización de paquetes, también es sumamente importante eliminar cualquier posibilidad de amenaza que pueda surgir al aprovecharse de la automatización del proceso de actualización, por ejemplo, debemos evitar a toda costa la distribución de troyanos que comprometarán la integridad de nuestros sistemas.
Un poco de historia…
No fue sino hasta la aparición de la versión 0.6 de la interfaz apt en donde se realiza la autenticación de ficheros binarios y fuentes de manera transparente haciendo uso de una Infraestructura de clave pública (en inglés, Public Key Infrastructure o PKI). La PKI se basa en el modelo GNU Privacy Guard (GnuPG) y se ofrece un enorme despliegue de keyservers internacionales.
Detectando la autenticidad de los paquetes
Como se menciono anteriormente desde la versión 0.6 de la interfaz apt se maneja de manera transparente el proceso de autentificación de los paquetes. Asi que vamos a hacer una prueba, voy a simular la instalación del paquete clamav.
$ sudo aptitude --simulate install clamav
Obteniendo por respuesta lo siguiente:
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado extendido
Inicializando el estado de los paquetes... Hecho
Se instalarán automáticamente los siguientes paquetes NUEVOS:
arj clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
Se instalarán los siguiente paquetes NUEVOS:
arj clamav clamav-base clamav-freshclam libclamav1 libgmp3 unzoo
0 paquetes actualizados, 7 nuevos instalados, 0 para eliminar y 0 sin actualizar.
Necesito descargar 3248kB de ficheros. Después de desempaquetar se usarán 4193kB.
¿Quiere continuar? [Y/n/?] Y
The following packages are not AUTHENTICATED:
clamav clamav-freshclam clamav-base libclamav1
Do you want to continue? [y/N] N
Cancela.
Si nos fijamos bien en la respuesta anterior notaremos que ciertos paquetes no han podido ser autentificados. A partir de este punto es responsabilidad del administrador del sistema el instalar o no dichos paquetes, por supuesto, cada quien es responsable de sus acciones, yo prefiero declinar mi intento por el momento y asegurarme de la autenticidad de los paquetes, para luego proceder con la instalación normal.
Comienza la diversión
Ahora bien, vamos a mostrar la secuencia de comandos a seguir para agregar las llaves públicas dentro del keyring por defecto. Antes de entrar en detalle es importante aclarar que el ejemplo agregará la llave pública del grupo os-cillation, quienes se encargan de mantener paquetes para el entorno de escritorio Xfce (siempre actualizados y manera no-oficial) para la distribución Debian GNU/Linux (también sirven para sus derivadas, como por ejemplo Ubuntu Linux).
Importando la llave pública desde un servidor GPG
$ gpg --keyserver hkp://wwwkeys.eu.pgp.net --recv-keys 8AC2C0A6
El comando anterior simplemente importara la llave especificada (8AC2C0A6) desde el servidor con el cual se ha establecido la comunicación, el valor de la opción --keyserver sigue cierto formato, el cual es: esquema:[//]nombreservidor[:puerto], los valores ubicados entre corchetes son opcionales, cuando hablamos del esquema nos referimos al tipo de servidor, regularmente utilizaremos como esquema hkp para servidores HTTP o compatibles.
Si el comando anterior se ejecuto de manera correcta, el proceso nos arrojará una salida similar a la siguiente:
gpg: key 8AC2C0A6: public key "os-cillation Debian Package Repository
(Xfld Package Maintainer) <[email protected]>" imported
La instrucción anterior solamente variará de acuerdo al keyserver y la clave que deseemos importar. En www.pgp.net está disponible un buscador que le facilitará la obtención de los datos necesarios.
Exportando y añadiendo la llave pública
$ gpg --armor --export 8AC2C0A6 | sudo apt-key add -
Con el comando anterior procedemos a construir la salida en formato ASCII producto de la exportación de la llave especificada y a través del pipe capturamos la salida estándar y la utilizamos como entrada estándar en el comando apt-key add, el cual simplemente agregará una nueva llave a la lista de llaves confiables, dicha lista puede visualizarse al hacer uso del comando apt-key list.
Aunque parezca evidente la aclaratoria, recuerde que si usted no puede hacer uso de sudo, debe identificarse previamente como superusuario.
Finalmente…
Para finalizar recuerde que debe actualizar la lista de paquetes.
$ sudo aptitude update
Ahora podemos proceder a instalar los paquetes desde el repositorio que hemos añadido como fuente confiable.
aptitude, ¿aún no lo usas?
Si usted es de los que piensa que aptitude por ser simplemente un frontend de apt no puede aportar alguna ventaja al manejo óptimo de paquetes, trataré en lo posible en este artículo hacerle cambiar de parecer, o por lo menos mostrarle que en realidad aptitude si ofrece ciertas ventajas sobre apt.
La útil y avanzada herramienta que le permite manejar cómodamente los paquetes, apt (y dpkg) no lleva un registro (ni hace distinciones) de las aplicaciones que se instalan de manera explícita y las que se instalan de manera implícita por consecuencia del primer punto (es decir, para establecer la resolución de dependencias). Esta característica genera ciertos inconvenientes a la hora de desinstalar un paquete que posee dependencias que no son empleadas por otros programas, al momento de realizar la desinstalación lo más seguro es que no queden las cosas muy “limpias” en el sistema.
Un remedio que en principio puede servirle es hacer uso de deborphan (también puede hacer uso de orphaner, un frontend para deborphan); una herramienta de mayor potencia es debfoster, el primero de los mencionados busca librerias huérfanas (como se explico en un artículo anterior) y al pasarle estos resultados al apt-get remove se puede resolver de cierta manera el problema.
El problema de deborphan es que su campo de acción es limitado, por lo que la “limpieza” puede no ser muy buena del todo. En cambio debfoster si hace la distinción de la cual hablaba al principio de este artículo, los paquetes instalados de manera explícita y aquellos que son instalados de manera implícita para resolver las dependencias, por lo tanto debfoster eliminará no solamente las librerias huérfanas tal cual lo hace deborphan si no que también eliminará aquellos paquetes que fueron instalados de manera implícita y que actualmente ningún otro programa dependa de él, también serán eliminados en el caso en que se de una actualización y ya la dependencia no sea necesaria.
Ahora bien, se presenta otra alternativa, aptitude, este frontend de apt si recuerda las dependencias de un programa en particular, por lo que el proceso de remoción del programa se da correctamente. Ya anteriormente había mencionado que apt y dpkg no hacen distinción de las aplicaciones instaladas y Synaptic apenas lleva un histórico, esto en realidad no cumple con las espectativas para mantener un sistema bastante “limpio”.
Aparte de lo mencionado previamente, otra ventaja que he encontrado en la migración a aptitude es que tienes dos opciones de manejo, la linea de comandos, la cual ha sido mi elección desde el comienzo, debido a la similitud de los comandos con los de apt y porque consigo lo que deseo inmediatamente, la interfaz gráfica no me llama la atención, pero quizás a usted si le guste. Adicionalmente, aptitude maneja de manera más adecuada el sistema de dependencias.
Para lograr ejecutar la interfaz gráfica de aptitude simplemente debe hacer:
$ sudo aptitude
De verdad le recomiendo emplear aptitude como herramienta definitiva para el manejo de sus paquetes, primero, si es usuario habitual de apt, el cambio prácticamente no lo notará, me refiero al tema de la similitud de los comandos entre estas dos aplicaciones, segundo, no tendrá que estar buscando “remedios” para mantener limpio el sistema, aptitude lo hará todo por usted.
Creando un repositorio local
Planteamiento del Problema:
Mantener actualizada una laptop (u ordenador de escritorio) de bajos recursos, con varios años de uso, el caso que se presenta es que el laptop en cuestión posee solo un puerto para conexiones por modem de velocidades topes de 56kbps, lo anterior puede ser traumático al realizar actualizaciones del sistema.
Consideraciones:
Nos aprovecharemos del hecho de la disponibilidad de un puerto USB en el ordenador de bajos recursos, el cual nos facilita en estos tiempos el almacenamiento masivo de paquetes, en caso de no tener puerto USB, podemos recurrir a unidades de CD como medio de almacenamiento masivo.
Adicionalmente, aprovecharemos conexiones de gran bando de ancha, lo cual nos facilitará la descarga de los paquetes necesarios desde los repositorios disponibles en la red.
Posible solución:
Después de plantear las consideraciones anteriores, una posible alternativa para mantener actualizados nuestros ordenadores de bajos recursos es utilizar dispositivos de almacenamiento masivo como repositorios locales, almacenando en ellos solo los paquetes que sean realmente necesarios.
En los siguientes puntos trataré de ampliar la manera de crear un repositorio local valiéndonos del uso de un Pen Drive.
Comenzamos:
En primer lugar vamos a respaldar los paquetes *.deb que se ubican en /var/cache/apt/archives, esta actividad la vamos a realizar en el ordenador que dispone de una conexión banda ancha.
$ mkdir $HOME/backup
$ sudo cp /var/cache/apt/archives/*.deb $HOME/backup
Después de respaldar los paquetes, vamos a remover todos los ficheros *.deb que han sido descargados al directorio cache que almacena los paquetes, usualmente esto quiere decir, eliminar todos los paquetes *.deb ubicados en /var/cache/apt/archives, para ello hacemos lo siguiente:
$ sudo aptitude clean
Ahora que se encuentra limpio el directorio cache procederemos a descargar (sin instalar) los paquetes que sean necesarios para nuestro ordenador de bajos recursos. Para ello hacemos lo siguiente:
$ sudo aptitude -d install <paquetes>
El comando anterior simplemente descargará la lista de paquetes especificada
(recuerde que debe sustituir
Para trabajar mas cómodamente crearemos una carpeta temporal y desde allí procederemos a crear nuestro repositorio local en cuestión, el cual finalmente se guardará en el medio de almacenamiento masivo correspondiente.
$ mkdir /tmp/debs
$ mv /var/cache/apt/archives/*.deb /tmp/debs/
$ cd /tmp
Estando ubicados en el directorio /tmp realizaremos una revisión de los paquetes que se ubican en el directorio debs/ y crearemos el fichero comprimido Packages.gz (el nombre del fichero debe ser exacto, no es cuestión de elección personal).
$ dpkg-scanpackages debs/.* | gzip > debs/Packages.gz
Guardando el repositorio en un dispositivo de almacenamiento masivo
En nuestro caso procederé a explicar como almacenar el repositorio en un Pen Drive, por ciertas cuestiones prácticas, primero, facilidad de movilidad que presentan, la capacidad de almacenamiento, la cual regularmente es mayor a la de un CD.
En la versión actual (Hoary) de Ubuntu Linux los Pen Drive son montados automáticamente, si esto no ocurre, puede realizar lo siguiente:
$ sudo mount -t vfat /dev/sda1 /media/usbdisk
Recuerde ajustar los argumentos de acuerdo a sus posibilidades. Luego de montado el dispositivo de almacenamiento masivo proceda a copiar de manera recursiva el directorio debs/.
$ cp -r /tmp/debs/ /media/usbdisk
Estableciendo el medio de almacenamiento masivo como un repositorio.
Si ha decidido utilizar un Pen Drive como medio de almacenamiento.
Después de copiar los ficheros en el medio de almacenamiento masivo, proceda a
desmontarlo (en nuestro caso: $ sudo umount /media/usbdisk) y conectelo a su
ordenador de bajos recursos, recuerde que si el ordenador de bajos recursos no
monta automáticamente el dispositivo, debe montarlo manualmente como se explico
anteriormente.
Después de haber sido reconocido el dispositivo de almacenamiento masivo en el ordenador de bajos recursos proceda a editar el fichero /etc/apt/sources.list y agregue la linea deb file:/media/usbdisk debs/. Comente los demás repositorios existentes, recuerde que para ello simplemente debe agregar el carácter almohadilla (#) al principio de la linea que especifica a dicho repositorio.
Si ha decidido utilizar un CD como medio de almacenamiento
Simplemente haciendo uso de apt-cdrom add le bastará, esto añadirá el medio a
la lista de recursos del fichero sources.list
Finalizando…
Para finalizar deberá actualizar la lista de paquetes disponibles y proceder con la instalación de dichos paquetes en el ordenador de bajos recursos, para ello, simplemente bastará con hacer lo siguiente:
$ sudo aptitude update
$ sudo aptitude install <paquetes>
Recuerde restaurar en el ordenador que dispone de conexión banda ancha los paquetes que se respaldaron previamente.
$ sudo mv $HOME/backup/*.deb /var/cache/apt/archives/
¡Que lo disfrute! :D
Organizando nuestros proyectos web
Antes de plantearme el rediseño de este sitio, pensé en organizar ciertas cosas para no complicarme la vida. En primera instancia procedi a instalar el servidor Apache, el soporte del lenguaje PHP, el servidor de bases de datos MySQL y finalmente el phpMyAdmin.
Lo anterior se resume de la siguiente manera en mi querido Ubuntu Linux.
$ sudo aptitude install apache2
$ sudo aptitude install mysql-server
$ sudo aptitude install php4
$ sudo aptitude install libapache2-mod-auth-mysql
$ sudo aptitude install php4-mysql
$ sudo /etc/init.d/apache2 restart
$ sudo aptitude install phpmyadmin
Recuerde después de instalar el servidor de bases de datos MySQL establecer la contraseña del usuario root de dicho servidor por seguridad. Si no sabe como hacerlo a través de la línea de comandos existe la alternativa de establecer la contraseña utilizando phpMyAdmin.
Por defecto el servidor Apache habilita el directorio /var/www/ como directorio principal, el problema que se plantearía el trabajar en dicho directorio es que cada vez que tuviese que realizar cambios a los ficheros tendría que hacer uso de la cuenta de superusuario o root, lo cual no me agrada mucho, así que para evitar lo mencionado previamente tenía dos opciones.
La primera de ellas era modificar el fichero /etc/apache2/apache.conf y habilitar que todos los usuarios tuviesen la posibilidad de publicar sus documentos dentro del directorio /home/*/public_html, esta opción no me llamaba mucho la atención, adicionalmente, la dirección queda de cierta manera algo extensa (p.ej. http://localhost/~usuario/proyectoweb), así que opte por recurrir a una segunda opción, la cual describiré detalladamente a continuación.
En primera instancia creé dos directorios, public_html como subdirectorio de $HOME, el segundo, milmazz como subdirectorio de public_html.
$ mkdir $HOME/public_html
$ mkdir $HOME/public_html/milmazz
Seguidamente procedi a crear el fichero /etc/apache2/sites-enabled/001-milmazz, este fichero contendrá las directivas necesarias para nuestro proyecto desarrollado en un ambiente local.
<VirtualHost *>
DocumentRoot "/home/milmazz/public_html/milmazz/"
ServerName milmazz.desktop
<Directory "/home/milmazz/public_html/milmazz/">
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order deny,allow
Deny from all
Allow from 127.0.0.0/255.0.0.0 ::1/128
</Directory>
</VirtualHost>
Ahora bien, necesitamos crear el host para que la directiva realmente redireccione al directorio /home/milmazz/public_html/milmazz/ simplemente tecleando milmazz.desktop en la barra de direcciones de nuestro navegador preferido. Por lo tanto, el siguiente paso es editar el fichero /etc/hosts y agregar una línea similar a 127.0.0.1 milmazz.desktop, note que el segundo parámetro especificado es exactamente igual al especificado en la directiva ServerName.
Seguidamente procedi a instalar WordPress (Sistema Manejador de Contenidos) en el directorio $HOME/public_html/milmazz y todo funciona de maravilla.
Evitando el acceso de usuarios no permitidos
Si queremos restringir aún más el acceso al directorio que contendrá los ficheros de nuestro proyecto web, en este ejemplo, el directorio es $HOME/public_html/milmazz/, realizaremos lo siguiente:
$ touch $HOME/public_html/milmazz/.htaccess
$ nano $HOME/public_html/milmazz/.htaccess
Dentro del fichero .htaccess insertamos las siguientes lineas.
AuthUserFile /var/www/.htpasswd
AuthGroupFile /dev/null
AuthName "Acceso Restringido"
AuthType Basic
require valid-user
Guardamos los cambios realizados y seguidamente procederemos a crear el fichero que contendrá la información acerca de los usuarios que tendrán acceso al directorio protegido, también se especificaran las contraseñas para validar la entrada. El fichero a editar vendra dado por la directiva AuthUserFile, por lo tanto, en nuestro caso el fichero a crear será /var/www/.htpasswd.
htpasswd -c /var/www/.htpasswd milmazz
Seguidamente introducimos la contraseña que se le asignará al usuario milmazz, la opción -c mostrada en el código anterior simplemente se utiliza para crear el fichero /var/www/.htpasswd, por lo tanto, cuando se vaya a autorizar a otro usuario cualquiera la opción -c debe ser ignorada.
Estableciendo la contraseña del usuario root del servidor de bases de datos a través de phpMyAdmin.
Si usted no sabe como establecer en línea de comandos la contraseña del usuario root en el servidor de bases de datos MySQL es posible establecerla en modo gráfico haciendo uso de phpMyAdmin.
A continuacion se describen los pasos que deberá seguir:
- Acceder a la interfaz del phpMyAdmin, para lograrlo escribe en la barra de direcciones de tu navegador http://localhost/phpmyadmin.
- Selecciona la opción de Privilegios, ésta se ubica en el menú principal.
- Debemos editar los dos últimos registros, uno representa el superusuario cuyo valor en el campo servidor será equivalente al nombre de tu máquina, el otro registro a editar es aquel superusuario cuyo valor en el campo servidor es igual a localhost. Para editar los registros mencionados anteriormente simplemente deberá presionar sobre la imagen que representa un lapíz.
- Los únicos campos que modificaremos de los registros mencionados previamente son aquellos que tienen relación con la contraseña. Recuerde que para guardar los cambios realizados al final debe presionar el botón Continúe. Si deseas evitar cualquier confusión en cuanto al tema de las contraseñas es recomendable que establezcas la misma en ambos registros.
Agradecimientos
A José Parella por sus valiosas indicaciones.
Feedness libera su código
Feedness es una aplicación que te permite gestionar tus canales o feeds, por lo cual podrás leer y gestionar los contenidos de las páginas que ofrecen sus artículos en XML. Esto implica que puedes manejar todos tus canales favoritos desde una misma aplicación, sin necesidad de visitar dichos sitios, lo cual optimiza el tiempo de lectura de tus noticias a diario manteniendote constante actualizado a través del notificador disponible.
Walter Kobylanski anuncia la liberación del código de feedness, según el anuncio uno de los motivos por los cuales han tomado esta decisión se debe al parcial estancamiento en el desarrollo de la aplicación.
Sin embargo, nuestro estudio ha cambiado desde el lanzamiento, las cosas han mejorado mucho y hace ya más de 3 meses que no paramos de trabajar en proyectos para clientes. En consecuencia, hemos visto como feedness ha quedado paralizado en términos de desarrollo mientras que cada día tenemos más personas que utilizan este servicio.
Feedness es liberado bajo la licencia MIT, por cual podrá:
Cualquier persona puede obtener el software y la documentación asociada gratuitamente, sin ninguna restricción, siendo posible usarlo, modificarlo, copiarlo, hacerlo público, sub-licenciarlo o venderlo - entre otras posibilidades - siempre y cuando se mantengan la noticia de la licencia en los lugares donde se encuentra.
Si deseas colaborar con el proyecto, toda la información que busca al respecto estará disponible en OpenFeedness.
Beagle
Beagle es una poderosa herramienta de búsqueda escrita en C# usando Mono y Gtk# que le permitirá buscar hasta en lo más recóndito de su espacio personal y de esta manera encontrar lo que está buscando. Beagle también puede buscar en distintos dominios.
Usando Beagle ud. fácilmente podrá encontrar.
- Documentos.
- Correos electrónicos.
- Historial web.
- Conversaciones de Mensajería Instantánea o del IRC.
- Código fuente.
- Imagénes.
- Ficheros de audio.
- Aplicaciones.
- Otros…
Beagle puede extraer información desde:
- Evolution, tanto los correos electrónicos como de la libreta de contactos.
- Gaim, desde los registros de mensajería instantánea.
- Firefox, páginas web.
- Blam y Liferea, agregadores RSS.
- Tomboy, notas.
De manera adicional Beagle soporta los siguientes formatos.
- OpenOffice.org
- Microsoft Office (
doc,ppt,xls). - HTML.
- PDF.
- Imágenes (jpeg, png).
- Audio (mp3, ogg, flac).
- AbiWord.
- Rich Text Format (RTF).
- Texinfo.
- Páginas del manual (man pages).
- Código Fuente (C, C++, C#, Fortran, Java, JavaScript, Pascal, Perl, PHP, Python).
- Texto sin formato.
Beagle aún se encuentra en una etapa temprana de desarrollo, así que aún faltan muchas características que le darían un plus a esta herramienta, por ejemplo, agregar el soporte a los sistemas de ficheros: NFS, Reiser4, NTFS y FAT.
En el caso de los sistemas de ficheros tipo FAT, muchos usuarios aún emplean este tipo de particiones para compartir datos entre los mundos GNU/Linux y Windows, por lo que sería conveniente el hecho de agregar esta funcionalidad a esta estupenda herramienta.
Si desea comenzar con esta herramienta, le recomiendo leer los primeros pasos del wiki de Beagle. A los usuarios de Ubuntu Linux le recomiendo la serie de pasos mostrados en el tema ¿Cómo instalar el buscador Beagle? de guia-ubuntu.org.
Existen algunas demostraciones sobre el uso de Beagle, propuestas por Nat Friedman, en una de ellas se podrá apreciar la funcionalidad de “búsqueda en vivo”, para ello es necesario activar el soporte de Inotify.
Inotify es un sistema de notificación de ficheros para el núcleo (kernel) de Linux. Actualmente esta característica no es incluida en la serie estable del núcleo de Linux, por lo que es muy probable que deba añadir esta característica al núcleo por si solo para poder utilizarlo. Existen algunas versiones del núcleo para distribuciones que si incluyen el soporte a Inotify.
Beagle como tal no requiere de Inotify para funcionar, solamente se recomienda su uso puesto que mejora la experiencia del usuario. Sin el soporte de Inotify, Beagle no podrá detectar automáticamente (en vivo) todos los cambios en su directorio personal, por lo que no podrá indexar los datos de manera oportuna.
De manera oportuna, los usuarios de Ubuntu Linux tienen cierta ventaja, no será necesario reparar el núcleo ni compilarlo, solamente hay que añadir la opción de Inotify en el fichero de configuración de Grub, de la manera siguiente:
$ sudo vi /boot/grub/menu.lst
title Ubuntu, kernel 2.6.10-5-k7
root (hd0,5)
kernel /vmlinuz-2.6.10-5-k7 root=/dev/hda8 ro quiet splash <strong>inotify</strong>
initrd /initrd.img-2.6.10-5-k7
savedefault
boot
Luego de hacer los cambios al fichero de configuración del gestor de arranque Grub, procedemos a actualizarlo.
$ sudo update-grub
Si utilizas Firefox y deseas que Beagle indexe las páginas que vas navegando, seguramente desearás instalar esta extensión.
ImageMagick
ImageMagick, es una suite de software libre, sirve para crear, editar y componer imágenes en mapa de bits. Puede leer, convertir y crear imágenes en una larga variedad de formatos (más de 90 formatos soportados). Las imágenes pueden ser cortadas, los colores pueden ser cambiados, ciertos efectos pueden ser aplicados, las imágenes pueden rotadas y combinadas, se pueden agregar a las imágenes, textos, líneas, polígonos, elipses, entre otros.
Es una suite realmente potente bajo la línea de comandos, puede ver una serie de ejemplos, esto le demostrará lo que puede llegar a hacer con esta eficaz aplicación.
Esta herramienta me ha facilitado enormemente el procesamiento de gran cantidad de imágenes que requieren el mismo tratamiento, solamente con una línea de comandos voy a establecer todas las opciones que deseo. Por ejemplo:
convert origen.jpg -resize 50% -bordercolor "#666"
-border 4 destino.png
Imagen Original -> Imagen modificada con ImageMagick.
Con esta simple línea de comandos estoy realizando las siguientes conversiones sobre la imagen origen.jpg, en primer lugar estoy reduciendo las proporciones de anchura y altura al 50%, posteriormente estoy designando el color del borde al valor hexadecimal (#666, gris), el ancho de dicho borde será de 4px, finalmente estoy cambiando el formato de la imagen, estoy convirtiendo de jpg a png, los resultados se podrán apreciar en la imagen destino.png. Ahora bien, imagínese procesar 500 imágenes desde una aplicación con interfaz gráfica que le brinde la rapidez que le ofrece ImageMagick, creo que hasta la fecha es imposible, por lo que resulta un buen recurso el emplear esta herramienta para el procesamiento de grandes lotes de imágenes.
Ahora vamos a “jugar” un poco para colocar una “marca de agua” a la imagen en cuestión.
convert origen.jpg -resize 50% -bordercolor "#666"
-border 4 -font "Bitstream Vera Sans" -pointsize 16 -gravity SouthEast
-fill "#FFF" -draw "text 10,10 'http://blog.milmazz.com.ve'" destino.png
Imagen Original -> Imagen modificada con ImageMagick.
Esta vez el número de opciones que he empleado han aumentado ligeramente. Vamos
a explicar brevemente cada una de ellas, la opción font nos permite elegir una
fuente, en el ejemplo he escogido la fuente Bitstream Vera Sans, la opción
pointsize permite escoger el tamaño de la fuente, la opción gravity nos permite
establecer la colocación horizontal y vertical del texto, he elegido la
primitiva SouthEast, la cual colocará el texto en la parte inferior derecha de
la imagen, la opción fill me permite establecer el color de relleno del texto
que se dibujará con la opción draw, esta última opción escribirá la cadena
http://blog.milmazz.com.ve.
Para mayor información acerca de las distintas opciones que puede manejar le recomiendo leer detenidamente la descripción de las herramientas en línea de comando de ImageMagick.
Opera 8
A pesar de ser un navegador con pocos adeptos, Opera es un excelente navegador, ofrece tanto seguridad, rapidez y una interfaz sencilla de manejar.
En esta nueva versión se ofrecen ciertas características que valen la pena mencionar, bloqueador de ventanas emergentes (pop-up), navegación por pestañas, busquedas integradas, e-mail, entre otros.
Opera soporta la mayoría de las distribuciones GNU/Linux, entre ellas se encuentran: RedHat, SuSE, Mandrake, Debian, etc., también se incluyen versiones PowerPC y Sparc.
En esta nueva versión se ha propuesto una interfaz que permite realizar funciones avanzadas de una manera fácil y de una manera efectiva. En cuanto a la seguridad, Opera ahora despliega información dentro de la barra de direcciones, indicándole el nivel de seguridad del sitio en el que navega actualmente, también ofrece protección para evitar el phishing (duplicación de páginas web, normalmente con propósitos ilegales), de manera automática se revisa si existen actualizaciones disponibles para el navegador.
Le recomiendo vea la sección de las características del navegador.
Adobe adquiere Macromedia
Adobe Systems Incorporated ha anunciado a través de un comunicado de prensa la adquisición de Macromedia Inc., se estima que el valor de dicha adquisición es de aproximadamente 3.4 billones de dolares.
Esta noticia está generando controversia y no es para menos, algunos apoyan la adquisición hecha por Adobe, yo pienso que estas personas están siendo muy entusiastas, pero la historia nos recuerda que los monopolios no son nada buenos, ¿necesito dar ejemplos?. Sí, efectivamente, Adobe por medio de esta adquisición ha “dejado fuera” a quien en los últimos años era su máximo competidor. Macromedia ofrecía mejores opciones en cuanto aplicaciones dirijidas al campo del dasarrollo/diseño web, aunque Adobe cuenta con Photoshop, para muchos la mejor herramienta gráfica que ha salido al mercado en todos estos años.
Por ejemplo, para Diego Lafuente la fusión puede generar ciertos beneficios:
…Esto es groso, genial, brutal, de hecho quiero ver las cosas que saldrán de esta fusión (por ej.): PDF + Flash + Flex… oh Dios, lo que viene lo que viene…
Pero desde mi punto de vista Diego no está considerando un factor muy importante, y es que históricamente las empresas monopolistas, al no tener competencia en el mercado, hacen lo que les da la gana con él, por ejemplo, podrían aumentar los precios de sus productos y sus clientes estarían obligados (en caso de realizar una actualización de la suite o de alguna de las aplicaciones en particular) a cancelar montos bastante considerables, por lo que habría que evaluar los posibles aumentos en los costos de dichas inversiones en pequeñas y medianas empresas, por otra parte, es bien sabido que las empresas monopolistas no actualizan su software con regularidad, en ciertos casos, solo aplican “parches”, los cuales son considerados mejoras al software por parte de la empresa (en este caso en particular, Adobe), para adquirir estas “mejoras” el cliente debe cancelar ciertos montos, pero una mejora drástica no se llega a ver tan seguido como en los casos cuando existe competencia en el mercado.
El mismo Diego en uno de los comentarios dejados en su artículo Adobe compra Macromedia parece comprender el riesgo que se genera en el momento en que una empresa controla el mercado, sobretodo, en cuanto a los precios.
Sí eran competidores, competían… Adobe pujaba por la web permanentemente. Aunque FW costaba 4 veces menos, era competidor. Le quitaba un gran mercado, yo siempre usé Photoshop es que no es que me disgustara el FW simplemente no me gustaba el sistema de trabajo que tiene. Muchos lo encontraron muy cómodo.
También podriamos considerar otro hecho bastante peculiar, y es que una persona que venía trabajando con la suite ofrecida por Macromedia hace varios años, puede que no esté acostumbrada al posible cambio en el flujo de trabajo que proponga Adobe en las aplicaciones de ahora en adelante, ¿es posible medir el costo generado por estos cambios?, en realidad no es una tarea sencilla, pero es suficientemente claro que este proceso de “adaptación” representa ciertos costos para una empresa, ya que en el caso de sufrir cambios drásticos, habría que dedicar cierto tiempo al proceso de adaptación, y es que nosotros los seres humanos, somos animales de costumbres, es decir, ciertos cambios podrían generar pequeños inconvenientes a la hora de trabajar con estas aplicaciones.
Ya para finalizar, quisiera mostrar mi apoyo a la opinión emitida por Gez.
No me traten de utópico. Sólo creo que el acceso masivo a la información y la universalización del conocimiento es el paso evolutivo lógico para la humanidad, y no le veo mucha vida a estas corporaciones cuyo único vector son las ganancias.
La aparición de la imprenta marcó en su momento una gran revolución, porque le quitaba poder a la iglesia, que entonces era poseedora del poder que da el conocimiento.
Ahora estamos en los umbrales de una nueva revolución, donde el conocimiento y la tecnología se empezarán a ver como un bien de la humanidad y no como algo a lo que sólo empresas multimillonarias puedan acceder.
Amén. Existen alternativas libres que pueden igualar o mejorar el rendimiento de las aplicaciones descritas anteriormente, pero de igual manera, como mencione anteriormente, el hombre es un animal de costumbres, allí radica la esencia del cambio.
debian
apt-get detrás de proxy con autenticación NTLM
Por motivos que no vienen al caso discutir en este artículo tuve que instalar Debian GNU/Linux detrás de un proxy que aún utiliza NTLM como medio de autenticación, aunque NTLM ya no es recomendado por Microsoft desde hace años en pro de usar Kerberos.
Una vez instalada la distribución quería utilizar apt-get para actualizarla e
instalar nuevos paquetes, el resultado fue que apt-get no funciona de manera
transparente detrás de un proxy con autenticación NTLM. La solución fue
colocar un proxy interno que esté atento a peticiones en un puerto particular
en el host, el proxy interno se encargará de proveer de manera correcta las
credenciales al proxy externo.
La solución descrita previamente resulta sencilla al utilizar cntlm. En
principio será necesario instalarlo vía dpkg, posteriormente deberá editar los
campos apropiados en el fichero /etc/cntlm.conf
- Username
- Domain
- Password
- Proxy
Seguidamente reinicie el servicio:
# /etc/init.d/cntlm restart
Ahora solo resta configurar apt-get para que utilice nuestro proxy interno,
para ello edite el fichero /etc/apt.conf.d/02proxy
Acquire::http::Proxy "http://127.0.0.1:3128";
NOTA: Se asume que el puerto de escucha de cntlm es el 3128.
Ahora puede hacer uso correcto de apt-get:
# apt-get update
# apt-get upgrade
...
NOTA FINAL: Es evidente que cualquier comando o herramienta que necesite
autenticarse contra el proxy externo deberá configurarlo para que utilice el
proxy interno, lo explicado en este artículo no solo aplica para el comando
apt-get.
Construyendo de manera efectiva y rápida imágenes ISO de Debian con jigdo
Si usted desea el conjunto de CD o DVD para instalar Debian, tiene muchas posibilidades, desde la compra de los mismos, muchos de los vendedores contribuyen con Debian. También puede realizar descargas vía HTTP/FTP, vía torrent o rsync. Pero en este artículo se discutirá sobre un método para construir las imágenes ISO de Debian de manera eficiente, sobretodo si cuenta con un repositorio local de paquetes, dicho método se conoce de manera abreviada como jigdo o Jigsaw Download.
Las ventajas que ofrece jigdo están bien claras en el portal de Debian, cito:
¿Por qué jigdo es mejor que una descarga directa?
¡Porque es más rápido! Por varias razones, hay muchas menos réplicas para imágenes de CDs que para el archivo «normal» de Debian. Consecuentemente, si descarga desde una réplica de imágenes de CD, esa réplica no sólo estará más lejos de su ubicación, además estará sobrecargada, especialmente justo después de una publicación.
Además, algunos tipos de imágenes no están disponibles para descarga completa como .iso porque no hay suficiente espacio en nuestros servidores para alojarlas.
Considero que la pregunta pertinente ahora es: ¿Cómo descargo la imagen con jigdo?.
En primer lugar, instalamos el paquete jigdo-file.
# aptitude install jigdo-file
Mi objetivo era generar los 2 primeros CD para Debian Lenny, para la fecha de publicación de este artículo la versión más reciente es la 5.0.7. La lista de imágenes oficiales para jigdo las puede encontrar acá.
milmazz@manaslu /tmp $ cat files
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.template
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.template
milmazz@manaslu /tmp $ wget -c -i files
--2010-12-02 12:39:52-- http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
Resolving cdimage.debian.org... 130.239.18.163, 130.239.18.173, 2001:6b0:e:2018::173, ...
Connecting to cdimage.debian.org|130.239.18.163|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 31737 (31K) [text/plain]
Saving to: `debian-507-i386-CD-1.jigdo'
100%[===================================================================================================================>] 31.737 44,7K/s in 0,7s
...
FINISHED --2010-12-02 12:50:15--
Downloaded: 4 files, 27M in 10m 21s (44,7 KB/s)
milmazz@manaslu /tmp $ ls
debian-507-i386-CD-1.jigdo debian-507-i386-CD-1.template debian-507-i386-CD-2.jigdo debian-507-i386-CD-2.template files
Una vez descargados los ficheros necesarios, es hora de ejecutar el comando
jigdo-lite, siga las instrucciones del asistente.
milmazz@manaslu ~ $ jigdo-lite debian-507-i386-CD-2.jigdo
Jigsaw Download "lite"
Copyright (C) 2001-2005 | jigdo@
Richard Atterer | atterer.net
Loading settings from `/home/milmazz/.jigdo-lite'
-----------------------------------------------------------------
Images offered by `debian-507-i386-CD-2.jigdo':
1: 'Debian GNU/Linux 5.0.7 "Lenny" - Official i386 CD Binary-2 20101127-16:55 (20101127)' (debian-507-i386-CD-2.iso)
Further information about `debian-507-i386-CD-2.iso':
Generated on Sat, 27 Nov 2010 17:02:14 +0000
-----------------------------------------------------------------
If you already have a previous version of the CD you are
downloading, jigdo can re-use files on the old CD that are also
present in the new image, and you do not need to download them
again. Mount the old CD ROM and enter the path it is mounted under
(e.g. `/mnt/cdrom').
Alternatively, just press enter if you want to start downloading
the remaining files.
Files to scan:
El comando despliega información acerca de la imagen ISO que generará, en este
caso particular, debian-507-i386-CD-2.iso. Además, jigdo-lite puede
reutilizar ficheros que se encuentren en CD viejos y así no tener que
descargarlos de nuevo. Sin embargo, este no era mi caso así que presione la
tecla ENTER.
-----------------------------------------------------------------
The jigdo file refers to files stored on Debian mirrors. Please
choose a Debian mirror as follows: Either enter a complete URL
pointing to a mirror (in the form
`ftp://ftp.debian.org/debian/'), or enter any regular expression
for searching through the list of mirrors: Try a two-letter
country code such as `de', or a country name like `United
States', or a server name like `sunsite'.
Debian mirror [http://debian.example.com/debian/]:
En esta fase jigdo-lite solicita la dirección URL completa de un
repositorio, aproveche la oportunidad de utilizar su repositorio local si es que
cuenta con uno. Luego de presionar la tecla ENTER es tiempo de relajarse y
esperar que jigdo descargue todos y cada uno de los ficheros que componen la
imagen ISO.
Luego de descargar los paquetes y realizar las operaciones necesarias para la
construcción de la imagen ISO jigdo le informará los resultados.
FINISHED --2010-12-01 14:43:50--
Downloaded: 6 files, 2,5M in 1,8s (1,39 MB/s)
Found 6 of the 6 files required by the template
Successfully created `debian-507-i386-CD-2.iso'
-----------------------------------------------------------------
Finished!
The fact that you got this far is a strong indication that `debian-507-i386-CD-2.iso'
was generated correctly. I will perform an additional, final check,
which you can interrupt safely with Ctrl-C if you do not want to wait.
OK: Checksums match, image is good!
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
milmazz@manaslu ~ $ time jigdo-lite debian-507-i386-CD-2.jigdo
...
real 8m35.704s
user 0m13.101s
sys 0m16.569s
Nada mal, ¿no les parece?.
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
Referencias
Instalando dependencias no-libres de JAVA en ambientes pbuilder
El día de hoy asumí la construcción de unos paquetes internos compatibles con
Debian 5.0 (a.k.a. Lenny) que anteriormente eran responsabilidad de
ex-compañeros de labores. El paquete en cuestión posee una dependencia
no-libre, sun-java6-jre. En este artículo se describirá como lograr
adecuar su configuración de pbuilder para la correcta construcción del
paquete.
Asumiendo que tiene un configuración similar a la siguiente:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
Para mayor información sobre estas opciones sírvase leer:
$ man 5 pbuilderrc
Mientras intenta compilar su paquete en el ambiente proporcionado por pbuilder
el proceso fallará ya que no se mostró la ventana para aceptar la licencia de
JAVA. Podrá observar en el registro de la construcción del build un mensaje
similar al siguiente:
Unpacking sun-java6-jre (from .../sun-java6-jre_6-20-0lenny1_all.deb) ...
sun-dlj-v1-1 license could not be presented
try 'dpkg-reconfigure debconf' to select a frontend other than noninteractive
dpkg: error processing /var/cache/apt/archives/sun-java6-jre_6-20-0lenny1_all.deb (--unpack):
subprocess pre-installation script returned error exit status 2
Para evitar esto altere la configuración del fichero pbuilderrc de la
siguiente manera:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
export DEBIAN_FRONTEND="readline"
Una vez alterada la configuración podrá interactuar con las opciones que le
ofrece debconf.
Ahora bien, si usted constantemente tiene que construir paquetes con dependencias no-libres como las de JAVA, es probable que le interese lo que se menciona a continuación.
Si lee detenidamente la página del manual de pbuilder en su sección 8 podrá
encontrar lo siguiente:
$ man 8 pbuilder
...
--save-after-login
--save-after-exec
Save the chroot image after exiting from the chroot instead of deleting changes. Effective for login and execute session.
...
Por lo tanto, usaremos esta funcionalidad que ofrece pbuilder para insertar
valores por omisión en la base de datos de debconf para que no se nos pregunte
si deseamos aceptar la licencia de JAVA:
# pbuilder login --save-after-login
I: Building the build Environment
I: extracting base tarball [/var/cache/pbuilder/base.tgz]
I: creating local configuration
I: copying local configuration
I: mounting /proc filesystem
I: mounting /dev/pts filesystem
I: Mounting /var/cache/pbuilder/ccache
I: policy-rc.d already exists
I: Obtaining the cached apt archive contents
I: entering the shell
File extracted to: /var/cache/pbuilder/build//27657
pbuilder:/# cat > java-license << EOF
> sun-java6-bin shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jdk shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jre shared/accepted-sun-dlj-v1-1 boolean true
> EOF
pbuilder:/# debconf-set-selections < java-license
pbuilder:/# exit
logout
I: Copying back the cached apt archive contents
I: Saving the results, modifications to this session will persist
I: unmounting /var/cache/pbuilder/ccache filesystem
I: unmounting dev/pts filesystem
I: unmounting proc filesystem
I: creating base tarball [/var/cache/pbuilder/base.tgz]
I: cleaning the build env
I: removing directory /var/cache/pbuilder/build//27657 and its subdirectories
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234
Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
Haciendo el cambio de ipw3945 a iwl3945
Si usted es de esas personas que cuenta con una tarjeta inalámbrica Intel Corporation PRO/Wireless 3945, seguramente sabrá que existen al menos dos proyectos que le dan soporte. El primero de ellos es ipw3945 y se encuentra obsoleto, el desarrollo pasó al proyecto iwlwifi.
Aprovechando que recientemente ha ingresado a la versión inestable de Debian la serie del kernel 2.6.24, este contiene el nuevo modulo iwl3945 que reemplaza al viejo ipw3945. Una de las ventajas de este cambio es que ya no hay necesidad de tener activo el demonio ipw3945d. Sin embargo, aun se necesita del firmware que se encuentra en la sección non-free del repositorio de Debian.
Hasta donde he leído el plan será remover los paquetes ipw3945-modules-* e ipw3945d de los repositorios de Debian (al menos en testing y en unstable) una vez que la serie 2.6.24 del kernel llegue a la versión de pruebas (testing). Aquellos que se encuentren hoy día en la versión inestable (unstable) de Debian deberán cambiar el driver desde ipw3945 a iwl3945. Para aquellos que trabajan en etch también es posible usar el driver iwl3945 si actualiza su versión del kernel por medio del repositorio etch-backports (el nuevo stack mac80211 que usa iwlwifi se encuentra a partir de la versión del kernel 2.6.22).
Las instrucciones que verá a continuación se han aplicado en Debian inestable, si usted desea instalar iwlwifi en etch puede seguir estas instrucciones.
Obteniendo algunos datos de interés antes de proceder con la actualización.
Versión del kernel:
$ uname -r
2.6.22-3-686
Verifique que en realidad tiene una tarjeta Intel Corporation PRO/Wireless 3945 $ lspci -nn | grep Wireless 03:00.0 Network controller [0280]: Intel Corporation PRO/Wireless 3945ABG Network Connection [8086:4227] (rev 02)
Paquetes necesarios
Ahora bien, es necesario instalar el nuevo kernel y el firmware necesario para hacer funcionar a iwlwifi
# aptitude install linux-image-2.6-686 \\
linux-image-2.6.24-1-686 \\
firmware-iwlwifi
Evitando problemas
Verifique que no existe alguna entrada que haga referencia al modulo ipw3945 en el fichero /etc/modules. Para ello recurrimos a Perl que nos facilita la vida.
# perl -i -ne 'print unless /^ipw3945/' /etc/modules
Debido a algunos problemas que se presentan en el paquete network-manager si anteriormente ha venido usando el modulo ipw3945 se recomienda eliminar la entrada que genera udev para dicho modulo en el fichero /etc/udev/rules.d/z25_persistent-net.rules, la entrada es similar a la siguiente:
# PCI device 0x8086:0x4227 (ipw3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTRS{address}=="00:13:02:4c:12:12", NAME="eth2"
Fichero /etc/network/interfaces
Este paso es opcional, agregamos la nueva interfaz wlan0 al fichero /etc/network/interfaces y procedemos a configurarla de acuerdo a nuestras necesidades.
auto lo
iface lo inet loopback
auto wlan0
iface wlan0 inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-key-mgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
En este caso particular se está indicando que nos vamos a conectar a un Access Point cuyo ssid es foo con tipo de cifrado WPA-PSK/WPA2-PSK, haciendo uso del driver wext que funciona como backend para wpa_supplicant. Es de hacer notar que el driver wext es utilizado por todos los adaptadores Intel Pro Wireless, eso incluye ipw2100, ipw2200 e ipw3945.
Para hacer funcionar WPA recuerde que debe haber instalado previamente el paquete wpasupplicant.
# aptitude install wpasupplicant
De igual manera se le recuerda adaptar todos aquellos parámetros como wpa-ssid y wpa-psk a aquellos adecuados en su caso. En particular el campo wpa-psk lo puede generar con el siguiente comando:
$ wpa_passphrase su_ssid su_passphrase
Aunque mi recomendación es usar el comando wpa_passphrase de la siguiente manera.
$ wpa_passphrase su_ssid
Posteriormente deberá introducir su_passphrase desde la entrada estándar, esto evitará que su_passphrase quede en el historial de comandos.
Para mayor detalle de los campos expuestos en la configuración del fichero /etc/network/interfaces se le recomienda leer la documentación expuesta en /usr/share/doc/wpasupplicant/README.modes.gz.
Una vez concluidos estos pasos reiniciamos el sistema y seleccionamos en nuestro Gestor de Arranque (ej. GRUB) la versión del kernel recien instalada. Al momento de iniciar su sesión verifique que su tarjeta inalámbrica esté funcionando, de lo contrario haga las revisiones que se indican en la siguiente sección.
En caso de persistir los problemas
Remueva y reinserte el modulo iwl3945
# modprobe -r iwl3945
# modprobe iwl3945
De manera adicional compruebe que udev haya generado una nueva entrada para iwl3945.
$ cat /etc/udev/rules.d/z25_persistent-net.rules
...
# PCI device 0x8086:0x4227 (iwl3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTR{address}=="00:13:02:4c:12:12", ATTR{type}=="1", NAME="wlan0"
Finalmente, reestablecemos la interfaz de red.
# ifdown wlan0
# ifup wlan0
Elimine ipw3945
Una vez verificado el correcto funcionamiento del módulo iwl3945 puede eliminar con seguridad todo aquello relacionado con el modulos ipw3945.
# aptitude --purge remove firmware-ipw3945 \\
ipw3945-modules-$(uname -r) \\
ipw3945-source ipw3945d
Estas instrucciones también aplican para el modulo iwl4965. Mayor información en Debian Wiki § iwlwifi.
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Recuperando una antigua Logitech Quickcam Express
No se porque motivo o razón comencé a revisar en unas cajas de mi cuarto, cuando de repente me encontré con la primera cámara web que compre, de hecho, vino como accesorio a mi máquina de escritorio Compaq Presario 5006LA. Así que me pregunté, ¿será que todavía funciona esta reliquia?.
Lo primero que hice fue conectar el dispositivo en cuestión a mi portátil actual, enseguida ejecuté el comando:
$ lsusb | grep -i logitech
Bus 002 Device 002: ID 046d:0840 Logitech, Inc. QuickCam Express</code>
Una vez conocido el PCI ID (046d:0840) del dispositivo realicé una búsqueda rápida en Google y llegué a un sitio muy interesante, en donde podemos obtener una descripción de los dispositivos USB para Linux, al usar la función de búsqueda en la base de datos del sitio mencionado previamente ingreso el dato correspondiente al Vendor ID (en mi caso, 046d), posteriormente filtre los resultados por el Product ID (en mi caso, 0840), sentía que ya estaba dando con la solución a mi problema, había encontrado información detallada acerca de mi Logitech Quickcam Express. Al llegar acá descubrí el Linux QuickCam USB Web Camera Driver Project.
En la página principal del Linux QuickCam USB Web Camera Driver Project observo que mi vejestorio de cámara es soportada por el driver qc-usb.
Con la información anterior decido hacer uso del manejador de paquetes aptitude y en los resultados avisté el nombre de un paquete qc-usb-source, así que definitivamente nuestra salvación es module-assistant.
# aptitude install qc-usb-source \\
build-essential \\
module-assistant \\
modconf \\
linux-headers-`uname -r`
# m-a update
# m-a prepare
# m-a a-i qc-usb
Una vez realizado el paso anterior recurro a la utilidad de configuración de módulos en Debian modconf e instalo el módulo quickcam, el cual se encuentra en /lib/modules/2.6.18-4-686/misc/quickcam.ko y verificamos.
# tail /var/log/messages
May 14 21:16:57 localhost kernel: Linux video capture interface: v2.00
May 14 21:16:57 localhost kernel: quickcam: QuickCam USB camera found (driver version QuickCam USB 0.6.6 $Date: 2006/11/04 08:38:14 $)
May 14 21:16:57 localhost kernel: quickcam: Kernel:2.6.18-4-686 bus:2 class:FF subclass:FF vendor:046D product:0840
May 14 21:16:57 localhost kernel: quickcam: Sensor HDCS-1000/1100 detected
May 14 21:16:57 localhost kernel: quickcam: Registered device: /dev/video0
May 14 21:16:57 localhost kernel: usbcore: registered new driver quickcam
Como puede observarse el dispositivo es reconocido y se ha registrado en /dev/video0. En este instante que poseemos los módulos del driver qc-sub para nuestro kernel, podemos instalar la utilidad qc-usb-utils, esta utilidad nos permitirá modificar los parámetros de nuestra Logitech QuickCam Express.
# aptitude install qc-usb-utils
Ahora podemos hacer una prueba rápida de nuestra cámara, comienza la diversión, juguemos un poco con mplayer.
$ mplayer tv:// -tv driver=v4l:width=352:height=288:outfmt=rgb24:device=/dev/video0:noaudio -flip
A partir de ahora podemos probar más aplicaciones ;)
Network Manager: Facilitando el manejo de redes inalámbricas
En la entrada previa, Establecer red inalámbrica en Dell m1210, comencé a describir el proceso que seguí para lograr hacer funcionar la tarjeta Broadcom Corporation Dell Wireless 1390 WLAN Mini-PCI Card (rev 01) en una portátil Dell m1210. El motivo de esta entrada se debe a que muchos usuarios hoy día no les interesa ni debe interesarles estar lidiando con la detección de redes inalámbricas, por eso les pasaré a comentar acerca de NetworkManager.
NetworkManager es una aplicación cuyo objetivo es que el usuario nunca tenga que lidiar con la línea de comandos o la edición de ficheros de configuración para manejar sus redes (ya sea cableada o inalámbrica), haciendo que la detección de dichas redes simplemente funcione tanto como se pueda y que interrumpa lo menos posible el flujo de trabajo del usuario. De manera que cuando usted se dirija a áreas en las cuales usted ha estado antes, NetworkManager se conectará automáticamente a la última red que haya escogido. Asimismo, cuando usted esté de vuelta al escritorio, NetworkManager cambiará a la red cableada más rápida y confiable.
Por los momentos, NetworkManager soporta redes cifradas WEP, el soporte para el cifrado WPA está contemplado para un futuro cercano. Respecto al soporte de VPN, NetworkManager soporta hasta ahora vpnc, aunque también está contemplado darle pronto soporte a otros clientes.
Para hacer funcionar NetworkManager en Debian los pasos que debemos seguir son los siguientes. En primera instancia instalamos el paquete.
# aptitude -r install network-manager-gnome
Que conste que NetworkManager funciona para entornos de escritorios como GNOME, KDE, XFCE, entre otros. En este caso particular estoy instalando el paquete disponible en Debian para GNOME en conjunto con sus recomendaciones.
De acuerdo al fichero /usr/share/doc/network-manager/README.Debian NetworkManager consiste en dos partes: uno a nivel del demonio del sistema que se encarga de manejar las conexiones y recoge información acerca de las nuevas redes. La otra parte es un applet que el usuario emplea para interactuar con el demonio de NetworkManager, dicha interacción se lleva a cabo a través de D-Bus.
En Debian por seguridad, los usuarios que necesiten conectarse al demonio de NetworkManager deben estar en el grupo netdev. Si usted desea agregar un usuario al grupo netdev utilice el comando adduser usuario netdev, luego de ello tendrá que recargar dbus haciendo uso del comando /etc/init.d/dbus reload.
Es necesario saber que NetworkManager manejará todos aquellos dispositivos que no estén listados en el fichero /etc/network/interfaces, o aquellos que estén listados en dicho fichero con la opción auto o dhcp, de esta manera usted puede establecer una configuración para un dispositivo que sea estática y puede estar seguro que NetworkManager no tratará de sobreescribir dicha configuración. Para mayor información le recomiendo leer detenidamente el fichero /usr/share/doc/network-manager/README.Debian.
Si usted desea que NetworkManager administre todas las interfaces posibles en su ordenador, lo más sencillo que puede hacer es dejar solo lo siguiente en el fichero /etc/network/interfaces.
$ cat /etc/network/interfaces
auto lo
iface lo inet loopback
Una vez que se ha modificado el fichero /etc/network/interfaces reiniciamos NetworkManager con el comando service network-manager restart. El programa ahora se encargará de detectar las redes inalámbricas disponibles. Para ver una lista de las redes disponibles, simplemente haga clic en el icono, tal como se muestra en la figura al principio de este artículo.
Había mencionado previamente que NetworkManager se conectará automáticamente a las redes de las cuales tiene conocimiento con anterioridad, pero usted necesitará conectarse manualmente a una red al menos una vez. Para ello, simplemente seleccione una red de la lista y NetworkManager automáticamente intentará conectarse. Si la red requiere una llave de cifrado, NetworkManager le mostrará un cuadro de dialogo en el cual le preguntará acerca de ella. Una vez ingresada la llave correcta, la conexión se establecerá.
Para cambiar entre redes, simplemente escoja otra red desde el menú que le ofrece el applet.
Establecer red inalámbrica en Dell m1210
Hace ya algunos días Ana me comentaba que no le estaba funcionando la configuración que tenía para su red inalámbrica, eso ocurrió una vez que actualizó la versión del kernel de linux, espero entrar en detalle acerca de los pasos que seguí para configurarle todo como se debe bajo Debian Etch.
Lo primero que debía saber era el tipo de componente PCI al que me estaba enfrentando.
$ lspci -nn | grep Wireless
0c:00.0 Network controller [0280]:
Broadcom Corporation Dell Wireless 1390
WLAN Mini-PCI Card [14e4:4311] (rev 01)
Lo anterior dice que nos estamos enfrentando ante una Broadcom cuyo chipset id es el 4311, debemos saber que el módulo para linux de estos chips es el bcm43xx y ha sido incluido al kernel de linux desde la versión 2.6.17-rc2Fuente: http://bcm43xx.berlios.de/, al revisar la lista de dispositivos soportados me percaté que el soporte para este chipset id aún es inestable, así que el siguiente paso era eliminar su presencia si aplicaba.
$ lsmod | grep bcm43xx
bcm43xx 148500 0
ieee80211softmac 40704 1 bcm43xx
ieee80211 39112 2 bcm43xx,ieee80211softmac
Como se puede observar en este caso aplica, así que comenzamos a eliminar su presencia.
# grep -q '^blacklist bcm43xx' /etc/modprobe.d/blacklist \\
|| tee -a 'blacklist bcm43xx' /etc/modprobe.d/blacklist
La inclusión de la línea blacklist bcm43xx al fichero /etc/modprobe.d/blacklist si aplica me permite indicar que dicho módulo no debe cargarse como resultado de la expansión de su alias, es decir, bcm43xx, esto se hace con el propósito de evitar que el subsistema hotplug lo carge, aunque esto no evita que el módulo se carge automáticamente por el kernel.
Luego verifique el fichero /etc/modules, el cual contiene los nombre de los módulos que serán cargados a la hora del inicio del sistema, no había entrada para el módulo bcm43xx, ahora es necesario remover dicho módulo, para lo cual hacemos:
# modprobe -r bcm43xx
Una vez culminado este proceso es necesario hacer uso de ndiswrapper, el cual es un módulo que me permite cargar y ejecutar drivers propietarios de Windows para tarjetas inalámbricas.
# aptitude -r install build-essential \\
module-assistant ndiswrapper-common
# m-a update
# m-a prepare
# m-a a-i ndiswrapper
# modprobe ndiswrapper
Una vez cargado el módulo ndiswrapper es necesario instalar el nuevo driver propietario, para ello debemos encontrar el fichero con extensión inf, este fichero especifica que ficheros necesitan estar presentes o descargarse para que el componente funcione correctamente, para dicho driver. Al consultar en la lista de tarjetas que funcionan con ndiswrapper me percato que han habido problemas de seguridad en algunos de los drivers recomendados para esta tarjeta, así que para asegurarme de obtener las versiones más recientes ingreso al sitio oficial de Dell, bajo la sección USA -> Support search: “m1210” -> Drivers and Downloads -> Network & Internet -> Network Driver, ingreso el campo correspondiente al service tag, y finalmente descargo el fichero R151517.EXE.
El siguiente paso es extraer los ficheros que se encuentran dentro de R151517.EXE, para ello:
unzip R151517.EXE
Ahora nos interesa el fichero bcmwl5.inf que está dentro del directorio DRIVER.
$ tree R151517/DRIVER/
R151517/DRIVER/
|-- bcm43xx.cat
|-- bcm43xx64.cat
|-- bcmwl5.inf
|-- bcmwl5.sys
`-- bcmwl564.sys
Una vez extraídos los ficheros, procedemos a cargar el driver, para ello hacemos lo siguiente:
# ndiswrapper -i R151517/DRIVER/bcmwl5.inf
Comprobamos que el driver se ha instalado correctamente.
# ndiswrapper -l
installed drivers:
bcmwl5 driver installed, hardware (14E4:4324) present (alternate driver: bcm43xx)
Luego verificamos nuestro trabajo al ejecutar el comando dmesg, tal como se muestra a continuación:
$ dmesg
[44093.473325] ndiswrapper version 1.27 loaded (preempt=no,smp=yes)
[44095.311236] ndiswrapper (link_pe_images:577): fixing KI_USER_SHARED_DATA address in the driver
[44093.482777] ndiswrapper: driver bcmwl5 (Broadcom,03/23/2006, 4.40.19.0) loaded
[44093.483250] ACPI: PCI Interrupt 0000:0c:00.0[A] -> GSI 17 (level, low) -> IRQ 177
[44093.483367] PCI: Setting latency timer of device 0000:0c:00.0 to 64
[44093.491760] ndiswrapper: using IRQ 177
[44094.162703] wlan0: vendor:
[44094.162708] wlan0: ethernet device 00:18:f3:6b:fc:3b using NDIS driver bcmwl5, 14E4:4311.5.conf
[44094.162772] wlan0: encryption modes supported: WEP; TKIP with WPA, WPA2, WPA2PSK; AES/CCMP with WPA, WPA2, WPA2PSK
[44094.166554] usbcore: registered new driver ndiswrapper
[44094.167390] ndiswrapper: changing interface name from 'wlan0' to 'eth1'
En este preciso instante el comando ifconfig -a debe mostrarnos la nueva interfaz, y el comando iwlist eth1 scan al ejecutarse como superusuario devolverá la lista de redes que han sido detectadas.
Recuerde que para que todo esto siga funcionando aún después de reiniciar el sistema, es necesario cargar el módulo de ndiswrapper, para ello hago uso del comando modconf.
*[PCI]: Peripheral Component Interconnect
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
GRUB: Mejorando nuestro gestor de arranque
Anteriormente había comentado en la primera entrega del artículo Debian: Bienvenido al Sistema Operativo Universal que por medidas de seguridad establezco las opciones de montaje ro, nodev, nosuid, noexec en la partición /boot, donde se encuentran los ficheros estáticos del gestor de arranque.
El gestor de arranque que manejo es GRUB. Por lo tanto, el motivo de este artículo es explicar como suelo personalizarlo, tanto para dotarle de seguridad como mejorar su presentación.
Seguridad
Lo primero que hago es verificar el dueño y los permisos que posee el fichero /boot/grub/menu.lst, en mi opinión la permisología más abierta y peligrosa sería 644, pero normalmente la establezco en 600, evitando de ese modo que todos los usuarios (excepto el dueño del fichero, que en este caso será root) puedan leer y escribir en dicho fichero. Para lograr esto recurrimos al comando chmod.
# chmod 600 /boot/grub/menu.lst
Si usted al igual que yo mantiene a /boot como una partición de solo lectura, deberá montar de nuevo la partición /boot estableciendo la opción de escritura, para lo cual hacemos:
# mount -o remount,rw /boot
Después de ello si podrá cambiar la permisología del fichero /boot/grub/menu.lst de ser necesario.
El segundo paso es evitar que se modifique de manera interactiva las opciones de inicio del kernel desde el gestor de arranque, para ello estableceremos una contraseña para poder editar dichas opciones, pero primero nos aseguraremos de cifrar esa contraseña con el algoritmo MD5. Por lo tanto, haremos uso de grub-md5-crypt
# grub-md5-crypt
Password:
Retype password:
$1$56z5r1$yMeSchRfnxdS3QDzLpovV1
La última línea es el resultado de aplicarle el algoritmo MD5 a nuestra contraseña, la copiaremos e inmediatamente procedemos a modificar de nuevo el fichero /boot/grub/menu.lst, el cual debería quedar más o menos como se muestra a continuación.
password --md5 $1$56z5r1$yMeSchRfnxdS3QDzLpovV1
title Debian GNU/Linux, kernel 2.6.18-3-686
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro
initrd /initrd.img-2.6.18-3-686
savedefault
title Debian GNU/Linux, kernel 2.6.18-3-686 (single-user mode)
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro single
initrd /initrd.img-2.6.18-3-686
savedefault
La instrucción password --md5 aplica a nivel global, así que cada vez que desee editar las opciones de inicio del kernel, tendrá que introducir la clave (deberá presionar la tecla p para que la clave le sea solicitada) que le permitirá editar dichas opciones.
Presentación del gestor de arranque
A muchos quizá no les agrade el aspecto inicial que posee el GRUB, una manera de personalizar la presentación de nuestro gestor de arranque puede ser la descrita en la segunda entrega de la entrada Debian: Bienvenido al Sistema Operativo Universal en donde instalaba el paquete grub-splashimages y posteriormente establecía un enlace simbólico, el problema de esto es que estamos limitados a las imágenes que trae solo ese paquete.
A menos que a usted le guste diseñar sus propios fondos, puede usar los siguientes recursos:
Después de escoger la imagen que servirá de fondo para el gestor de arranque, la descargamos y la colocamos dentro del directorio /boot/grub/, una vez allí procedemos a modificar el fichero /boot/grub/menu.lst y colocaremos lo siguiente:
splashimage=(hd0,1)/grub/debian.xpm.gz
En la línea anterior he asumido lo siguiente:
- La imagen que he colocado dentro del directorio
/boot/grub/lleva por nombredebian.xpm.gz -
He ajustado la ubicación de mi partición
/boot, es probable que en su caso sea diferente, para obtener dicha información puede hacerlo al leer la tabla de particiones confdisk -lo haciendo uso del comandomount.$ mount | grep /boot /dev/sda2 on /boot type ext2 (rw,noexec,nosuid,nodev)
fdisk -l | grep ^/dev/sda2
/dev/sda2 1217 1226 80325 83 Linux
Por lo tanto, la ubicación de la partición /boot es en el primer disco duro, en la segunda partición, recordando que la notación en el grub comienza a partir de cero y no a partir de uno, tenemos como resultado hd0,1.
También puede darse el caso que ninguno de los fondos para el gestor de arranque mostrados en los recursos señalados previamente sean de su agrado. En ese caso, puede que le sirva el siguiente video demostrativo sobre como convertir un fondo de escritorio en un Grub Splash Image (2 MB) haciendo uso de The Gimp, espero le sea útil.
Después de personalizar el fichero /boot/grub/menu.lst recuerde ejecutar el comando update-grub como superusuario para actualizar las opciones.
Identificar el Hardware de tu PC en Debian GNU/Linux
Bien, lo que vamos a hacer a continuación es muy fácil, tán fácil como instalar un paquete, luego ejecutarlo y leer la información que él nos “escupe” (me encanta como suena :) ). Como sabrán, soy usuario de Debian GNU/Linux en su versión Etch para la arquitectura AMD64, pero ésto en realidad no es tan relevante ya que el paquete se encuentra tanto en Testing como en Stable para la mayoría de las arquitecturas y en la sección main de los repositorios.
Lo que vamos a instalar es el paquete lshw-gtk, que bien como dice en la descripción del paquete: “es una pequeña herramienta que provee información detallada de la configuración de hardware de la máquina. Puede reportar la configuración exacta de la memoria, versión de firmware, configuración de la tarjeta madre, versión del procesador y su velocidad, configuración de la caché, velocidad del bus, etc. en sistemas x86 con soporte DMI, en algunas máquinas PowerPC (se sabe de su funcionamiento en las PowerMac G4) y ADM64”.
Como ya sabrán, para instalar el paquete es tan sencillo como abrir una terminal y escribir en modo superusuario los siguiente:
# aptitude install lshw-gtk
El paquete no es muy pesado, de hecho, con todo y dependencias a penas ha de superar el mega de información, por lo que el proceso de instalación es rápido (si se tiene una conexión decente claro).
Una vez instalado el paquete no tenemos que hacer más que ejecutarlo. Para poder ejecutarlo debemos hacerlo desde una terminal, ya que según tengo entendido, no se instala en los menús del Gnome. Así que debemos escribir en una terminal (en modo superusuario):
# lshw-gtk
y listo, se ejecutará perfectamente, dejándonos navegar por unos paneles donde se encuentran los distintos componentes de nuestro sistema.
Si lo que quieres es tener un lanzador en los menús del Gnome, es muy sencillo, sólo deberás crear uno de la siguiente manera. Abre una terminal en modo superusuario y escribe lo siguiente:
gedit /usr/share/applications/LSHW.desktop
luego de presionar la tecla Enter se abrirá una ventana con el gedit en la cual deberás pegar el siguiente texto:
[Desktop Entry]
Name=LSHW
Comment=Identifica el hardware del sistema
Exec=gksu lshw-gtk
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya con eso deberías tener tu lanzador en el menú Aplicaciones –> Herramientas del sistema. Vas a necesitar de permisos de superusuario para poder ejecutarlo.
Acá una imagen de como se ve el lshw-gtk:
Creando un chroot en Etch AMD64
Bien la cosa es que tratando de instalar el Google Earth en mi Debian me he encontrado que no existe un paquete nativo para AMD64 (¿qué raro no?), por lo que me las he tenido que ingeniar para instalarlo. Nunca tuve la necesidad de hacer un chroot en el sistema ya que lo único que lo ameritaba era el Flash, pero no pensaba hacerme un chroot expresamente para el Flash y malgastar el espacio en mi disco, pero a la final siempre he tenido que hacerme uno!
Para aquellos que dominan el inglés se pueden leer el Debian GNU/Linux AMD64 HOW-TO ya que los pasos para crear el chroot los he seguido de ahí. Claro que para aquellos que no tengan mucho tiempo o no sientan la necesidad de hacer un chroot siempre existe una manera rápida de hacer funcionar las cosas en un apuro.
Para aquellos que todavía no saben qué es un chroot les recomiendo que le echen un ojo a la Guía de referencia Debian, de todas formas acá les cito textualmente de dicha guía lo que ellos definen como un chroot:
…el programa chroot, nos permite ejecutar diferentes instancias de un entorno GNU/Linux en un único sistema, simultáneamente y sin reiniciar…
El chroot en mi caso, está pensado para poder ejecutar aplicaciones a 32bits en un entorno 64 bits. El chroot es necesario ya que no se puede mezclar aplicaciones 32 bits con librerías 64 bits, por lo que se necesitan las librerías a 32 bits para correr dichas aplicaciones.
Lo que se hace en el chroot es instalar un sistema base para la arquitectura x86. Ésto lo puedes lograr haciendo en una terminal:
# debootstrap --arch i386 sid /var/chroot/sid-ia32 http://ftp.debian.org/debian/
…para lo cual, posiblemente, vas a necesitar el paquete debootstrap. Ahora bien, ¿qué hace el debootstrap?; debootstrap es usado para crear un sistema base debian from scratch (es algo como, desde la nada) sin tener que recurrir a la disponibilidad de dpkg ó aptitude. Todo ésto lo logra descargando los .deb de un servidor espejo y desempaquetándolos a un directorio, el cual, eventualmente sera utilizado con el comando ` chroot`. Por lo tanto la línea de comandos que introduciste anteriormente hace todo eso, sólo que lo vas a hacer para la rama unstable ó sid, en el directorio /var/chroot/sid-ia32 y desde el servidor espejo específicado.
El proceso anterior puede demorar según sea la velocidad de tu conexión. No pude saber cuánto demoro el proceso en mi caso porque cuando empecé a hacerlo eran altas horas de la madrugada y me quedé dormido :(. Lo que tienes que saber es que cuando éste proceso finalice, ya tendrás un sistema base x86 o 32 bits en un disco duro en el directorio /var/chroot/sid-ia32. Una vez finalizado deberías instalar algunas librerías adicionales, pero para hacerlo deberás moverte al chroot y hacerlo con aptitude:
# chroot /var/chroot/sid-ia32
…y luego instalas las librerías adicionales:
# aptitude install libx11-6
Para poder ejecutar aplicaciones dentro del chroot deberás tener también algunas partes del árbol de tu sistema 64 bits, lo cual puedes hacerlo mediante un montaje enlazado. El ejemplo a continuación, enlaza el directorio /tmp a el chroot para que éste pueda utilizar los “sockets” del X11, los cuales están en el /tmp de nuestro sistema 64 bits; y también enlaza el /home para que podamos accesarlo desde el chroot. También es aconsajable enlazar los directorios /dev, /proc y /sys. Para lograr ésto deberás editar tu fstab que se encuentra en /etc y añadir lo siguiente:
# sid32 chroot
/home /var/chroot/sid-ia32/home none bind 0 0
/tmp /var/chroot/sid-ia32/tmp none bind 0 0
/dev /var/chroot/sid-ia32/dev none bind 0 0
/proc /var/chroot/sid-ia32/proc none bind 0 0
…y luego montarlas:
# mount -a
Bien ya vamos llegando a final, unos cuántos pasos más y listo. Lo que necesitamos hacer a continuacióne es establecer los usuarios importantes en el chroot. La forma más rápida (sobretodo si tienes muchos usuarios) es copiar tus directorios /etc/passwd, /etc/shadow y /etc/group al chroot, a menos claro que quieras tomarte la molestia de añadirlos manualmente.
ADVERTENCIA! Cuando enlazas tu directorio /home al chroot, y borras éste último, todos tus datos personales se borrarán con éste, por consiguiente serán totalmente perdidos, por lo tanto debes recordar desmontar los enlaces antes de borrar el chroot.
Corriendo aplicaciones en el chroot
Después de hacer todos los pasos anteriores, ya deberías poder ejecutar aplicaciones desde el chroot. Para poder ejecutar aplicaciones desde el chroot debes hacer en una terminal (en modo root):
# chroot /var/chroot/sid-ia32
Luego deberás cambiarte al usuario con el que quieres ejecutar la aplicación:
# su - usuario
Establecer $DISPLAY:
# export DISPLAY=:0
Y finalmente ejecutar la aplicación que quieras, como por ejemplo, el firefox con el plugin de flash! Por supuesto deberás instalar la aplicación antes de ejecutarla, recuerda que lo que has instalado es un sistema base y algunas librerías adicionales.
Compilar aMSN en Debian Etch AMD64
Bien, sin mucho preámbulo, lo primero que debemos hacer es descargar el tarball de la página de amsn. Luego deberás descomprimirlo en la carpeta de tu preferencia, en mi caso está en ~/Sources/amsn-0.96RC1/. Una vez que lo descomprimes abre una terminal y obtén derechos de administrador (modo root); cuando tengas privilegios de root ubícate en el directorio donde descomprimiste el tarball y escribe lo siguiente:
$ ./configure
$ make
$ make install
Debes asegurarte de cumplir todos los requisitos cuando haces el ./configure, ya que te pide varias “dependencias” por así decirlo, como por ejemplo, tls y tk. Una vez que hayas hecho el make install quedará automágicamente instalado el amsn en tu sistema. Deberás poder verlo en Aplicaciones –> Internet –> aMSN. Bien eso es todo en lo que respecta al proceso de compilado, ¿nunca antes fué tan fácil verdad?.
Un problema que me dió una vez que lo compilé y lo ejecuté fué que no me permitía iniciar sesión porque me decía que no tenía instalado el módulo TLS. Entonces abrí una terminal e hice lo siguiente:
$ aptitude install tcltls
…pero ésto no me solucionó el problema, entonces me puse a indagar por la web y me encontré con la siguiente solución: editar el archivo /usr/lib/tls1.50/pkgIndex.tcl y ubicar la línea que dice algo como: package ifneeded tls 1.5 para entonces modificarla por package ifneeded tls 1.50 y listo :D
Smartmontools: aprendiendo a chequear tu disco duro…
Los discos duros modernos (y no tan modernos) vienen equipados con una tecnología conocida como S.M.A.R.T., el cual le permite al disco monitorear de manera contínua su propio estado de “salud” y alertar al usuario si es detectada alguna anormalidad, para que luego pueda ser corregida.
ADVERTENCIA: antes de continuar, sería recomendable hacer una copia de respaldo de todos sus datos importantes a pesar de todo lo que diga el S.M.A.R.T. Éste sistema es muy confiable pero no obstante, ésta información en alguno de los casos podría ser imprecisa, de hecho, los discos duro se dañan de manera inesperada, inclusive si el S.M.A.R.T te ha dicho que algo anda mal, posiblemente no tengas tiempo para respaldar tus datos o moverlos a un lugar más seguro.
¿Cómo instalar SMARTMONTOOLS?
Lo primero que debemos hacer, preferiblemente antes de instalar el SMT es chequear si nuestro disco duro soporta éste tipo de tecnología, lo cual puedes hacer visitando la página del fabricante de tu disco. De todas formas, si lo compraste después del año 1992, lo más seguro es que posea ésta tecnología.
Lo segundo, y no menos importante, es activar o asegurarte que en el BIOS de la tarjeta madre este activada ésta función. Lo puedes conseguir ya que luce algo como:
S.M.A.R.T for Hard Disk: Enable
Algunos BIOS no tienen ésta opción y reportan el S.M.A.R.T como inactivo, pero no te preocupes que el smartcl, uno de los dos programas de utilidad que tiene el Smartmontools, puede activarlo. Una vez que estemos seguros de todo ésto podemos proceder a instalar el Smartmontools, el cual, en la distribución que uso, Debian, es tan fácil como escribir en una terminal:
$ aptitude install smartmontools
Y de esa manera ya queda automágicamente instalado el paquete el sistema. Si quieres verificar si ya lo tienes instalado, entonces tendrías que escribir en una terminal lo siguiente:
$ aptitude show smartmontools
Y verificar que el atributo Estado se corresponda con Instalado. Una vez hecho ésto procedemos a verificar si nuestro disco soporta S.M.A.R.T con la siguiente línea de comandos:
$ smartctl -i /dev/hda
En caso que tu disco sea SATA tendrías que escribir la siguiente línea:
$ smartctl -i -d ata /dev/sda
La información se vería algo así:
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar family
Device Model: WDC WD1200BB-00RDA0
Serial Number: WD-WMANM1700779
Firmware Version: 20.00K20
User Capacity: 120,034,123,776 bytes
Device is: In smartctl database [for details use: -P show]
ATA Version is: 7
ATA Standard is: Exact ATA specification draft version not indicated
Local Time is: Sun Sep 24 22:27:09 2006 VET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Si tu disco es SATA pero tiene el soporte S.M.A.R.T desactivado, entonces deberás usar la siguiente línea de comandos para activarlo:
$ smartctl -s on -d ata /dev/sda
Aprendiendo a usar SMT
Estado de “salud” de nuestro disco duro
Para leer la información que SMT ha recopilado acerca de nuestro disco, debemos escribir la siguiente linea de comandos:
$ smartctl -H /dev/hda
Para discos SATA no es suficiente con sustituir hda con sda, sino que debemos añadir las opciones extras que usamos anteriormente para obtener la información del disco. La línea de comandos entonces quedaría así:
$ smartctl -d ata -H /dev/sda
Si lees PASSED al final de la información, no tienes que preocuparte. Pero si lees FAILED deberías empezar a hacer respaldo de tus datos inmediatamente, ya que ésto quiere decir que tu disco ha presentado fallas anteriormente o es muy probable que falle dentro de un lapso de aproximadamente 24 horas.
Bitácora de errores de SMT
Para chequear la bitácora de errores de SMT debemos escribir la siguiente línea de comandos:
$ smartctl -l error /dev/hda
De manera análoga al caso anterior, añadimos los comandos extras si nuestro disco es SATA. La línea de comandos quedaría así:
$ smartctl -d ata -l error /dev/sda
Si leemos al final de la información No errors logged todo anda bien. Si hay varios errores pero éstos no son muy recientes, deberías empezar a preocuparte e ir comprando los discos para el respaldo. Pero si en vez de ésto hay muchos errores y una buena cantidad son recientes entonces deberías empezar a hacer respaldo de tus datos, inclusive antes de terminar de leer ésta línea. Apurate! :D
A pesar que smartctl nos da una información muy valiosa acerca de nuestros discos, el tan solo revisar ésta no es suficiente, realmente se deben hacer algunas pruebas específicas para corroborar los errores que conseguimos en la información anterior, dichas pruebas las menciono a continuación.
Pruebas con SMT
Las pruebas que se van a realizar a continuación no interfieren con el funcionamiento normal del disco y por lo tanto pueden ser realizadas en cualquier momento. Aquí solo describiré como ejecutarlas y entender los errores. Si quieres saber más te recomiendo que visites ésta pagina o que leas las páginas del manual.
Lo primero sería saber cuáles pruebas soporta tu disco, lo cual logramos mediante la siguiente línea de comandos:
$ smartctl -c /dev/hda
De ésta manera puedes saber cuáles pruebas soporta tu disco y también cuanto tiempo aproximadamente puede durar cada una. Bien, ahora ejecutemos Immediate Offline Test ó Prueba Inmediata Desconetado (si está soportada, por supuesto), con la siguiente línea de comandos:
$ smartctl -t offline /dev/hda
Como ya sabemos, los resultados de ésta prueba no son inmediatos, de hecho el resultado de ésta linea de comandos te dirá que la prueba ha comenzado, el tiempo que aproximadamente va a demorar la prueba en terminar con una hora aproximada para dicha finalización, y al final te dice la línea de comandos para abortar la operación. En uno de mis discos, un IDE de 120Gb, demoró 1 hora, para que tengan una idea. Por los momentos sólo te queda esperar por los resultados. Ahora te preguntarás ¿Cómo puedo saber los resultados?, pues tan sencillo como ejecutar la línea de comandos para leer la bitácora del SMT y seguir las recomendaciones.
Ahora vamos a ejecutar Short self-test routine ó Extended self-test routine, Rutina corta de autoprueba y Rutina extendida de autoprueba, respectivamente (de nuevo, si están soportadas). Éstas pruebas son similares, sólo que la segunda, como su nombre lo indica, es más rigurosa que la primera. Una vez más ésto lo logramos con los siguientes comandos:
$ smartctl -t short /dev/hda
$ smartctl -t long /dev/hda
Luego vamos a chequear el Self Test Error Log ó Bitácora de errores de autopruebas:
$ smartctl -l selftest /dev/hda
Luego ejecutamos Conveyance Self Test ó Autoprueba de Transporte:
$ smartctl -t conveyance /dev/hda
Y por último chequeamos Self Test Error Log de nuevo.
Algo que tengo que resaltar es que el SMT tiene dos bitácoras, una de las cuales es la Bitácora de errores y la otra es la Bitácora de Errores de Autopruebas.
¿Cómo monitorear el disco duro automáticamente?
Para lograr ésto tendrás que configurar el demonio smartd para que sea cargado cuando se inicia el sistema. A continuación un pequeño HOWTO.
ADVERTENCIA: el siguiente HOWTO es para monitorear un disco IDE, programar todas las pruebas cada viernes de la semana, de 11:00 a.m a 2:00 p.m, y luego ejecutar un script de Bash si algún error es detectado. Éste script escribirá un reporte bien detallado y luego apagará el equipo para su propia protección.
El archivo de configuración de smartd se encuentra en /etc/smartd.conf, si éste no existe,
el cual sería un caso poco común, deberás crearlo en tu editor de elección.
...
#DEVICESCAN
...
/dev/hda \
-H \
-l error -l selftest \
-s (O/../../5/11|L/../../5/13|C/../../5/15) \
-m ThisIsNotUsed -M exec /usr/local/bin/smartd.sh
El script en Bash también puedes hacerlo en un editor de tu elección, y tendrá la siguiente forma:
#!/bin/bash
LOGFILE="/var/log/smartd.log"
echo -e "$(date)\n$SMARTD_MESSAGE\n" >> "$LOGFILE"
shutdown -h now
Luego de crear el script deberás hacerlo ejecutable cambiando sus atributos con la siguiente línea de comandos:
$ chmod +x /usr/local/bin/smartd.sh
Para probar todo, puedes agregar al final de tu /etc/smartd.conf la línea
-M test
y luego ejecutar el demonio. Nota que ésto apagará tu equipo, hayan errores o no. Luego si algo sale mal deberás chequear la bitácora del sistema en /var/log/messages con:
$ tail /var/log/messages
Y así corregir el problema. Ahora tendrás que quitar la línea
-M test
y guardar los cambios. Por último debes hacer que smartd sea cargado al momento del arranque, lo cual lo logras con la siguiente línea:
$ rc-update add smartd default
Algunos enlaces de interés:
- S.M.A.R.T en la Wikipedia
- Página Oficial de smartmontools
- Ejemplos de salidas del SMT
- Atributos usados para recuperar el estado físico/lógico de una unidad y mostrar su significado de una forma más entendible para un usuario final
Nota: Ésta artículo está basado en un HOWTO del Wiki de Gentoo
Audigy SE en Etch AMD64
Hace días me hice con una tarjeta de sonido Audigy SE de la marca Creative y la verdad tuve que dar bastante golpes para dar con la configuración correcta. ¿Cómo lo logré? Muy fácil: Googleando :).
Resulta que el sistema (Debian, of course) reconoce bien el dispositivo y carga de manera perfecta los módulos necesarios; de hecho el alsa-mixer me mostraba todos los canales de la tarjeta pero el único que parecía funcionar era el Analog Front y los otros parecían estar muertos. Casi daño el mouse de tando hacer clicks y darle hacia arriba y hacia abajo :). No podía creer que no funcionara!.
Googleando llegué a la página de la gente de Alsa y me encontré una manera de configurar los drivers. Ahi confirmé que el sistema me estaba cargando el módulo correcto, el snd-ca0106. Entonces, después de ver la pequeña lista de instrucciones, no voy a decir que me espanté y maldije a Creative, no, no lo hice, en ése momento miré al cielo y pregunté: ¡¿Acaso no existe una manera más fácil de lograr que suenen la benditas cornetas?! y la respuesta a mi pregunta vino del wiki de Gentoo, ¿qué cosas no? imagínense todo lo que googleé; bueno específicamente de la sección que dice VIA Envy24HT (ice1724) chip. Ahora se preguntarán.. ¿VIA? éste tipo está loco…. pues sí, VIA. ¿Y qué fué lo que hice? Abrí una terminal e hice lo siguiente:
$ gedit .asoundrc
Luego lo que hice fué copiar el contenido del segundo .asoundrc y pegarlo al mío, luego guardar los cambios y voilá, sistema de sonido 5.1 andando ;). Se preguntarán ¿Cómo hizo éste loco para saber que ese .asoundrc funciona con la Audigy SE?, bueno, con el proceso estándar, prueba error. Copiando y pegando cada uno de los ficheros.
Ahora que el sistema suena perfectamente bien me ha surgido una nueva interrogante, debido a que para poder graduar el volumen del sistema tengo que graduar los tres controles, y la pregunta es: ¿Habrá alguna forma de graduar el volumen para los tres controles al mismo tiempo? Que lo disfruten…
Debian GNU/Linux 4.0
Según puede verse en el sitio oficial del Proyecto Debian, en una noticia aparecida el día de hoy, Upcoming Release of Debian GNU/Linux 4.0, se confirma que el próximo mes de diciembre del presente año será la fecha de publicación de la siguiente versión 4.0 de Debian GNU/Linux, cuyo código nombre es “etch”.
Entre las novedades que podremos observar en esta nueva versión se encuentran las siguientes:
- Será la primera versión que ofrezca soporte oficial a la arquitectura AMD64. De manera simultánea, esta versión se publicará para 11 arquitecturas.
- La versión 4.0 ofrecerá la versión 2.6.17 del núcleo linux de manera predeterminada. Además, esta misma versión se utilizará en todas las arquitecturas y a su vez en el instalador.
- Debian GNU/Linux 4.0 presentará la colección de compiladores de GNU versión 4.1.
- Debian GNU/Linux deja de utilizar XFree86 como implementación de X11 (sistema de ventanas X) para darle paso a X.Org.
- Al menejador de paquetes APT seguramente se le añadan algunas mejoras en cuanto a seguridad, admitiendo criptografía modo paranoico y firmas digitales.
Reuniones para eliminar fallos
En la misma noticia podemos enterarnos que el Proyecto Debian está planeando algunas reuniones previas al nuevo lanzamiento en búsqueda de fallos y establecer las debidas correcciones, de esta manera, se ofrecerá al público una versión que presente la mínima cantidad de errores críticos de programación.
Estas reuniones se llevarán a cabo en varias ciudades alrededor del mundo. Por lo tanto, podrá participar el mayor número de personas en la búsqueda y corrección de estos errores de programación.
Si usted está interesado en participar pero no puede reunirse personalmente con los desarrolladores en las distintas ciudades que se describen en BSPMarathon, puede conectarse al canal #debian-bugs en el servidor irc.debian.org y de esta manera participar.
La situación en Venezuela
En mi humilde opinión, considero oportuno que la comunidad Debian Venezuela debe tomar las riendas en este asunto, organizar reuniones para eliminar fallos en nuestra distribución favorita, aprovechando la cercanía del Día Debian para organizar actividades de este tipo. ¿Qué opinan en este sentido?.
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
StarDict: El diccionario que buscaba
Leyendo el ejemplar #14 de la revista Tux Magazine me encuentro con un interesante artículo, Learning Foreign Languages with jVLT and StarDict, la segunda aplicación descrita en dicho artículo, StartDict, llamó mi atención, así que a continuación se dará una breve revisión de la aplicación en cuestión.
¿Qué es StarDict?
StarDict es un diccionario internacional multiplataforma escrito en Gtk2, puede ser utilizado sin conexión a la web.
Características
-
Búsqueda de patrones: Usted puede buscar patrones de cadenas o caracteres usando comodines, por ejemplo, podrá usar el comodín
*para buscar una cadena arbitraria, el resultado puede ser vacío, mientras que con el uso del comodín?buscará una coincidencia con un carácter arbitrario. e.g. Suponiendo que tiene instalado el diccionario Inglés – Español, al buscar el patrón hell? encontrará como resultado la traducción de hello, mientras que con el uso del patrón hell* encontrará todas aquellas posibles coincidencias que comiencen con la cadena hell, hell (infierno en inglés), hell (suerte en noruego), los resultados encontrados dependerá de los diccionarios que haya instalado. - Búsqueda difusa: Si usted por casualidad no recuerda exactamente como deletrear una palabra, podrá intentar realizar dicha búsqueda desde StarDict, éste utilizará el algoritmo de la Distancia de Levenshtein El algoritmo de la Distancia de Levenshtein o la distancia de edición entre dos cadenas, se refiere al número mínimo de operaciones necesarias para transformar una cadena en otra, bajo éste algoritmo se considera una operación a la inserción, eliminación o substitución de un carácter. Para mayor información le recomiendo leer el artículo Levenshtein Distance, in Three Flavors.. Para utilizar esta característica simplemente comience la búsqueda con el carácter /, e.g., suponga que tiene instalado el diccionario Español – Inglés, usted cree que la palabra acero realmente se escribe así: asero, simplemente introduzca en el formulario la cadena /asero, obtendrá el resultado deseado.
-
Búsqueda por palabras seleccionadas: Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada.
-
Manejo de diccionarios: StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen).
- ¿No encuentra lo que necesita?: StarDict le permite realizar búsquedas en la web, solo deberá seleccionar el botón de búsqueda en Internet y escoger cualquiera de las 10 opciones actuales de búsqueda.
Ahora bien, seguramente esta aplicación resultará útil para muchas personas, si usted es uno de ellos y está interesado en instalarlo, es muy sencillo.
¿Cómo instalar StarDict?
Si usted es tan afortunado como yo, debe estar usando Debian, así que simplemente tendrá que hacer:
# aptitude install stardict
Ahora bien, si usted utiliza por ejemplo, Ubuntu, también puede instalarlo fácilmente, ¿cómo?, en primer lugar debe activar el repositorio universe (recuerde actualizar la lista de paquetes disponibles), posteriormente debe hacer:
$ sudo aptitude install stardict
Si usted utiliza otra distribución de GNU+Linux o es usuario de Windows, lea la documentación de la página oficial del proyecto, lamento informarle que este artículo es una revisión breve de la aplicación StarDict.
¿Cómo instalar diccionarios?
Primero que nada, debe descargar los diccionarios que necesite, para ello le recomiendo ir a la página de Descarga de Diccionarios del proyecto.
Una vez que haya descargado los diccionarios, debe proceder como sigue:
tar -C /usr/share/stardict/dic -x -v -j -f \\
diccionario.tar.bz2
Personalizando la aplicación
Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Una característica de StarDict que puede resultar realmente molesta es cuando se encuentra activo el modo Scan, es decir, toda palabra o frase resaltada con el ratón generará un cuadro de dialogo con la definición de dicha palabra o frase, si usted desea controlar este comportamiento, le recomiendo activar las siguientes casillas de verificación:
- Only do scanning while modifier key being pressed.
- Hide floating window when modifier key pressed.
Las casillas de verificación previamente mencionadas podrá encontrarlas bajo la sección Dictionary -> Scan Selection.
Si usted esta inconforme con las opciones de búsqueda en Internet, puede agregar las que usted desea desde la sección Main Window -> Search Website.
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
Debian: Bienvenido al Sistema Operativo Universal (Parte II)
Esta serie de anotaciones comenzo con la entrada Debian: Bienvenido al Sistema Operativo Universal (Parte I).
Después de escribir en la tabla de particiones el esquema de particionamiento descrito en la parte anterior, el sistema base Debian comenzo a instalarse. Posterior a la Bienvenida al nuevo sistema Debian, reinicie y comence a configurar el sistema base debian, en la sección de selección de programas Debian escogí la última opción que nos brinda el asistente, selección manual de paquetes, luego configure las fuentes de aptitude y enseguida inicie la instalación de paquetes puntuales, los cuales describiré a continuación, de manera breve.
Como lo que tenía a mano era el CD Debian GNU/Linux testing Sarge- Official Snapshot i386 Binary-1, lo primero que hice fue actualizar a Sarge, seguidamente cambie las fuentes del fichero /etc/apt/sources.list a Etch, actualice la lista de paquetes disponibles e inmediatamente hice un aptitude dist-upgrade, el cambio de una rama a otra fué de lo más normal, no genero problema alguno.
Nota: No he descrito el proceso de instalación del sistema base de manera detallada ya que existe suficiente información en el sitio oficial de Debian, si lo desea, puede ver este video tutorial de instalación de Debian Sarge (aprox. 54MB.), en este video se explica como instalar el Entorno de Escritorio predeterminado que ofrece el asistente, no es el caso que explico en esta entrada, puesto que vamos a generar un Entorno de Escritorio de acuerdo a nuestras necesidades particulares.
Si tiene alguna duda acerca de la funcionalidad de un paquete en particular, puede consultar la descripción del mismo al hacer uso del comando aptitude show _package-name_, en donde package-name es el nombre del paquete en cuestión.
En los siguientes pasos haré uso intensivo de aptitude, anteriormente ya he explicado las ventajas que presenta aptitude sobre los comandos apt-get y sobre la interfaz gráfica Synaptic, puede encontrar mayor información en los artículos:
Sistema X Window
Instalando los componentes esenciales para el Sistema X Window.
# aptitude install x-window-system-core
GNOME
Instalando los componentes esenciales para el entorno de escritorio GNOME.
# aptitude install gnome-core
GNOME Display Manager
Si usted hubiese instalado el paquete x-window-system, metapaquete que incluye todos los componentes para el Sistema X Window, se instalaría por defecto XDM (X Display Manager), normalmente debería recurrir a la línea de comandos para resolver los problemas de configuración de este manejador, mientras que con GDM (GNOME Display Manager) no debe preocuparse por ello, puede personalizarlo o solucionar los problemas sin recurrir a la línea de comandos. De manera adicional, puede mejorar su presentación con la instalación de temas.
# aptitude install gdm gdm-themes
Mensajería Instantánea, IRC, Jabber
GAIM
Todo lo anterior se puede encontrar al instalar GAIM.
# aptitude install gaim gaim-themes
irssi
Si le agrada utilizar IRC modo texto, puede instalar irssi.
# aptitude install irssi
Centericq
Centericq es un cliente de mensajería instantánea multiprotocolo, soporta ICQ2000, Yahoo!, AIM, IRC, MSN, Gadu-Gadu y Jabber.
# aptitude install centericq
Programas para la manipulación de imágenes
GIMP por defecto no puede abrir ficheros SVG, si desea manipularlos desde GIMP y no desde Inkscape puede hacer uso del paquete gimp-svg.
# aptitude install gimp gimp-python gimp-svg inkscape
Navegador Web
Definitivamente Firefox.
# aptitude install firefox firefox-locale-es-es
Creación de CDs y DVDs
# aptitude install k3b cdrdao
Para quienes quieran su version de K3b en español pueden instalar el paquete k3b-i18n, yo no lo considere necesario puesto que aporta 11,5MB, inútiles desde mi punto de vista.
Cliente Bittorrent
No le recomiendo instalar el cliente bittorrent Azureus, consume demasiados recursos, acerca de ello explico brevemente en el artículo Clientes Bittorrent.
# aptitude install freeloader
Lector de feeds
Normalmente utilizo Liferea. También cabe la posibilidad de utilizar el servicio que presta Bloglines.
# aptitude install liferea
Editor
# aptitude install vim-full
Cliente de correo electrónico
Para la fecha, a la rama testing de Debian no ingresa la versión 1.5 del cliente de correo Thunderbird (mi favorito), así que vamos a instalarlo manualmente.
En primer lugar deberá descargar (se asume que la descarga se realizará al escritorio) la última versión del cliente de correo, el paquete empaquetado y comprimido lo encontrará en el sitio oficial de Thunderbird.
Seguidamente, proceda con los siguientes comandos.
# tar -C /opt/ -x -v -z -f ~/Desktop/thunderbird*.tar.gz
# ln -s /opt/thunderbird/thunderbird /usr/bin/thunderbird
Instalar Diccionario en español
wget -c http://downloads.mozdev.org/dictionaries/spell-es-ES.xpi
Aplicaciones -> Herramientas del Sistema -> Root Terminal. Desde allí procedará a ejecutar el comando thunderbird.
Desde Thunderbird, seleccione la opción Extensiones del menú Herramientas. Seguidamente proceda a dar click en el botón Instalar y posteriormente busque la ruta del paquete que contiene el diccionario.
Thunderbird + GPG = Enigmail
Esta excelente extensión le permitira cifrar y descifrar correos electrónicos, a su vez, le permitirá autenticar usuarios usando OpenPGP.
wget -c http://releases.mozilla.org/pub/mozilla.org/extensions/enigmail/enigmail-0.94.0-mz+tb-linux.xpi
Como usuario normal, proceda a invocar el cliente de correo electrónico Thunderbird, seleccione la opción Extensiones del menú Herramientas y proceda a instalar la extensión en cuestión, similar al proceso seguido para lograr instalar el diccionario.
Reproductor de videos
Aunque existen reproductores muy buenos como el VLC y XINE, mi reproductor favorito es, sin lugar a dudas, MPlayer. La mejor opción es compilarlo, aún en la misma página oficial del proyecto MPlayer lo recomiendan, existe mucha documentación al respecto. Sin embargo, si no tiene tiempo para documentarse puede seguir los siguientes pasos, le advierto que el rendimiento quizá no sea el mismo que al compilar el programa.
# echo "deb ftp://ftp.nerim.net/debian-marillat/ etch main" >> /etc/apt/sources.list
# aptitude update
# aptitude install mplayer-386 w32codecs
Extensiones para Mozilla Firefox
Estas son las que he instalado hasta ahora, siempre uso un poco más, puede encontrarlas en la sección Firefox Add-ons del sitio oficial.
- Answers
- del.icio.us
- FireFoxMenuButtons
- Colorful Tabs
- Tab Mix Plus
Gestor de Arranque
Vamos a personalizar un poco el gestor de arranque GRUB.
# aptitude install grub-splashimages
$ cd /boot/grub/splashimages
En este instante le recomiendo escoger alguno de los motivos que incluye el paquete grub-splashimages, una vez hecho esto, proceda a realizar lo siguiente.
$ cd /boot/grub/
# ln -s splashimages/image.xpm.gz splash.xpm.gz
# update-grub
En donde, evidentemente, debe cambiar el nombre del fichero image.xpm.gz por el nombre de fichero de la imagen que le haya gustado en /boot/grub/splashimages.
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Debian: Bienvenido al Sistema Operativo Universal (Parte I)
Desde el día ayer tengo en mi ordenador de escritorio solo Debian, anteriormente tenía las tres versiones actuales de Ubuntu (warty, hoary y breezy), las cuales compartían la misma particion /home, sentía que estaba desperdiciando espacio, aunque siempre trataba de usar las tres versiones de Ubuntu, una buena excusa que encontre para arreglar las cosas fué la noticia en la que se anunciaba que el período de soporte para Ubuntu 4.10 (Warty Hedgehog) estaba llegando a su fín, después del día 30 de Abril de 2006, no se incluirá información acerca de las actualizaciones de seguridad en los paquetes de Ubuntu 4.10.
Esta entrada viene a ser una recopilación de los pasos que he seguido para migrar de Ubuntu a Debian, a manera de recordatorio, espero pueda servirle a alguien más.
¿Por qué Debian?
Los siguientes puntos son solo opiniones personales.
- El paso de Ubuntu a Debian es poco traumático.
- Había trabajado con Debian en mi portátil por mucho tiempo.
- Debian no depende de ninguna compañía ni del financiamiento de un solo hombre, es un trabajo realizado solo por una comunidad de voluntarios.
- Existe demasiada (y excelente) documentación.
- Tenía que probar algo nuevo, algo mejor, algunos amigos me convencieron, y aún más después del bautizo que me dio José Parrella en el canal IRC #velug en el servidor freenode.
Primeros pasos
En primer lugar procedí a realizar respaldos de la información almacenada en programas como Mozilla Thunderbird, Liferea, Mozilla Firefox, bases de datos en PostgreSQL, MySQL, entre otros. Este proceso es realmente sencillo.
En todos los programas mencionados anteriormente fué suficiente con copiar la raíz de su directorio correspondiente, por ejemplo:
$ tar cvzf /path/respaldo/thunderbird.tgz ~/.thunderbird
El comando anterior generará un fichero empaquetado y comprimido en el directorio /path/respaldo/ (por supuesto, la ruta debe adaptarla según sus necesidades), dicho fichero contendrá la configuración personal e información almacenada por el programa Mozilla Thunderbird (según el ejemplo) del usuario en cuestión.
Obteniendo el CD de Debian
Puede conseguir Debian de muchas maneras, yo por lo menos descargue hace mucho tiempo la imagen del CD Debian GNU/Linux testing Sarge- Official Snapshot i386 Binary-1 por Bitorrent, aunque también contaba con la imagen del CD de Debian 3.1r2, desgraciadamente no pude encontrarle.
Analizando el esquema de particionamiento
Siempre acostumbro dedicarle un buen tiempo al esquema de particionamiento que utilizaré antes de proceder a instalar una distribución en particular, leyendo el manual de instalación de Debian GNU/Linux 3.1 (le dije que existe una excelente documentación), específicamente en el Apéndice B. Particionado en Debian, tenía pensado hacer lo siguiente:
Partición Tamaño Tipo
/ 200MB ext2
/usr 6GB ext3
/var 500MB ext2
/tmp 3GB ext2
/opt 200MB ext2
swap 1GB Intercambio
/home Resto ext3
Por supuesto, estaba siguiendo las recomendaciones del manual de instalación previamente mencionado, antes de continuar pregunte en el canal IRC #velug del servidor freenode y entre algunos amigos me recomendaron lo siguiente:
Partición Tamaño Tipo
/boot 80MB ext2
/tmp 3GB ext2
swap 1GB Intercambio
/ 10GB ext3
/home Resto ext3
Algunos seguramente se preguntaran por qué se le ha asignado tanto espacio a la partición /tmp, simplemente porque continúamente estaré haciendo uso de herramientas para la creación de CDs ó DVDs, además de algunos programas multimedia y siempre he configurado mis clientes Bittorrent para que hagan uso de esta partición antes de finalizar la descarga de los ficheros.
Por medidas de seguridad he establecido nodev, nosuid, noexec como opciones de montaje para la partición /tmp y las opciones ro, nodev, nosuid, noexec en la partición /boot.
¿Por qué a la final no he seguido las indicaciones del manual de instalación de Debian GNU/Linux?
Según un comentario que me hizo José Parrella, el cual más o menos decía así: cuando vas a utilizar el sistema Debian GNU/Linux para la casa, es muy probable que las particiones crezcan de manera desproporcionada y sin sentido (de acuerdo al uso que le dé el usuario), debido a esto es díficil adaptarlo a un modelo realmente conocido, entonces, la idea es no desperdiciar espacio alguno.
Resumiendo un poco la opinión de José:
- No sabemos que vamos a hacer con la máquina.
- Al no saberlo, no podemos particionarla más allá de lo que la lógica indica (separar /home, o /tmp).
- Uno sabe que el sistema raíz de Debian, para un usuario en sus cabales (no soy uno de ellos), normalmente no excede los 4.5GB., muy probablemente menos.
- A menos que sepamos exactamente la funcionalidad principal del Sistema Operativo, no podemos monitorear las particiones /var y /home.
- La partición /tmp normalmente no debe exceder más de 1GB. de espacio, a menos que se haga uso intensivo de ella como prentendo hacerlo.
- Si quisieramos un servidor de archivos, dejaríamos /var en la partición raíz y separaríamos /home.
- Si quisieramos un servidor de bases de datos, dejaríamos /home en la partición raíz y separaríamos /var.
Sus razones me convencieron y desde mi punto de vista tenían lógica, sobretodo para alguien que le gusta hacer pruebas (a veces extremas) directamente desde su ordenador de escritorio.
En la siguiente entrega disertaré acerca del proceso de instalación del sistema base de Debian GNU/Linux y la puesta en marcha de la interfaz gráfica.
Correcciones, críticas constructivas siempre serán bien recibidas.
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
Los Repositorios
Contenido:
- Definición
- ¿Cómo funcionan los Repositorios?
- ¿Cómo establecer Repositorios? 1. Los Repositorios Automáticos 2. Los Repositorios Triviales
- ¿Cómo crear ficheros Index?
- ¿Cómo crear ficheros Release?
- ¿Cómo crear Estanques? 1. Herramientas
- ¿Cómo usar los Repositorios?
Los Repositorios (definición)
Un repositorio es un conjunto de paquetes Debian organizados en un directorio en árbol especial, el cual también contiene unos pocos ficheros adicionales con los índices e información de los paquetes. Si un usuario añade un repositorio a su fichero sources.list, él puede ver e instalar facilmente todos los paquetes disponibles en éste al igual que los paquetes contenidos en Debian.
¿Cómo funcionan los repositorios?
Un repositorio consiste en al menos un directorio con algunos paquetes DEB en él, y dos ficheros especiales que son el Packages.gz para los paquetes binarios y el Sources.gz para los paquetes de las fuentes. Una vez que tu repositorio esté listado correctamente en el sources.list, si los paquetes binarios son listados con la palabra clave deb al principio, apt-get buscará en el fichero índice Packages.gz, y si las fuentes son listadas con las palabras claves deb-src al principio, éste buscará en el fichero indice Sources.gz. Ésto se debe a que en el fichero Packages.gz se encuentra toda la información de todos los paquetes, como nombre, version, tamaño, descripción corta y larga, las dependencias y alguna información adicional que no es de nuestro interés. Toda la información es listada y usada por los Administradores de Paquetes del sistema tales como dselect o aptitude. Sin embargo, en el fichero Sources.gz se encuentran listados todos los nombres, versiones y las dependencias de desarrollo (esto es, los paquetes necesitados para compilar) de todos los paquetes, cuya información es usada por apt-get source y herramientas similares.
Una vez que hayas establecido tus repositorios, serás capaz de listar e instalar todos sus paquetes junto a los que vienen en los discos de instalación Debian; una vez que hayas añadido el repositorio deberás ejecutar en la consola:
$ sudo apt-get update
Ésto es con el fin de actualizar la base de datos de nuestro APT y así el podrá “decirnos” cuales paquetes disponemos con nuestro nuevo repositorio. Los paquetes serán actualizados cuando ejecutemos en consola.
$ sudo apt-get upgrade
¿Cómo establecer Repositorios?
Existen dos tipos de repositorios: los complejos, que es donde el usuario sólo tiene que especificar la ruta base de el repositorio, la distribución y los componentes que él quiera (APT automáticamente buscará los paquetes correctos para la arquitectura correspondiente, si están disponibles), y los más simples, donde el usuario debe especificar la ruta exacta (aqui APT no hará magia para encontrar cuales de los paquetes son los indicados). El primero es más difícil de establecer, pero es más fácil de utilizar, y siempre debería ser usado para repositorios complejos y/o plataformas cruzadas; el último, es más fácil de establecer, pero sólo debería ser usado para repositorios pequeños o de una sola arquitectura.
Aunque no es realmente correcto, aquí llamaré al primero Repositorios Automáticos y al último Repositorios Triviales.
Repositorios Automáticos
La estructura del directorio de un repositorio automático con las arquitecturas estándares de Debian y sus componentes se asemeja mucho a ésto:
(tu repositorio root)
|
+-dists
|
|-stable
| |-main
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| |-contrib
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| +-non-free
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|
|-testing
| |-main
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| |-contrib
| | |-binary-alpha
| | |-binary-arm
| | |-binary-...
| | +-source
| +-non-free
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|
+-unstable
|-main
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
|-contrib
| |-binary-alpha
| |-binary-arm
| |-binary-...
| +-source
+-non-free
|-binary-alpha
|-binary-arm
|-binary-...
+-source
Los paquetes libres van en el directorio main; los que no son libres van en el directorio non-free y los paquetes libres que dependen de los que no son libres van en el directorio contrib.
Existen también otros directorios poco comunes que son el non-US/main que contienen paquetes que son libres pero que no pueden ser exportados desde un servidor en los Estados Unidos y el directorio non-US/non-free que contiene paquetes que tienen alguna condición de licencia onerosa que restringe su uso o redistribución. No pueden ser exportados de los Estados Unidos porque son paquetes de software de cifrado que no están gestionados por el procedimiento de control de exportación que se usa con los paquetes de main o no pueden ser almacenados en servidores en los Estados Unidos por estar sujetos a problemas de patentes.
Actualmente Debian soporta 11 tipos de arquitecturas; en éste ejemplo se han omitido la mayoría de ellas por el bien de la brevedad. Cada directorio binary-* contiene un fichero Packages.gz y un fichero opcional Release; cada directorio fuente contiene un fichero Sources.gz y también contiene un fichero opcional Release.
Nota que los paquetes no tienen que estar en el mismo directorio como los ficheros índices, porque los ficheros índices contienen las rutas a los paquetes individuales; de hecho, podrían estar ubicados en cualquier lugar en el repositorio. Ésto hace posible poder crear estanques.
Somos libres de crear tantas distribuciones como componentes y llamarlos como queramos; las que se usan en el ejemplo son, justamente las usadas en Debian. Podríamos, por ejemplo, crear las distribuciones current y beta (en vez de stable, unstable y testing, y que los componentes sean foo, bar, baz y qux (en lugar de main, contrib y non-free).
Ya que somos libres de llamar los componentes como queramos, siempre es recomendable usar las distribuciones estándar de Debian, porque son los nombres que los usuarios de Debian esperan.
Repositorios Triviales
Los repositorios triviales, consisten en un directorio raíz y tantos sub-directorios
como deseemos. Como los usuarios tienen que especificar la ruta a la raíz del repositorio
y la ruta relativa entre la raíz y el directorio con los ficheros indices en él, somos libres de hacer lo que queramos (inclusive, colocar todo en la raíz del repositorio; entonces, la ruta relativa simplemente sería /. Se parecen mucho a ésto:
(your repository root)
|
|-binary
+-source
¿Cómo crear ficheros Index?
dpkg-scanpackages es la herramienta con la que podemos generar el fichero Packages y con la herramienta dpkg-scansources creamos los ficheros Sources. Ellos pueden enviar sus salidas a stout; por consiguiente, para generar ficheros comprimidos, podemos usar una cadena de comandos como ésta:
$ dpkg-scanpackages arguments | gzip -9c > Packages.gz
Las dos herramientas trabajan de la misma manera; ambas toman dos argumentos (en realidad son más, pero aquí no hablaremos de eso; puedes leerte las páginas del manual si quieres saber más); el primer argumento es el directorio en cual están los paquetes, y el segundo es el fichero predominante. En general no necesitamos los ficheros predominantes para repositorios simples, pero como éste es un argumento requerido, simplemente lo pasamos a /dev/null. dpkg-scanpackages escanea los paquetes .deb, sin embargo, dpkg-scansources escanea los ficheros .dsc, por lo tanto es necesario colocar los ficheros .orig.gz, .diff.gz y .dsc juntos. Los ficheros .changes no son necesarios. Así que, si tienes un repositorio trivial como el mostrado anteriormente, puedes crear los dos ficheros indice de la siguiente manera:
$ cd my-repository
$ dpkg-scanpackages binary /dev/null | gzip -9c > binary/Packages.gz
$ dpkg-scansources source /dev/null | gzip -9c > source/Sources.gz
Ahora bien, si tienes un repositorio tan complejo como el mostrado en el primer ejemplo, tendrás que escribir algunos scripts para automatizar éste proceso. También puedes usar el argumento pathprefix de las dos herramientas para simplificar un poco la sintaxis.
¿Cómo crear ficheros Release?
Si quieres permitirle a los usuarios de tu repositorio usar el pinning con tu repositorio, entonces deberás incluir un fichero Release en cada directorio que contenga un fichero Index. (Puedes leer más acerca del pinning en el COMO APT). Los ficheros Release son ficheros de texto simple y cortos que tienen una forma muy parecida a la que sigue:
Archive: archivo
Component: componente
Origin: TuCompañia
Label: TuCompañia Debian repositorio
Architecture: arquitectura
- Archive: El nombre de la distribución de Debian. Los paquetes en éste directorio pertenecen a (o estan diseñados para), por ejemplo,
stable,testingounstable. - Component: Aquí van los componentes de los paquetes en el directorio, por ejemplo,
main,non-freeocontrib. - Origin: El nombre de la persona que hizo los paquetes.
- Label: Algunas etiquetas adecuadas para los paquetes de tu repositorio. Usa tu imaginación.
- Architecture: La arquitectura de lo paquetes en éste directorio, como
i386por ejemplo,sparco fuente. Es importante que se establezcanArchitectureyArchivede manera correcta, ya que ellos son más usados para hacerpinning. Los otros, sin embargo, son menos importantes en éste aspecto.
¿Cómo crear estanques?
Con los repositorios automáticos, distribuir los paquetes en los diferentes directorios puede tornarse rápidamente en una bestia indomable, además también se gasta mucho espacio y ancho de banda, y hay demasiados paquetes (como los de la documentación, por ejemplo) los cuales son los mismos para todas las arquitecturas.
En éstos casos, una posible solución es un estanque. Un estanque es un directorio adicional dentro del directorio raíz del repositorio, que contiene todos los paquetes (los binarios para todas las arquitecturas, distribuciones y componente y todas las fuentes). Se pueden evitar muchos problemas, a través de una combinación inteligente de ficheros predominantes (tema que no se toca en éste documento) y de scripts. Un buen ejemplo de un reposotorio “estancado” es el propio repositorio de Debian.
Los estanques sólo son útiles para repositorio grandes. Nunca he hecho uno y no creo que lo haga en un futuro cercano y ésa es la razón por la cual no se explica como hacerlo aquí. Si tu crees que esa sección debería ser añadida siéntete libre de escribir una y contáctame luego.
Herramientas
Existen varias herramientas para automatizar y facilitar la creación de ficheros Debian. A continuación son listados los más importantes:
-
apt-ftparchive: Es la línea de comandos de la herramienta usada para generar los ficheros indice que APT utiliza para accesar a la fuente de una distribución. -
apt-move: Es usado para mover una colección de ficheros paquetes de Debian a un fichero jerárquico como el usado en el fichero oficial Debian. Éste es parte del paqueteapt-utils.
¿Cómo usar los repositorios?
Usar un repositorio es muy sencillo, pero ésto depende de el tipo de repositorio que hayas creado, ya sea binario o de fuentes, automático o trivial. Cada repositorio ocupa una línea en el fichero sources.list. Para usar un repositorio binario solo tenemos que usar deb al principio de la línea y para usar un repositorio de
fuentes, en vez de deb, sólo tenemos que agregrar deb-src. Cada línea tiene la siguiente sintaxis:
deb|deb-src uri distribución [componente1] [componente2] [...]
El URI es el Identificador Universal de Recursos de la raíz del repositorio, como por ejemplo: ftp://ftp.tusitio.com/debian, http://tusitio.com/debian, o, para ficheros locales, file::///home/joe/mi-repositorio-debian/. Donde la barra inclinada es opcional. Para repositorios automáticos, tienes que especificar la distribución y uno o más componentes; la distribución no debe terminar con una inclinada.
A continuación unos ejemplos de repositorios:
deb ftp://sunsite.cnlab-switch.ch/mirror/debian/ unstable main contrib non-free
deb-src ftp://sunsite.cnlab-switch.ch/mirror/debian/ unstable main contrib non-free
deb file:///home/aisotton/rep-exact binary/
deb-src file:///home/aisotton/rep-exact source/
Donde los dos primeros se corresponden con repositorios de tipo Automático y los dos últimos Triviales.
Lista de paquetes en la distribución estable de Debian. Lista de paquetes en la distribución testing de Debian Lista de paquetes en la distribución inestable de Debian
Artículo original Debian Repository HOWTO por Aaron Isotton
El fichero sources.list
La mayoría de los entusiastas de sistemas Linux, tarde o temprano llegan a toparse con ésta interrogante. En una forma bastante general, podríamos definir a éste fichero como la lista de recursos de paquetes que es usada para localizar los ficheros del sistema de distribución de paquetes usado en el sistema. Este fichero de control está ubicado en la carpeta /etc/apt/ de nuestro sistema. El fichero es un simple documento de texto sencillo que puede ser modificado con cualquier editor de textos.
Dentro de éste fichero nos vamos a encontrar una serie de líneas, que no son más que las procedencias de los recursos ubicados en los repositorios que elijamos. Éstas líneas de procedencias tienen una forma general que es: tipo, uri, distribución y complementos.
Entonces, las formas generales de las líneas de procedencias sería así:
deb uri distribución [componente1] [componente2] [...]
deb-src uri distribución [componente1] [componente2] [...]
¿Qué debo saber sobre el sources.list?
Debemos tener en cuenta varios aspectos sobre éste fichero tan importante. Por ejemplo, hay algo que muchos no saben e ignoran, y es que ésta lista de procedencias está diseñada para soportar cualquier número y distintos tipos de procedencias, por supuesto, la demora del proceso de actualización de la base de datos del APT va a ser proporcional al número de procedencias, ya que mientras más procedencias, mayor es la cantidad de paquetes a añadir a la base de datos, y también va a durar un poco más de tiempo, dependiendo de nuestra velocidad de conexión.
El fichero lista una procedencia por línea, con la procedencia de mayor prioridad en la primera línea, como por ejemplo, cuando tenemos los paquetes en discos CD-ROM, entonces ubicamos éste de primero. Como ya mencioné, el formato de cada línea es:
tipo uri distribución complementos
Donde:
-
tipo: Determina el formato de los argumentos, que pueden ser de dos tipos:debydeb-src. El tipodebhace referencia a un típico archivo de Debian de dos niveles, que son distribución y componente, sin embargo, el tipodeb-srchace referencia al código fuente de la distribución y tiene la misma sintaxis que las de tipodeb. Las líneas de tipodeb-srcson necesarias si queremos descargar un índice de los paquetes que tienen el código fuente disponible, entonces de ésta forma obtendremos los códigos originales, más un fichero de control, con extensión.dscy un fichero adicionaldiff.gz, que contiene los cambios necesario para debianizar el código. -
uri: Identificador Universal de Recursos, ésto es, el tipo de recurso de la cual estamos obteniendo nuestros paquetes. Pero ¿Cuáles son los tipos deurique admite nuestra lista de procedencias? A continuación hago mención de las más populares, por así decirlo: *CD-ROM: El cdrom permite a APT usar la unidad de CD-ROM local. Se puede usar el programaapt-cdrompara añadir entradas de un cdrom al ficherosources.listde manera automática, en modo consola.-
FTP: Especifica un servidor FTP como archivo. *HTTP: Especifica un servidor HTTP como archivo. -
FILE: Permite considerar como archivo a cualquier fichero en el sistema de ficheros. Esto es útil para particiones montadas mediante NFS (sistema de ficheros usado para montar particiones de sistemas remotos) y réplicas locales.
-
-
distribución: Aquí especificamos la distribución en la cual estamos trabajando, bien sea Debian, Ubuntu, Kubuntu, Gnoppix,Knoppix y otras, basadas en sistemas Debian GNU/Linux.distribucióntambién puede contener una variable,$(ARCH), que se expandirá en la arquitectura de Debian usada en el sistema (i386,m68k,powerpc,…). Esto permite quesources.listno sea dependiente de la arquitectura del sistema. -
componentes: Los componentes son los tipos de repositorios clasificados según las licencias de los paquetes que contienen. Dentro de los componentes tenemosmain,contribynon-free, para usuarios Debian; sin embargo para usuarios Ubuntu, por ejemplo, también existenuniverse,multiverserestricted. Ahora la decisión de cuales repositorios utilizar, eso va más allá de lo pueda ser explicado acá, ya que eso le concierne a su persona.
Entonces, la forma de una línea de procedencias quedaría algo así:
# deb http://security.ubuntu.com/ubuntu breezy-security main restricted
# deb-src http://security.ubuntu.com/ubuntu breezy-security main restricted
Ahora bien, se preguntarán ¿Por qué el carácter # (almohadilla) al principio de la línea? Bueno, la respuesta es muy simple. Éste caracter se utiliza para indicarle al APT cuando ignorar, por así decirlo, las líneas que contengan dicho caracter al principio, pues lo que hace en realidad es tomarlas como comentarios de lenguaje y simplemente no las interpreta, por lo tanto, si queremos que el APT tome o no en cuenta una línea de procedencias, entonces quitamos o añadimos el caracter, respectivamente.
Nota del autor: Algunas partes de este artículo fueron tomadas del manual de Debian.
Seleccionando el mejor mirror para debian
El día de ayer decidí instalar Debian Sarge en uno de los ordenadores de casa, la instalación base de maravilla, luego procedi a levantar el entorno gráfico de GNOME haciendo uso de aptitude, deje de lado muchas aplicaciones que no voy utilizar extensivamente. Mientras intento solucionar un problemita con el sonido me dispuse a indagar acerca de los repositorios que ofrece Debian.
Leyendo la lista de mirrors en el sitio
oficial de Debian se me ocurrio que debia existir una manera de medir la rapidez
de cada uno de ellos, quizá para muchos esto no es nuevo, para mí si lo es,
recien comienzo con esta
distro, aunque aún
mantengo Ubuntu (no se preocupen mis dos o tres
lectores que seguiré escribiendo acerca de esta excelente distro). Bueno, he
hecho uso de apt-spy, este paquete hace una serie de pruebas sobre los mirrors
de debian, midiendo la su ancho de banda y su latencia.
El paquete apt-spy por defecto reescribe el fichero /etc/apt/sources.list
con los servidores con los resultados más rápidos.
Para instalarlo simplemente hacer lo siguiente:
# aptitude install apt-spy
Leyendo el manual de esta aplicación se puede observar que existe la opción de seleccionar a cuales mirrors se les harán las pruebas de acuerdo a su localización geográfica.
Por ejemplo:
# apt-spy -d stable -a South-America -o mirror.txt
Lo anterior genera un fichero fichero, cuyo nombre será mirror.txt, la opción
-a indica un área, esta opción acepta los valores siguientes: Africa,
Asia, Europe, North-America, Oceania y South-America, aunque es
posible definir sus propias áreas. La opción -d indica la distribución, esta
opcion acepta los valores siguiente: stable, testing o unstable.
He obtenido como resultado lo siguiente:
milmazz@nautilus:~$ cat mirror.txt
deb http://ftp.br.debian.org/debian/ stable main
deb-src http://ftp.br.debian.org/debian/ stable main
deb http://security.debian.org/ stable/updates main
También he realizado una segunda prueba.
# apt-spy -d stable -e 10 -o mirror.txt
Obteniendo como respuesta lo siguiente:
milmazz@nautilus:~$ cat mirror.txt
deb http://ftp.tu-graz.ac.at/mirror/debian/ stable main
deb-src http://ftp.tu-graz.ac.at/mirror/debian/ stable main
deb http://security.debian.org/ stable/updates main
La opción -e es para detener el análisis después de haber completado 10 (o el
número entero indicado como parámetro en dicha opción) servidores.
Me he quedado con los mirrors de Brazil (los mostrados en la primera prueba) por su cercanía geográfica, los del segundo análisis resultan ser de Austria y entran en la categoría de mirrors secundarios.
linux
apt-get detrás de proxy con autenticación NTLM
Por motivos que no vienen al caso discutir en este artículo tuve que instalar Debian GNU/Linux detrás de un proxy que aún utiliza NTLM como medio de autenticación, aunque NTLM ya no es recomendado por Microsoft desde hace años en pro de usar Kerberos.
Una vez instalada la distribución quería utilizar apt-get para actualizarla e
instalar nuevos paquetes, el resultado fue que apt-get no funciona de manera
transparente detrás de un proxy con autenticación NTLM. La solución fue
colocar un proxy interno que esté atento a peticiones en un puerto particular
en el host, el proxy interno se encargará de proveer de manera correcta las
credenciales al proxy externo.
La solución descrita previamente resulta sencilla al utilizar cntlm. En
principio será necesario instalarlo vía dpkg, posteriormente deberá editar los
campos apropiados en el fichero /etc/cntlm.conf
- Username
- Domain
- Password
- Proxy
Seguidamente reinicie el servicio:
# /etc/init.d/cntlm restart
Ahora solo resta configurar apt-get para que utilice nuestro proxy interno,
para ello edite el fichero /etc/apt.conf.d/02proxy
Acquire::http::Proxy "http://127.0.0.1:3128";
NOTA: Se asume que el puerto de escucha de cntlm es el 3128.
Ahora puede hacer uso correcto de apt-get:
# apt-get update
# apt-get upgrade
...
NOTA FINAL: Es evidente que cualquier comando o herramienta que necesite
autenticarse contra el proxy externo deberá configurarlo para que utilice el
proxy interno, lo explicado en este artículo no solo aplica para el comando
apt-get.
Debian GNU/Linux 4.0
Según puede verse en el sitio oficial del Proyecto Debian, en una noticia aparecida el día de hoy, Upcoming Release of Debian GNU/Linux 4.0, se confirma que el próximo mes de diciembre del presente año será la fecha de publicación de la siguiente versión 4.0 de Debian GNU/Linux, cuyo código nombre es “etch”.
Entre las novedades que podremos observar en esta nueva versión se encuentran las siguientes:
- Será la primera versión que ofrezca soporte oficial a la arquitectura AMD64. De manera simultánea, esta versión se publicará para 11 arquitecturas.
- La versión 4.0 ofrecerá la versión 2.6.17 del núcleo linux de manera predeterminada. Además, esta misma versión se utilizará en todas las arquitecturas y a su vez en el instalador.
- Debian GNU/Linux 4.0 presentará la colección de compiladores de GNU versión 4.1.
- Debian GNU/Linux deja de utilizar XFree86 como implementación de X11 (sistema de ventanas X) para darle paso a X.Org.
- Al menejador de paquetes APT seguramente se le añadan algunas mejoras en cuanto a seguridad, admitiendo criptografía modo paranoico y firmas digitales.
Reuniones para eliminar fallos
En la misma noticia podemos enterarnos que el Proyecto Debian está planeando algunas reuniones previas al nuevo lanzamiento en búsqueda de fallos y establecer las debidas correcciones, de esta manera, se ofrecerá al público una versión que presente la mínima cantidad de errores críticos de programación.
Estas reuniones se llevarán a cabo en varias ciudades alrededor del mundo. Por lo tanto, podrá participar el mayor número de personas en la búsqueda y corrección de estos errores de programación.
Si usted está interesado en participar pero no puede reunirse personalmente con los desarrolladores en las distintas ciudades que se describen en BSPMarathon, puede conectarse al canal #debian-bugs en el servidor irc.debian.org y de esta manera participar.
La situación en Venezuela
En mi humilde opinión, considero oportuno que la comunidad Debian Venezuela debe tomar las riendas en este asunto, organizar reuniones para eliminar fallos en nuestra distribución favorita, aprovechando la cercanía del Día Debian para organizar actividades de este tipo. ¿Qué opinan en este sentido?.
Perl y su poderío
Al igual que José, considero que el hilo de discusión Borrar línea X de un archivo es bastante interesante, este hilo fué discutido en la lista de correos técnica l-linux es la la lista de correos para Consultas Técnicas sobre Linux y Software Libre en VELUG del Grupo de Usuarios de Linux de Venezuela (VELUG), el problema planteado por quien inicio el hilo de discusión, José Luis Bazo Villasante, consistía en eliminar un registro completo, en donde se pasara como argumento el primer campo (tal vez el identificador) de dicho registro.
Suponga que el fichero tiene la siguiente estructura:
:(123
... # otros campos
)
:(234
... # otros campos
)
:(456
... # otros campos
)
Se dieron soluciones en lenguajes como Bash y C ¿Con intención de autoflagelación? y ciertas en Perl, éstas últimas son las que llaman mi atención, vamos por partes Diría Jack El Destripador.
José propuso lo siguiente:
#!/usr/bin/perl -n
$deadCount = 7 if ($_ =~ /${ARGV[0]}/);
--$deadCount if ($deadCount);
print unless ($deadCount);El programa debe ejecutarse así:
$ perl script.pl archivo 123
Este programa hace el trabajo, pero al final emitirá un error porque cree que el argumento 123 es otro fichero, y por supuesto, no lo encuenta.
Mi solución fue la siguiente:
perl -ne 'print unless /:\\(123/../\\)/' input.data > output.dataPor supuesto, en este caso solamente estaría eliminando el registro cuyo primer elemento es 123, funciona, pero genera un problema al igual que el hecho por José, se deja una línea de espacio vacía adicional en los registros, cuando el separador de los grupos de datos debe ser una No dos, ni tres, … línea en blanco, tal cual como apunto Ernesto Hernández en una de sus respuestas.
Otro apunte realizado por el profesor Ernesto, fué que las soluciones presentadas hasta el momento de su intervención fué el análisis de fondo que estabamos haciendo, el problema no consistía en procesar cada una de las líneas, el trabajo en realidad consistía en analizar un registro multilínea (o párrafo), en términos más sencillos, cada grupo de datos (registros) está separado por una línea en blanco.
El profesor continuaba su excelente explicación diciendo que el problema se reduce al analizarlo de esta manera en lo siguiente:
…si se cuenta con un lenguaje de programación que está preparado para manejar el concepto de “registro” y puede definir el separador de registro como una línea en blanco, simplemente se trata de ignorar aquellos registros que tengan la expresión regular (X, donde X es la secuencia de dígitos que no nos interesa preservar.
La solución presentada por el profesor Ernesto fue:
perl -000 -i -ne 'print unless /\\(XXX/' archivoEn donde se debe sustituir las XXX por los dígitos cuyo bloque no nos interesa conservar.
De este hilo aprendí cosas nuevas de Perl, en realidad estoy comenzando, muchos pensarán que este código es críptico, por ello considero conveniente aclarar algunas cosas.
Lo críptico de un código no es inherente a un lenguaje particular, eso depende más del cómo se programe.
En este caso particular una sola línea de código nos proporciona mucha información, evidentemente para comprender dicho contenido es necesario leer previamente cierta documentación del lenguaje, pero ¿quien comienza a programar en un lenguaje en particular sin haber leído primero la documentación?, la respuesta parece lógica, ¿cierto?.
La existencia de opciones predefinidas y maneras de ejecutar el interprete de Perl permiten enfocarse únicamente en la resolucion de tareas, cero burocracia.
Un ejemplo de lo mencionado en el párrafo anterior es el siguiente, un bucle lo puedo reducir con la opción de ejecución -n del interprete Perl, simplemente leyendo un poco perlrunman perlrun, perlrun se incluye en la documentación de Perl, en sistemas Debian lo encontramos en el paquete perl-doc, para instalar simplemente hacer ejecutar el comando aptitude install perl-doc como superusuario nos enteramos del asunto, eso quiere decir que podemos reducir a una simple opción de ejecución del interprete de Perl todo esto:
#!/usr/bin/perl
while(<>){
#...
}¿Qué es ese operador que parece un “platillo volador”, según nos conto José Luis Rey, el profesor Ernesto Hernández le llama así de manera informal (null filehandle)?, bueno, lea perlop, en especial la sección I/O Operators.
La opción -i me permite editar (reescribir) in situ el fichero que vamos a procesar, en el caso de no añadir una extensión no se realizara un respaldo del fichero, el fichero original se sobreescribe. Mayor detalle en perlrun.
Lo que si no sabía hasta ahora, es lo explicado por el profesor acerca de los párrafos (registros multilínea) en Unix, la opción -0 tiene un valor especial, el cual es 00, si este valor es suministrado hace que Perl entre en “modo párrafo”, en pocas palabras, se reconoce una línea en blanco como el separador de los registros.
El resto del código es solo manejo de una sencilla expresión regular, se asume que el lector conoce algo del tema, solo indica el registro que queremos ignorar.
Así que podemos concluir lo siguiente, Perl no es críptico, asumiendo que el programador ha leido suficiente documentación acerca del lenguaje en cuestión, evitamos la burocracia y atendemos el problema de raíz en el menor tiempo posible.
La solución que propone Perl con el lema Hay más de una manera de hacerlo, es ofrecerle al programador libertad en su forma de expresarse, ¿acaso todos hablamos el mismo idioma?, ¿acaso debemos seguir las malas prácticas que intenta difundir el maligno Java?, coartar el pensar del programador y obligarlo a hacer las cosas al estilo Java, ¿dónde queda la imaginación? De hecho, se dice que, un programador experto en Java está muy cerca de convertirse en un autómata, ¿paso a ser un lujo?.
A todos los que lo deseen, les invito a participar en la lista de correos técnica (l-linux) del Grupo de Usuarios de Linux de Venezuela (VELUG), les recomiendo leer detenidamente las normas de uso antes de inscribirse en la lista.
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
Lavado de cara para Planeta Linux
Desde las 2:00 p.m. (hora local) del día de hoy, con la asistencia del compañero Damog, hemos ido actualizando el layout de Planeta Linux, aún falta mucho trabajo por hacer, pero al menos ya hemos dado los primeros pasos.
Cualquier opinión, crítica, sugerencia, comentario agradecemos enviar un correo electrónico a la lista de correos de Planeta Linux. *[p.m.]: Post meridiem
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
Vulnerabilidad en el kernel Linux de ubuntu
Este problema de seguridad únicamente afecta a la distribución Ubuntu 5.10, Breezy Badger.
Los paquetes afectados son los siguientes:
linux-image-2.6.12-10-386linux-image-2.6.12-10-686linux-image-2.6.12-10-686-smplinux-image-2.6.12-10-amd64-genericlinux-image-2.6.12-10-amd64-k8linux-image-2.6.12-10-amd64-k8-smplinux-image-2.6.12-10-amd64-xeonlinux-image-2.6.12-10-iseries-smplinux-image-2.6.12-10-itaniumlinux-image-2.6.12-10-itanium-smplinux-image-2.6.12-10-k7linux-image-2.6.12-10-k7-smplinux-image-2.6.12-10-mckinleylinux-image-2.6.12-10-mckinley-smplinux-image-2.6.12-10-powerpclinux-image-2.6.12-10-powerpc-smplinux-image-2.6.12-10-powerpc64-smplinux-patch-ubuntu-2.6.12
El problema puede ser solucionado al actualizar los paquetes afectados a la versión 2.6.12-10.28. Posterior al proceso de actualización debe reiniciar el sistema para que los cambios logren surtir efecto.
Puede encontrar mayor detalle acerca de esta información en el anuncio Linux kernel vulnerability hecho por Martin Pitt a la lista de correos de avisos de seguridad en Ubuntu.
Planeta Linux
Hace tiempo que no revisaba algunas de las estadísticas del sitio, me he percatado que han llegado algunos enlaces desde Planeta Linux Venezuela. El principal objetivo de este sitio es:
Planeta Linux es un pequeño proyecto que pretende fomentar la comunicación e intercambio sencillo de información sobre cualquier usuario de GNU/Linux o software libre, en Venezuela. Con esta breve comunicación, podremos conformar una comunidad mucho má sólida, unificada e integral.
Lo anterior también es extensible para aquellas personas mexicanas, puesto que existe un Planeta Linux México.
¿Desea colaborar con el proyecto?
El proceso de registro es muy sencillo, solamente debes enviar un correo a lista de correos [email protected], si desea suscribirse a dicha lista solamente rellene los datos solicitados página de información de la lista de correos de Planeta Linux.
Para su admision usted debe suministrar los siguientes datos:
- Nombre completo
- Lugar de residencia
- URI del feed RSS/Atom
Opcionalmente puede enviar su Hackergotchi, imagen de un escritor que es utilizada como ícono para identificar al autor de un feed dado dentro de un agregador de blogs, ésta no debe exceder un ancho de 95 pixels y un alto de 95 pixels.
Conociendo un poco más acerca del proyecto
Me ha interesado mucho esta iniciativa, así que no dude en ponerme en contacto con David Moreno Garza (a.k.a. damog), él cual me ha contestado muy amablemente. En las siguientes líneas expongo nuestro intercambio de correos electrónicos.
- MilMazz: Hola David, en realidad no tengo el placer de conocerte personalmente, pero he notado recientemente algunos enlaces entrantes desde el Planeta Linux Venezuela, no se quien me dio de alta, se agradece, así que gracias.
- Damog: Hola Milton, no, al parecer no nos conocemos. Yo te di de alta en el rol debido a que José Parrella, a.k.a bureado, me pasó tu nombre y feed.
- MilMazz: El motivo de este mensaje es para pedirte un poco de informacion respecto al proyecto, para publicar un artículo en mi blog y así colaborar con la difusión de esta interesante idea.
- Damog: ¡Muchas gracias! Así es como el proyecto va ganando adeptos y más gente se va uniendo y leyendo el contenido de Planeta Linux.
- MilMazz: Espero no te molesten las siguientes preguntas, tomalo a manera de entrevista :)
- Damog: Desde luego que no, ¡bienvenidas! Antes que cualquier cosa, espero que no te importe que reenvíe este correo a la lista de Planeta Linux.
- MilMazz: ¿Quién o quienes se plantearon en principio la idea de crear Planeta Linux?, ¿quién lo llevaron a cabo?
- Damog: Debido al boom que han tenido los blogs entre usuarios y desarrolladores de software libre en el mundo, se ve la necesidad de crear nuevas herramientas para «monitorear» los contenidos dependiendo de los gustos de cada uno de los usuarios. Wieland Kublun, un mexicano radicado en Guadalajara, en el estado de Jalisco, en el occidente de México, alguna vez me comentó que estaría bien tener una especie de «planeta», como los que se han dado a conocer por proyectos grandes como Planet Debian o Planet GNOME. Creí que la idea era estupenda y empezamos a poner el agregador en marcha y añadiendo a nuestros conocidos al rol.
Otro factor que ha influído mucho en la gran proliferación de Planeta Linux es Jaws. Jaws es un proyecto, iniciado por Jonathan Hernández, radicado en Chihuahua, en el norte de México, de software libre para construir fácilmente un blog. El proyecto Jaws ha avanzado ya muchísimo, pues el software desarollado es altamente útil, funcional y bastante bonito. Por ende, muchos usuarios mexicanos empezaron a montar sus blogs en él y la mancha de usuarios blogueadores mexicanos creció mucho.
- MilMazz: Tengo entendido que el primer planeta de la “serie” fue el Planeta Linux Mexico, ¿desde cuando está en línea?
- Damog: Así es, fue el primero. Ha estado en línea desde octubre de 2004. Antes utilizábamos el dominio planetalinux.com.mx, pero recientemente abrimos el 2006 con el dominio, más genérico y permitible de expansión, planetalinux.org.
- MilMazz: ¿Por qué decidiste incluir a Venezuela como parte del Planeta Linux?, ¿alguna persona te pidio que lo hicieras?
- Damog: No. Personalmente tengo mucha relación con Venezuela, pues mi novia es de allá y tengo bastantes amigos, en el mundillo del software libre, allá. Quise lanzarlo por que empecé a conocer a gente que tenía un blog y llegó a un punto donde consideré pertinente lanzarlo, y donde la gente se interesaría por él. Mucha gente, hasta donde tengo entendido, ni siquiera sabe que está en el planeta. Como tú mismo, a muchas personas se han agregado teniendo conocimientos de ellos por terceras partes. Sin embargo, la forma de ver crecer un proyectito así es precisamente de boca en boca, de blog en blog.
- MilMazz: ¿Tienes pensado en el futuro incluir a mas paises?, si es así, ¿cuáles serían?
- Damog: Sí, la idea también era esa al iniciar con el dominio que usamos actualmente. Al principio creí que lo ideal sería empezar con México y Venezuela por razones ya explicadas, y además con Estados Unidos (sindicando a la gente latina que radica en ese país y que bloguea), usando la dirección us.planetalinux.org. Sin embargo, aún no se ha juntado suficiente gente para llevar a cabo tal subproyecto. En general cualquier país latinoamericano podría entrar mientras se junte suficiente gente y vaya creciendo como han ido creciendo los correspondientes a México y Venezuela. Creo que sería interesante seguirse luego con Brasil, donde hay una enorme actividad de software libre, o incluso en Argentina. Sin embargo, esto depende de la gente: Hace falta todavía escribir mucho contenido, hace falta escribir una especie de FAQ donde se explique qué pueden hacer si alguien quiere iniciar una instancia de Planeta Linux en un país donde no exista, hace falta hacer ese tipo de cosas y generar esos contenidos.
- MilMazz: Estaba por documentarme acerca de los lineamientos, al parecer el enlace de los lineamientos de Planeta Linux está roto por ahora, ¿cuáles serían los lineamientos que debe seguir un miembro del Planeta Linux?
- Damog: Bueno, como te digo, uno más de los contenidos inconclusos. Básicamente, los lineamientos establecerán algunos reglas o consejos, como que deberán hablar de Linux y Software Libre con cierta regularidad en su blog, que su feed debe ser válido, etc. Ese tipo de cosas.
- MilMazz: ¿Quienes pueden participar en el Planeta Linux?
- Damog: Cualquier persona que lleve un blog y toque periódicamente temas sobre Linux o Software Libre.
- MilMazz: ¿Deseas agregar algo más?
- Damog: Pues si alguien se quiere unir, es más que bienvenido. Simplemente escriban a la lista: [email protected] o suscríbanse.
Antes de culminar, quisiera agradecerle públicamente a José Parella por la sugerencia hecha a David Moreno Garza.
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
Cowbell: Organiza tu música
Cowbell, es una aplicación que te permite organizar tus compilaciones musicales de una manera fácil y divertida, ya no tienes que aburrirte por horas al intentar organizar tus colección musical manualmente.
Una de las cosas que me han agradado de este programa es que aparte de poder editar las etiquetas manualmentede en una interfaz bastante agradable y sencilla, también puedes obtener toda la información necesaria a través de Amazon Web Services, lo anterior incluye: Número, Título, Año, Estilo, Portada y demás información relacionada con las canciones. Al utilizar este servicio cuentas con una amplia bases de datos, lo anterior en realidad permite ahorrar mucho tiempo.
Dentro de las preferencias de este programa nos encontraremos con opciones que nos permitirán renombrar ficheros de acuerdo a un patrón, el cual lo podemos generar al combinar cualquiera de las siguientes palabras claves.
- Artist
- Album
- Title
- Track
- Genre
- Year
Las palabras claves anteriores se explican por sí solas. Simplemente escoge el patrón que más se ajuste a tus necesidades. Entre otras de las características de este programa, cabe mencionar la posibilidad de generar un fichero de lista de reproducción del álbum.
¿Tienes una larga colección de música cuyas etiquetas debes arreglar?, no te preocupes, Cowbell también puedes usar desde la línea de comandos, la manera de invocar el comando es la siguiente:
$ cowbell --batch /ruta/a/tu/musica
Donde evidentemente debes modificar el directorio /ruta/a/tu/musica de acuerdo a tus necesidades.
Para instalar esta aplicación en ubuntu debes tener activo el repositorio universe en tu fichero /etc/apt/sources.list. Una vez actualizada la lista de repositorios, puedes instalar Cowbell de la siguiente manera:
$ sudo aptitude cowbell
Integridad del CD de Ubuntu
Recientemente un amigo (de ahora en adelante lo llamaré pepito) al que le regalé un par de CD’s de Ubuntu, me preguntó después de unos días lo siguiente: Milton, ¿cómo puedo verificar la integridad del CD de instalación de Ubuntu?.
En primer lugar, estaba muy contento porque pepito deseaba en realidad migrar a GNU/Linux. Pero la idea de este artículo no es hablarles de pepito, sino describir lo más detalladamente posible la respuesta que le dí.
Aprovechar las opciones que nos brinda el CD de instalación
El mismo CD de instalación de ubuntu nos brinda una opción que nos permite verificar la integridad del disco, para ello debemos realizar lo siguiente:
- Colocar el CD de instalación de Ubuntu en la unidad de CD-ROM correspondiente, seguidamente proceder a reiniciar, recuerde que en la configuración de la BIOS debe tener como primera opción de arranque la unidad de CD-ROM que corresponda en su caso.
- Al terminar la carga del CD usted podrá apreciar un mensaje de bienvenida similar al siguiente:
The default installation is suitable for most desktop or laptops systems. Press F1 for help and advanced installation options.
To install only the base system, type “server” then ENTER. For the default installation, press ENTER.
boot:_
Lo anterior, traducido a nuestro idioma sería similar a:
La instalación por defecto es conveniente para la mayoría de los sistemas de escritorio o portátiles. Presione F1 para ayuda y opciones de instalación avanzadas.
Para instalar solo el sistema base, escriba “server” luego ENTER. Para la instalación por defecto, presione ENTER.
- Para este artículo, se realizará el modo de instalación por defecto, lo anterior quiere decir que solamente debemos presionar la tecla ENTER, enseguida observaremos la carga del kernel.
- Desde el cuadro de dialogo Choose Language, primero en aparecer, presionaremos la tecla Tab y seguidamente debemos seleccionar la opción Go back
- El paso anterior nos llevará al menú principal de la instalación de Ubuntu (Ubuntu installer main menu), una vez ubicados acá, simplemente debemos seleccionar la opción Check the CD-ROM(s) Integrity.
- Al finalizar el paso anterior nos llevará a un cuadro de dialogo de confirmación, pero antes podremos notar una pequeña advertencia:
Warning: this check depends on your hardware and may take some time.
Check CD-ROM integrity?
Lo anterior, traducido a nuestro idioma sería similar a:
Advertencia: Esta revisión depende de su hardware y puede tomar cierto tiempo.
Revisar la integridad del CD-ROM?
A la pregunta anterior respondemos Sí
- Si lo prefiere, salga de su casa, tome un poco de sol y regrese ;)
- Si el CD-ROM no tiene fallo alguno, podrá observar un mensaje al final de la revisión similar al siguiente:
Integrity test successful the CD-ROM. Integrity test was successful.
The CD-ROM is valid
Si la revisión de la integridad del CD-ROM es satisfactoría, puede continuar con el proceso de instalación.
Suerte y bienvenido al mundo GNU/Linux ;)
Ubuntu (Dapper Drake) Flight 3
La tercera versión alpha de Ubuntu 6.04 (Dapper Drake), continúa mostrando mejoras e incluye nuevo software.
Las mejoras incluyen una actualización en el tema, el cual desde la segunda versión alpha es manejado por gfxboot.
Ademas se incluye X Window System versión X11R7, GNOME 2.13.4, también se observan mejoras y simplificación de los menús, algunas nuevas aplicaciones como XChat-GNOME, un LiveCD más rápido y que permite almacenar nuestras configuraciones.
También se notan algunas mejoras estéticas en el cuadro de dialógo de cierre de sesión.
En cuanto a la mejora y simplificación de los menús, la idea básicamente es obviar aquellas opciones que pueden llegar a ser confusas para los usuarios, también se evita la duplicación de opciones, esto permite que exista un solo punto para acceder a cada función del sistema, mejorando de esta manera la usabilidad en nuestro escritorio favorito.
Se ha creado un nuevo dialógo que indica cuando es necesario reiniciar el sistema, esto sucede cuando se realizan importantes actualizaciones al sistema, en donde es recomendable reiniciar el sistema para que dichas actualizaciones surtan efecto.
¿Qué mejoras incluye la versión LiveCD?
Quién haya usado alguna vez en su vida un LiveCD puede haberse percatado que éstos presentan ciertos problemas, uno de ellos es la lentitud en el tiempo de carga del sistema, en este sentido se han realizado algunas mejoras en el cargador utilizado en el arranque, el tiempo de carga se ha reducido aproximadamente de unos 368 segundos a 231 segundos, esta mejora es bastante buena, aunque se espera mejorar aún mas este tiempo de carga del LiveCD.
Otro de los problemas encontrados en los LiveCD, es que el manejo de los datos no es persistente, esta nueva versión incluye una mejora que permite recordar las configuraciones, esto quiere decir que la siguiente vez que usted utilice el LiveCD dichas configuraciones serán recordadas. Esto es posible ya que el LiveCD permite guardar sus cambios en un dispositivo externo (al CD) como por ejemplo un llavero usb. Por lo tanto, si usted especifica el parámetro persistent cuando usted esta iniciando el LiveCD, éste buscará el dispositivo externo que mantiene las configuraciones que usted ha almacenado. Si desea conocer más acerca de esta nueva funcionalidad en el LiveCD vea el documento LiveCDPersistence.
Si usted desea descargar esta tercera versión alpha de Ubuntu 6.04, puede hacerlo en Ubuntu (Dapper Drake) Flight CD 3.
Mayor detalle acerca de las nuevas características que presenta esta nueva versión en el documento DapperFlight3.
Nota: Esta versión no es recomendable instalarla en entornos de producción, la versión estable de Dapper Drake se espera para Abril de este mismo año.
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
Vulnerabilidad en Apache
Según un anuncio hecho el día de hoy por Adam Conrad a la lista de seguridad de ubuntu existe una vulnerabilidad que podría permitirle a una página web maligna (o un correo electrónico maligno en HTML) utilizar técnicas de Cross Site Scripting en Apache. Esta vulnerabilidad afecta a las versiones: Ubuntu 4.10 (Warty Warthog), Ubuntu 5.04 (Hoary Hedgehog) y Ubuntu 5.10 (Breezy Badger).
De manera adicional, Hartmut Keil descubre una vulnerabilidad en el módulo SSL (mod_ssl), que permitiría realizar una denegación de servicio (DoS), lo cual pone en riesgo la integridad del servidor. Esta última vulnerabilidad solo afecta a apache2, siempre y cuando esté usando la implementación “worker” (apache2-mpm-worker).
Los paquetes afectados son los siguientes:
apache-commonapache2-commonapache2-mpm-worker
Los problemas mencionados previamente pueden ser corregidos al actualizar los paquetes mencionados.
programming
Oban: Testing your Workers and Configuration
In this article, I will continue talking about Oban, but I’ll focus on how to test your workers and, also, your configuration.
Oban: job processing library for Elixir
After working for years on different organizations, one common theme is scheduling background jobs. In this article, I’ll share my experience with Oban, an open-source job processing package for Elixir. I’ll also cover some features, like real-time monitoring with Oban Web and complex workflow management with Oban Pro.
Improve the codebase of an acquired product
In this article I’ll share my experience improving the codebase of an acquired product, this couldn’t be possible without the help of a fantastic team. Before diving into the initial diagnostic and strategies that we took to tackle technical debt, I’ll share some background around the acquisition. Let’s start.
Elixir’s MIME library review
Elixir’s MIME is a read-only and immutable library that embeds the MIME type database, so, users can map MIME (Multipurpose Internet Mail Extensions) types to extensions and vice-versa. It’s a really compact project and includes nice features, which I’ll try to explain in case you’re not familiar with the library. Then, I’ll focus on MIME’s internals or how was built, and also how MIME illustrates in an elegant way so many features of Elixir itself.
Follow-up: Function currying in Elixir
NOTE: This article is a follow-up examination after the blog post Function currying in Elixir by @stormpat
In his article, Patrik Storm, shows how to implement function currying in Elixir, which could be really neat in some situations. For those who haven’t read Patrik’s post, first, let us clarify what is function currying.
Currying is the process of transforming a function that takes multiple arguments (arity) into a function that takes only one argument and returns another function if any arguments are still required. When the last required argument is given, the function automatically executes and computes the result.
Asynchronous Tasks with Elixir
One of my first contributions into ExDoc, the tool used to produce HTML documentation for Elixir projects, was to improve the documentation build process performance. My first approach for this was to build each module page concurrently, manually sending and receiving messages between processes. Then, as you can see in the Pull Request details, Eric Meadows-Jönsson pointed out that I should look at the Task module. In this article, I’ll try to show you the path that I followed to do that contribution.
How to document your Javascript code
Someone that knows something about Java probably knows about JavaDoc. If you know something about Python you probably document your code following the rules defined for Sphinx (Sphinx uses reStructuredText as its markup language). Or in C, you follow the rules defined for Doxygen (Doxygen also supports other programming languages such as Objective-C, Java, C#, PHP, etc.). But, what happens when we are coding in JavaScript? How can we document our source code?
As a developer that interacts with other members of a team, the need to document all your intentions must become a habit. If you follow some basic rules and stick to them you can gain benefits like the automatic generation of documentation in formats like HTML, PDF, and so on.
I must confess that I’m relatively new to JavaScript, but one of the first things that I implement is the source code documentation. I’ve been using JSDoc for documenting all my JavaScript code, it’s easy, and you only need to follow a short set of rules.
/**
* @file Working with Tags
* @author Milton Mazzarri <[email protected]>
* @version 0.1
*/
var Tag = $(function(){
/**
* The Tag definition.
*
* @param {String} id - The ID of the Tag.
* @param {String} description - Concise description of the tag.
* @param {Number} min - Minimum value accepted for trends.
* @param {Number} max - Maximum value accepted for trends.
* @param {Object} plc - The ID of the {@link PLC} object where this tag belongs.
*/
var Tag = function(id, description, min, max, plc) {
id = id;
description = description;
trend_min = min;
trend_max = max;
plc = plc;
};
return {
/**
* Get the current value of the tag.
*
* @see [Example]{@link http://example.com}
* @returns {Number} The current value of the tag.
*/
getValue: function() {
return Math.random;
}
};
}());
In the previous example, I have documented the index of the file, showing the author and version, you can also include other things such as a copyright and license note. I have also documented the class definition including parameters and methods specifying the name, and type with a concise description.
After you process your source code with JSDoc the result looks like the following:

In the previous image you see the documentation in HTML format, also you see a table that displays the parameters with appropriate links to your source code, and finally, JSDoc implements a very nice style to your document.
If you need further details I recommend you check out the JSDoc documentation.
Grunt: The Javascript Task Manager
When you play the Web Developer role, sometimes you may have to endure some repetitive tasks like minification, unit testing, compilation, linting, beautify or unpack Javascript code and so on. To solve this problems, and in the meantime, try to keep your mental health in a good shape, you desperately need to find a way to automate this tasks. Grunt offers you an easy way to accomplish this kind of automation.
The DRY principle
The DRY (Don’t Repeat Yourself) principle it basically consist in the following:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
That said, it’s almost clear that the DRY principle is against the code duplication, something that in the long-term affect the maintenance phase, it doesn’t facilitate the improvement or code refactoring and, in some cases, it can generate some contradictions, among other problems.
jQuery best practices
After some time working with C programming language in a *NIX like operating system, recently I came back again to Web Programming, mostly working with HTML, CSS and JavaScript in the client-side and other technologies in the backend area.
The current project I’ve been working on, heavily relies on jQuery and Highcharts/Highstock libraries, I must confess that at the beginning of the project my skills in the client-side were more than rusted, so, I began reading a lot of articles about new techniques and good practices to catch up very quickly, in the meantime, I start taking some notes about “best practices”1 that promotes a better use of jQuery2
Elixir: Primeras impresiones
Elixir: Primeras impresiones
NOTA: Este artículo originalmente lo escribí para La Cara Oscura del Software, un blog colectivo dedicado a desarrollo de software.
 Durante el segundo hangout de @rubyVE escuché
a @edgar comentar sobre Elixir y en verdad
me llamó la atención lo que indicaba, siempre me inquieta conocer al menos un
poco sobre otros lenguajes de programación, siempre terminas aprendiendo algo,
una buena lección es seguro, sobre todo por aquello de la filosofía del
programador pragmático y la necesidad de invertir regularmente en tu portafolio
de conocimientos.
Durante el segundo hangout de @rubyVE escuché
a @edgar comentar sobre Elixir y en verdad
me llamó la atención lo que indicaba, siempre me inquieta conocer al menos un
poco sobre otros lenguajes de programación, siempre terminas aprendiendo algo,
una buena lección es seguro, sobre todo por aquello de la filosofía del
programador pragmático y la necesidad de invertir regularmente en tu portafolio
de conocimientos.
Ahora bien, después de leer un artículo de Joe Armstrong, padre de Erlang, en donde afirmaba que tras una semana de haber usado Elixir estaba completamente entusiasmado por lo visto. Con esto era claro que se estaba presentando para mi una gran oportunidad para retomar la programación funcional con Elixir, inicié con Haskell en la Universidad en la materia de Compiladores y la verdad es que no lo he vuelto a tocar.
José Valim es un brasileño, parte del equipo core committer de Rails. Después de sufrir RSI, en su afán por encontrar qué hacer en su reposo se puso a leer el libro: Seven Languages in Seven Weeks: A Pragmatic Guide to Learning Programming Languages y allí conoció Erlang y su EVM (Erlang Virtual Machine), cierto tiempo después creo este nuevo lenguaje llamado Elixir, en donde uno de sus mayores activos es la EVM, tanto es así que de hecho no existe un costo de conversión al invocar Erlang desde Elixir y viceversa. Todo esto es seguramente es la respuesta de Valim a las limitantes físicas actuales en los procesadores o lo que se conoce también como: “se nos acabó el almuerzo gratis”, sobre todo ahora con recientes anuncios de Parallella y de Intel con los procesadores Xeon Phi.
A pesar de la horrible sintaxis de Erlang, o al menos después de leer a Damien Katz, autor original de CouchDB en What Sucks About Erlang y a Tony Arcieri, autor de Reia (otro lenguaje basado en BEAM), en su artículo The Trouble with Erlang (or Erlang is a ghetto) es fácil concluir que la sintaxis no es la más amenas de todas. Sin embargo, las inmensas habilidades que brinda Erlang para establecer sistemas concurrentes (distribuidos, tolerantes a fallas y code swapping) ha permitido llegar a mantener hasta 2 millones de conexiones TCP en un solo nodo. Es por ello que compañías como Whatsapp, Facebook, Amazon, Ericsson, Motorola, Basho (Riak) y Heroku por mencionar algunas están usando Erlang para desarrollar sus sistemas.
Rápidamente quisiera compartirles mi felicidad por haber iniciado a explorar este lenguaje. Para iniciar tu proyecto tienes un magnífico utilitario llamado mix (inspirado en Leiningen de Clojure). Mix también permite manejar las tareas más comunes como administración de dependencias de tu proyecto, compilación, ejecución de pruebas, despliegue (pronto), entre otras. Incluso puedes programar nuevas tareas, simplemente asombroso, en fin, vamos a jugar:
$ mix help
mix # Run the default task (current: mix run)
mix archive # Archive this project into a .ez file
mix clean # Clean generated application files
mix cmd # Executes the given command
mix compile # Compile source files
mix deps # List dependencies and their status
mix deps.clean # Remove the given dependencies' files
mix deps.compile # Compile dependencies
mix deps.get # Get all out of date dependencies
mix deps.unlock # Unlock the given dependencies
mix deps.update # Update the given dependencies
mix do # Executes the tasks separated by comma
mix escriptize # Generates an escript for the project
mix help # Print help information for tasks
mix local # List local tasks
mix local.install # Install a task or an archive locally
mix local.rebar # Install rebar locally
mix local.uninstall # Uninstall local tasks or archives
mix new # Creates a new Elixir project
mix run # Run the given file or expression
mix test # Run a project's tests
Procedamos con la creación de un nuevo proyecto:
$ mix new demo
* creating README.md
* creating .gitignore
* creating mix.exs
* creating lib
* creating lib/demo.ex
* creating test
* creating test/test_helper.exs
* creating test/demo_test.exs
Your mix project was created with success.
You can use mix to compile it, test it, and more:
cd demo
mix compile
mix test
Run `mix help` for more information.
La estructura del proyecto creado por mix es como sigue:
$ cd demo
$ tree
.
|-- README.md
|-- lib
| `-- demo.ex
|-- mix.exs
`-- test
|-- demo_test.exs
`-- test_helper.exs
2 directories, 5 files
En mix.exs encontramos la configuración del proyecto así como sus dependencias
en caso de aplicar, en lib/demo.ex ubicamos la definición del módulo que nos
ayudará a estructurar posteriormente nuestro código, en test/test_demo.exs
encontramos un esqueleto base para los casos de pruebas asociadas al modulo.
Finalmente en test/test_helper.exs radica inicialmente el arranque del
framework ExUnit.
Creemos un par de pruebas sencillas primero:
$ vim test/demo_test.exs
defmodule DemoTest do
use ExUnit.Case
test "factorial base case" do
assert Demo.factorial(0) == 1
end
test "factorial general case" do
assert Demo.factorial(10) == 3628800
end
test "map factorial" do
assert Demo.map([6, 8, 10], fn(n) -> Demo.factorial(n) end) == [720, 40320, 3628800]
end
end
Evidentemente al hacer “mix test” todas las pruebas fallaran, vamos a comenzar a subsanar eso:
$ vim lib/demo.ex
defmodule Demo do
def factorial(0) do
1
end
def factorial(n) when n > 0 do
n * factorial(n - 1)
end
end
En el par de bloques de código mostrado previamente se cubren los dos casos posibles del factorial.
Volvamos a correr las pruebas:
$ mix test
..
1) test map factorial (DemoTest)
** (UndefinedFunctionError) undefined function: Demo.map/2
stacktrace:
Demo.map([6, 8, 10], #Function<0.60019678 in DemoTest.test map factorial/1>)
test/demo_test.exs:13: DemoTest."test map factorial"/1
Finished in 0.04 seconds (0.04s on load, 0.00s on tests)
3 tests, 1 failures
De las 3 pruebas programadas hemos superado dos, nada mal, continuemos, volvamos a editar nuestro módulo:
$ vim lib/demo.ex
defmodule Demo do
def factorial(0) do
1
end
def factorial(n) when n > 0 do
n * factorial(n - 1)
end
def map([], _func) do
[]
end
def map([head|tail], func) do
[func.(head) | map(tail, func)]
end
end
En esta última versión se ha agregado la función map, básicamente esta función
recibe una colección de datos y una función que se aplicará sobre cada uno de
los elementos de la colección, para nuestros efectos prácticos la función que
será pasada a map será el factorial.
Como nota adicional, los bloques de código vistos en el ejemplo anterior prefiero expresarlos de manera sucinta así, cuestión que también es posible en Elixir:
$ vim lib/demo.ex
defmodule Demo do
@moduledoc """
Demo module documentation, Python *docstrings* inspired.
"""
def factorial(0), do: 1
def factorial(n) when n > 0, do: n * factorial(n - 1)
def map([], _func), do: []
def map([head|tail], func), do: [func.(head) | map(tail, func)]
end
Acá se pueden apreciar conceptos como pattern matching, guard clauses, manejo de listas y docstrings (inspirado en Python). Atención, los docstrings soportan MarkDown, junto a ExDoc es posible producir sitios estáticos que extraen los docstrings a partir del código fuente.
Comprobemos los casos desde la consola interactiva iex antes de pasar de nuevo
al caso automatizado:
$ iex lib/demo.ex
Erlang R16B01 (erts-5.10.2) [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (0.10.2-dev) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> import Demo
nil
iex(2)> h(Demo)
# Demo
Demo module documentation, Python *docstrings* inspired.
iex(3)> Demo.factorial(10)
3628800
iex(4)> Demo.map([6, 8, 10], Demo.factorial(&1))
[720, 40320, 3628800]
Lo previo es una consola interactiva, vimos la documentación e hicimos unas pruebas manuales.
Seguro notaron que al final del ejemplo previo, al hacer el map he cambiado la
forma en la que invoco a la función anónima la cual originalmente fue definida
en las pruebas como fn(n) -> Demo.factorial(n) end, solamente he recurrido a
un modo que permite Elixir y otros lenguajes funcionales para expresar este tipo
de funciones de manera concisa, se le conoce como Partials.
Ahora corramos las pruebas automatizadas de nuevo:
$ mix test
Compiled lib/demo.ex
Generated demo.app
...
Finished in 0.04 seconds (0.04s on load, 0.00s on tests)
3 tests, 0 failures
Con eso hemos pasado los casos de pruebas.
En este caso particular, prefiero que las pruebas sean autocontenidas en el módulo, además, no recurrimos a fixtures ni nada por el estilo, así que vamos a cambiar el código para que soporte doctest
$ vim lib/demo.ex
defmodule Demo do
@moduledoc """
Demo module documentation, Python *docstrings* inspired.
"""
@doc """
Some examples
iex> Demo.factorial(0)
1
iex> Demo.factorial(10)
3628800
iex> Demo.map([6, 8, 10], Demo.factorial(&1))
[720, 40320, 3628800]
"""
def factorial(0), do: 1
def factorial(n) when n > 0, do: n * factorial(n - 1)
def map([], _func), do: []
def map([head|tail], func), do: [func.(head) | map(tail, func)]
end
Dado lo anterior ya no es necesario tener las pruebas aparte, por lo que reduzco:
$ vim test/demo_test.exs
defmodule DemoTest do
use ExUnit.Case
doctest Demo
end
Comprobamos la equivalencia:
$ mix test
...
Finished in 0.06 seconds (0.06s on load, 0.00s on tests)
3 tests, 0 failures
Simplemente hermoso, cabe resaltar que lo mencionado es solo rascar un poco la superficie de Elixir :-)
Ah, por cierto, ya para finalizar, José Valim está apuntando el desarrollo de Elixir y Dynamo (framework) a la Web, lo ha dejado claro, por eso he visto que algunos programadores Rails están “echándole un ojo” a Elixir, al menos eso es lo que concluyo de los elixir-issues en Github, el reciente screencast de Peepcode (vale la pena comprarlo) y los libros que se avecinan de Dave Thomas y Simon St. Laurent.
Quizá en una nueva oportunidad hablemos de Macros, pase de mensajes entre
procesos, Protocolos (inspirados en Clojure
protocols), Reducers (inspirados también en
Clojure
Reducers),
HashDict, el hermoso y *nix like operador pipeline (|>), mejorar nuestra
implementación de la función map para que haga los cálculos de manera
concurrente, entre otros.
Espero hayan disfrutado la lectura, que este artículo sirva de abreboca y les anime a probar Elixir.
Enviando correos con Perl
Regularmente los administradores de sistemas requieren notificar, vía correo electrónico, a sus usuarios de ciertos cambios o nuevos servicios disponibles. La experiencia me ha indicado que el usuario aprecia más un correo personalizado que uno general. Sin embargo, lograr lo primero de manera manual es bastante tedioso e ineficaz. Por lo tanto, es lógico pensar en la posibilidad de automatizar el proceso de envío de correos electrónicos personalizados, en este artículo, explicaré una de las tantas maneras de lograrlo haciendo uso del lenguaje de programación Perl.
En CPAN podrá encontrar muchas alternativas, recuerde el
principio
TIMTOWTDI.
Sin embargo, la opción que más me atrajo fue MIME::Lite:TT, básicamente este
módulo en Perl es un wrapper de MIME::Lite que le permite el uso de
plantillas, vía Template::Toolkit, para el cuerpo del mensaje del correo
electrónico. También puede encontrar MIME::Lite::TT::HTML que le permitirá
enviar correos tanto en texto sin formato (MIME::Lite::TT) como en formato
HTML. Sin embargo, estoy en contra de enviar correos en formato HTML, lo dejo a
su criterio.
Una de las ventajas de utilizar Template::Toolkit para el cuerpo del mensaje
es separar en capas nuestra script, si se observa desde una versión muy
simplificada del patrón
MVC, el
control de la lógica de programación reside en el script en Perl, la plantilla
basada en Template Toolkit ofrecería la vista de los datos, de modo tal que
podríamos garantizar que la presentación está separada de los datos, los cuales
pueden encontrarse desde una base de datos o un simple fichero CSV. Otra ventaja
evidente es el posible reuso de componentes posteriormente.
Un primer ejemplo del uso de MIME::Lite:TT puede ser el siguiente:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
my %params;
$params{first_name} = "Milton";
$params{last_name} = "Mazzarri";
$params{username} = "milmazz";
$params{groups} = "sysadmin";
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => '[email protected]',
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();Y el cuerpo del correo electrónico, lo que en realidad es una plantilla basada
en Template::Toolkit, vendría definido en el fichero example.txt.tt de la
siguiente manera:
Hola [% last_name %], [% first_name %].
Tu nombre de usuario es [% username %].
Un saludo, feliz día.
Su querido BOFH de siempre.En el script en Perl mostrado previamente podemos percatarnos que los datos del destinario se encuentran inmersos en la lógica. Por lo tanto, el siguiente paso sería desacoplar esta parte de la siguiente manera:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Class::CSV;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();
}Ahora los datos de los destinarios los extraemos de un fichero en formato CSV,
en este ejemplo, el fichero en formato CSV lo hemos denominado example.csv.
Cabe aclarar que $msg->send() realiza el envío por medio de Net::SMTP y
podrá usar las opciones que se describen en dicho módulo. Sin embargo, si
necesita establecer una conexión SSL con el servidor SMTP es oportuno recurrir a
Net::SMTP::SSL:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Net::SMTP::SSL;
use Class::CSV;
my $from = '[email protected]';
my $host = 'mail.example.com';
my $user = 'jdoe';
my $pass = 'example';
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => $from,
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
my $smtp = Net::SMTP::SSL->new( $host, Port => 465 )
or die "No pude conectarme";
$smtp->auth( $user, $pass )
or die "No pude autenticarme:" . $smtp->message();
$smtp->mail($from) or die "Error:" . $smtp->message();
$smtp->to( $line->email() ) or die "Error:" . $smtp->message();
$smtp->data() or die "Error:" . $smtp->message();
$smtp->datasend( $msg->as_string ) or die "Error:" . $smtp->message();
$smtp->dataend() or die "Error:" . $smtp->message();
$smtp->quit() or die "Error:" . $smtp->message();
}Note en este último ejemplo que la representación en cadena de caracteres del
cuerpo del correo electrónico viene dado por $msg->as_string.
Para finalizar, es importante mencionar que también podrá adjuntar ficheros de
cualquier tipo a sus correos electrónicos, solo debe prestar especial atención
en el tipo MIME de los ficheros que adjunta, es decir, si enviará un fichero
adjunto PDF debe utilizar el tipo application/pdf, si envía una imagen en el
formato GIF, debe usar el tipo image/gif. El método a seguir para adjuntar uno
o más ficheros lo dejo para su investigación ;)
Recursos
Identificar el Hardware de tu PC en Debian GNU/Linux
Bien, lo que vamos a hacer a continuación es muy fácil, tán fácil como instalar un paquete, luego ejecutarlo y leer la información que él nos “escupe” (me encanta como suena :) ). Como sabrán, soy usuario de Debian GNU/Linux en su versión Etch para la arquitectura AMD64, pero ésto en realidad no es tan relevante ya que el paquete se encuentra tanto en Testing como en Stable para la mayoría de las arquitecturas y en la sección main de los repositorios.
Lo que vamos a instalar es el paquete lshw-gtk, que bien como dice en la descripción del paquete: “es una pequeña herramienta que provee información detallada de la configuración de hardware de la máquina. Puede reportar la configuración exacta de la memoria, versión de firmware, configuración de la tarjeta madre, versión del procesador y su velocidad, configuración de la caché, velocidad del bus, etc. en sistemas x86 con soporte DMI, en algunas máquinas PowerPC (se sabe de su funcionamiento en las PowerMac G4) y ADM64”.
Como ya sabrán, para instalar el paquete es tan sencillo como abrir una terminal y escribir en modo superusuario los siguiente:
# aptitude install lshw-gtk
El paquete no es muy pesado, de hecho, con todo y dependencias a penas ha de superar el mega de información, por lo que el proceso de instalación es rápido (si se tiene una conexión decente claro).
Una vez instalado el paquete no tenemos que hacer más que ejecutarlo. Para poder ejecutarlo debemos hacerlo desde una terminal, ya que según tengo entendido, no se instala en los menús del Gnome. Así que debemos escribir en una terminal (en modo superusuario):
# lshw-gtk
y listo, se ejecutará perfectamente, dejándonos navegar por unos paneles donde se encuentran los distintos componentes de nuestro sistema.
Si lo que quieres es tener un lanzador en los menús del Gnome, es muy sencillo, sólo deberás crear uno de la siguiente manera. Abre una terminal en modo superusuario y escribe lo siguiente:
gedit /usr/share/applications/LSHW.desktop
luego de presionar la tecla Enter se abrirá una ventana con el gedit en la cual deberás pegar el siguiente texto:
[Desktop Entry]
Name=LSHW
Comment=Identifica el hardware del sistema
Exec=gksu lshw-gtk
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya con eso deberías tener tu lanzador en el menú Aplicaciones –> Herramientas del sistema. Vas a necesitar de permisos de superusuario para poder ejecutarlo.
Acá una imagen de como se ve el lshw-gtk:
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
Automatiza el uso de pastebin desde la línea de comandos
Si deseas colocar gran cantidad de código en un canal IRC, Chat o haciendo uso de la mensajería instantánea, es realmente recomendable que haga uso de un sistema pastebin, por ejemplo, pastebin.com, el cual es una herramienta colaborativa que permite depurar código.
Además, siguiendo esta metodología se evita incurrir en el conocido flood, el cual consiste en el envio de gran cantidad de información a un usuario o canal, la mayoría de las ocasiones con el fin de molestar, incluso, puede lograr desconectar a otros usuarios. Este tipo de prácticas se castigan en muchos canales IRC.
Si no está familiariazado con la idea de los sistemas pastebin, un resúmen le puede ayudar en algo:
- Envie un fragmento de código al sistema pastebin de su preferencia, obtendrá
una dirección similar a
http://pastebin.com/1234 - Informe de la URL obtenida en los canales IRC o a través de la conversación que mantenga por mensajería instantánea.
- Cualquier persona puede leer su código, a su vez, pueden enviar modificaciones de éste.
- Si no se da cuenta de las modificaciones a primera vista, puede hacer uso de las opciones que le muestran las diferencias entre los ficheros de manera detallada.
Existe un script hecho en Python que le permite de manera automática y fácil el colocar la salida del terminal o de otros programas hechos en Python al sitio de pastebin que usted prefiera.
Instalación
Ejecute los siguientes pasos:
$ wget http://www.ubuntulinux.nl/files/pastebin
$ chmod +x pastebin
$ sudo ./pastebin --install
El comando anterior instalará el script dentro del directorio /usr/bin/ con permisos de ejecución.
Uso
pastebin [--name Autor] [--pid Entrada_Padre] [--bin URL_Pastebin]
Los valores entre corchetes son opcionales, cada uno significa lo siguiente:
-
--name: Recibe como valor el nombre del autor del código. -
--pid: Debe usarlo cuando está dando una respuesta o corrección a alguna entrada. Normalmente es el número que le sigue inmediatamente al nombre del servidor por ejemplo: Si usted tiene una URL de este tipo,http://pastebin.com/2401, elpidsería2401. -
--bin: Recibe como valor el sistema pastebin que esté usando.
Si no desea estar especificando a todo momento el nombre del autor (--name) y
el servicio pastebin que usa (--bin), puede crear un fichero en
/etc/pastebinrc o en ~/.pastebinrc. El primero aplica a todos los usuarios y
el segundo a un usuario local. En cualquiera de los casos, dicho fichero debe
contener lo siguiente:
poster = Nombre Autor
pastebin = Servicio Pastebin
Por ejemplo, en mi caso particular, el contenido del fichero /etc/pastebinrc
es el siguiente:
poster = [MilMazz]
pastebin = paste.ubuntulinux.nl
Haciendo uso de la tubería o pipe
Colocando la salida estándar
`$ comando | pastebin`
Colocando la salida estándar y los posibles errores
`$ comando 2>&1 | pastebin`
Recuerde que debe sustituir comando en los dos ejemplos mostrados previamente por el nombre real del comando del cual desea obtener una respuesta.
Vía: Ubuntu Blog.
Conozca la temperatura de su disco duro
Si desea conocer cual es el valor en grados centígrados de la temperatura de su
disco duro, simplemente instale el paquete hddtemp desde el repositorio
universe haciendo lo siguiente:
$ sudo aptitude install hddtemp
Después, siempre que desee conocer la temperatura actual de su disco duro, proceda de la siguiente manera:
$ sudo hddtemp /dev/hdb
Por supuesto, recuerde que en la línea anterior /dev/hdb es el identificador
de mi segundo disco duro, proceda a cambiarlo si es necesario.
Mi temperatura actual en el segundo disco duro es de:
milmazz@omega:~$ sudo hddtemp /dev/hdb
/dev/hdb: ST340014A: 46°C
Antes de finalizar, es importante resaltar que hddtemp le mostrará la
temperatura de su disco duro IDE o SCSI solamente si éstos soportan la
tecnología SMART (acrónimo de: Self-Monitoring, Analysis and Reporting
Technology).
SMART simplemente es una tecnología que de manera automática realiza un monitoreo, análisis e informes, ésta tiene un sistema de alarma que en la actualidad viene de manera predeterminada en muchos modelos de discos duros, lo anterior puede ayudarle a evitar fallas que de una u otra manera pueden afectarle de manera contundente.
En esencia, SMART realiza un monitoreo del comportamiento del disco duro y si éste presenta un comportamiento poco común, será analizado y reportado al usuario.
Vía: Ubuntu Blog.
Charlas en #ubuntu-es
El día de ayer se llevo a cabo la primera de la serie de charlas que se
emitirán por el canal #ubuntu-es del servidor FreeNode, en esta oportunidad
el ponente ha sido zodman, el tema que abordo zodman
fue acerca de Cómo montar un servidor casero haciendo uso de Ubuntu Linux como
plataforma, en el transcurrir de la charla se explico como configurar y
establecer un servidor con los siguientes servicios.
- Apache2
- MySQL
- PHP4
- FTP
- SSH
También se hablo acerca de la configuración de dominios .com, .net y .org sin hacer uso de bind, aplicando dichas configuraciones en el servidor que se está estableciendo.
Si desgraciadamente no pudo estar presente en el evento, no se preocupe, ya he habilitado un registro de la charla. Por motivos de tiempo se decidio dividir la charla en dos partes, si le interesa asistir a la segunda parte de esta charla, esté atentos a los cambios en la sección de Eventos en Ubuntuchannel.org.
Reduciendo el tamaño de tus hojas de estilos, una revisión
Hace pocos días atrás comenté acerca de la reducción en el tamaño en bytes de las hojas de estilo en cascada a través del uso de CSScompiler, en esta ocasión presentaré otras herramientas que cumplen el mismo fin, unas lo llevan a cabo mejor que otras.
Nacho, uno de los responsables de Microsiervos, nos presenta dos alternativas más, la primera de ellas es CSS Optimiser, si lo desea puede leer acerca de CSS Optimiser para obtener mayor información. De todas maneras, a continuación un resúmen de las características de esta herramienta.
Características de CSS Optimiser
- Elimina los comentarios.
- Elimina los espacios en blancos (por ejemplo, el exceso de espacios).
- Opción que permite convertir valores RGB a Hexadecimal (estos últimos son más pequeños).
- Convierte valores hexadecimales bajo el formato #RRGGBB a #RGB.
- Produce cambios en los valores, como por ejemplo
border: 1px 2px 1px 2px;enborder: 1px 2px; - Convierte múltiples atributos de
background,font,margin,padding,listen una simple lista de atributos. - Convierte múltiples valores de la propiedad
borderen una simple lista de atributos. - Se da la opción de convertir valores absolutos (por ejemplo:
pxopt) en valores relativos (em). - Agrupa atributos y valores de estilos que aparecen en varias ocasiones en un solo estilo.
Ahora bien, la segunda alternativa que nos plantea Nacho, CSS Compressor solo nos brinda la oportunidad de eliminar los espacios en blancos y fusionar lo mayor posible el contenido, por ejemplo:
Código fuente CSS original:
body{
/* Propiedades de fondo */
background-color:#666666;
background-image: url(image.png);
background-position: bottom right;
background-repeat: no-repeat;
background-attachment: fixed;
font-size: 100%;
}
Resultado:
body{background-color:#666666;background-image:url(image.png);background-position:bottom right;background-repeat:no-repeat;background-attachment:fixed;font-size:100%}
Para muchos este nuevo formato puede ser practicamente ilegible, es cierto, pero en realidad ofrece cierta reducción al tamaño de las hojas de estilos en cascada.
Continuando con el tema, Zootropo nos propone en su artículo ¡Adelgazar es fácil! una nueva herramienta a las expuestas anteriormente, esta herramienta es CSS Formatter and Optimiser, esta herramienta llega a cumplir a cabalidad con la funcionalidad que propone CSS Compressor, entre otras características, como la optimización del código CSS. CSS Formatter and Optimiser es una excelente herramienta, muy poderosa y posee muchas opciones para el usuario. Vamos a describirlas brevemente.
Opciones que ofrece CSS Formatter and Optimiser
- Compresión máxima (ninguna legibilidad, tamaño más pequeño)
- Compresión moderada (legibilidad moderada, tamaño reducido)
- Compresión estándar (equilibrio entre legibilidad y tamaño)
- Compresión baja (legilibilidad más alta)
- Compresión personalizada, puede elegir entre:
- Ordenar los selectores.
- Ordenar las propiedades.
- Fusionar aquellos selectores que posean las mismas propiedades.
- Fusionar aquellas propiedades en las que aplique el shorthand CSS.
- Comprimir el formato del color, si el formato está en RGB se lleva a Hexadecimal, si está en hexadecimal también trata de reducir su formato en aquellos casos que aplique el shorthand CSS.
- Convierte los selectores a minúsculas.
- Casos especiales para las propiedades:
- Convertir a minúsculas.
- Convertir a mayúsculas.
- Eliminar los simbolos
\innecesarios.
- Se ofrece la opción de guardar la salida en un fichero, lo que le permitirá ahorrar tiempo entre copiar y pegar en su editor de hojas de estilos en cascada favorito.
Pruebas
A continuación se realizarán una serie de pruebas, estas estarán basadas únicamente en dos parámetros, legibilidad y tamaño de los ficheros generados. Todas las pruebas hechas parten de un mismo fichero CSS, él código mostrado en este fichero presenta gran cantidad de comentarios y precario (adrede) uso de shorthands.
Tabla de Resultados
Herramienta
Característica
Antes
Después
Ahorro
CSS Optimiser
Caracteres
3143
601
2542
Lineas
128
41
N/A
Legibilidad
Muy alta
Alta
N/A
Porcentaje
N/A
N/A
81%
CSS Formatter & Optimiser
Caracteres
3143
802
2341
Lineas
128
57
N/A
Legibilidad
Muy alta
Alta
N/A
Porcentaje
N/A
N/A
74%
CSS Compressor
Caracteres
3143
1225
1918
Lineas
128
1
N/A
Legibilidad
Muy alta
Muy baja
N/A
Porcentaje
N/A
N/A
61%
CSScompiler
Caracteres
3143
1230
1913
Lineas
128
8
N/A
Legibilidad
Muy alta
Baja
N/A
Porcentaje
N/A
N/A
61%
N/A: No aplica
Observaciones
CSS Optimiser maneja muy bien la reducción de las declaraciones cuando es aplicable el shorthand, algo en lo falla un poco CSS Formatter & Optimiser, aunque éste último ofrece bastantes opciones, por lo que es bueno tomarlo en cuenta a la hora de reducir el tamaño en bytes de nuestras hojas de estilos. Si queremos hacer uso de CSS Optimiser y aún deseamos obtener una mayor compresión, es posible obtenerla si combinamos el resultado obtenido con la herramienta CSS Compressor, el cual eliminará los espacios existentes. Quizás la única falla que percibi en CSS Optimiser fue que aún no maneja adecuadamente las reducciones de aquellas reglas que presentan declaraciones comunes, leyendo ciertas notas del autor, me doy cuenta que está trabajando en ello.
He trabajado con una hoja de estilos bastante comentada y sin utilizar propiedades abreviadas (adrede) para realizar las pruebas, a continuación muestro los enlaces a cada uno de los ficheros de las hojas de estilos.
- Hoja sin ninguna compresión, original
- Hoja de estilos utilizando CSS Optimiser
- Hoja de estilos utilizando CSS Fomatter & Optimiser
- Hoja de estilos utilizando CSS Compressor
- Hoja de estilos utilizando CSScompiler
Si conoces alguna herramienta que permita la reducción del tamaño en bytes de las hojas de estilo en cascada no dudes en comentarlo, de esta manera, podría ampliar la revisión nuevamente.
Libros sobre Perl
Victor Reyes, miembro de la lista de correos para consultas técnicas de VELUG (Grupo de Usuario Linux de Venezuela), nos facilita de su biblioteca personal la excelente recopilación The Perl CD Bookshelf, el cual contiene 6 excelentes libros de la editorial O’Reilly sobre el lenguaje de programación Perl.
Actualización:
En la página principal de Victor Reyes podrán conseguir mayor documentación sobre otros temas, menciono solo algunos de ellos:
- Java
- TCP/IP
- Unix
- Java Enterprise
- Linux
- Oracle PL/SQL
- WWW
- FreeBSD
CSScompiler, reduce el tamaño de tus hojas de estilos
Daniel Mota recientemente ha lanzado CSScompiler 1.0, se trata de un script que reduce al máximo el peso en bytes (unidad básica de almacenamiento de información) de tus hojas de estilo, esto puede ser significativo si existe excesiva cantidad de peticiones a dichos ficheros, el beneficio es ahorrar ancho de bando en nuestros servidores.
Ahora bien, ¿qué hace CSScompiler para reducir el tamaño de las hojas de estilos en cascada?, simplemente elimina los comentarios, saltos de líneas y el último punto y coma antes del cierre de los corchetes, además, se ofrecen otras funcionalidades que mejoran la sintaxis e interpretación de algunas propiedades.
Puedes obtener una descripción más detallada en el artículo CSScompiler. En el mismo artículo podrás encontrar dos ejemplos (uno compilado y el otro sin compilar) que te darán una idea acerca de la funcionalidad de este script.
Viendo tus diseños en una Mac
Para todas aquellas personas que no posean una Mac, quizás la aplicación Screenshot Generator les resulte bastante útil, si eres diseñador web seguramente te preocuparás porque tus trabajos se vean correctamente en todos los navegadores, esta aplicación te permite simular la vista en los siguientes navegadores bajo Mac:
- Safari 1.3
- Internet Explorer 5.2.3
- Mozilla 1.7.7
Vía Ovillo.
Scripts
Enviando correos con Perl
Regularmente los administradores de sistemas requieren notificar, vía correo electrónico, a sus usuarios de ciertos cambios o nuevos servicios disponibles. La experiencia me ha indicado que el usuario aprecia más un correo personalizado que uno general. Sin embargo, lograr lo primero de manera manual es bastante tedioso e ineficaz. Por lo tanto, es lógico pensar en la posibilidad de automatizar el proceso de envío de correos electrónicos personalizados, en este artículo, explicaré una de las tantas maneras de lograrlo haciendo uso del lenguaje de programación Perl.
En CPAN podrá encontrar muchas alternativas, recuerde el
principio
TIMTOWTDI.
Sin embargo, la opción que más me atrajo fue MIME::Lite:TT, básicamente este
módulo en Perl es un wrapper de MIME::Lite que le permite el uso de
plantillas, vía Template::Toolkit, para el cuerpo del mensaje del correo
electrónico. También puede encontrar MIME::Lite::TT::HTML que le permitirá
enviar correos tanto en texto sin formato (MIME::Lite::TT) como en formato
HTML. Sin embargo, estoy en contra de enviar correos en formato HTML, lo dejo a
su criterio.
Una de las ventajas de utilizar Template::Toolkit para el cuerpo del mensaje
es separar en capas nuestra script, si se observa desde una versión muy
simplificada del patrón
MVC, el
control de la lógica de programación reside en el script en Perl, la plantilla
basada en Template Toolkit ofrecería la vista de los datos, de modo tal que
podríamos garantizar que la presentación está separada de los datos, los cuales
pueden encontrarse desde una base de datos o un simple fichero CSV. Otra ventaja
evidente es el posible reuso de componentes posteriormente.
Un primer ejemplo del uso de MIME::Lite:TT puede ser el siguiente:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
my %params;
$params{first_name} = "Milton";
$params{last_name} = "Mazzarri";
$params{username} = "milmazz";
$params{groups} = "sysadmin";
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => '[email protected]',
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();Y el cuerpo del correo electrónico, lo que en realidad es una plantilla basada
en Template::Toolkit, vendría definido en el fichero example.txt.tt de la
siguiente manera:
Hola [% last_name %], [% first_name %].
Tu nombre de usuario es [% username %].
Un saludo, feliz día.
Su querido BOFH de siempre.En el script en Perl mostrado previamente podemos percatarnos que los datos del destinario se encuentran inmersos en la lógica. Por lo tanto, el siguiente paso sería desacoplar esta parte de la siguiente manera:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Class::CSV;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();
}Ahora los datos de los destinarios los extraemos de un fichero en formato CSV,
en este ejemplo, el fichero en formato CSV lo hemos denominado example.csv.
Cabe aclarar que $msg->send() realiza el envío por medio de Net::SMTP y
podrá usar las opciones que se describen en dicho módulo. Sin embargo, si
necesita establecer una conexión SSL con el servidor SMTP es oportuno recurrir a
Net::SMTP::SSL:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Net::SMTP::SSL;
use Class::CSV;
my $from = '[email protected]';
my $host = 'mail.example.com';
my $user = 'jdoe';
my $pass = 'example';
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => $from,
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
my $smtp = Net::SMTP::SSL->new( $host, Port => 465 )
or die "No pude conectarme";
$smtp->auth( $user, $pass )
or die "No pude autenticarme:" . $smtp->message();
$smtp->mail($from) or die "Error:" . $smtp->message();
$smtp->to( $line->email() ) or die "Error:" . $smtp->message();
$smtp->data() or die "Error:" . $smtp->message();
$smtp->datasend( $msg->as_string ) or die "Error:" . $smtp->message();
$smtp->dataend() or die "Error:" . $smtp->message();
$smtp->quit() or die "Error:" . $smtp->message();
}Note en este último ejemplo que la representación en cadena de caracteres del
cuerpo del correo electrónico viene dado por $msg->as_string.
Para finalizar, es importante mencionar que también podrá adjuntar ficheros de
cualquier tipo a sus correos electrónicos, solo debe prestar especial atención
en el tipo MIME de los ficheros que adjunta, es decir, si enviará un fichero
adjunto PDF debe utilizar el tipo application/pdf, si envía una imagen en el
formato GIF, debe usar el tipo image/gif. El método a seguir para adjuntar uno
o más ficheros lo dejo para su investigación ;)
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
audioconverter v0.3.1
El día de hoy me comentaba Fernando Arenas, quien me contacto vía correo electrónico, que se había percatado de un pequeño bug en el script audioconverter, específicamente cuando se realizaba la conversión del formato .wma a .mp3.
Para quienes utilizan el script, les recomiendo actualizar a la versión más reciente, audioconverter-v0.3.1. También pueden emplearlo todas esas personas que deseen probar el programa (al menos por curiosidad), cualquier comentario es bienvenido.
Espero poder traerles una nueva versión del script audioconverter en el mes de Enero, mejorando la interfaz e incluyendo algunas características que me han mencionado en el transcurso del desarrollo de la aplicación. Espero poder complacerles. De nuevo, cualquier sugerencia es bienvenida.
Referencias
Eliminando ficheros inútiles de manera recursiva
En algunos casos mientras redactamos, codificamos o trabajamos en algunos editores de texto se van generando ficheros temporales que puede irse acumulando en nuestros directorios, estos suelen ser utiles en aquellos casos en los cuales las aplicaciones terminan de manera inesperada, seguramente podremos recuperar los ultimos cambios hechos al utilizar este tipo de ficheros, o en el caso de los ficheros core, nos pueden servir en aquellos casos en los cuales alguna funcion de nuestros programas no funciona como deberia y genera una violacion de segmento, los ficheros core nos pueden facilitar el analisis en la busqueda de los posibles errores en la funcion.
En muchas ocasiones nos encontramos que estos ficheros temporales se encuentran dispersos en algunos directorios y el hecho de borrarlos uno a uno suele ser un proceso mas bien tedioso. Por la razon mencionada anteriormente podriamos hacernos la siguiente pregunta, ¿es posible automatizar el proceso de eliminacion de ficheros “inutiles” de manera recursiva?, la respuesta es si.
El siguiente script nos ayudara servira para lograr lo que deseamos.
#!/bin/bash
#Borrar de manera recursiva los ficheros inutiles.
echo Directorio Raiz: $PWD
echo Procesando...
find $PWD \( -name \*~ -or -name \*.o -or -name \*\# -or -name core \) -exec rm -vf {} \;
echo Listo!
En el codigo mostrado anteriormente el comando que realiza todo el trabajo por nosotros es find, voy a explicar brevemente que hace este comando.
El comando find necesita de un camino o ruta y de una expresion regular para lograr encontrar alguna coincidencia al recorrer el arbol de directorios cuya raiz es el camino especificado, find evaluara de izquierda a derecha las expresiones indicadas, tomando en cuenta las reglas de precedencia en los operadores, al conocer el resultado (cierto o falso) find continuara con el siguiente fichero.
Dentro del comando find encontrara el uso de ciertas opciones, entre las cuales cabe mencionar las siguientes:
-
-or: Representa el o logico, es equivalente a utilizar la opcion-o. -
-exec: Ejecuta la orden especificada siempre y cuandofindhaya encontrado alguna concordancia con la expresion regular, por lo tanto se devuelve valor cierto. Las ordenes seran aquellos argumentos que siguen a-exechasta que encontrar el caracter ; (punto y coma). Si desea ser consultado antes de realizar la ejecucion al encontrarse alguna coincidencia, es preferible hacer uso de la opcion-ok. -
-name: Especifica la base del nombre del fichero que deseamos buscar, no es necesario especificar el directorio, hace distincion entre mayusculas y minusculas. Se puede hacer uso de metacaracteres. -
{}: Cadena que es reemplazada por el nombre del fichero que se esta procesando en ese instante.
Puede copiar el script mostrado arriba, supongamos que lo ha llamado rmnull, debe moverlo dentro del directorio /usr/local/bin/ (haciendolo como superusuario). Posteriormente debe otorgarle permisos de ejecucion.
$ sudo mv rmnull /usr/local/bin/
chmod +x /usr/local/bin/rmnull
Ahora bien, para hacer uso del script simplemente debera teclear en consola rmnull, el directorio raiz sera el directorio en el que se encuentre actualmente. Veamos un ejemplo de ejecucion del script.
milton@omega:~$ touch file# file.o file~ pruebas/file# pruebas/file~ pruebas/core
milton@omega:~$ pwd
/home/milton
milton@omega:~$ rmnull
Directorio Raiz: /home/milton
Procesando...
«/home/milton/Desktop/find.txt~» borrado
«/home/milton/pruebas/file#» borrado
«/home/milton/pruebas/file~» borrado
«/home/milton/pruebas/core» borrado
«/home/milton/file#» borrado
«/home/milton/file.o» borrado
«/home/milton/file~» borrado
Listo!
En el ejemplo de ejecucion hago uso del comando touch para crear los ficheros especificados (en caso de no existir), estos archivos en principio se encuentran vacios y con permisos de lectura y escritura para el dueño del fichero, grupo al pertenece el dueño y demas usuarios. Posteriormente hago uso del comando pwd para conocer mi ubicacion actual, a continuacion “invoco” al script rmnull quien hara el trabajo de limpieza de manera automatizada.
AudioConverter v0.3
El día de hoy he publicado la nueva versión de este script, Audio Converter v0.3, para mayor detalle vea el artículo Convirtiendo los formatos de compresión de audio.
Zenity, mejorando la presencia de tus scripts
Zenity, es un programa que le permitirá desplegar cuadros de dialogos GTK+, lo cual le facilitará la interacción con el usuario. Tomando en consideración lo anterior, Zenity debe ser considerado a la hora de desarrollar scripts que necesitan presentar una interfaz “amigable”, lo cual facilitará el manejo del script. Por ejemplo, puede generar un cuadro de dialogo que le indique al usuario el progreso de la operación actual, o un mensaje de alerta al usuario.
¿Qué puedo hacer con Zenity?
Puede hacer los siguientes cuadros de dialogos:
- Calendarios
- Selección de ficheros o directorios
- Listas
- Mensajes de:
- Error
- Información
- Preguntas
- Alerta
- Progreso de operaciones
- Entradas de texto
- Textos de información
- Mensajes en el área de notificación
Esto no pretende ser un tutorial exhaustivo del uso de Zenity, simplemente se mostrarán algunos usos que le he dado al desarrollar audioconverter, si utiliza el entorno de escritorio GNOME, puede encontrar información detallada en: Sistema -> Ayuda -> Escritorio -> Zenity.
Listas
 En la imagen de la
izquierda podemos apreciar uno de los tipos de listas que pueden ser creadas, en
este caso he usado la opción –radiolist, esto permite que únicamente se
seleccione una opción, si se desea permitir el seleccionar más de una opción,
podemos recurrir a –checklist. Al emplear las opciones –radiolist o
–checklist es necesario comenzar cada fila con alguna de las constantes
En la imagen de la
izquierda podemos apreciar uno de los tipos de listas que pueden ser creadas, en
este caso he usado la opción –radiolist, esto permite que únicamente se
seleccione una opción, si se desea permitir el seleccionar más de una opción,
podemos recurrir a –checklist. Al emplear las opciones –radiolist o
–checklist es necesario comenzar cada fila con alguna de las constantes
TRUE o FALSE, en donde TRUE hará que el botón de radio (o de verificación)
se encuentre marcado, en caso contrario el botón quedará desmarcado.
Es importante aclarar que Zenity retornará la entrada que se encuentre en la
primera columna de texto de la fila seleccionada al error estándar (stderr),
en el ejemplo el valor de retorno sería 2. En el caso que necesite utilizar
dicho valor en el script, será necesario hacer una redirección de los
descriptores.
zenity --list \
--title="AudioConverter (v0.3)" \
--text="Seleccione una operacion a realizar de la lista." \
--radiolist \
--width="355" \
--height="290" \
--column="" --column="#" --column="Operacion" --column="Descripcion" \
FALSE 1 "MP3 a WAV" "Convierte ficheros MP3 a WAV" \
FALSE 2 "MP3 a OGG" "Convierte ficheros MP3 a OGG" \
FALSE 3 "OGG a WAV" "Convierte ficheros OGG a WAV" \
FALSE 4 "OGG a MP3" "Convierte ficheros OGG a MP3" \
FALSE 5 "WAV a OGG" "Convierte ficheros WAV a OGG" \
FALSE 6 "WAV a MP3" "Convierte ficheros WAV a MP3" \
FALSE 7 "WMA a MP3" "Convierte ficheros WMA a MP3"
En el codigo de arriba se muestran algunas cosas que aún no he detallado, por ejemplo:
-
--titlees una opción general, establece el título del cuadro de dialogo. -
--widthes una opción general, establece la anchura del cuadro de dialogo. -
--heightes una opción general, establece la altura del cuadro de dialogo. -
--textestablece el texto de la lista. -
--columnes una opción específica para la generación de listas, establece el título de la columna.
Existe una opción bastante interesante dentro de las opciones de las listas,
dicha opción es –print-column, la cual permite especificar qué columna se
imprimirá en la salida estándar (stdout). Por defecto se devuelve el valor de
la primera columna, puede utilizar la cadena ALL para imprimir todas las
columnas de la fila seleccionada.
Es importante que se asegure de encerrar entre comillas cada uno de los argumentos de los comandos en Zenity, de lo contrario, puede obtener resultados inesperados.
Textos de información
Para crear dialogos de textos de información simplemente debemos utilizar la
opción --text-info.
 Aparte de las
opciones generales, los dialogos de textos de información soportan las
siguientes opciones:
Aparte de las
opciones generales, los dialogos de textos de información soportan las
siguientes opciones:
-
--filename=ficheroespecifica qué fichero será cargado en el dialogo de información -
--editablepermite que el texto mostrado pueda ser editado. El texto editado es retornado astandard error(stderr), cuando el cuadro de dialogo se cierra:… 2) mp32ogg 2>&1 | zenity –text-info
–title=”Registro de la Conversion”
–width=”420”
–height=”500”;; …
En el código no se indica explicitamente la opción –filename, pero cabe
resaltar que la salida estándar (stdout) de la función mp32ogg es trasladada a
través de una tubería (pipe, |) a Zenity, previamente se ha duplicado el
error estándar (stderr) de la fucnión mp32ogg a la salida estándar
(stdout) de la misma, de esta manera aprovechamos como entrada al dialogo de
información las salidas de la función mp32ogg.
Si lo desea puede ampliar la información acerca de las redirecciones en bash leyendo el Manual de Referencia Bash (inglés), no estoy seguro si existe en la red una versión en español de este manual.
Dialogos de Información
 Para mostrar
cuadros de dialogos de información debemos hacer uso de la opción –info. Dentro
de esta categoría existe únicamente un parámetro que se puede utilizar aparte de
las opciones generales, dicho parámetro es –text, éste establece un texto
en el dialogo.
Para mostrar
cuadros de dialogos de información debemos hacer uso de la opción –info. Dentro
de esta categoría existe únicamente un parámetro que se puede utilizar aparte de
las opciones generales, dicho parámetro es –text, éste establece un texto
en el dialogo.
zenity --info \
--text="Conversion MP3 a OGG finalizada."
De manera similar se puede mostrar un mensaje de error, debemos recurrir a la opción –error para ello, por ejemplo:
if [ "${1}" -ne "0" ]; then
zenity --error \
--text="${2}"
exit ${1}
fi
Entradas de Texto
 Se debe utilizar la
opción –entry para crear cuadros de dialogos de entrada de texto, es importante
hacer notar que Zenity retornará el contenido de la entrada de texto al error
estándar. En el caso que necesite utilizar dicho valor en el script, será
necesario hacer una redirección de los descriptores.
Se debe utilizar la
opción –entry para crear cuadros de dialogos de entrada de texto, es importante
hacer notar que Zenity retornará el contenido de la entrada de texto al error
estándar. En el caso que necesite utilizar dicho valor en el script, será
necesario hacer una redirección de los descriptores.
Dentro de esta categoría tenemos las siguientes opciones:
-
--textespecifica el texto que se mostrará en el cuadro de dialogo de entrada de texto. -
--entry-textestablece el texto que será mostrado en el campo de entrada en el cuadro de dialogo, ideal en los casos cuando quiere mostrar al usuario algún valor predeterminado. -
--hide-textoculta el texto en el campo de entrada del cuadro de dialogo, ideal en aquellos casos cuando el valor ingresado es una contraseña.
Código de muestra
...
if zenity --entry \
--title="Ingreso de datos" \
--text="Ingrese el valor del Bitrate:" \
--entry-text="160" > bitrate.txt
then bitrate=$(head bitrate.txt); rm -f bitrate.txt
else bitrate="160"
fi
...
Ya para finalizar, solo espero que se animen a probar esta útil herramienta a la hora de desarrollar sus scripts, en principio Zenity es básico en su manejo e implementación, próximamente espero publicar un breve tutorial acerca del uso de Xdialog, el cual desde mi perspectiva es más profundo que Zenity.
Convirtiendo los formatos de compresión de audio
Siguiendo con la temática que propuse en el artículo Convirtiendo formatos de audio OGG a MP3 he decido ampliar dicho script para abarcar nuevos formatos. En esta ocasión he decidido hacerlo un poco más interactivo con el usuario, aún faltan cosas, pero las funciones elementales las cumple a cabalidad.
Las conversiones que se pueden realizar son las siguientes:
- mp3 -> wav
- mp3 -> ogg
- ogg -> wav
- ogg -> mp3
- wav -> ogg
- wav -> mp3
Antes de proseguir, vamos a revisar los requerimientos.
-
mpg321:Reproductor libre de MP3 bajo linea de comandos, compatible conmpg123, este último no es libre. Nos permitirá decodificar ficheros MP3 (mp3 -> wav). -
vorbis-tools:Paquete de herramientas de OGG Vorbis, entre las cuales se encuentranoggenc, para codificar ficheros WAV (wav -> ogg), yoggdec, para decodificar ficheros OGG Vorbis (ogg -> wav). -
lame:Codificar ficheros MP3 (wav -> mp3). -
normalize:Para ajustar o equilibrar el volúmen de los distintos ficheros involucrados, actúa sobre ficheros WAV.
Una breve descripción acerca de la funcionalidad del paquete normalize la
podrá encontrar en el artículo Convirtiendo formatos de audio OGG a
MP3.
Para aquellas personas que disfrutan de una distribución
Debian o alguna basada en ella simplemente deben hacer
lo siguiente como superusuario o root.
apt-get install lame mpg321 vorbis-tools normalize
El script temporalmente actúa sobre los directorios actuales, aún no tiene la
capacidad de permitir como parámetros un directorio origen y un directorio
destino, próximamente implementaré esta opción, ante lo explicado anteriormente,
puede que le resulte conveniente copiar el script dentro del directorio
/usr/local/bin, así podrá ejecutarlo desde cualquier directorio de su $HOME
sin inconveniente alguno.
Desde mi punto de vista el uso del script es intuitivo, sin embargo, explicare la evolución del proceso de conversión de 3 ficheros OGG Vorbis a MP3 con un ejemplo. Puede descargar el script al hacer clic en AudioConverter.
Cosas por hacer (TODO)
- Permitir al usuario indicar un directorio origen y un directorio destino
- Permitir al usuario seleccionar si el formato de compresión de audio en un fichero mp3 sea CBR (Tasa Constante de Bits) o VBR (Tasa Variable de Bits)
- Permitir al usuario seleccionar la calidad de codificación de los ficheros OGG Vorbis, de manera predeterminada está seleccionada como 3, en donde, -1 representa la peor calidad y 10 la mejor.
¿Puedo colaborar?
Por supuesto, este script es de uso libre, puede colaborar también al comentar si existe algún fallo, o simplemente con sus sugerencias, las cuales serán tomadas en cuenta para el posterior desarrollo del script.
Anuncios
24/04/2005 Sale la versión 0.3 del script.
Características de la versión
Se añaden cuadros de dialogos con el uso de Zenity, permitiendo así interactuar con el usuario de manera más amena.
22/04/2005 Sale la versión 0.2 del script.
Características de la versión
- Se verifica que las aplicaciones necesarias se encuentren instaladas.
- Se verifica la existencia de ficheros origen en el directorio donde es ejecutado el script.
- Se incorpora la posibilidad de convertir ficheros WMA a MP3.
- El script renombra los ficheros para evitar posibles errores en las conversiones a realizar.
- El nombre del ejecutable cambia a: audioconverter, de esta manera el comando es más homogéneo a los comandos regulares del shell.
Agradecimientos
Muchas gracias Gabriel de guia-ubuntu.org por sus comentarios y sugerencias.
Convirtiendo formatos de audio OGG a MP3
Por todos es bien sabido la superioridad que presenta el formato de compresión de audio OGG Vorbis frente al MP3, adicionalmente, el primero de los formatos es libre, no posee patentes, algo que, en el caso del MP3 no es cierto, el MP3 sí posee licencia. Desgraciadamente no siempre lo mejor es lo más difundido, solo espero que esta situación cambie algún día.
Solo en algunas ocasiones es “preferible” hacer uso de los MP3, por ejemplo, mi reproductor portátil únicamente acepta los formatos Mp3 y WMA, dos formatos privativos, el primero de ellos fué desarrollado por Fraunhofer ISS y el segundo por Microsoft.
Ahora bien, después de una breve introducción, vamos a lo nuestro, el script
en primera instancia removerá los espacios en los nombres de los ficheros OGG
Vorbis, seguidamente convertirá todos los carácteres en mayúsculas a
minúsculas, esto lo hacemos con
rename, a continuación
decodificaremos el fichero con oggdec, este último creará ficheros WAV. Luego
de haber creado los ficheros WAV, vamos a ajustar el volumen de dichos ficheros
a un nivel standard, con esto evitamos la posible existencia de una variación
muy drástica en el volumen de una canción a otra, sobretodo si se tienen
colecciones de álbumes distintos, con niveles de grabación diferentes, este
ajuste lo realizamos con el comando normalize.
Ya para finalizar, el último bucle del script convertirá los ficheros WAV en MP3, de manera predeterminada se codificará el formato de compresión de audio a unos 160kbps, ud. puede modificar este comportamiento pasándole al script el único argumento que éste acepta, por ejemplo:
ogg2mp3 192
Esto codificará el fichero MP3 a 192kbps. Ya para finalizar, si no hay errores en la codificación de los ficheros, se procederá a borrar los ficheros WAV, que han sido usados como temporales.
#!/bin/bash
#Removiendo Espacios
rename 'y/\ /_/' *.ogg
#Mayusculas a Minusculas
rename 'y/A-Z/a-z/' *.ogg
#Conversion de archivo *.ogg a *.wav
for archivo in *.ogg; do oggdec $archivo; done
#Comente la siguiente linea si no desea igualar el volumen de los ficheros
normalize -m *.wav
for archivo in *.wav; do
#Variable auxiliar con el nombre base del archivo
aux="$(basename "$archivo" .wav)"
#Verificamos que el usuario introduzca el bitrate
#En caso de no insertar el bitrate, se proporciona uno predeterminado
if [ -z "$1" ]
then
echo ":Valor de bitrate no suministrado. Predeterminado: 160kbps."
lame -b 160 "$aux.wav" "$aux.mp3"
else
lame -b $1 "$aux.wav" "$aux.mp3"
fi
#Verificamos posible errores
#Si no hay errores, eliminamos el fichero *.wav
if [ $? -eq 0 ]
then
rm -f "$aux.wav"
fi
done
Nota: Es posible que de acuerdo a la distribución que use, deba instalar
ciertos paquetes, en mi caso solamente debi instalar el paquete normalize y el
lame, simplemente hice lo siguiente: sudo apt-get install lame normalize
Anuncios
Lavado de cara para Planeta Linux
Desde las 2:00 p.m. (hora local) del día de hoy, con la asistencia del compañero Damog, hemos ido actualizando el layout de Planeta Linux, aún falta mucho trabajo por hacer, pero al menos ya hemos dado los primeros pasos.
Cualquier opinión, crítica, sugerencia, comentario agradecemos enviar un correo electrónico a la lista de correos de Planeta Linux. *[p.m.]: Post meridiem
Actualizando WordPress
Tenía cierto tiempo que no actualizaba la infraestructura que mantiene a MilMazz, el día de hoy he actualizado WordPress a su version 2.0.2, este proceso como siempre es realmente sencillo, no hubo problema alguno.
También he aprovechado la ocasión para actualizar el tema K2, creado por Michael Heilemann y Chris J. Davis, de igual manera, he actualizado la mayoría de los plugins.
Respecto al último punto mencionado en el párrafo anterior, algo extraño sucedió al actualizar el plugin Ultimate Tag Warrior, al revisar su funcionamiento me percaté que al intentar ingresar a una etiqueta particular se generaba un error 404, de inmediato supuse que era la estructura de los enlaces permanentes y las reglas de reescritura, para solucionar el problema simplemente actualice la estructura de enlaces permanentes desde las opciones de la interfaz administrativa de WordPress.
Si nota cualquier error le agradezco me lo haga saber a través de la sección de contacto.
Planeta Linux
Hace tiempo que no revisaba algunas de las estadísticas del sitio, me he percatado que han llegado algunos enlaces desde Planeta Linux Venezuela. El principal objetivo de este sitio es:
Planeta Linux es un pequeño proyecto que pretende fomentar la comunicación e intercambio sencillo de información sobre cualquier usuario de GNU/Linux o software libre, en Venezuela. Con esta breve comunicación, podremos conformar una comunidad mucho má sólida, unificada e integral.
Lo anterior también es extensible para aquellas personas mexicanas, puesto que existe un Planeta Linux México.
¿Desea colaborar con el proyecto?
El proceso de registro es muy sencillo, solamente debes enviar un correo a lista de correos [email protected], si desea suscribirse a dicha lista solamente rellene los datos solicitados página de información de la lista de correos de Planeta Linux.
Para su admision usted debe suministrar los siguientes datos:
- Nombre completo
- Lugar de residencia
- URI del feed RSS/Atom
Opcionalmente puede enviar su Hackergotchi, imagen de un escritor que es utilizada como ícono para identificar al autor de un feed dado dentro de un agregador de blogs, ésta no debe exceder un ancho de 95 pixels y un alto de 95 pixels.
Conociendo un poco más acerca del proyecto
Me ha interesado mucho esta iniciativa, así que no dude en ponerme en contacto con David Moreno Garza (a.k.a. damog), él cual me ha contestado muy amablemente. En las siguientes líneas expongo nuestro intercambio de correos electrónicos.
- MilMazz: Hola David, en realidad no tengo el placer de conocerte personalmente, pero he notado recientemente algunos enlaces entrantes desde el Planeta Linux Venezuela, no se quien me dio de alta, se agradece, así que gracias.
- Damog: Hola Milton, no, al parecer no nos conocemos. Yo te di de alta en el rol debido a que José Parrella, a.k.a bureado, me pasó tu nombre y feed.
- MilMazz: El motivo de este mensaje es para pedirte un poco de informacion respecto al proyecto, para publicar un artículo en mi blog y así colaborar con la difusión de esta interesante idea.
- Damog: ¡Muchas gracias! Así es como el proyecto va ganando adeptos y más gente se va uniendo y leyendo el contenido de Planeta Linux.
- MilMazz: Espero no te molesten las siguientes preguntas, tomalo a manera de entrevista :)
- Damog: Desde luego que no, ¡bienvenidas! Antes que cualquier cosa, espero que no te importe que reenvíe este correo a la lista de Planeta Linux.
- MilMazz: ¿Quién o quienes se plantearon en principio la idea de crear Planeta Linux?, ¿quién lo llevaron a cabo?
- Damog: Debido al boom que han tenido los blogs entre usuarios y desarrolladores de software libre en el mundo, se ve la necesidad de crear nuevas herramientas para «monitorear» los contenidos dependiendo de los gustos de cada uno de los usuarios. Wieland Kublun, un mexicano radicado en Guadalajara, en el estado de Jalisco, en el occidente de México, alguna vez me comentó que estaría bien tener una especie de «planeta», como los que se han dado a conocer por proyectos grandes como Planet Debian o Planet GNOME. Creí que la idea era estupenda y empezamos a poner el agregador en marcha y añadiendo a nuestros conocidos al rol.
Otro factor que ha influído mucho en la gran proliferación de Planeta Linux es Jaws. Jaws es un proyecto, iniciado por Jonathan Hernández, radicado en Chihuahua, en el norte de México, de software libre para construir fácilmente un blog. El proyecto Jaws ha avanzado ya muchísimo, pues el software desarollado es altamente útil, funcional y bastante bonito. Por ende, muchos usuarios mexicanos empezaron a montar sus blogs en él y la mancha de usuarios blogueadores mexicanos creció mucho.
- MilMazz: Tengo entendido que el primer planeta de la “serie” fue el Planeta Linux Mexico, ¿desde cuando está en línea?
- Damog: Así es, fue el primero. Ha estado en línea desde octubre de 2004. Antes utilizábamos el dominio planetalinux.com.mx, pero recientemente abrimos el 2006 con el dominio, más genérico y permitible de expansión, planetalinux.org.
- MilMazz: ¿Por qué decidiste incluir a Venezuela como parte del Planeta Linux?, ¿alguna persona te pidio que lo hicieras?
- Damog: No. Personalmente tengo mucha relación con Venezuela, pues mi novia es de allá y tengo bastantes amigos, en el mundillo del software libre, allá. Quise lanzarlo por que empecé a conocer a gente que tenía un blog y llegó a un punto donde consideré pertinente lanzarlo, y donde la gente se interesaría por él. Mucha gente, hasta donde tengo entendido, ni siquiera sabe que está en el planeta. Como tú mismo, a muchas personas se han agregado teniendo conocimientos de ellos por terceras partes. Sin embargo, la forma de ver crecer un proyectito así es precisamente de boca en boca, de blog en blog.
- MilMazz: ¿Tienes pensado en el futuro incluir a mas paises?, si es así, ¿cuáles serían?
- Damog: Sí, la idea también era esa al iniciar con el dominio que usamos actualmente. Al principio creí que lo ideal sería empezar con México y Venezuela por razones ya explicadas, y además con Estados Unidos (sindicando a la gente latina que radica en ese país y que bloguea), usando la dirección us.planetalinux.org. Sin embargo, aún no se ha juntado suficiente gente para llevar a cabo tal subproyecto. En general cualquier país latinoamericano podría entrar mientras se junte suficiente gente y vaya creciendo como han ido creciendo los correspondientes a México y Venezuela. Creo que sería interesante seguirse luego con Brasil, donde hay una enorme actividad de software libre, o incluso en Argentina. Sin embargo, esto depende de la gente: Hace falta todavía escribir mucho contenido, hace falta escribir una especie de FAQ donde se explique qué pueden hacer si alguien quiere iniciar una instancia de Planeta Linux en un país donde no exista, hace falta hacer ese tipo de cosas y generar esos contenidos.
- MilMazz: Estaba por documentarme acerca de los lineamientos, al parecer el enlace de los lineamientos de Planeta Linux está roto por ahora, ¿cuáles serían los lineamientos que debe seguir un miembro del Planeta Linux?
- Damog: Bueno, como te digo, uno más de los contenidos inconclusos. Básicamente, los lineamientos establecerán algunos reglas o consejos, como que deberán hablar de Linux y Software Libre con cierta regularidad en su blog, que su feed debe ser válido, etc. Ese tipo de cosas.
- MilMazz: ¿Quienes pueden participar en el Planeta Linux?
- Damog: Cualquier persona que lleve un blog y toque periódicamente temas sobre Linux o Software Libre.
- MilMazz: ¿Deseas agregar algo más?
- Damog: Pues si alguien se quiere unir, es más que bienvenido. Simplemente escriban a la lista: [email protected] o suscríbanse.
Antes de culminar, quisiera agradecerle públicamente a José Parella por la sugerencia hecha a David Moreno Garza.
WordPress 2.0
Anoche comencé a realizar algunos cambios a este blog, entre ellos, actualizar la plataforma de publicación que lo gestiona, WordPress. He pasado de la versión 1.5.2 a la 2.0 (nombre clave Duke, en honor al pianista y compositor de Jazz Duke Ellington), estoy muy contento con el cambio puesto que el área administrativa ha sufrido muchos cambios para bien.
Por supuesto, aún faltán muchos detalles por arreglar, en el transcurso de la semana iré traduciendo el tema que posee actualmente la bitácora y algunos plugins que recien comienzo a utilizarlos.
El anuncio de la nueva versión, así como las características que incluye esta nueva versión de WordPress, puede encontrarlas en la entrada WordPress 2, publicada por Matt.
En verdad fué muy fácil la actualización, a mi me tomo solo unos cuantos minutos siguiendo la guía del Codex de WordPress, pero si prefieres una guía en castellano y muy completa te recomiendo leer el artículo Actualización de WordPress de 1.5.x a 2.0.
Año nuevo
Sé que es tarde para andar diciendo estas cosas, pero apenas el día de hoy es que he regresado a casa después de unas extensas vacaciones; lejos de las tentaciones, adicciones y demás perversiones a las que conduce el mundo de la informática ;).
Resumiendo la historía (porque debo ocuparme de leer una gran cantidad de correos, noticias en el agregador de feeds, responder algunos comentarios del blog, entre otras cosas), quisiera desearles a todos un Feliz Año 2006.
Proporcionando medios alternativos a las suscripciones RSS
Según un estudio de Nielsen//NetRatings, quienes se dedican al estudio de mercados y medios en internet, afirma que apenas el 11% de los lectores habituales de blogs, utilizan RSS (acrónimo de Sindicación Realmente Simple, Really Simple Syndication en inglés) para clasificar la lectura de la gran cantidad de blogs disponibles hoy día.
Del mismo estudio se desprende que apenas cerca del 5% de los lectores de blogs utiliza software de escritorio para leer sus suscripciones, mientras que un poco más del 6% utiliza un agregador en línea para ser notificado de los nuevos artículos existentes en los blogs.
A lo descrito previamente, tenemos que agregarle que se estima que el 23% de los lectores entiende lo qué es y para que sirven los RSS, pero en realidad no lo utilizan, mientras que el 66% de las personas en realidad no entienden de que trata la tecnología en discusión o nunca han escuchado de ella.
Ante esta situación, tendremos que buscar alternativas que quizás sean más efectivas que el uso de la sindicación de contenidos vía RSS para mantener informados a nuestros lectores acerca de los nuevos artículos disponibles en nuestras bitácoras.
¿Qué podemos hacer?, solamente tenemos que pensar en ofrecer un mecanismo alternativo, que sirva para que ese 89% pueda suscribirse a los contenidos que ofrecemos. En este artículo discutiremos sobre las suscripciones por correo electrónico.
Algunas ventajas del ofrecer suscripciones por correo son las siguientes:
- El usuario no necesita de una agregador de noticias, ya sea instalable en el escritorio o un servicio en línea. Lo anterior puede ser molesto o complejo para muchos usuarios.
- La mayoría de las personas reconocen lo que es un correo electrónico, incluso, manejan sus cuentas.
- Tanto teléfonos, como PDAs y otros dispositivos que pueden conectarse a la red pueden enviar y recibir correos electrónicos.
- El e-mail se ofrece como un medio alternativo en donde no es posible tener agregadores RSS.
- Puede realizar búsquedas de entradas antiguas, puesto que existen registros en su cuenta, tal cual como hace comúnmente con su correo electrónico.
- Hoy en día no deberiamos preocuparnos en borrar nuestros correos electrónicos, puesto que existen servicios que nos ofrecen gran capacidad de almacenamiento.
- Si el usuario lo desea, ¿por qué no ofrecerle otro medio de suscripción?.
Existen varios servicios que nos facilitan el ofrecer suscripciones a nuestros blogs por medio del correo electrónico. En este artículo discutiremos acerca de FeedBlitz.
FeedBlitz, es un servicio que convierte tus feeds (RSS y ATOM) en un correo electrónico y procederá a enviarlo a todas aquellas personas que se suscriban a este servicio.
Si estás familiarizado con el concepto de newsletter, puedes verlo como tal, pero el contenido de dicho newsletter son las entradas de los blogs a los que estás suscrito.
Algunos puntos que me parecen favorables del servicio es que el proceso de suscripción es muy sencillo, simplemente debe rellenarse un campo en el formulario, esto automáticamente registrará a los usuarios siempre y cuando estos sean nuevos con el servicio, generará una contraseña aleatoria para su cuenta. El usuario deberá simplemente responder al e-mail enviado por FeedBlitz y ¡eso es todo!. Con lo anterior nos aseguramos de obtener una cuenta de correo válida, este modo de verificación es común en muchos servicios que se ofrecen en la red.
Otro punto que me gusta de FeedBlitz es que te envia un solo correo diario, con el contenido actual de los blogs a los que estás suscrito, esto no lo hace por ejemplo RssFwd, el cual te envia un correo por cada nueva entrada existente en los blogs a los cuales estás suscrito, esto puede resultar frustrante (sobretodo en blogs muy activos) para muchos usuarios, me incluyo.
Además, FeedBlitz esta totalmente integrado con FeedBurner, servicio que utilizo para gestionar los RSS de esta bitácora.
Desde FeedBlitz puedes elegir el formato (Texto o HTML) en el que prefieras recibir las notificaciones en tu cuenta de correo electrónico.
¿No le gusto el servicio que ofrece FeedBlitz?, usted en cualquier momento puede dejar de recibir las notificaciones vía correo electrónico, en cada mensaje tiene la información necesaria para darse de baja del servicio.
LinuxMag
Después de concretar algunas negociaciones con la imprenta sale la primera edición de LinuxMag, la primera revista impresa orientada a los fanáticos de GNU/Linux en mi ciudad, por ahora la distribución es local, esperemos la mayor receptividad posible y esperamos expander, tanto en contenido como en número de ejemplares, nuestras ediciones posteriores.
Nuestra portada este mes.
¿Le ha parecido interesante lo que ha visto?, le invito a seguirnos de cerca. Si desea saber un poco más acerca de nosotros, puede consultar el uso de esta herramienta para generar covers de revistas y obtendrá muchas respuestas.
Antes de finalizar, debo agradecer públicamente a José Vicente Nuñez Zuleta, nos brindó su apoyo incondicional, este proyecto no se hubiese llevado a cabo sin su ayuda.
Versión Previa a Kubuntu Breezy
Una vez hecho el anuncio de la versión previa a Ubuntu 5.10 (Breezy Badger), era de esperarse otro anuncio por parte del proyecto relacionado Kubuntu.
¿Qué hay de nuevo en esta versión?
-
KDE 3.4.2
-
OpenOffice 2 (Beta 2)
-
X.org 6.8.2
Se incluyen otras características tentadoras, como por ejemplo editores de imágenes, una mejora en la usabilidad para el manejo de las preferencias del sistema, entre otras.
Al igual que Ubuntu, la versión previa a la salida oficial de Kubuntu Breezy está disponible tanto en CD instalable como en en LiveCD para tres arquitecturas: x86 (PC), AMD64 (PC 64 bits) y PowerPC (Mac).
Puede descargar la imagen de esta versión en Kubuntu 5.10 (Breezy Badger) Preview. Recuerde usar en la medida de lo posible BitTorrent, para evitar la sobrecarga del servidor.
Si lo desea, puede ver el anuncio de esta versión previa.
Primer Congreso Nacional de Software Libre
El día de hoy se dió inicio en Mérida al Primer Congreso Nacional de Software Libre, el cual es auspiciado por el Grupo de Usuarios de GNU/Linux de Venezuela UNPLUG. El objetivo de este congreso es promocionar el uso, implementación, características y posibilidades del Software Libre en Venezuela, generando una estructura de soporte y apoyo a los diferentes Grupos de Usuarios de GNU/Linux y Software Libre en todo el territorio nacional.
Las charlas de día de hoy han sido:
- El Software Libre y GNU/Linux, Ponente: Octavio Rossell
- Diseño Gráfico Digital en Software Libre, Ponente: Leonardo Caballero
- ¿Por qué Open Office es la alternativa?, Ponente: Joskally Carrero
- La respuesta está en el Software Libre, Ponente: Francisco Palm
- Sistemas de Información Geográfica en GNU, Ponente: Damian Fossi
Las charlas del día de mañana serán:
- Fábrica del Software Libre, Ponente: Javier Riviera
- Software Libre como palanca para el desarrollo endógeno, Ponente: Mariángela Petrizzo
- El Software Libre en la Educación Universitaria, Ponente: Samuel Rojas
- Redes Inalámbricas bajo Software Libre, Ponente: Walter Vargas
- Metodología de Migración hacia el Software Libre, Ponente: Jorge González
- El escritorio en GNU/Linux, Ponente: Vladimir Llanos
Según anuncio Octavio Rossell al finalizar la jornada del día de hoy, la entrada el día de mañana será libre al público en general. La jornada del día de mañana comenzará a las 9:00 a.m. hora local.
En los próximos días trataré hacer un resúmen acerca de las charlas, ya estoy tomando notas.
General
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
Identificar el Hardware de tu PC en Debian GNU/Linux
Bien, lo que vamos a hacer a continuación es muy fácil, tán fácil como instalar un paquete, luego ejecutarlo y leer la información que él nos “escupe” (me encanta como suena :) ). Como sabrán, soy usuario de Debian GNU/Linux en su versión Etch para la arquitectura AMD64, pero ésto en realidad no es tan relevante ya que el paquete se encuentra tanto en Testing como en Stable para la mayoría de las arquitecturas y en la sección main de los repositorios.
Lo que vamos a instalar es el paquete lshw-gtk, que bien como dice en la descripción del paquete: “es una pequeña herramienta que provee información detallada de la configuración de hardware de la máquina. Puede reportar la configuración exacta de la memoria, versión de firmware, configuración de la tarjeta madre, versión del procesador y su velocidad, configuración de la caché, velocidad del bus, etc. en sistemas x86 con soporte DMI, en algunas máquinas PowerPC (se sabe de su funcionamiento en las PowerMac G4) y ADM64”.
Como ya sabrán, para instalar el paquete es tan sencillo como abrir una terminal y escribir en modo superusuario los siguiente:
# aptitude install lshw-gtk
El paquete no es muy pesado, de hecho, con todo y dependencias a penas ha de superar el mega de información, por lo que el proceso de instalación es rápido (si se tiene una conexión decente claro).
Una vez instalado el paquete no tenemos que hacer más que ejecutarlo. Para poder ejecutarlo debemos hacerlo desde una terminal, ya que según tengo entendido, no se instala en los menús del Gnome. Así que debemos escribir en una terminal (en modo superusuario):
# lshw-gtk
y listo, se ejecutará perfectamente, dejándonos navegar por unos paneles donde se encuentran los distintos componentes de nuestro sistema.
Si lo que quieres es tener un lanzador en los menús del Gnome, es muy sencillo, sólo deberás crear uno de la siguiente manera. Abre una terminal en modo superusuario y escribe lo siguiente:
gedit /usr/share/applications/LSHW.desktop
luego de presionar la tecla Enter se abrirá una ventana con el gedit en la cual deberás pegar el siguiente texto:
[Desktop Entry]
Name=LSHW
Comment=Identifica el hardware del sistema
Exec=gksu lshw-gtk
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya con eso deberías tener tu lanzador en el menú Aplicaciones –> Herramientas del sistema. Vas a necesitar de permisos de superusuario para poder ejecutarlo.
Acá una imagen de como se ve el lshw-gtk:
GoogleEarth en Etch AMD64
Hace días pude darme cuenta que el paquete para instalar Google Earth en Debian se encuentra en los repositorios (en la sección [Contrib]). Debo detenerme un momento acá para mencionar que el paquete googleearth-package es Software Libre, sin embargo, depende de Google Earth que es total y absolutamente Software Propietario, por lo tanto deberás estár dispuesto a “ensuciar” un poco tu Debian.
Bien, hasta ahora sólo he mencionado que el paquete está en los repositorios bla bla bla, pero no he mencionado algo MUY importante, y es que, éste paquete (googleearth-package) no hace nada más que adornar (al menos por los momentos) los repositorios, ya que si se ubican en la sección de descargas de Google Earth se podrán dar cuenta que no existen binarios para la arquitectura AMD64, por lo cual tendrán que crear un chroot para poder correr la versión disponible (la de 32bits). Otra cosa MUY pero MUY importante que debo hacer es recomendarles que, por favor, le echen un vistazo a los requerimiento mínimos para que no tengan una mala experiencia en lo que a ejecutar el Google Earth refiere.
Una vez que han creado el chroot, el primer paso sería instalar el paquete googleearth-packages, lo cual se puede lograr con la siguiente línea de comandos en una terminal:
# aptitude install googleearth-package
Ésto también lo pueden hacer por el Gestor de Paquetes Synaptic sin ningún problema, es cuestión de gustos y costumbres. Cuando vayan a instalar el googleearth-package, el apt posiblemente les sugiera instalar también el paquete fakeroot, ésta sugerencia deberán aceptarla ya que, el fakeroot es necesario para poder construir el .deb de google-earth que vamos a instalar; él (fakeroot) básicamente lo que hace es quitar la necesidad de trabajar como root para poder construir paquetes. También el apt puede hacerle otras muchas sugerencias, sobre todo si el chroot está recién creado.
Una vez que se haya instalado todo, procedemos a descargar el binario de Google Earth de la página. Éste paso queda a juicio del lector, ya que puede descargarlo como se le de la antojada gana; en lo personal, lo hice utilzando la utilidad wget (Debian definitely rulez!) con la siguiente línea de comandos:
# wget http://dl.google.com/earth/GE4/GoogleEarthLinux.bin
Por cierto, ésa la URL para la descarga :).
Cuando haya terminado la descarga (el binario ha de “pesar” unos 20 Mb aproximadamente) lo siguiente que hacemos es construir el paquete, lo cual logramos con un simple:
# make-googleearth-package
Y básicamente ése es todo el proceso para construir el .deb. Lo único que faltaría sería instalarlo (casi nada jeje), pero eso es tan fácil como hacer en la terminal:
# dpkg -i googleearth_4.0.2723.0-1_i386.deb
Cuando ejecutes Google Earth el programa quizá te llame la atención diciéndote que no tienes instalada la fuente Bitstream Vera, pero ésto no es problema alguno ya que el programa corre perfectamente (al menos en mi caso :)); de todas formas para instalar la fuente es tan simple como hacer en una terminal:
# aptitude install ttf-bitstream-vera
En éste momento ya debería estar todo instalado en su máquina. Que lo disfruten! Aquí un vistazo del Google Earth corriendo en mi PC:
Muere Rob Levin
Rob Levin, el fundador de Freenode, ha muerto trágicamente luego de estar en coma debido a un accidente que sufrió mientras manejaba su bicicleta. Al parecer Levin fué arroyado por un vehículo el pasado 12 de septiembre mientras manejaba su bici y como consecuencias sufrió heridas graves. Estaba siendo tratado en un hospital local en Houston, Texas en el cual falleció el día de ayer.
Nuestras más sinceras condolencias a la familia de éste pionero.
Para enviar sus condolencias puede hacerlo a [email protected]
Recuperar el Terminal después de ejecutar un comando en primer plano
Si regularmente ejecuta programas desde el Terminal, seguramente en alguna
ocasión habrá olvidado añadirle al final del comando un carácter &, por si no
lo sabe, el uso del carácter & permite ejecutar el comando en segundo plano,
por lo tanto, podrá seguir utilizando el Terminal para llevar a cabo otras
actividades.
Si por casualidad se encuentra ante la situación descrita en el párrafo
anterior, existe una solución rápida y efectiva, después de ejecutar el comando
desde el Terminal sin el carácter & presione la combinación de teclas Ctrl + Z
dentro del mismo Terminal, esto permitirá detener (más no cancelar) el
programa que ha ejecutado previamente, para reanudar la ejecución del programa
use el comando bg.
Veamos un ejemplo para aclarar las posibles dudas.
milmazz@omega:~$ gaim
[1]+ Stopped gaim
milmazz@omega:~$ bg
[1]+ gaim &
El comando bg permite ejecutar el programa que se encontraba detenido en
segundo plano, es decir, como si desde el principio hubiese ejecutado el
programa de la siguiente manera:
$ gaim &
Este tip me ha servido en muchas ocasiones, espero lo encuentre útil al igual que yo.
LinuxMag
Después de concretar algunas negociaciones con la imprenta sale la primera edición de LinuxMag, la primera revista impresa orientada a los fanáticos de GNU/Linux en mi ciudad, por ahora la distribución es local, esperemos la mayor receptividad posible y esperamos expander, tanto en contenido como en número de ejemplares, nuestras ediciones posteriores.
Nuestra portada este mes.
¿Le ha parecido interesante lo que ha visto?, le invito a seguirnos de cerca. Si desea saber un poco más acerca de nosotros, puede consultar el uso de esta herramienta para generar covers de revistas y obtendrá muchas respuestas.
Antes de finalizar, debo agradecer públicamente a José Vicente Nuñez Zuleta, nos brindó su apoyo incondicional, este proyecto no se hubiese llevado a cabo sin su ayuda.
Bienvenid@
Antes que nada quisiera darles la bienvenida a todos los que visitan este humilde weblog, trataré tocar temas diversos, pero que realmente me atraen, algunos de estos temas son los siguientes:
- Tecnología
- Internet
- Software Libre
- GNU/Linux
Adicionalmente comentaré mi experiencia personal en algunas distribuciones de GNU/Linux, espero poder aprender con ustedes y hacer de esto una experiencia muy grata.
Como referencia de mi trabajo pueden leer ciertos artículos que he redactado para BdW, anteriormente manejaba un pequeño weblog en Blogger, pero lo tenía muy descuidado para ser sincero. Al comenzar a interesarme en el mundo del desarrollo web, comencé utilizando Macromedia Dreamweaver, el cual, llegue a dominar bastante bien en su momento, debido a esto, decidí comenzar una especie de guía acerca de los Fundamentos de Macromedia Dreamweaver MX, esta guía estaba orientada hacia los usuarios no iniciados, gracias a esta actividad comencé a documentarme y a preocuparme por el seguimiento de los estándares web y mantener la separación entre el contenido, la presentación y los comportamientos en los documentos HTML/XHTML, espero poder seguir aprendiendo, porque apenas estoy comenzando.
Python
Mejoras en el comportamiento a la hora de eliminar un ForeignKey
 Cuando un objeto referenciado por una clave foránea (
Cuando un objeto referenciado por una clave foránea (ForeignKey) es eliminado, Django por omisión emula el comportamiento de la sentencia SQL ON DELETE CASCADE y también se elimina el objeto que contiene el ForeignKey.
A partir de la versión 1.3 de Django el comportamiento descrito en el párrafo anterior puede ser sobreescrito al especificar el argumento on_delete. Por ejemplo, si usted permite que una clave foránea pueda ser nula y usted desea que sea establecida a NULL cuando un objeto referenciado sea eliminado:
user = models.ForeignKey(User, blank=True, null=True, on_delete=models.SET_NULL)Los posibles valores para el argumento on_delete pueden encontrarse en django.db.models:
- CASCADE: Eliminación en cascada, el comportamiento por omisión.
- PROTECT: Prevee la eliminación del objeto referenciado al lanzar una excepción del tipo:
django.db-IntegrityError. - SET_NULL: Establece la clave foránea a
NULL, esto solo es posible si el argumentonullesTrue. - SET_DEFAULT: Establece la clave foránea a su valor por omisión, tenga en cuenta que un valor por omisión debe ser establecido.
- SET(): Establece el valor del
ForeignKeyindicado enSET(), si una función es invocada, el resultado de dicha función será el valor establecido. - DO_NOTHING: No tomar acciones. Si el gestor de base de datos requiere integridad referencial, esto causará una excepción del tipo
IntegrityError.
A continuación un par de ejemplos de esta nueva funcionalidad:
# models.py
from django.db import models
class Author(models.Model):
nickname = models.CharField(max_length=32)
def __unicode__(self):
return self.nickname
class Post(models.Model):
author = models.ForeignKey(Author, blank=True, null=True, on_delete=models.SET_NULL)
title = models.CharField(max_length=128)
def __unicode__(self):
return self.titleNuestra sesión interactiva con el API sería similar a la siguiente:
$ python manage.py shell
>>> from ondelete.models import Author, Post
>>> Author.objects.all()
[]
# Creamos el autor
>>> author = Author(nickname='milmazz')
# Guardamos el objeto en la base de datos al usar de manera explícita el método save()
>>> author.save()
# Obtenemos el autor en base a su id
>>> Author.objects.get(pk=1)
<Author: milmazz>
# Creamos par de artículos
>>> article1 = Post(author=author, title="Article 1")
>>> article1.save()
>>> article2 = Post(author=author, title="Article 2")
>>> article2.save()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.author))
Article 1 by milmazz
Article 2 by milmazz
# Eliminamos el autor
>>> author.delete()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.author))
Article 1 by None
Article 2 by NoneUn segundo ejemplo, ahora haciendo uso del valor SET() en el argumento on_delete:
# models.py
from django.db import models
from django.contrib.auth.models import User
def get_superuser():
return User.objects.get(pk=1)
class Post(models.Model):
user = models.ForeignKey(User, on_delete=models.SET(get_superuser))
title = models.CharField(max_length=128)
def __unicode__(self):
return self.titleNuestra sesión interactiva con el API sería similar a la siguiente:
$ python manage.py shell
>>> from ondelete.models import Post
>>> from django.contrib.auth.models import User
>>> User.objects.all()
[<User: milmazz>]
# Creamos un nuevo usuario
>>> author = User(username='milton')
# Guardamos el objeto en la base de datos,
# de manera explícita al invocar el método save()
>>> author.save()
# Vista de los usuarios registrados en la base de datos
>>> User.objects.all()
[<User: milmazz>, <User: milton>]
# Creamos par de artículos
>>> article1 = Post(user=author, title="Article 1")
>>> article1.save()
>>> article2 = Post(user=author, title="Article 2")
>>> article2.save()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.user))
Article 1 by milton
Article 2 by milton
# Eliminamos el usuario 'milton'
>>> author.delete()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.user))
Article 1 by milmazz
Article 2 by milmazzPylint: Análisis estático del código en Python
Básicamente el análisis estático del código se refiere al proceso de evaluación del código fuente sin ejecutarlo, es en base a este análisis que se obtendrá información que nos permita mejorar la línea base de nuestro proyecto, sin alterar la semántica original de la aplicación.
Pylint es una herramienta que todo programador en Python debe considerar en su proceso de integración continua (Ej. Bitten), básicamente su misión es analizar código en Python en busca de errores o síntomas de mala calidad en el código fuente. Cabe destacar que por omisión, la guía de estilo a la que se trata de apegar Pylint es la descrita en el PEP-8.
Es importante resaltar que Pylint no sustituye las labores de revisión continua de alto nivel en el Proyecto, con esto quiero decir, su estructura, arquitectura, comunicación con elementos externos como bibliotecas, diseño, entre otros.
Tome en cuenta que Pylint puede arrojar falsos positivos, esto puede entenderse al recibir una alerta por parte de Pylint de alguna cuestión que usted realizó conscientemente. Ciertamente algunas de las advertencias encontradas por Pylint pueden ser peligrosas en algunos contextos, pero puede que en otros no lo sea, o simplemente Pylint haga revisiones de cosas que a usted realmente no le importan. Puede ajustar la configuración de Pylint para no ser informado acerca de ciertos tipos de advertencias o errores.
Entre la serie de revisiones que hace Pylint al código fuente se encuentran las siguientes:
- Revisiones básicas:
- Presencia de cadenas de documentación (docstring).
- Nombres de módulos, clases, funciones, métodos, argumentos, variables.
- Número de argumentos, variables locales, retornos y sentencias en funciones y métodos.
- Atributos requeridos para módulos.
- Valores por omisión no recomendados como argumentos.
- Redefinición de funciones, métodos, clases.
- Uso de declaraciones globales.
- Revisión de variables:
- Determina si una variable o
importno está siendo usado. - Variables indefinidas.
- Redefinición de variables proveniente de módulos builtins o de ámbito externo.
- Uso de una variable antes de asignación de valor.
- Determina si una variable o
- Revisión de clases:
- Métodos sin
selfcomo primer argumento. - Acceso único a miembros existentes vía
self - Atributos no definidos en el método
__init__ - Código inalcanzable.
- Métodos sin
- Revisión de diseño:
- Número de métodos, atributos, variables locales, entre otros.
- Tamaño, complejidad de funciones, métodos, entre otros.
- Revisión de imports:
- Dependencias externas.
-
imports relativos o importe de todos los métodos, variables vía
*(wildcard). - Uso de imports cíclicos.
- Uso de módulos obsoletos.
- Conflictos entre viejo/nuevo estilo:
- Uso de
property,__slots__,super. - Uso de
super.
- Uso de
- Revisiones de formato:
- Construcciones no autorizadas.
- Sangrado estricto del código.
- Longitud de la línea.
- Uso de
<>en vez de!=.
- Otras revisiones:
- Notas de alerta en el código como
FIXME,XXX. - Código fuente con caracteres non-ASCII sin tener una declaración de encoding. PEP-263
- Búsqueda por similitudes o duplicación en el código fuente.
- Revisión de excepciones.
- Revisiones de tipo haciendo uso de inferencia de tipos.
- Notas de alerta en el código como
Mientras Pylint hace el análisis estático del código muestra una serie de mensajes así como también algunas estadísticas acerca del número de advertencias y errores encontrados en los diferentes ficheros. Estos mensajes son clasificados bajo ciertas categorías, entre las cuales se encuentran:
- Refactorización: Asociado a una violación en alguna buena práctica.
- Convención: Asociada a una violación al estándar de codificación.
- Advertencia: Asociadas a problemas de estilo o errores de programación menores.
- Error: Asociados a errores de programación importantes, es probable que se trate de un bug.
- Fatal: Asociados a errores que no permiten a Pylint avanzar en su análisis.
Un ejemplo de este reporte lo puede ver a continuación:
Messages by category
--------------------
+-----------+-------+---------+-----------+
|type |number |previous |difference |
+===========+=======+=========+===========+
|convention |969 |1721 |-752.00 |
+-----------+-------+---------+-----------+
|refactor |267 |182 |+85.00 |
+-----------+-------+---------+-----------+
|warning |763 |826 |-63.00 |
+-----------+-------+---------+-----------+
|error |78 |291 |-213.00 |
+-----------+-------+---------+-----------+
Cabe resaltar que el formato de salida del ejemplo utilizado está en modo texto, usted puede elegir entre: coloreado, texto, msvs (Visual Estudio) y HTML.
Pylint le ofrece una sección dedicada a los reportes, esta se encuentra inmediatamente después de la sección de mensajes de análisis, cada uno de estos reportes se enfocan en un aspecto particular del proyecto, como el número de mensajes por categorías (mostrado arriba), dependencias internas y externas de los módulos, número de módulos procesados, el porcentaje de errores y advertencias encontradas por módulo, el total de errores y advertencias encontradas, el porcentaje de clases, funciones y módulos con docstrings y su respectiva comparación con un análisis previo (si existe). El porcentaje de clases, funciones y módulos con nombres correctos (de acuerdo al estándar de codificación), entre otros.
Al final del reporte arrojado por Pylint podrá observar una puntuación general por su código, basado en el número y la severidad de los errores y advertencias encontradas a lo largo del código fuente. Estos resultados suelen motivar a los desarrolladores a mejorar cada día más la calidad de su código fuente.
Si usted ejecuta Pylint varias veces sobre el mismo código, podrá ver el puntaje de la corrida previa junto al resultado de la corrida actual, de esta manera puede saber si ha mejorado la calidad de su código o no.
Global evaluation
-----------------
Your code has been rated at 7.74/10 (previous run: 4.64/10)
If you commit now, people should not be making nasty comments about you on c.l.py
Una de las grandes ventajas de Pylint es que es totalmente configurable, además, se pueden escribir complementos o plugins para agregar una funcionalidad que nos pueda ser útil.
Si usted quiere probar desde ya Pylint le recomiendo seguir la guía introductoria descrita en Pylint tutorial. Si desea una mayor ayuda respecto a los códigos indicados por Pylint, puede intentar el comando pylint --help-msg=CODIGO, si eso no es suficiente, le recomiendo visitar el wiki PyLint Messages para obtener una rápida referencia de los mensajes arrojados por Pylint, organizados de varias maneras para hacer más fácil y agradable la búsqueda. Además de encontrar explicaciones de cada mensaje, especialmente útiles para aquellos programadores que recién comienzan en Python.
Referencias
Charla: Desarrollo web en Python usando el framework Django
El profesor Jacinto Dávila, en el marco de actividades del Jueves Libre, me ha invitado a dar una charla sobre Desarrollo web en Python usando el framework Django para el día de mañana, 20 30 de noviembre de 2006, el sitio de la charla será en el salón OS-02 del edificio B de la facultad de ingeniería, sector La Hechicera, a partir de las 11:00 a.m.
Básicamente estaré conversando sobre nuevas metodologías de desarrollo Web, el uso de frameworks, ¿en realidad promueven mejores prácticas de desarrollo?, acerca del modelo MVC y el principio DRY (Don’t Repeat Yourself).
A manera de introducción les dejo lo siguiente.
Django es un framework de alto nivel escrito en el lenguaje de programación Python con el objetivo de garantizar desarrollos web rápidos y limpios, con un diseño pragmático.
Un framework orientado al desarrollo Web es un software que facilita la implantación de aquellas tareas tediosas que se encuentran al momento de la construcción de un sitio de contenido dinámico. Se abstraen problemas inherentes al desarrollo Web y se proveen atajos en la programación de tareas comunes.
Con Django, usted construirá sitios web en cuestion de horas, no días; semanas, no años. Cada una de las partes del framework Django ha sido diseñada con el concepto de productividad en mente.
Django sigue la arquitectura MVC (Modelo-Vista-Controlador), en términos simples, es una manera de desarrollo de software en donde el código para definir y acceder a los datos (el modelo) se encuentra separado de la lógica de negocios (el controlador), a su vez está separado de la interfaz de usuario (la vista).
El framework Django ha sido escrito en Python, un lenguaje de programación interpretado de alto nivel que es poderoso, dinámicamente tipado, conciso y expresivo. Para desarrollar un sitio usando Django, debemos escribir código en Python, haciendo uso de las librerías de Django.
Finalmente, Django mantiene de manera estricta a lo largo de su propio código un diseño limpio, y le hace seguir las mejores prácticas cuando se refiere al desarrollo de su aplicación Web.
En resumen, Django facilita el hacer las cosas de manera correcta.
Para finalizar, espero poder hacer una demostración en vivo, ya que el tiempo que dispongo no es mucho.
FeedJack: Ya está disponible
Ya había comentado acerca de ésta aplicación en la entrada FeedJack: Un Planet con esteroides, resulta que hace pocos días Gustavo Picón anunció la salida de la versión 0.9.6 bajo licencia BSD. Algunas de las características más resaltantes de esta aplicación son:
- Soporte de virtual hosts: Esto quiere decir que desde la misma instalación y la misma Base de Datos e interfaz de administración, se manejan múltiples planetas. Si hay feeds en común estos se bajan una sola vez para optimizar recursos.
- Temas (Themes): Cada sitio (virtual host) puede tener temas distintos.
- Soporte de folcsonomías (etiquetas o tags): Muy popular en las aplicaciones de la Web 2.0, se ha optimizado el algoritmo.
- Generación de páginas o feeds por folcsonomías: http://www.chichaplanet.org/tag/django/
- Generación de páginas o feeds por miembros: http://www.chichaplanet.org/user/1/
- Generación de páginas o feeds de una categoría en especial de un miembro particular: http://www.chichaplanet.org/user/1/tag/django/
- Generar un feed general: http://www.chichaplanet.org/feed/
- Histórico de entradas: Entre muchas otras cosas. La principal ventaja frente a Planet es el soporte de un histórico de entradas o posts, por el uso de una Base de Datos.
Para conocer los detalles acerca de los requerimientos, el proceso de instalación, configuración y la modificación de los temas lea con detenimiento la entrada Feedjack - A Django+Python Powered Feed Aggregator (Planet).
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
FeedJack: Un Planet con esteroides
FeedJack es una mejora hecha por Gustavo Picon (a.k.a. tabo) del muy conocido Planet, la mejor muestra de la funcionalidad de este software se puede apreciar en el planeta peruano ChichaPlanet.
Gustavo Picon, autor del reemplazo del Planet en Django, afirma que el código fuente todavía no está disponible, pero piensa hacerlo público bajo el esquema de código abierto tan pronto logre depurarlo un poco y redacte cierta documentación, coincido con el autor cuando éste afirma que: si un software no posee documentación, no existe.
FeedJack ofrece algunas características que le dan cierta ventaja sobre el Planet, algunas de ellas son:
- Maneja datos históricos. Por lo tanto, usted puede leer entradas antiguas.
- Realiza un análisis más exhaustivo de las entradas, incluyendo sus categorías.
- Es capaz de generar páginas de acuerdo a las categorías de las entradas.
- Brinda soporte al sistema de folcsonomías (etiquetas), opción muy popular en la Web 2.0.
- Utiliza el lenguaje de plantillas de Django
Mayor información y detalle en la entrada Django powered chicha planet with feedjack, de Gustavo Picon.
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
Python Sidebar
Para aquellos que al igual que yo comienzan en el mundo de la programación en Python, siempre es recomendable tener un acceso rápido y sencillo a la documentación de referencia, esto es posible realizarlo a través de la utilidad Python Sidebar.
Además, con Python Sidebar, podrá realizar búsquedas en sitios relacionados con Python y listas de correo.
Esta herramienta está disponible para la familia de navegadores de la Fundación Mozilla.
Local
gUsLA: Grupo de Usuarios de Software Libre de la Universidad de Los Andes
Un grupo de compañeros de estudio y mi persona por fin hemos iniciado una serie de actividades para formar el Grupo de Usuarios de Software Libre de la Universidad de Los Andes.
El día de hoy, hicimos entrega de una carta al Consejo de Escuela de Ingeniería de Sistemas, solicitando un aval académico para lograr llevar a cabo las siguientes actividades:
- Charlas.
- Festivales de instalación.
- Atención al usuario.
- Otras actividades de naturaleza académica.
Esta solicitud la hicimos ya que consideramos necesaria la creación de un Grupo de Usuarios que se encargue de:
- Difundir y promover el Software Libre en la Universidad de los Andes.
- Difundir las bases filosóficas detrás del modelo del Software Libre.
- Demostrar la calidad técnica del Software Libre.
- Demostrar a los usuarios finales cuan fácil es utilizar GNU/Linux.
- Fomentar el intercambio de conocimientos en Talleres, Foros, Charlas y/o encuentros con grupos de usuarios de otras latitudes.
- Adaptación al proceso de cambio fomentado por el ente público (decreto 3390).
En este momento hemos contactado a ciertos profesores que han mostrado interés en la iniciativa, la idea es involucrar a todas aquellas personas relacionadas con la Universidad de Los Andes.
En resumen, el objetivo principal que pretende alcanzar nuestro grupo es: El estudio, desarrollo, promoción, difusión, educación, enseñanza y uso de sistemas operativos GNU/Linux, GNU/Hurd, FreeBSD, y de las herramientas libres que interactúan con estos, tanto en el ámbito nacional como en el internacional. Es importante resaltar en este instante que No se perseguirán fines de lucro, ni tendremos finalidades o actividades políticas, partidistas ni religiosas; seremos un grupo apolítico, abierto, pluralista y con fines académicos.
Personalmente, debo agradecer a José Parrella por haberme facilitado un borrador del documento constitutivo/estatutario del Grupo de Usuarios de Linux de la Universidad Central de Venezuela (UCVLUG), lo hemos utilizado como base para formar el nuestro, aunque será discutido por ahora en una lista privada de estudiantes y profesores que han manifestado interés en participar.
Esperamos con ansiedad la decisión del Consejo de Escuela de Ingeniería de Sistemas.
Decisión del Consejo de Facultad de la Universidad de Los Andes
Según informa la profesora Flor Narciso en un comunicado, el Consejo de Facultad de la Universidad de Los Andes en una sesión ordinaria llevada a cabo el día de ayer, 13 de Junio de 2006, se aprobó la reprogramación del semestre.
Esta noticia toma por sorpresa a muchas personas, me incluyo, imagínense tener que asistir a clases cinco sábados seguidos para lograr culminar las actividades el día 21 de Julio de 2006, por supuesto, debemos agradecerles a todos esos revolucionarios que generaron caos en la ciudad por esta decisión del Consejo de Facultad, en verdad, ¡muchas gracias!.
Los días 17, 24 de Junio y los días 1, 8 y 15 de Julio las clases se dictarán en el mismo horario, correspondiente a los días Lunes, Martes, Miércoles, Jueves y Viernes respectivamente.
La fecha que corresponde a la finalización de las evaluaciones queda para el día 21 de Julio de 2006.
Todas asignaturas con proyectos, en mi caso 4, la entrega de los mismos será realizada el día 4 de Septiembre de 2006.
Las notas definitivas serán dadas a conocer en el intervalo comprendido del 4 al 8 de Septiembre de este mismo año.
Ya para culminar, en definitiva, citando al profesor y amigo Richard Márquez: Se pasaron…
XXXII Aniversario EISULA
Según lo manifiesta la profesora Flor Narciso en un comunicado, el día de mañana, 14/06/2006, se celebrará una misa conmemorativa del XXXII Aniversario de la Escuela de Ingeniería de Sistemas a las 9:00 a.m. en la Sala de Reuniones de la Escuela.
Además, en el horario comprendido de 4:00 a 6:00 p.m. se llevará a cabo el seminario titulado Técnicas Emergentes en Automatización Industrial a cargo de los ingenieros Jesús Durán, Lisbeth Pérez y Jorge Vento.
El seminario se realizará en el Auditorio A de la Facultad de Ingeniería de la Universidad de Los Andes.
Están todos cordialmente invitados a participar en estas actividades.
Amigas se unen a la blogocosa
Así como lo indica el título de esta entrada, dos mujeres muy importantes en mi vida, se unen a la blogocosa, la primera, mi novia Ana Rangel, la segunda es mi querida amiga Gaby Márquez, ambas comparten conmigo estudios en la carrera de Ing. de Sistemas en la Universidad de Los Andes, espero que realmente inviertan tiempo a esta tarea. Estaré atento a sus artículos y trataré de darles ánimo.
Ana y Gaby, bienvenidas a la blogocosa.
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
Charla: Libre como un Mercado Libre
El Consejo de Computación Académica, la Corporación Parque Tecnológico de Mérida y el Centro Nacional de Cálculo Científico de la Universidad de Los Andes, invitan a la charla Libre como un Mercado Libre, cuyo ponente será el Profesor Jacinto Dávila.
El objetivo de la charla básicamente es el siguiente:
En esta presentación, pretendemos argumentar en favor de “libre como en el mercado libre”, una manera quizás desesperada de enfatizar el valor social del nuevo espacio para los negocios que se abre con el Software Libre. El Software Libre no es software gratis. De hecho, quienes desarrollen así pueden seguir cobrando lo que quieran por su trabajo, siempre que no impidan que otros conozcan los códigos fuentes, los usen y los compartan sin restricciones. Lamentablemente, las animosidades, sobretodo las políticas, están nublando toda discusión al respecto y destrozando el mayor logro del software libre: devolver a los tecnólogos a la especie humana.
Información adicional:
- Fecha: Jueves 2 de Marzo.
- Hora: 2:30 pm.
- Lugar: Núcleo La Hechicera, Facultad de Ciencias, Nivel Patio, Salón A9.
- Costo: Entrada Libre.
Algunas referencias que se recomienda leer.
- Petróleo por Software: La energía de los hidrocarburos y la apuesta a futuro con el Software Libre.
- El Copyleft es derechista (también)
Ambos artículos escritos por el profesor Jacinto Dávila.
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
Programación
Enviando correos con Perl
Regularmente los administradores de sistemas requieren notificar, vía correo electrónico, a sus usuarios de ciertos cambios o nuevos servicios disponibles. La experiencia me ha indicado que el usuario aprecia más un correo personalizado que uno general. Sin embargo, lograr lo primero de manera manual es bastante tedioso e ineficaz. Por lo tanto, es lógico pensar en la posibilidad de automatizar el proceso de envío de correos electrónicos personalizados, en este artículo, explicaré una de las tantas maneras de lograrlo haciendo uso del lenguaje de programación Perl.
En CPAN podrá encontrar muchas alternativas, recuerde el
principio
TIMTOWTDI.
Sin embargo, la opción que más me atrajo fue MIME::Lite:TT, básicamente este
módulo en Perl es un wrapper de MIME::Lite que le permite el uso de
plantillas, vía Template::Toolkit, para el cuerpo del mensaje del correo
electrónico. También puede encontrar MIME::Lite::TT::HTML que le permitirá
enviar correos tanto en texto sin formato (MIME::Lite::TT) como en formato
HTML. Sin embargo, estoy en contra de enviar correos en formato HTML, lo dejo a
su criterio.
Una de las ventajas de utilizar Template::Toolkit para el cuerpo del mensaje
es separar en capas nuestra script, si se observa desde una versión muy
simplificada del patrón
MVC, el
control de la lógica de programación reside en el script en Perl, la plantilla
basada en Template Toolkit ofrecería la vista de los datos, de modo tal que
podríamos garantizar que la presentación está separada de los datos, los cuales
pueden encontrarse desde una base de datos o un simple fichero CSV. Otra ventaja
evidente es el posible reuso de componentes posteriormente.
Un primer ejemplo del uso de MIME::Lite:TT puede ser el siguiente:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
my %params;
$params{first_name} = "Milton";
$params{last_name} = "Mazzarri";
$params{username} = "milmazz";
$params{groups} = "sysadmin";
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => '[email protected]',
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();Y el cuerpo del correo electrónico, lo que en realidad es una plantilla basada
en Template::Toolkit, vendría definido en el fichero example.txt.tt de la
siguiente manera:
Hola [% last_name %], [% first_name %].
Tu nombre de usuario es [% username %].
Un saludo, feliz día.
Su querido BOFH de siempre.En el script en Perl mostrado previamente podemos percatarnos que los datos del destinario se encuentran inmersos en la lógica. Por lo tanto, el siguiente paso sería desacoplar esta parte de la siguiente manera:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Class::CSV;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();
}Ahora los datos de los destinarios los extraemos de un fichero en formato CSV,
en este ejemplo, el fichero en formato CSV lo hemos denominado example.csv.
Cabe aclarar que $msg->send() realiza el envío por medio de Net::SMTP y
podrá usar las opciones que se describen en dicho módulo. Sin embargo, si
necesita establecer una conexión SSL con el servidor SMTP es oportuno recurrir a
Net::SMTP::SSL:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Net::SMTP::SSL;
use Class::CSV;
my $from = '[email protected]';
my $host = 'mail.example.com';
my $user = 'jdoe';
my $pass = 'example';
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => $from,
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
my $smtp = Net::SMTP::SSL->new( $host, Port => 465 )
or die "No pude conectarme";
$smtp->auth( $user, $pass )
or die "No pude autenticarme:" . $smtp->message();
$smtp->mail($from) or die "Error:" . $smtp->message();
$smtp->to( $line->email() ) or die "Error:" . $smtp->message();
$smtp->data() or die "Error:" . $smtp->message();
$smtp->datasend( $msg->as_string ) or die "Error:" . $smtp->message();
$smtp->dataend() or die "Error:" . $smtp->message();
$smtp->quit() or die "Error:" . $smtp->message();
}Note en este último ejemplo que la representación en cadena de caracteres del
cuerpo del correo electrónico viene dado por $msg->as_string.
Para finalizar, es importante mencionar que también podrá adjuntar ficheros de
cualquier tipo a sus correos electrónicos, solo debe prestar especial atención
en el tipo MIME de los ficheros que adjunta, es decir, si enviará un fichero
adjunto PDF debe utilizar el tipo application/pdf, si envía una imagen en el
formato GIF, debe usar el tipo image/gif. El método a seguir para adjuntar uno
o más ficheros lo dejo para su investigación ;)
Generar reporte en formato CSV de tickets en Trac desde Perl
El día de hoy recibí una llamada telefónica de un compañero de labores en donde me solicitaba con cierta preocupación un “pequeño” reporte del estado de un listado de tickets que recién me había enviado vía correo electrónico puesto que no contaba con conexión a la intranet, al analizar un par de tickets me dije que no iba a ser fácil realizar la consulta desde el asistente que brinda el mismo Trac. Así que inmediatamente puse las manos sobre un pequeño script en Perl que hiciera el trabajo sucio por mí.
Es de hacer notar que total de tickets a revisar era el siguiente:
$ wc -l tickets
126 tickets
Tomando en cuenta el resultado previo, era inaceptable hacer dicha labor de manera manual. Por lo tanto, confirmaba que realizar un script era la vía correcta y a la final iba a ser más divertido.
Tomando en cuenta que el formato de entrada era el siguiente:
#3460
#3493
...
El formato de la salida que esperaba era similar a la siguiente:
3460,"No expira la sesión...",closed,user
Básicamente el formato implica el id, sumario, estado y responsable asociado al ticket.
Net::Trac le ofrece una manera sencilla de interactuar con una instancia remota de Trac, desde el manejo de credenciales, consultas, revisión de tickets, entre otros. A la vez, se hace uso del módulo Class::CSV el cual le ofrece análisis y escritura de documentos en formato CSV.
#!/usr/bin/perl
use warnings;
use strict;
use Net::Trac;
use Class::CSV;
# Estableciendo la conexion a la instancia remota de Trac
my $trac = Net::Trac::Connection->new(
url => 'http://trac.example.com/project',
user => 'user',
password => 'password'
);
# Construccion del objecto CSV y definicion de opciones
my $csv = Class::CSV->new(
fields => [qw/ticket sumario estado responsable/],
line_separator => "\r\n",
csv_xs_options => { binary => 1, } # Manejo de caracteres non-ASCII
);
# Nos aseguramos que el inicio de sesion haya sido exitoso
if ( $trac->ensure_logged_in ) {
my $ticket = Net::Trac::Ticket->new( connection => $trac );
# Consultamos cada uno de los tickets indicados en el fichero de entrada
while ( my $line = <> ) {
chomp($line);
if ( $line =~ m/^#\d+$/ ) {
$line =~ s/^#(\d+)$/$1/;
$ticket->load($line);
$csv->add_line(
{
ticket => $ticket->id,
sumario => $ticket->summary,
estado => $ticket->status,
responsable => $ticket->owner
}
);
}
else {
print "[INFO] La linea no cumple el formato requerido: $line\n";
}
}
$csv->print();
}
else {
print "No se pudieron asegurar las credenciales";
}La manera de ejecutar el script es la siguiente:
$ perl trac_query.pl tickets
En donde trac_query.pl es el nombre del script y tickets es el fichero de
entrada.
Debo aclarar que el script carece de comentarios, mea culpa. Además, el manejo de opciones vía linea de comandos es inexistente, si desea mejorarlo puede hacer uso de Getopt::Long.
Cualquier comentario, sugerencia o corrección es bienvenida.
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234
Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Sistema de manejo y seguimiento de proyectos: Trac
Trac es un sistema multiplataforma desarrollado y mantenido por Edgewall Software, el cual está orientado al seguimiento y manejo de proyectos de desarrollo de software haciendo uso de un enfoque minimalista basado en la Web, su misión es ayudar a los desarrolladores a escribir software de excelente calidad mientras busca no interferir con el proceso y políticas de desarrollo. Incluye un sistema wiki que es adecuado para el manejo de la base de conocimiento del proyecto, fácil integración con sistemas de control de versiones ((Por defecto Trac se integra con subversion)). Además incluye una interfaz para el seguimiento de tareas, mejoras y reporte de errores por medio de un completo y totalmente personalizable sistema de tickets, todo esto con el fin de ofrecer una interfaz integrada y consistente para acceder a toda información referente al proyecto de desarrollo de software. Además, todas estas capacidades son extensibles por medio de plugins o complementos desarrollados específicamente para Trac.
Breve historia de Trac
El origen de Trac no es una idea original, algunos de sus objetivos se basan en los diversos sistemas de manejo y seguimiento de errores que existen en la actualidad, particularmente del sistema CVSTrac y sus autores.
Trac comenzó como la reimplementación del sistema CVSTrac en el lenguaje de programación Python y como ejercicio de entretenimiento, además de utilizar la base de datos embebida SQLite ((Hoy día también se le da soporte a PostgreSQL, mayor detalle en Database Backend)). En un corto lapso de tiempo, el alcance de estos esfuerzos iniciales crecieron en gran medida, se establecieron metas y en el presente Trac presenta un curso de desarrollo propio.
Los desarrolladores de Edgewall Software esperan que Trac sea una plataforma viable para explorar y expandir el cómo y qué puede hacerse con sistemas de manejo de proyectos de desarrollo de software basados en sistemas wiki.
Características de Trac
A continuación se presenta una descripción breve de las distintas características de Trac.
Herramienta de código abierto para el manejo de proyectos
Trac es una herramienta ligera para el manejo de proyectos basada en la Web, desarrollada en el lenguaje de programación Python. Está enfocada en el manejo de proyectos de desarrollo de software, aunque es lo suficientemente flexible para usarla en muchos tipos de proyectos. Al ser una herramienta de código abierto, si Trac no llena completamente sus necesidades, puede aplicar los cambios necesarios usted mismo, escribir complementos o plugins, o contratar a alguien calificado que lo haga por usted.
Sistema de tickets
El sistema de tickets le permite hacer seguimiento del progreso en la resolución de problemas de programación particulares, requerimientos de nuevas características, problemas e ideas, cada una de ellas en su propio ticket, los cuales son enumerados de manera ascendente. Puede resolver o reconciliar aquellos tickets que buscan un mismo objetivo o donde más de una persona reporta el mismo requerimiento. Permite hacer búsquedas o filtrar tickets por severidad, componente del proyecto, versión, responsable de atender el ticket, entre otros.
Para mejorar el seguimiento de los tickets Trac ofrece la posibilidad de activar notificaciones vía correo electrónico, de este modo se mantiene informado a los desarrolladores de los avances en la resolución de las actividades planificadas.
Vista de progreso
Existen varias maneras convenientes de estar al día con los acontecimientos y cambios que ocurren dentro de un proyecto. Puede establecer hitos y ver un mapa del progreso (así como los logros históricos) de manera resumida. Además, puede visualizar desde una interfaz centralizada los cambios ocurridos cronológicamente en el wiki, hitos, tickets y repositorios de código fuente, comenzando con los eventos más recientes, toda esta información es accesible vía Web o de manera alternativa Trac le ofrece la posibilidad de exportar esta información a otros formatos como el RSS, permitiendo que los usuarios puedan observar esos cambios fuera de la interfaz centralizada de Trac, así como la notificación por correo electrónico.
Vista del repositorio en línea
Una de las características de mayor uso en Trac es el navegador o visor del repositorio en línea, se le ofrece una interfaz bastante amigable para el sistema de control de versiones que esté usando ((Por defecto Trac se integra con subversion, la integración con otros sistemas es posible gracias a plugins o complementos.)). Este visualizador en línea le ofrece una manera clara y elegante de observar el código fuente resaltado, así como también la comparación de ficheros, apreciando fácilmente las diferencias entre ellos.
Manejo de usuarios
Trac ofrece un sistema de permisología para controlar cuales usuarios pueden acceder o no a determinadas secciones del sistema de manejo y seguimiento del proyecto, esto se logra a través de la interfaz administrativa. Además, esta interfaz es posible integrarla con la definición de permisos de lectura y escritura de los usuarios en el sistema de control de versiones, de ese modo se logra una administración centralizada de usuarios.
Wiki
El sistema wiki es ideal para mantener la base de conocimientos del proyecto, la cual puede ser usada por los desarrolladores o como medio para ofrecerles recursos a los usuarios. Tal como funcionan otros sistemas wiki, puede permitirse la edición compartida. La sintaxis del sistema wiki es bastante sencilla, si esto no es suficiente, es posible integrar en Trac un editor WYSIWYG (lo que se ve es lo que se obtiene, por sus siglas en inglés) que facilita la edición de los documentos.
Características adicionales
Al ser Trac un sistema modular puede ampliarse su funcionalidad por medio de complementos o plugins, desde sistemas anti-spam hasta diagramas de Gantt o sistemas de seguimiento de tiempo.
Pylint: Análisis estático del código en Python
Básicamente el análisis estático del código se refiere al proceso de evaluación del código fuente sin ejecutarlo, es en base a este análisis que se obtendrá información que nos permita mejorar la línea base de nuestro proyecto, sin alterar la semántica original de la aplicación.
Pylint es una herramienta que todo programador en Python debe considerar en su proceso de integración continua (Ej. Bitten), básicamente su misión es analizar código en Python en busca de errores o síntomas de mala calidad en el código fuente. Cabe destacar que por omisión, la guía de estilo a la que se trata de apegar Pylint es la descrita en el PEP-8.
Es importante resaltar que Pylint no sustituye las labores de revisión continua de alto nivel en el Proyecto, con esto quiero decir, su estructura, arquitectura, comunicación con elementos externos como bibliotecas, diseño, entre otros.
Tome en cuenta que Pylint puede arrojar falsos positivos, esto puede entenderse al recibir una alerta por parte de Pylint de alguna cuestión que usted realizó conscientemente. Ciertamente algunas de las advertencias encontradas por Pylint pueden ser peligrosas en algunos contextos, pero puede que en otros no lo sea, o simplemente Pylint haga revisiones de cosas que a usted realmente no le importan. Puede ajustar la configuración de Pylint para no ser informado acerca de ciertos tipos de advertencias o errores.
Entre la serie de revisiones que hace Pylint al código fuente se encuentran las siguientes:
- Revisiones básicas:
- Presencia de cadenas de documentación (docstring).
- Nombres de módulos, clases, funciones, métodos, argumentos, variables.
- Número de argumentos, variables locales, retornos y sentencias en funciones y métodos.
- Atributos requeridos para módulos.
- Valores por omisión no recomendados como argumentos.
- Redefinición de funciones, métodos, clases.
- Uso de declaraciones globales.
- Revisión de variables:
- Determina si una variable o
importno está siendo usado. - Variables indefinidas.
- Redefinición de variables proveniente de módulos builtins o de ámbito externo.
- Uso de una variable antes de asignación de valor.
- Determina si una variable o
- Revisión de clases:
- Métodos sin
selfcomo primer argumento. - Acceso único a miembros existentes vía
self - Atributos no definidos en el método
__init__ - Código inalcanzable.
- Métodos sin
- Revisión de diseño:
- Número de métodos, atributos, variables locales, entre otros.
- Tamaño, complejidad de funciones, métodos, entre otros.
- Revisión de imports:
- Dependencias externas.
-
imports relativos o importe de todos los métodos, variables vía
*(wildcard). - Uso de imports cíclicos.
- Uso de módulos obsoletos.
- Conflictos entre viejo/nuevo estilo:
- Uso de
property,__slots__,super. - Uso de
super.
- Uso de
- Revisiones de formato:
- Construcciones no autorizadas.
- Sangrado estricto del código.
- Longitud de la línea.
- Uso de
<>en vez de!=.
- Otras revisiones:
- Notas de alerta en el código como
FIXME,XXX. - Código fuente con caracteres non-ASCII sin tener una declaración de encoding. PEP-263
- Búsqueda por similitudes o duplicación en el código fuente.
- Revisión de excepciones.
- Revisiones de tipo haciendo uso de inferencia de tipos.
- Notas de alerta en el código como
Mientras Pylint hace el análisis estático del código muestra una serie de mensajes así como también algunas estadísticas acerca del número de advertencias y errores encontrados en los diferentes ficheros. Estos mensajes son clasificados bajo ciertas categorías, entre las cuales se encuentran:
- Refactorización: Asociado a una violación en alguna buena práctica.
- Convención: Asociada a una violación al estándar de codificación.
- Advertencia: Asociadas a problemas de estilo o errores de programación menores.
- Error: Asociados a errores de programación importantes, es probable que se trate de un bug.
- Fatal: Asociados a errores que no permiten a Pylint avanzar en su análisis.
Un ejemplo de este reporte lo puede ver a continuación:
Messages by category
--------------------
+-----------+-------+---------+-----------+
|type |number |previous |difference |
+===========+=======+=========+===========+
|convention |969 |1721 |-752.00 |
+-----------+-------+---------+-----------+
|refactor |267 |182 |+85.00 |
+-----------+-------+---------+-----------+
|warning |763 |826 |-63.00 |
+-----------+-------+---------+-----------+
|error |78 |291 |-213.00 |
+-----------+-------+---------+-----------+
Cabe resaltar que el formato de salida del ejemplo utilizado está en modo texto, usted puede elegir entre: coloreado, texto, msvs (Visual Estudio) y HTML.
Pylint le ofrece una sección dedicada a los reportes, esta se encuentra inmediatamente después de la sección de mensajes de análisis, cada uno de estos reportes se enfocan en un aspecto particular del proyecto, como el número de mensajes por categorías (mostrado arriba), dependencias internas y externas de los módulos, número de módulos procesados, el porcentaje de errores y advertencias encontradas por módulo, el total de errores y advertencias encontradas, el porcentaje de clases, funciones y módulos con docstrings y su respectiva comparación con un análisis previo (si existe). El porcentaje de clases, funciones y módulos con nombres correctos (de acuerdo al estándar de codificación), entre otros.
Al final del reporte arrojado por Pylint podrá observar una puntuación general por su código, basado en el número y la severidad de los errores y advertencias encontradas a lo largo del código fuente. Estos resultados suelen motivar a los desarrolladores a mejorar cada día más la calidad de su código fuente.
Si usted ejecuta Pylint varias veces sobre el mismo código, podrá ver el puntaje de la corrida previa junto al resultado de la corrida actual, de esta manera puede saber si ha mejorado la calidad de su código o no.
Global evaluation
-----------------
Your code has been rated at 7.74/10 (previous run: 4.64/10)
If you commit now, people should not be making nasty comments about you on c.l.py
Una de las grandes ventajas de Pylint es que es totalmente configurable, además, se pueden escribir complementos o plugins para agregar una funcionalidad que nos pueda ser útil.
Si usted quiere probar desde ya Pylint le recomiendo seguir la guía introductoria descrita en Pylint tutorial. Si desea una mayor ayuda respecto a los códigos indicados por Pylint, puede intentar el comando pylint --help-msg=CODIGO, si eso no es suficiente, le recomiendo visitar el wiki PyLint Messages para obtener una rápida referencia de los mensajes arrojados por Pylint, organizados de varias maneras para hacer más fácil y agradable la búsqueda. Además de encontrar explicaciones de cada mensaje, especialmente útiles para aquellos programadores que recién comienzan en Python.
Referencias
Consideraciones para el envío de cambios en Subversion
Hoy día pareciese que los sistemas de control de versiones centralizados están pasando de moda ante la aparición de sistemas de control de versiones descentralizados poderosos como Git, del cual espero poder escribir en próximos artículos. Sin embargo, puede que la adopción de estos sistemas descentralizados tarden en controlar el mundo de los SCM, al menos por ahora las métricas de ohloh.net indican que Subversion sigue siendo bastante empleado, mayor detalle en el artículo Subversion - As Strong As Ever.
En este artículo se expondrán algunas políticas que suelen definirse para la sana convivencia entre colaboradores de un proyecto de desarrollo de software, estas reglas no solo aplican a Subversion en particular, son de uso común en otros sistemas de control de versiones centralizados.
Analice bien los cambios hechos antes de enviarlos
Cualquier cambio en la línea base de su proyecto puede traer consecuencias, tome en cuenta que los demás desarrolladores obtendrán sus cambios una vez que estén en el repositorio centralizado. Si usted no se preocupó por validar que todo funcionara correctamente antes de enviar sus cambios, es probable que algún compañero le recrimine por su irresponsabilidad, esto afecta de cierta forma el anillo de confianza entre los colaboradores del proyecto.
Nunca envíe cambios que hagan fallar la construcción del proyecto
Siempre verifique que su proyecto compile, si el proyecto presenta errores debido a los cambios hechos por usted atiendalos inmediatamente, evite los errores de sintaxis, tenga siempre presente respetar las políticas de estilo de código definidas para su proyecto.
Si ha ingresado nuevos ficheros o directorios al proyecto recuerde ejecutar el comando svn add para programar la adición en Subversion, si omite este paso es posible que su copia de trabajo funcione o compile, pero la del resto de sus compañeros no, evite de nuevo ser recriminado por los demás colaboradores del proyecto.
Si su proyecto pretende ser multiplataforma, trate de imaginar las consecuencias de sus cambios bajo otro sistema operativo o arquitectura. Por ejemplo, he visto más de una vez este tipo de error:
path = "dir/subdir/fichero.txt" # Malo
path = os.path.join(os.path.dirname(__file__), 'dir', 'subdir', 'fichero.txt') # CorrectoPruebe los cambios antes de hacer el envío
Antes de realizar un envío al repositorio centralizado actualice su copia de trabajo (svn up), verifique que las pruebas unitarias, regresión de su proyecto arrojan resultados positivos, de igual manera haga pruebas funcionales del sistema.
Al momento de hacer la actualización de su copia de trabajo tome nota de los ficheros editados por los demás colaboradores del proyecto, verifique que no existan conflictos, nuevos ficheros que no haya considerado, entre otros. Una vez que haya solventado la actualización de su copia de trabajo, construya (su proyecto tiene un sistema de autoconstrucción, ¿verdad?) el paquete, inicie su aplicación que contiene los cambios locales y asegúrese que el comportamiento obtenido sea igual al esperado.
Promueva un histórico de cambios descriptivo
El histórico de cambios debe ser comprensible por cualquier colaborador del proyecto solamente con la información suministrada en dicho registro, evite depender de información fuera del contexto del envío de cambios. Se le recomienda colocar toda la información importante que no pueda obtenerse a partir de un svn diff del código fuente.
¿Está corrigiendo un error?
Si usted está reparando un error en la aplicación que se encuentra presente en la rama principal de desarrollo (trunk), considere seriamente portar esa reparación a otras ramas de desarrollo (branches) en el caso que su proyecto posea una versión estable que requiere actualmente de mantenimiento. Trate en lo posible de aprovechar el mismo commit para enviar la corrección de la rama principal de desarrollo (trunk) y las ramas de mantenimiento.
Si el error fue reportado a través del sistema de seguimiento de errores (usted mantiene un sistema de seguimiento de errores, ¿verdad?), agregue en el registro del mensaje de envío el número del ticket, boleto o reporte que usted está atendiendo. Seguidamente proceda a cerrar el ticket o boleto en el sistema de seguimiento de errores.
No agregue ficheros generados por otras herramientas al repositorio
No agregue ficheros innecesarios al repositorio, el origen de estos ficheros suele ser:
- Proceso de autoconstrucción (Ej. distutils, autotools, scons, entre otros).
- Herramientas de verificación de calidad del código (Ej. PyLint, CppLint, entre otros).
- Herramientas para generar documentación (Ej. Doxygen, Sphinx, entre otros).
Estos ficheros generados por otras herramientas no es necesario versionarlos, puede considerarlos cache, este tipo de datos son localmente generados como resultado de operaciones I/O o cálculos, las herramientas deben ser capaces de regenerar o restaurar estos datos a partir del código presente en el repositorio central.
Realice envíos atómicos
Recuerde que SVN le brinda la posibilidad de enviar más de un fichero en un solo commit. Por lo tanto, envíe todos los cambios relacionados en múltiples ficheros, incluso si los cambios se extienden a lo largo de varios directorios en un mismo commit. De esta manera, se logra que SVN se mantenga en un estado compatible antes y después del commit.
Recuerde asegurarse al enviar un cambio al repositorio central reflejar un solo propósito, el cual puede ser la corrección de un error de programación o bug, agregar una nueva funcionalidad al sistema, ajustes de estilo del código o alguna tarea adicional.
Separe los ajustes de formato de código de otros envíos
Ajustar el formato del código, como la sangría, los espacios en blanco, el largo de la línea incrementa considerablemente los resultados del diff, si usted mezcla los cambios asociados al ajuste de formato de código con otros estará dificultando un posterior análisis al realizar un svn diff.
Haga uso intensivo de la herramienta de seguimiento de errores
Trate en lo posible de crear enlaces bidireccionales entre el conjunto de cambios hechos en el repositorio de subversion y la herramienta de seguimientos de errores tanto como sea posible.
- Trate de hacer una referencia al id o número del ticket al cual está dando solución desde su mensaje de registro o log previo a realizar el commit.
- Cuando agregue información o responda a un ticket, ya sea para describir su avance o simplemente para cerrar el ticket, indique el número o números de revisión que atienden o responden a dichos cambios.
Indique en el registro de envío el resultado del merge
Cuando usted está enviando el resultado de un merge, asegúrese de indicar sus acciones en el registro de envío, tanto aquello que fue fusionado como los números de revisiones que fueron tomadas en cuenta. Ejemplo:
Fusión de las revisiones 10:40 de /branches/foo a /trunk.
Tenga claro cuando es oportuno crear una rama
Esto es un tema polémico. Sin embargo, dependiendo del proyecto en el que esté involucrado usted puede definir una estrategia o mezcla de ellas para manejar el desarrollo del proyecto. Generalmente puede encontrar lo siguiente:
Los proyectos que requieren un alto manejo y supervisión recurren a estrategias de siempre crear ramas, acá puede encontrarse que cada colaborador crea o trabaja en una rama privada para cada tarea de codificación. Cuando el trabajo individual ha finalizado, algún responsable, ya sea el fundador del proyecto, un revisor técnico, analiza los cambios hechos por el colaborador y hace la fusión con la línea principal de desarrollo. En estos casos la rama principal de desarrollo suele ser bastante estable. Sin embargo, este modo de trabajo conlleva normalmente a crear mayores conflictos en la etapa de fusión o merge, además, las labores de fusión bajo este esquema son constantemente requeridas.
Existe otro enfoque que permite mantener una línea base de desarrollo estable, el cual consiste en crear ramas de desarrollo solo cuando se ameritan. Sin embargo, esto requiere que los colaboradores tengan mayor dominio del uso de Subversion y una constante comunicación entre ellos. Además de aumentar el número de pruebas antes de cada envío al repositorio centralizado.
Estudie, analice las distintas opciones y defina un método para la creación de ramas en su proyecto. Una vez definido, es sumamente importante que cada colaborador tenga clara esta estrategia de trabajo.
Las estrategias antes mencionadas y otras más pueden verse en detalle en:
Los sistemas de control de versiones no substituyen la comunicación entre los colaboradores
Por último pero no menos importante, los sistemas de control de versiones no substituyen la comunicación entre los desarrolladores o colaboradores del proyecto de software. Cuando usted tenga planes de hacer un cambio que pueda afectar una cantidad de código considerable en su proyecto, establezca un control de cambios, haga un análisis de las posibles consecuencias o impacto de los mismos, difunda esta información a través de una lista de discusión (usted mantiene una lista de discusión para desarrolladores, ¿verdad?) y espere la respuesta, preocupaciones, sugerencias de los demás colaboradores, quizá juntos se encuentre un modo más eficaz de aplicar los cambios.
Referencias:
- Subversion Best Practices (presentación)
- SVN commit basic policy guide
- Subversion Best Practices
- Subversion Best Practices (presentación)
subversion: Recuperar cambios y eliminaciones hechas
Muchos compañeros de trabajo y amigos en general que recién comienzan con el manejo de sistemas de control de versiones centralizados, en particular subversion, regularmente tienen inquietudes en cuanto al proceso de recuperación de cambios una vez que han sido enviados al repositorio, así como también la recuperación de ficheros y directorios que fueron eliminados en el pasado. Trataré de explicar algunos casos en base a ejemplos para que se tenga una idea más clara del problema y su respectiva solución.
En el primero de los casos se tiene recuperar la revisión previa a la actual, suponga que usted mantiene un repositorio de recetas, una de ellas en particular es la ensalada caprese, por error o descuido añadió el ingrediente Mostaza tipo Dijón a la lista, si usted posee siquiera un lazo con italinos sabe que está cometiendo un error que puede devenir en escarnio público, desprecio e insultos.
~/svn/wc/trunk$ svn diff -r 2:3 ${URL}/trunk/caprese
Index: caprese
===================================================================
--- caprese (revision 2)
+++ caprese (revision 3)
@@ -7,3 +7,4 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
+ - Mostaza tipo Dijon
Note que el comando anterior muestra las diferencias entre las revisiones 2 y 3 del repositorio, en el resumen se puede apreciar que en la revisión 3 ocurrió el error. Un modo rápido de recuperarlo es como sigue.
~/svn/wc/trunk$ svn merge -c -3 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
En este caso particular se están aplicando las diferencias entre las revisiones consecutivas a la copia de trabajo. Es hora de verificar que los cambios hechos sean los deseados:
~/svn/wc/trunk$ svn status
M caprese
~/svn/wc/trunk$ svn diff
Index: caprese
===================================================================
--- caprese (revision 3)
+++ caprese (working copy)
@@ -7,4 +7,3 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
- - Mostaza tipo Dijon
Una vez verificado enviamos los cambios hechos al repositorio a través de comando svn commit.
Seguramente usted se estará preguntando ahora que sucede si las revisiones del ficheros no son consecutivas como en el caso mostrado previamente. En este caso es importante hacer notar que la opción -c 3 es equivalente a -r 2:3 al usar el comando svn merge, en nuestro caso particular -c -3 es equivalente a -r 3:2 (a esto se conoce como una fusión reversa), substituyendo la opción -c (o --changes) en el caso previo obtenemos lo siguiente:
~/svn-tests/wc/trunk$ svn merge -r 3:2 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
Referencias: svn help merge, svn help diff, svn help status.
Recuperando ficheros o directorios eliminados
Una manera bastante sencilla de recuperar ficheros o directorios eliminados es haciendo uso de comando svn cp o svn copy, una vez determinada la revisión del fichero o directorio que desea recuperar la tarea es realmente sencilla:
~/svn-tests/wc/trunk$ svn cp ${URL}/trunk/panzanella@6 panzanella
A panzanella
En este caso se ha duplicado la revisión 6 del fichero panzanella en la copia de trabajo local, se ha programado para su adición incluyendo su historial, esto último puede verificarse en detalle al observar el signo ’+’ en la cuarta columna del comando svn status.
~/svn-tests/wc/trunk$ svn status
A + panzanella
Referencias: svn help copy, svn help status.
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
Perl
Enviando correos con Perl
Regularmente los administradores de sistemas requieren notificar, vía correo electrónico, a sus usuarios de ciertos cambios o nuevos servicios disponibles. La experiencia me ha indicado que el usuario aprecia más un correo personalizado que uno general. Sin embargo, lograr lo primero de manera manual es bastante tedioso e ineficaz. Por lo tanto, es lógico pensar en la posibilidad de automatizar el proceso de envío de correos electrónicos personalizados, en este artículo, explicaré una de las tantas maneras de lograrlo haciendo uso del lenguaje de programación Perl.
En CPAN podrá encontrar muchas alternativas, recuerde el
principio
TIMTOWTDI.
Sin embargo, la opción que más me atrajo fue MIME::Lite:TT, básicamente este
módulo en Perl es un wrapper de MIME::Lite que le permite el uso de
plantillas, vía Template::Toolkit, para el cuerpo del mensaje del correo
electrónico. También puede encontrar MIME::Lite::TT::HTML que le permitirá
enviar correos tanto en texto sin formato (MIME::Lite::TT) como en formato
HTML. Sin embargo, estoy en contra de enviar correos en formato HTML, lo dejo a
su criterio.
Una de las ventajas de utilizar Template::Toolkit para el cuerpo del mensaje
es separar en capas nuestra script, si se observa desde una versión muy
simplificada del patrón
MVC, el
control de la lógica de programación reside en el script en Perl, la plantilla
basada en Template Toolkit ofrecería la vista de los datos, de modo tal que
podríamos garantizar que la presentación está separada de los datos, los cuales
pueden encontrarse desde una base de datos o un simple fichero CSV. Otra ventaja
evidente es el posible reuso de componentes posteriormente.
Un primer ejemplo del uso de MIME::Lite:TT puede ser el siguiente:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
my %params;
$params{first_name} = "Milton";
$params{last_name} = "Mazzarri";
$params{username} = "milmazz";
$params{groups} = "sysadmin";
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => '[email protected]',
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();Y el cuerpo del correo electrónico, lo que en realidad es una plantilla basada
en Template::Toolkit, vendría definido en el fichero example.txt.tt de la
siguiente manera:
Hola [% last_name %], [% first_name %].
Tu nombre de usuario es [% username %].
Un saludo, feliz día.
Su querido BOFH de siempre.En el script en Perl mostrado previamente podemos percatarnos que los datos del destinario se encuentran inmersos en la lógica. Por lo tanto, el siguiente paso sería desacoplar esta parte de la siguiente manera:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Class::CSV;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();
}Ahora los datos de los destinarios los extraemos de un fichero en formato CSV,
en este ejemplo, el fichero en formato CSV lo hemos denominado example.csv.
Cabe aclarar que $msg->send() realiza el envío por medio de Net::SMTP y
podrá usar las opciones que se describen en dicho módulo. Sin embargo, si
necesita establecer una conexión SSL con el servidor SMTP es oportuno recurrir a
Net::SMTP::SSL:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Net::SMTP::SSL;
use Class::CSV;
my $from = '[email protected]';
my $host = 'mail.example.com';
my $user = 'jdoe';
my $pass = 'example';
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => $from,
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
my $smtp = Net::SMTP::SSL->new( $host, Port => 465 )
or die "No pude conectarme";
$smtp->auth( $user, $pass )
or die "No pude autenticarme:" . $smtp->message();
$smtp->mail($from) or die "Error:" . $smtp->message();
$smtp->to( $line->email() ) or die "Error:" . $smtp->message();
$smtp->data() or die "Error:" . $smtp->message();
$smtp->datasend( $msg->as_string ) or die "Error:" . $smtp->message();
$smtp->dataend() or die "Error:" . $smtp->message();
$smtp->quit() or die "Error:" . $smtp->message();
}Note en este último ejemplo que la representación en cadena de caracteres del
cuerpo del correo electrónico viene dado por $msg->as_string.
Para finalizar, es importante mencionar que también podrá adjuntar ficheros de
cualquier tipo a sus correos electrónicos, solo debe prestar especial atención
en el tipo MIME de los ficheros que adjunta, es decir, si enviará un fichero
adjunto PDF debe utilizar el tipo application/pdf, si envía una imagen en el
formato GIF, debe usar el tipo image/gif. El método a seguir para adjuntar uno
o más ficheros lo dejo para su investigación ;)
Generar reporte en formato CSV de tickets en Trac desde Perl
El día de hoy recibí una llamada telefónica de un compañero de labores en donde me solicitaba con cierta preocupación un “pequeño” reporte del estado de un listado de tickets que recién me había enviado vía correo electrónico puesto que no contaba con conexión a la intranet, al analizar un par de tickets me dije que no iba a ser fácil realizar la consulta desde el asistente que brinda el mismo Trac. Así que inmediatamente puse las manos sobre un pequeño script en Perl que hiciera el trabajo sucio por mí.
Es de hacer notar que total de tickets a revisar era el siguiente:
$ wc -l tickets
126 tickets
Tomando en cuenta el resultado previo, era inaceptable hacer dicha labor de manera manual. Por lo tanto, confirmaba que realizar un script era la vía correcta y a la final iba a ser más divertido.
Tomando en cuenta que el formato de entrada era el siguiente:
#3460
#3493
...
El formato de la salida que esperaba era similar a la siguiente:
3460,"No expira la sesión...",closed,user
Básicamente el formato implica el id, sumario, estado y responsable asociado al ticket.
Net::Trac le ofrece una manera sencilla de interactuar con una instancia remota de Trac, desde el manejo de credenciales, consultas, revisión de tickets, entre otros. A la vez, se hace uso del módulo Class::CSV el cual le ofrece análisis y escritura de documentos en formato CSV.
#!/usr/bin/perl
use warnings;
use strict;
use Net::Trac;
use Class::CSV;
# Estableciendo la conexion a la instancia remota de Trac
my $trac = Net::Trac::Connection->new(
url => 'http://trac.example.com/project',
user => 'user',
password => 'password'
);
# Construccion del objecto CSV y definicion de opciones
my $csv = Class::CSV->new(
fields => [qw/ticket sumario estado responsable/],
line_separator => "\r\n",
csv_xs_options => { binary => 1, } # Manejo de caracteres non-ASCII
);
# Nos aseguramos que el inicio de sesion haya sido exitoso
if ( $trac->ensure_logged_in ) {
my $ticket = Net::Trac::Ticket->new( connection => $trac );
# Consultamos cada uno de los tickets indicados en el fichero de entrada
while ( my $line = <> ) {
chomp($line);
if ( $line =~ m/^#\d+$/ ) {
$line =~ s/^#(\d+)$/$1/;
$ticket->load($line);
$csv->add_line(
{
ticket => $ticket->id,
sumario => $ticket->summary,
estado => $ticket->status,
responsable => $ticket->owner
}
);
}
else {
print "[INFO] La linea no cumple el formato requerido: $line\n";
}
}
$csv->print();
}
else {
print "No se pudieron asegurar las credenciales";
}La manera de ejecutar el script es la siguiente:
$ perl trac_query.pl tickets
En donde trac_query.pl es el nombre del script y tickets es el fichero de
entrada.
Debo aclarar que el script carece de comentarios, mea culpa. Además, el manejo de opciones vía linea de comandos es inexistente, si desea mejorarlo puede hacer uso de Getopt::Long.
Cualquier comentario, sugerencia o corrección es bienvenida.
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234
Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Generando contraseñas aleatorias con Perl
El día de hoy se manifestó la necesidad de generar una serie de claves aleatorias para un proyecto en el que me he involucrado recientemente, la idea es que la entrada que tenemos corresponde más o menos al siguiente formato:
username_1
username_2
...
username_n
La salida que se desea obtener debe cumplir con el siguiente formato:
username_1 pass_1
username_2 pass_2
username_3 pass_3
...
username_n pass_n
En este caso debía cumplir un requisito fundamental, las contraseñas deben ser suficientemente seguras.
No pensaba en otra cosa que usar el lenguaje de programación Perl para realizar esta tarea, así fue, hice uso del poderío que brinda Perl+CPAN y en menos de 5 minutos ya tenía la solución al problema planteado, el tiempo restante me sirvió para comerme un pedazo de torta que me dió mi hermana, quien estuvo de cumpleaños el día de ayer.
En primer lugar, debemos instalar el módulo String::MkPasswd, el cual nos permitirá generar contraseñas de manera aleatoria. Si usted disfruta de una distribución decente como DebianRecuerde, Debian es inexorable la instalación del módulo es realmente trivial.
# aptitude install libstring-mkpasswd-perl
Además, si usted se detiene unos segundos y lee la documentación del módulo String::MkPasswd Este modulo en particular no solo se encuentra perfectamente integrado con nuestra distribución favorita, sino que además sus dependencias están resueltas. Esto es una simple muestra del poderío que ofrece una distribución como Debian., se dará cuenta que la función mkpasswd() toma un hash de argumentos opcionales. Si no le pasa ningún argumento a esta función estará generando constraseñas aleatorias con las siguientes características:
- La longitud de la contraseña será de 9.
- El número mínimo de dígitos será de 2.
- El número mínimo de caracteres en minúsculas será de 2.
- El número mínimo de caracteres en mayúsculas será de 2.
- El número mínimo de caracteres no alfanuméricos será de 1.
- Los caracteres no serán distribuidos entre los lados izquierdo y derecho del teclado.
Ahora bien, asumiendo que el fichero de entrada es users.data, la tarea con Perl es resumida en una línea de la siguiente manera.
perl -MString::MkPasswd=mkpasswd -nli -e 'print $_, " ", mkpasswd()' users.data
La línea anterior hace uso de la función mkpasswd del módulo String::MkPasswd para generar las contraseñas aleatorias para cada uno de los usuarios que se encuentran en el fichero de entrada users.data, además, la opción -iPara mayor información acerca de las distintas opciones usadas se le sugiere referirse a man perlrun permite editar el fichero de entrada in situ, ahora bien, quizá para algunos paranoicos (me incluyo) no sea suficiente todo esto, así que vamos a generar contraseñas aleatorias aún más complicadas.
#!/usr/bin/perl -li
use strict;
use warnings;
use String::MkPasswd qw(mkpasswd);
while(<>){
chomp;
print $_, " ", mkpasswd(
-length => 16,
-minnum => 5,
-minlower => 5,
-minupper => 3,
-minspecial => 3,
-distribute => 1
);
}En esta ocasión el la función mkpasswd() generará claves aún más complejas, dichas claves cumplirán con las siguientes condiciones.
-
-length: La longitud total de la contraseña, 16 en este caso. -
-minnum: El número mínimo de digitos. 5 en este caso. -
-minlower: El número mínimo de caracteres en minúsculas, en este caso 5. -
-minupper: El número mínimo de caracterés en mayúsculas, en este caso 3. -
-minspecial: El número mínimo de caracteres no alfanuméricos, en este caso será de 3. -
-distribute: Los caracteres de la contraseña serán distribuidos entre el lado izquierdo y derecho del teclado, esto hace más díficil que un fisgón vea la contraseña que uno está escribiendo. El valor predeterminado es falso, en este caso el valor es verdadero.
El script mostrado anteriormente lo podemos reducir a una línea, aunque preferí guardarlo en un fichero al que denomine genpasswd.pl por cuestiones de legibilidad.
El algoritmo de Dijkstra en Perl
Hace ya algunos días nos fué asignado en la cátedra de Redes de Computadoras encontrar el camino más corto entre dos vértices de un grafo dirigido que no tuviese costos negativos en sus arcos, para ello debíamos utilizar el algoritmo de Dijkstra. Además de ello, debía presentarse el grafo y la ruta más corta en una imagen, para visualizarlo de mejor manera.
Cuando un profesor te dice: No se preocupen por la implementación del algoritmo de Dijkstra, utilice la que usted prefiera, pero les agradezco que la analicen. Además, pueden utilizar el lenguaje de programación de su preferencia. Estas palabras te alegran el día, simplemente eres feliz.
Por algunos problemas que tuve con algunos módulos en Python, no lo hice en dicho lenguaje de programación, no vale la pena explicar en detalle los problemas que se me presentaron.
Lo importante de todo esto, es que asumí el reto de realizar la asignación en un lenguaje de programación practicamente nuevo para mí, aunque debo reconocer que la resolución no me causó dolores de cabezas en lo absoluto, a continuación algunos detalles.
En primer lugar, formularse las preguntas claves, ¿existe algún módulo en Perl que implemente el algoritmo de Dijkstra para encontrar el camino más corto?, ¿existe algún módulo en Perl que implemente GraphViz?
En segundo lugar, buscar en el lugar correcto, y cuando hablamos de Perl el sitio ideal para buscar es search.cpan.org, efectivamente, en cuestión de segundos encontre los dos módulos que me iban a facilitar la vida, Bio::Coordinate::Graph, para encontrar la ruta más corta entre dos vértices en un grafo y GraphViz, para pintar el grafo.
En tercer lugar, verificar en tu distro favorita, Debian, si existe un paquete precompilado listo pasa ser usado, para GraphViz existe uno, libgraphviz-perl, así que para instalarlo es tan fácil como:
# aptitude install libgraphviz-perl
Para instalar el módulo Bio::Coordinate::Graph, primero debía debianizarlo, eso es tan sencillo como hacer.
# dh-make-perl --build --cpan Bio::Coordinate::Graph
Luego debe proceder a instalar el fichero .deb que se generó con dh-make-perl, para lograrlo hago uso del comando dpkg, eso es todo. Por cierto, acerca del comando dh-make-perl ya había hablado en la entrada Perl: Primeras experiencias.
Encontrando el camino más corto
Según dice la documentación del módulo Bio::Coordinate::Graph debemos hacer uso de un hash de hashes anónimos para representar la estructura del grafo, en ese momento recordé algunas palabras que José Luis Rey nos comentó en la primera parte del curso de Perl, vale resalta la siguiente: Si usted no utiliza un hash, no lo está haciendo bien.
my $hash = {
'6' => undef,
'1' => {
'2' => 1
},
'2' => {
'6' => 4,
'4' => 1,
'3' => 1
},
'3' => {
'6' => 1
},
'4' => {
'5' => 1
},
'5' => undef
};Algo que es importante saber es que en Perl las estructuras de datos son planas, lo cual es conveniente. Por lo tanto, vamos a tener que utilizar referencias en este caso, pero luego nos preocuparemos por ello. Ahora solo resta decir que, la estructura hecha a través de un hash de hashes es sencilla de interpretar, las llaves o keys del hash principal representan los vértices del grafo, ahora bien, las llaves de los hashes más internos representan los vértices vecinos de cada vértice descrito en el hash principal, el valor de los hashes más internos representa el peso, distancia o costo que existe entre ambos vértices, para aclarar la situación un poco: El vértice 2, tiene como vecinos a los vértices 3, 4 y 6, con costos de 1, 1 y 4 respectivamente. Puede ver una muestra del grafo resultante.
De manera alternativa puede utilizar un hash de arrays para representar la estructura del grafo, siempre y cuando todos los costos entre los vértices sean igual a 1, este método es menos general que el anterior y además, este tipo de estructura es convertida a un hash de hashes, así que a la final resulta ineficiente.
Una vez definida la estructura del grafo corresponde crear el objeto, esto es realmente sencillo.
my $graph = Bio::Coordinate::Graph->new(-graph => $hash);Lo que resta es definir el vértice de inicio y el vértice final, yo los he definido en las variables $start y $end, luego de ello, debemos invocar al método shortest_path, de la siguiente manera:
my @path = $graph->shortest_path($start, $end);En el array @path encontraremos los vértices involucrados en el camino más corto.
Pintando el grafo
Una vez hallado el camino más corto entre dos vértices dados en un grafo dirigido con un costo en los arcos siempre positivos, lo que resta es hacer uso del módulo GraphViz, hacemos uso del constructor del objeto de la siguiente manera:
my $g = GraphViz->new();Usted puede invocar al constructor con distintos atributos, para saber cuales usar le recomiendo leer la documentación del módulo.
Ahora bien, yo quería distinguir aquellos vértices involucrados en el camino más corto de aquellos que no pertenecían, así que lo más sencillo es generar una lista de atributos que será usada posteriormente. Por ejemplo:
my @shortest_path_attrs = (
color => 'red',
);Una vez definidos los atributos, debemos generar cada uno de sus vértices y además, establecer los arcos entre cada uno de ellos. Para ello haremos uso de los métodos add_node, add_edge.
foreach my $key (keys %$hash){
$g->add_node($key);
foreach my $neighbor (keys %{$hash->{$key}}){
$g->add_edge($key => $neighbor, label => $hash->{$key}->{$neighbor});
}
}El bloque de código anterior lo que hace es agregar cada uno de los vértices que se encuentran en el hash que representa la estructura del grafo, para cada uno de estos vértices, se añade cada uno de los arcos que lo conectan con sus vecinos, nótese el manejo del operador flecha (->) para desreferenciar las referencias al hash de hashes anónimos.
Una vez construidos los nodos y sus arcos, ¿cómo reconocer aquellos que pertenecen al camino más corto?, bueno, toda esa información la podemos extraer del array que hemos denominado @path.
for (my $count=0; $count < = $#path; $count++){
$g->add_node($path[$count], @shortest_path_attrs);
$g->add_edge($path[$count] => $path[$count+1], @shortest_path_attrs) unless ($count+1 > $#path);
}Según dice la documentación del módulo GraphViz todos los atributos de un vértice del grafo no tienen que definirse de una sola vez, puede hacerse después, ya que las declaraciones sucesivas tienen efecto acumulativo, eso quiere decir lo siguiente:
$g->add_node('1', color => 'red');Es equivalente a hacer las siguientes declaraciones sucesivas.
$g->add_node('1');
$g->add_node('1', color => 'red');Lo que resta por hacer en este instante es exportar el objeto creado, puede crear por ejemplo un PNG, texto sin formato, PostScript, entre otros.
Yo decidí generar un fichero PostScript:
$g->as_ps("dijkstra.ps");Por supuesto, les dejo una muestra de los resultados. Los vértices cuyo borde es rojo, son aquellos involucrados en el camino más corto desde el vértice inicio al vértice final, los arcos que marcan la ruta más corta también han sido coloreados.
Como siempre, todas las recomendaciones, comentarios, sugerencias son bienvenidas.
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
Vulnerabilidad en Perl
Las siguientes versiones se encuentran afectadas ante este fallo de seguridad:
- Ubuntu 4.10 (Warty Warthog)
- Ubuntu 5.04 (Hoary Hedgehog)
- Ubuntu 5.10 (Breezy Badger)
En particular, los siguientes paquetes se encuentran afectados:
libperl5.8perl-base
El problema puede ser corregido actualizando los paquetes a sus últimas versiones en las respectivas versiones de Ubuntu. En general, el modo estándar de actualizar la distribución será mas que suficiente.
$ sudo aptitude dist-upgrade
La actualización pretende solucionar una vulnerabilidad del interprete Perl, el cual no era capaz de manejar todos los posibles casos de una entrada malformada que podría permitir la ejecución de código arbitrario, así que es recomendable actualizar su sistema de inmediato.
Sin embargo, es importante hacer notar que esta vulnerabilidad puede ser aprovechada en aquellos programas inseguros escritos en Perl que utilizan variables con valores definidos por el usuario en cadenas de caracteres y en donde no se realiza una verificación de dichos valores.
Si desea mayor detalle, le recomiendo leer el anuncio hecho por Martin Pitt en [USN-222-1] Perl vulnerability.
Seguridad
GRUB: Mejorando nuestro gestor de arranque
Anteriormente había comentado en la primera entrega del artículo Debian: Bienvenido al Sistema Operativo Universal que por medidas de seguridad establezco las opciones de montaje ro, nodev, nosuid, noexec en la partición /boot, donde se encuentran los ficheros estáticos del gestor de arranque.
El gestor de arranque que manejo es GRUB. Por lo tanto, el motivo de este artículo es explicar como suelo personalizarlo, tanto para dotarle de seguridad como mejorar su presentación.
Seguridad
Lo primero que hago es verificar el dueño y los permisos que posee el fichero /boot/grub/menu.lst, en mi opinión la permisología más abierta y peligrosa sería 644, pero normalmente la establezco en 600, evitando de ese modo que todos los usuarios (excepto el dueño del fichero, que en este caso será root) puedan leer y escribir en dicho fichero. Para lograr esto recurrimos al comando chmod.
# chmod 600 /boot/grub/menu.lst
Si usted al igual que yo mantiene a /boot como una partición de solo lectura, deberá montar de nuevo la partición /boot estableciendo la opción de escritura, para lo cual hacemos:
# mount -o remount,rw /boot
Después de ello si podrá cambiar la permisología del fichero /boot/grub/menu.lst de ser necesario.
El segundo paso es evitar que se modifique de manera interactiva las opciones de inicio del kernel desde el gestor de arranque, para ello estableceremos una contraseña para poder editar dichas opciones, pero primero nos aseguraremos de cifrar esa contraseña con el algoritmo MD5. Por lo tanto, haremos uso de grub-md5-crypt
# grub-md5-crypt
Password:
Retype password:
$1$56z5r1$yMeSchRfnxdS3QDzLpovV1
La última línea es el resultado de aplicarle el algoritmo MD5 a nuestra contraseña, la copiaremos e inmediatamente procedemos a modificar de nuevo el fichero /boot/grub/menu.lst, el cual debería quedar más o menos como se muestra a continuación.
password --md5 $1$56z5r1$yMeSchRfnxdS3QDzLpovV1
title Debian GNU/Linux, kernel 2.6.18-3-686
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro
initrd /initrd.img-2.6.18-3-686
savedefault
title Debian GNU/Linux, kernel 2.6.18-3-686 (single-user mode)
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro single
initrd /initrd.img-2.6.18-3-686
savedefault
La instrucción password --md5 aplica a nivel global, así que cada vez que desee editar las opciones de inicio del kernel, tendrá que introducir la clave (deberá presionar la tecla p para que la clave le sea solicitada) que le permitirá editar dichas opciones.
Presentación del gestor de arranque
A muchos quizá no les agrade el aspecto inicial que posee el GRUB, una manera de personalizar la presentación de nuestro gestor de arranque puede ser la descrita en la segunda entrega de la entrada Debian: Bienvenido al Sistema Operativo Universal en donde instalaba el paquete grub-splashimages y posteriormente establecía un enlace simbólico, el problema de esto es que estamos limitados a las imágenes que trae solo ese paquete.
A menos que a usted le guste diseñar sus propios fondos, puede usar los siguientes recursos:
Después de escoger la imagen que servirá de fondo para el gestor de arranque, la descargamos y la colocamos dentro del directorio /boot/grub/, una vez allí procedemos a modificar el fichero /boot/grub/menu.lst y colocaremos lo siguiente:
splashimage=(hd0,1)/grub/debian.xpm.gz
En la línea anterior he asumido lo siguiente:
- La imagen que he colocado dentro del directorio
/boot/grub/lleva por nombredebian.xpm.gz -
He ajustado la ubicación de mi partición
/boot, es probable que en su caso sea diferente, para obtener dicha información puede hacerlo al leer la tabla de particiones confdisk -lo haciendo uso del comandomount.$ mount | grep /boot /dev/sda2 on /boot type ext2 (rw,noexec,nosuid,nodev)
fdisk -l | grep ^/dev/sda2
/dev/sda2 1217 1226 80325 83 Linux
Por lo tanto, la ubicación de la partición /boot es en el primer disco duro, en la segunda partición, recordando que la notación en el grub comienza a partir de cero y no a partir de uno, tenemos como resultado hd0,1.
También puede darse el caso que ninguno de los fondos para el gestor de arranque mostrados en los recursos señalados previamente sean de su agrado. En ese caso, puede que le sirva el siguiente video demostrativo sobre como convertir un fondo de escritorio en un Grub Splash Image (2 MB) haciendo uso de The Gimp, espero le sea útil.
Después de personalizar el fichero /boot/grub/menu.lst recuerde ejecutar el comando update-grub como superusuario para actualizar las opciones.
Generando contraseñas aleatorias con Perl
El día de hoy se manifestó la necesidad de generar una serie de claves aleatorias para un proyecto en el que me he involucrado recientemente, la idea es que la entrada que tenemos corresponde más o menos al siguiente formato:
username_1
username_2
...
username_n
La salida que se desea obtener debe cumplir con el siguiente formato:
username_1 pass_1
username_2 pass_2
username_3 pass_3
...
username_n pass_n
En este caso debía cumplir un requisito fundamental, las contraseñas deben ser suficientemente seguras.
No pensaba en otra cosa que usar el lenguaje de programación Perl para realizar esta tarea, así fue, hice uso del poderío que brinda Perl+CPAN y en menos de 5 minutos ya tenía la solución al problema planteado, el tiempo restante me sirvió para comerme un pedazo de torta que me dió mi hermana, quien estuvo de cumpleaños el día de ayer.
En primer lugar, debemos instalar el módulo String::MkPasswd, el cual nos permitirá generar contraseñas de manera aleatoria. Si usted disfruta de una distribución decente como DebianRecuerde, Debian es inexorable la instalación del módulo es realmente trivial.
# aptitude install libstring-mkpasswd-perl
Además, si usted se detiene unos segundos y lee la documentación del módulo String::MkPasswd Este modulo en particular no solo se encuentra perfectamente integrado con nuestra distribución favorita, sino que además sus dependencias están resueltas. Esto es una simple muestra del poderío que ofrece una distribución como Debian., se dará cuenta que la función mkpasswd() toma un hash de argumentos opcionales. Si no le pasa ningún argumento a esta función estará generando constraseñas aleatorias con las siguientes características:
- La longitud de la contraseña será de 9.
- El número mínimo de dígitos será de 2.
- El número mínimo de caracteres en minúsculas será de 2.
- El número mínimo de caracteres en mayúsculas será de 2.
- El número mínimo de caracteres no alfanuméricos será de 1.
- Los caracteres no serán distribuidos entre los lados izquierdo y derecho del teclado.
Ahora bien, asumiendo que el fichero de entrada es users.data, la tarea con Perl es resumida en una línea de la siguiente manera.
perl -MString::MkPasswd=mkpasswd -nli -e 'print $_, " ", mkpasswd()' users.data
La línea anterior hace uso de la función mkpasswd del módulo String::MkPasswd para generar las contraseñas aleatorias para cada uno de los usuarios que se encuentran en el fichero de entrada users.data, además, la opción -iPara mayor información acerca de las distintas opciones usadas se le sugiere referirse a man perlrun permite editar el fichero de entrada in situ, ahora bien, quizá para algunos paranoicos (me incluyo) no sea suficiente todo esto, así que vamos a generar contraseñas aleatorias aún más complicadas.
#!/usr/bin/perl -li
use strict;
use warnings;
use String::MkPasswd qw(mkpasswd);
while(<>){
chomp;
print $_, " ", mkpasswd(
-length => 16,
-minnum => 5,
-minlower => 5,
-minupper => 3,
-minspecial => 3,
-distribute => 1
);
}En esta ocasión el la función mkpasswd() generará claves aún más complejas, dichas claves cumplirán con las siguientes condiciones.
-
-length: La longitud total de la contraseña, 16 en este caso. -
-minnum: El número mínimo de digitos. 5 en este caso. -
-minlower: El número mínimo de caracteres en minúsculas, en este caso 5. -
-minupper: El número mínimo de caracterés en mayúsculas, en este caso 3. -
-minspecial: El número mínimo de caracteres no alfanuméricos, en este caso será de 3. -
-distribute: Los caracteres de la contraseña serán distribuidos entre el lado izquierdo y derecho del teclado, esto hace más díficil que un fisgón vea la contraseña que uno está escribiendo. El valor predeterminado es falso, en este caso el valor es verdadero.
El script mostrado anteriormente lo podemos reducir a una línea, aunque preferí guardarlo en un fichero al que denomine genpasswd.pl por cuestiones de legibilidad.
Vulnerabilidad grave corregida en ubuntu
La vulnerabilidad en ubuntu donde cualquiera con acceso al shell podía ver la contraseña del instalador del sistema ha sido reparada.
Los paquetes afectados son base-config y passwd en Ubuntu 5.10 (Breezy Badger), el problema puede ser corregido al actualizar los paquetes afectados a las versiones 2.67ubuntu20 (base-config) y 1:4.0.3-37ubuntu8 (passwd). En general, una actualización del sistema es suficiente para que los cambios surtan efecto.
La vulnerabilidad en donde era posible ver la constraseña del instalador de ubuntu y así tener acceso a privilegios de superusuario (por supuesto, si la contraseña no había sido cambiada desde la instalación) fue descubierta por Karl Øie, el instalador de Ubuntu 5.10 falla en la limpieza de contraseñas en los ficheros de registros de instalación. Dichos ficheros pueden ser leidos por cualquiera, de este modo cualquier usuario local pudiese ver las contraseñas del primer usuario, el cual tiene privilegios por completo en una instalación por defecto.
El paquete actualizado eliminará las contraseñas almacenadas en texto plano en los ficheros de registro de instalación y adicionalmente hará que los registros sean leídos únicamente por el superusuario.
Esta vulnerabilidad no afecta a los instaladores de las versiones 4.10, 5.04, o la que está por llegar, 6.04. Sin embargo, considere necesario aplicar el parche si usted ha actualizado su sistema desde Ubuntu 5.10 a la actual versión en desarrollo 6.04 (Dapper Drake), en este caso verifique que ha actualizado el paquete passwd a la versión 1:4.0.13-7ubuntu2.
Vulnerabilidad en el kernel Linux de ubuntu
Este problema de seguridad únicamente afecta a la distribución Ubuntu 5.10, Breezy Badger.
Los paquetes afectados son los siguientes:
linux-image-2.6.12-10-386linux-image-2.6.12-10-686linux-image-2.6.12-10-686-smplinux-image-2.6.12-10-amd64-genericlinux-image-2.6.12-10-amd64-k8linux-image-2.6.12-10-amd64-k8-smplinux-image-2.6.12-10-amd64-xeonlinux-image-2.6.12-10-iseries-smplinux-image-2.6.12-10-itaniumlinux-image-2.6.12-10-itanium-smplinux-image-2.6.12-10-k7linux-image-2.6.12-10-k7-smplinux-image-2.6.12-10-mckinleylinux-image-2.6.12-10-mckinley-smplinux-image-2.6.12-10-powerpclinux-image-2.6.12-10-powerpc-smplinux-image-2.6.12-10-powerpc64-smplinux-patch-ubuntu-2.6.12
El problema puede ser solucionado al actualizar los paquetes afectados a la versión 2.6.12-10.28. Posterior al proceso de actualización debe reiniciar el sistema para que los cambios logren surtir efecto.
Puede encontrar mayor detalle acerca de esta información en el anuncio Linux kernel vulnerability hecho por Martin Pitt a la lista de correos de avisos de seguridad en Ubuntu.
Vulnerabilidad en Apache
Según un anuncio hecho el día de hoy por Adam Conrad a la lista de seguridad de ubuntu existe una vulnerabilidad que podría permitirle a una página web maligna (o un correo electrónico maligno en HTML) utilizar técnicas de Cross Site Scripting en Apache. Esta vulnerabilidad afecta a las versiones: Ubuntu 4.10 (Warty Warthog), Ubuntu 5.04 (Hoary Hedgehog) y Ubuntu 5.10 (Breezy Badger).
De manera adicional, Hartmut Keil descubre una vulnerabilidad en el módulo SSL (mod_ssl), que permitiría realizar una denegación de servicio (DoS), lo cual pone en riesgo la integridad del servidor. Esta última vulnerabilidad solo afecta a apache2, siempre y cuando esté usando la implementación “worker” (apache2-mpm-worker).
Los paquetes afectados son los siguientes:
apache-commonapache2-commonapache2-mpm-worker
Los problemas mencionados previamente pueden ser corregidos al actualizar los paquetes mencionados.
Vulnerabilidad en Perl
Las siguientes versiones se encuentran afectadas ante este fallo de seguridad:
- Ubuntu 4.10 (Warty Warthog)
- Ubuntu 5.04 (Hoary Hedgehog)
- Ubuntu 5.10 (Breezy Badger)
En particular, los siguientes paquetes se encuentran afectados:
libperl5.8perl-base
El problema puede ser corregido actualizando los paquetes a sus últimas versiones en las respectivas versiones de Ubuntu. En general, el modo estándar de actualizar la distribución será mas que suficiente.
$ sudo aptitude dist-upgrade
La actualización pretende solucionar una vulnerabilidad del interprete Perl, el cual no era capaz de manejar todos los posibles casos de una entrada malformada que podría permitir la ejecución de código arbitrario, así que es recomendable actualizar su sistema de inmediato.
Sin embargo, es importante hacer notar que esta vulnerabilidad puede ser aprovechada en aquellos programas inseguros escritos en Perl que utilizan variables con valores definidos por el usuario en cadenas de caracteres y en donde no se realiza una verificación de dichos valores.
Si desea mayor detalle, le recomiendo leer el anuncio hecho por Martin Pitt en [USN-222-1] Perl vulnerability.
Maestro, es Windows XP un virus?
Ps:
Háblame, estoy atento a tus palabras, mi Maestro.
M:
Los virus se reproducen rápidamente por todo el planeta.
Ps:
Bueno, windows XP hace eso.
M:
Los virus consumen varios recursos del sistema, ralentizándolo.
PS:
Bueno, windows XP también hace eso.
M:
Los virus de vez en cuando arruinan tu disco duro.
Ps:
Oopss!! pues windows XP también lo hace!
M:
Normalmente los virus se trasmiten, de forma que el usuario no lo sepa, junto con valiosos programas y sistemas.
PS:
Por los dioses del cielo!!...Windows XP hace eso también!!!
M:
Ocasionalmente los virus harán creer al usuario que su sistema es demasiado lento y el infeliz comprará hardware nuevo.
PS:
Cielos, maestro!!! eso también va con windows XP.
M:
Mira pequeño saltamontes, hasta ahora parece que windows XP es un virus, pero hay diferencias fundamentales: Los virus están bien soportados por sus autores, funcionan en la mayoría de los sistemas, su código es rápido, compacto y eficiente, y tienden a sofisticarse más y más a medida que maduran.
Ps:
Ahhhhh, entonces windows XP no es un virus.
M:
No pequeño saltamontes, no es un virus. Es un [bug!](http://es.wikipedia.org/wiki/Error_de_software).
Vía: Seguridad0.info
elixir
Oban: Testing your Workers and Configuration
In this article, I will continue talking about Oban, but I’ll focus on how to test your workers and, also, your configuration.
Oban: job processing library for Elixir
After working for years on different organizations, one common theme is scheduling background jobs. In this article, I’ll share my experience with Oban, an open-source job processing package for Elixir. I’ll also cover some features, like real-time monitoring with Oban Web and complex workflow management with Oban Pro.
Improve the codebase of an acquired product
In this article I’ll share my experience improving the codebase of an acquired product, this couldn’t be possible without the help of a fantastic team. Before diving into the initial diagnostic and strategies that we took to tackle technical debt, I’ll share some background around the acquisition. Let’s start.
Elixir’s MIME library review
Elixir’s MIME is a read-only and immutable library that embeds the MIME type database, so, users can map MIME (Multipurpose Internet Mail Extensions) types to extensions and vice-versa. It’s a really compact project and includes nice features, which I’ll try to explain in case you’re not familiar with the library. Then, I’ll focus on MIME’s internals or how was built, and also how MIME illustrates in an elegant way so many features of Elixir itself.
Follow-up: Function currying in Elixir
NOTE: This article is a follow-up examination after the blog post Function currying in Elixir by @stormpat
In his article, Patrik Storm, shows how to implement function currying in Elixir, which could be really neat in some situations. For those who haven’t read Patrik’s post, first, let us clarify what is function currying.
Currying is the process of transforming a function that takes multiple arguments (arity) into a function that takes only one argument and returns another function if any arguments are still required. When the last required argument is given, the function automatically executes and computes the result.
Asynchronous Tasks with Elixir
One of my first contributions into ExDoc, the tool used to produce HTML documentation for Elixir projects, was to improve the documentation build process performance. My first approach for this was to build each module page concurrently, manually sending and receiving messages between processes. Then, as you can see in the Pull Request details, Eric Meadows-Jönsson pointed out that I should look at the Task module. In this article, I’ll try to show you the path that I followed to do that contribution.
Elixir: Primeras impresiones
Elixir: Primeras impresiones
NOTA: Este artículo originalmente lo escribí para La Cara Oscura del Software, un blog colectivo dedicado a desarrollo de software.
Durante el segundo hangout de @rubyVE escuché
a @edgar comentar sobre Elixir y en verdad
me llamó la atención lo que indicaba, siempre me inquieta conocer al menos un
poco sobre otros lenguajes de programación, siempre terminas aprendiendo algo,
una buena lección es seguro, sobre todo por aquello de la filosofía del
programador pragmático y la necesidad de invertir regularmente en tu portafolio
de conocimientos.
Ahora bien, después de leer un artículo de Joe Armstrong, padre de Erlang, en donde afirmaba que tras una semana de haber usado Elixir estaba completamente entusiasmado por lo visto. Con esto era claro que se estaba presentando para mi una gran oportunidad para retomar la programación funcional con Elixir, inicié con Haskell en la Universidad en la materia de Compiladores y la verdad es que no lo he vuelto a tocar.
José Valim es un brasileño, parte del equipo core committer de Rails. Después de sufrir RSI, en su afán por encontrar qué hacer en su reposo se puso a leer el libro: Seven Languages in Seven Weeks: A Pragmatic Guide to Learning Programming Languages y allí conoció Erlang y su EVM (Erlang Virtual Machine), cierto tiempo después creo este nuevo lenguaje llamado Elixir, en donde uno de sus mayores activos es la EVM, tanto es así que de hecho no existe un costo de conversión al invocar Erlang desde Elixir y viceversa. Todo esto es seguramente es la respuesta de Valim a las limitantes físicas actuales en los procesadores o lo que se conoce también como: “se nos acabó el almuerzo gratis”, sobre todo ahora con recientes anuncios de Parallella y de Intel con los procesadores Xeon Phi.
A pesar de la horrible sintaxis de Erlang, o al menos después de leer a Damien Katz, autor original de CouchDB en What Sucks About Erlang y a Tony Arcieri, autor de Reia (otro lenguaje basado en BEAM), en su artículo The Trouble with Erlang (or Erlang is a ghetto) es fácil concluir que la sintaxis no es la más amenas de todas. Sin embargo, las inmensas habilidades que brinda Erlang para establecer sistemas concurrentes (distribuidos, tolerantes a fallas y code swapping) ha permitido llegar a mantener hasta 2 millones de conexiones TCP en un solo nodo. Es por ello que compañías como Whatsapp, Facebook, Amazon, Ericsson, Motorola, Basho (Riak) y Heroku por mencionar algunas están usando Erlang para desarrollar sus sistemas.
Rápidamente quisiera compartirles mi felicidad por haber iniciado a explorar este lenguaje. Para iniciar tu proyecto tienes un magnífico utilitario llamado mix (inspirado en Leiningen de Clojure). Mix también permite manejar las tareas más comunes como administración de dependencias de tu proyecto, compilación, ejecución de pruebas, despliegue (pronto), entre otras. Incluso puedes programar nuevas tareas, simplemente asombroso, en fin, vamos a jugar:
$ mix help
mix # Run the default task (current: mix run)
mix archive # Archive this project into a .ez file
mix clean # Clean generated application files
mix cmd # Executes the given command
mix compile # Compile source files
mix deps # List dependencies and their status
mix deps.clean # Remove the given dependencies' files
mix deps.compile # Compile dependencies
mix deps.get # Get all out of date dependencies
mix deps.unlock # Unlock the given dependencies
mix deps.update # Update the given dependencies
mix do # Executes the tasks separated by comma
mix escriptize # Generates an escript for the project
mix help # Print help information for tasks
mix local # List local tasks
mix local.install # Install a task or an archive locally
mix local.rebar # Install rebar locally
mix local.uninstall # Uninstall local tasks or archives
mix new # Creates a new Elixir project
mix run # Run the given file or expression
mix test # Run a project's tests
Procedamos con la creación de un nuevo proyecto:
$ mix new demo
* creating README.md
* creating .gitignore
* creating mix.exs
* creating lib
* creating lib/demo.ex
* creating test
* creating test/test_helper.exs
* creating test/demo_test.exs
Your mix project was created with success.
You can use mix to compile it, test it, and more:
cd demo
mix compile
mix test
Run `mix help` for more information.
La estructura del proyecto creado por mix es como sigue:
$ cd demo
$ tree
.
|-- README.md
|-- lib
| `-- demo.ex
|-- mix.exs
`-- test
|-- demo_test.exs
`-- test_helper.exs
2 directories, 5 files
En mix.exs encontramos la configuración del proyecto así como sus dependencias
en caso de aplicar, en lib/demo.ex ubicamos la definición del módulo que nos
ayudará a estructurar posteriormente nuestro código, en test/test_demo.exs
encontramos un esqueleto base para los casos de pruebas asociadas al modulo.
Finalmente en test/test_helper.exs radica inicialmente el arranque del
framework ExUnit.
Creemos un par de pruebas sencillas primero:
$ vim test/demo_test.exs
defmodule DemoTest do
use ExUnit.Case
test "factorial base case" do
assert Demo.factorial(0) == 1
end
test "factorial general case" do
assert Demo.factorial(10) == 3628800
end
test "map factorial" do
assert Demo.map([6, 8, 10], fn(n) -> Demo.factorial(n) end) == [720, 40320, 3628800]
end
end
Evidentemente al hacer “mix test” todas las pruebas fallaran, vamos a comenzar a subsanar eso:
$ vim lib/demo.ex
defmodule Demo do
def factorial(0) do
1
end
def factorial(n) when n > 0 do
n * factorial(n - 1)
end
end
En el par de bloques de código mostrado previamente se cubren los dos casos posibles del factorial.
Volvamos a correr las pruebas:
$ mix test
..
1) test map factorial (DemoTest)
** (UndefinedFunctionError) undefined function: Demo.map/2
stacktrace:
Demo.map([6, 8, 10], #Function<0.60019678 in DemoTest.test map factorial/1>)
test/demo_test.exs:13: DemoTest."test map factorial"/1
Finished in 0.04 seconds (0.04s on load, 0.00s on tests)
3 tests, 1 failures
De las 3 pruebas programadas hemos superado dos, nada mal, continuemos, volvamos a editar nuestro módulo:
$ vim lib/demo.ex
defmodule Demo do
def factorial(0) do
1
end
def factorial(n) when n > 0 do
n * factorial(n - 1)
end
def map([], _func) do
[]
end
def map([head|tail], func) do
[func.(head) | map(tail, func)]
end
end
En esta última versión se ha agregado la función map, básicamente esta función
recibe una colección de datos y una función que se aplicará sobre cada uno de
los elementos de la colección, para nuestros efectos prácticos la función que
será pasada a map será el factorial.
Como nota adicional, los bloques de código vistos en el ejemplo anterior prefiero expresarlos de manera sucinta así, cuestión que también es posible en Elixir:
$ vim lib/demo.ex
defmodule Demo do
@moduledoc """
Demo module documentation, Python *docstrings* inspired.
"""
def factorial(0), do: 1
def factorial(n) when n > 0, do: n * factorial(n - 1)
def map([], _func), do: []
def map([head|tail], func), do: [func.(head) | map(tail, func)]
end
Acá se pueden apreciar conceptos como pattern matching, guard clauses, manejo de listas y docstrings (inspirado en Python). Atención, los docstrings soportan MarkDown, junto a ExDoc es posible producir sitios estáticos que extraen los docstrings a partir del código fuente.
Comprobemos los casos desde la consola interactiva iex antes de pasar de nuevo
al caso automatizado:
$ iex lib/demo.ex
Erlang R16B01 (erts-5.10.2) [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (0.10.2-dev) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> import Demo
nil
iex(2)> h(Demo)
# Demo
Demo module documentation, Python *docstrings* inspired.
iex(3)> Demo.factorial(10)
3628800
iex(4)> Demo.map([6, 8, 10], Demo.factorial(&1))
[720, 40320, 3628800]
Lo previo es una consola interactiva, vimos la documentación e hicimos unas pruebas manuales.
Seguro notaron que al final del ejemplo previo, al hacer el map he cambiado la
forma en la que invoco a la función anónima la cual originalmente fue definida
en las pruebas como fn(n) -> Demo.factorial(n) end, solamente he recurrido a
un modo que permite Elixir y otros lenguajes funcionales para expresar este tipo
de funciones de manera concisa, se le conoce como Partials.
Ahora corramos las pruebas automatizadas de nuevo:
$ mix test
Compiled lib/demo.ex
Generated demo.app
...
Finished in 0.04 seconds (0.04s on load, 0.00s on tests)
3 tests, 0 failures
Con eso hemos pasado los casos de pruebas.
En este caso particular, prefiero que las pruebas sean autocontenidas en el módulo, además, no recurrimos a fixtures ni nada por el estilo, así que vamos a cambiar el código para que soporte doctest
$ vim lib/demo.ex
defmodule Demo do
@moduledoc """
Demo module documentation, Python *docstrings* inspired.
"""
@doc """
Some examples
iex> Demo.factorial(0)
1
iex> Demo.factorial(10)
3628800
iex> Demo.map([6, 8, 10], Demo.factorial(&1))
[720, 40320, 3628800]
"""
def factorial(0), do: 1
def factorial(n) when n > 0, do: n * factorial(n - 1)
def map([], _func), do: []
def map([head|tail], func), do: [func.(head) | map(tail, func)]
end
Dado lo anterior ya no es necesario tener las pruebas aparte, por lo que reduzco:
$ vim test/demo_test.exs
defmodule DemoTest do
use ExUnit.Case
doctest Demo
end
Comprobamos la equivalencia:
$ mix test
...
Finished in 0.06 seconds (0.06s on load, 0.00s on tests)
3 tests, 0 failures
Simplemente hermoso, cabe resaltar que lo mencionado es solo rascar un poco la superficie de Elixir :-)
Ah, por cierto, ya para finalizar, José Valim está apuntando el desarrollo de Elixir y Dynamo (framework) a la Web, lo ha dejado claro, por eso he visto que algunos programadores Rails están “echándole un ojo” a Elixir, al menos eso es lo que concluyo de los elixir-issues en Github, el reciente screencast de Peepcode (vale la pena comprarlo) y los libros que se avecinan de Dave Thomas y Simon St. Laurent.
Quizá en una nueva oportunidad hablemos de Macros, pase de mensajes entre
procesos, Protocolos (inspirados en Clojure
protocols), Reducers (inspirados también en
Clojure
Reducers),
HashDict, el hermoso y *nix like operador pipeline (|>), mejorar nuestra
implementación de la función map para que haga los cálculos de manera
concurrente, entre otros.
Espero hayan disfrutado la lectura, que este artículo sirva de abreboca y les anime a probar Elixir.
software+libre
gUsLA: Grupo de Usuarios de Software Libre de la Universidad de Los Andes
Un grupo de compañeros de estudio y mi persona por fin hemos iniciado una serie de actividades para formar el Grupo de Usuarios de Software Libre de la Universidad de Los Andes.
El día de hoy, hicimos entrega de una carta al Consejo de Escuela de Ingeniería de Sistemas, solicitando un aval académico para lograr llevar a cabo las siguientes actividades:
- Charlas.
- Festivales de instalación.
- Atención al usuario.
- Otras actividades de naturaleza académica.
Esta solicitud la hicimos ya que consideramos necesaria la creación de un Grupo de Usuarios que se encargue de:
- Difundir y promover el Software Libre en la Universidad de los Andes.
- Difundir las bases filosóficas detrás del modelo del Software Libre.
- Demostrar la calidad técnica del Software Libre.
- Demostrar a los usuarios finales cuan fácil es utilizar GNU/Linux.
- Fomentar el intercambio de conocimientos en Talleres, Foros, Charlas y/o encuentros con grupos de usuarios de otras latitudes.
- Adaptación al proceso de cambio fomentado por el ente público (decreto 3390).
En este momento hemos contactado a ciertos profesores que han mostrado interés en la iniciativa, la idea es involucrar a todas aquellas personas relacionadas con la Universidad de Los Andes.
En resumen, el objetivo principal que pretende alcanzar nuestro grupo es: El estudio, desarrollo, promoción, difusión, educación, enseñanza y uso de sistemas operativos GNU/Linux, GNU/Hurd, FreeBSD, y de las herramientas libres que interactúan con estos, tanto en el ámbito nacional como en el internacional. Es importante resaltar en este instante que No se perseguirán fines de lucro, ni tendremos finalidades o actividades políticas, partidistas ni religiosas; seremos un grupo apolítico, abierto, pluralista y con fines académicos.
Personalmente, debo agradecer a José Parrella por haberme facilitado un borrador del documento constitutivo/estatutario del Grupo de Usuarios de Linux de la Universidad Central de Venezuela (UCVLUG), lo hemos utilizado como base para formar el nuestro, aunque será discutido por ahora en una lista privada de estudiantes y profesores que han manifestado interés en participar.
Esperamos con ansiedad la decisión del Consejo de Escuela de Ingeniería de Sistemas.
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Charla: Libre como un Mercado Libre
El Consejo de Computación Académica, la Corporación Parque Tecnológico de Mérida y el Centro Nacional de Cálculo Científico de la Universidad de Los Andes, invitan a la charla Libre como un Mercado Libre, cuyo ponente será el Profesor Jacinto Dávila.
El objetivo de la charla básicamente es el siguiente:
En esta presentación, pretendemos argumentar en favor de “libre como en el mercado libre”, una manera quizás desesperada de enfatizar el valor social del nuevo espacio para los negocios que se abre con el Software Libre. El Software Libre no es software gratis. De hecho, quienes desarrollen así pueden seguir cobrando lo que quieran por su trabajo, siempre que no impidan que otros conozcan los códigos fuentes, los usen y los compartan sin restricciones. Lamentablemente, las animosidades, sobretodo las políticas, están nublando toda discusión al respecto y destrozando el mayor logro del software libre: devolver a los tecnólogos a la especie humana.
Información adicional:
- Fecha: Jueves 2 de Marzo.
- Hora: 2:30 pm.
- Lugar: Núcleo La Hechicera, Facultad de Ciencias, Nivel Patio, Salón A9.
- Costo: Entrada Libre.
Algunas referencias que se recomienda leer.
- Petróleo por Software: La energía de los hidrocarburos y la apuesta a futuro con el Software Libre.
- El Copyleft es derechista (también)
Ambos artículos escritos por el profesor Jacinto Dávila.
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
CSS
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
Cómo mejorar la presentación de nuestros bloques de código
El día de ayer en la entrada Ctrl + Alt + Supr en
ubuntu el amigo (gracias al
canal ubuntu-es en el servidor Freenode) Red me
preguntaba lo siguiente:
quisiera saber que plugin de WP usas para que salga en un recuadro los comandos de la terminal?
Ahora bien, como en principio la pregunta no tiene que ver con la temática de la entrada, además, mi respuesta puede que sea algo extensa, prefiero responderle a través de esta entrada.
En realidad para la presentación de los bloques de código no hago uso de ningún agregado, solo uso correctamente (sin animos de parecer ostentoso) las etiquetas que nos ofrece el lenguaje de marcado XHTML (lenguaje extensible de marcado de hipertexto), dándole semántica a la estructura de la entrada, la presentación de dicho bloque de código lo realizo a través del uso de CSS (hojas de estilo en cascada).
En primer lugar vamos a ver como debe ser la estructura de los bloques de código.
<code><pre><code>#include <iostream>
int main()
{
std::cout << "Hola Mundo!!!" << std::endl;
return 0;
}
</code></pre></code>
Vea el ejemplo #1.
El bloque de código anterior muestra un programa muy sencillo en C++.
Estructura XHTML
Es hora de definir algunos conceptos muy interesantes.
El elemento <pre>
En primer lugar debemos recordar que el elemento <pre> es un elemento en bloque, los agentes de usuario visuales entenderán que el texto contenido dentro de este elemento vendrá con un formato previo.
Lo anterior implica ciertas ventajas, por ejemplo, pueden dejarse espacios en blanco, los cuales serán interpretados tal cual como se manifiestan de manera explícita. Adicionalmente, se pueden representar fuentes de ancho fijo dentro de estos bloques.
El elemento <code>
El elemento es un elemento en línea, la semántica detrás de este
elemento es indicar segmentos de código.
Mejorando la presentación del bloque de código
Una vez que comprendamos la estructura que deben seguir nuestros bloques de código, debemos hacer uso de las hojas de estilos en cascada para la presentación de dichos bloques. Esto será necesario realizarlo una sola vez.
Mi gusto particular es centrar los bloques de código, esto no tiene porque ser entonces una regla estándar, a continuación describiré como realizar esto vía CSS, solamente debemos seguir las siguientes reglas.
<code>pre{
text-align: center;
width: 30em;
margin: 1em auto;
white-space: pre; /* CSS 2 */
}
pre code{
display: block;
text-align: left;
}</code>
Vea el ejemplo #2.
Al selector pre le he asignado una anchura de 30em, este valor es relativo
a la fuente, pero también podría especificarse en px, es importante resaltar
que haciendo uso de la unidad em se permite generar un bloque líquido.
La declaración que está realizando todo el trabajo de centrar el bloque es
margin: 1em **auto**;, en ella se indica que tanto el margen superior como
inferior sea de 1em, de igual manera se especifica que tanto el margen
izquierdo como el derecho sean auto, por lo tanto, sus valores serán iguales,
esto nos asegura que la caja quede centrada.
Ahora bien, para brindar mayor accesibilidad a nuestro bloque de código, será
necesario hacer uso de la propiedad text-align: center; en el selector pre,
la razón por la cual se usa la declaración anterior es para brindar una buena
presentación en aquellos usuarios de IE5 bajo sistemas Windows. Sin esta regla,
la mayoría de los agentes de usuario visuales podrán mostrar el bloque de
código centrado, pero no aquellos usuarios de IE5/Win.
La declaración white-space: pre; se utiliza para especificar como serán
tratados los espacios en blanco dentro del elemento. Cuando se indica el
valor pre los agentes de usuario visuales impedirán el cierre de las
secuencias de espacios en blanco.
Finalmente, en el selector pre code, debemos reescribir la declaración de
alineación del texto (text-align). En ella estamos alineando el texto de
nuevo a la izquierda, si no lo hacemos, el texto se mostrará centrado debido a
la declaracion de alineación de texto en el selector pre.
El uso de la declaración display: block; modifica la manera en que se muestra
el elemento code, como se mencionó previamente, el elemento code es un
elemento en línea, al hacer uso de esta instrucción, nos permitirá mostrar al
elemento code como un elemento en bloque.
Ahora bien, todavía existe una interrogante que debemos contestar, dicha interrogante es: ¿Qué sucede si el contenido del bloque de código es demasiado extenso horizontalmente?, simplemente el texto se desbordará por encima del bloque, esto es un problema, pero existen dos maneras de solucionarlo.
¿Cómo solucionar un posible desborde del contenido sobre el bloque de código?
La primera solución que podriamos pensar es hacer uso de la declaración
overflow: auto;, la propiedad overflow especifica si el contenido de un
elemento en bloque puede ser recortado o nó cuando éste desborda a dicho
elemento. El valor auto nos permite proporcionar un mecanismo de
desplazamiento en el caso de aquellas cajas que presenten un desborde.
La solución anterior también implica otra inquietud, en este caso particular, la usabilidad, según el gurú de la usabilidad, Jakob Nielsen, los usuarios detestan el tener que hacer uso de las barras de desplazamiento horizontales, el parecer el desplazamiento vertical parece estar bien, puesto que es más común.
Por los motivos descritos en el párrafo anterior, el hacer uso de la barra de desplazamiento horizontal no es la mejor solución. Veamos la solucion definitiva.
La única posibilidad que tenemos para evitar hacer uso de la barra de desplazamiento horizontal es que al ocurrir un desborde, el contenido que desborda pase a la siguiente línea.
Ahora bien, lo que se mostrará a continuación puede resultarle confuso, no se preocupe, trataré de explicarlo, pero recuerde, no soy ningún experto, solo un entusiasta :)
<code>pre{
/* Reglas especificas para algunos navegadores y CSS 3 */
white-space: -moz-pre-wrap; /* Mozilla, soportado desde 1999 */
white-space: -hp-pre-wrap; /* Impresoras HP */
white-space: -o-pre-wrap; /* Opera 7 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: pre-wrap; /* CSS 2.1 */
white-space: pre-line; /* CSS 3 (y 2.1 tambien, actualmente) */
word-wrap: break-word; /* IE 5.5+ */</code>
Vea el archivo maestro.
La versión original del código mostrado previamente pertenece a Ian Hickson quien distribuye su trabajo bajo licencia GPL.
Bajo CSS2, no existe una manera explícita de indicar
que los espacios y nuevas líneas deban preservarse, pero en el caso en el cual
el texto alcance el extremo del bloque que le contiene, se le puede envolver.
Lo más cercano que nos podemos encontrar es white-space: pre, sino no es
posible envolverlo. Antes de que CSS2.1 sea la
recomendación candidata, los agentes de usuario no podrán implementarla, por
eso se han implementado ciertas extensiones propietarias, en el código mostrado
previamente se muestran todas estas posibilidades, los agentes de usuario
tomarán aquellas declaraciones que soporten.
La declaración word-wrap: break-word es una extensión propietaria de IE, la
cual no es parte de ningún estándar.
Para dejar las cosas en claro, pre-wrap actúa como pre pero cubrirá cuando
sea necesario, mientras que pre-line actúa como normal pero preserva nuevas
líneas. Según la opinión de Lim Chee
Aun, la propiedad pre-wrap será
realmente útil en aquellos casos en los cuales deban mostrarse largas líneas de
código que posiblemente desborden en otros elementos o simplemente se muestren
fuera de pantalla.
Ahora bien, ¿qué hay del soporte de los agentes de usuario visuales?, bien, la
mayoría de los navegadores modernos soportan correctamente la propiedad pre,
normal y nowrap. Firefox soporta la propiedad -moz-pre-wrap pero no
soporta pre-wrap y pre-line todavía. Opera 8 soporta pre-wrap incluyendo
sus extensiones previas, -pre-wrap y -o-pre-wrap, pero no pre-line.
Referencias:
Reduciendo el tamaño de tus hojas de estilos, una revisión
Hace pocos días atrás comenté acerca de la reducción en el tamaño en bytes de las hojas de estilo en cascada a través del uso de CSScompiler, en esta ocasión presentaré otras herramientas que cumplen el mismo fin, unas lo llevan a cabo mejor que otras.
Nacho, uno de los responsables de Microsiervos, nos presenta dos alternativas más, la primera de ellas es CSS Optimiser, si lo desea puede leer acerca de CSS Optimiser para obtener mayor información. De todas maneras, a continuación un resúmen de las características de esta herramienta.
Características de CSS Optimiser
- Elimina los comentarios.
- Elimina los espacios en blancos (por ejemplo, el exceso de espacios).
- Opción que permite convertir valores RGB a Hexadecimal (estos últimos son más pequeños).
- Convierte valores hexadecimales bajo el formato #RRGGBB a #RGB.
- Produce cambios en los valores, como por ejemplo
border: 1px 2px 1px 2px;enborder: 1px 2px; - Convierte múltiples atributos de
background,font,margin,padding,listen una simple lista de atributos. - Convierte múltiples valores de la propiedad
borderen una simple lista de atributos. - Se da la opción de convertir valores absolutos (por ejemplo:
pxopt) en valores relativos (em). - Agrupa atributos y valores de estilos que aparecen en varias ocasiones en un solo estilo.
Ahora bien, la segunda alternativa que nos plantea Nacho, CSS Compressor solo nos brinda la oportunidad de eliminar los espacios en blancos y fusionar lo mayor posible el contenido, por ejemplo:
Código fuente CSS original:
body{
/* Propiedades de fondo */
background-color:#666666;
background-image: url(image.png);
background-position: bottom right;
background-repeat: no-repeat;
background-attachment: fixed;
font-size: 100%;
}
Resultado:
body{background-color:#666666;background-image:url(image.png);background-position:bottom right;background-repeat:no-repeat;background-attachment:fixed;font-size:100%}
Para muchos este nuevo formato puede ser practicamente ilegible, es cierto, pero en realidad ofrece cierta reducción al tamaño de las hojas de estilos en cascada.
Continuando con el tema, Zootropo nos propone en su artículo ¡Adelgazar es fácil! una nueva herramienta a las expuestas anteriormente, esta herramienta es CSS Formatter and Optimiser, esta herramienta llega a cumplir a cabalidad con la funcionalidad que propone CSS Compressor, entre otras características, como la optimización del código CSS. CSS Formatter and Optimiser es una excelente herramienta, muy poderosa y posee muchas opciones para el usuario. Vamos a describirlas brevemente.
Opciones que ofrece CSS Formatter and Optimiser
- Compresión máxima (ninguna legibilidad, tamaño más pequeño)
- Compresión moderada (legibilidad moderada, tamaño reducido)
- Compresión estándar (equilibrio entre legibilidad y tamaño)
- Compresión baja (legilibilidad más alta)
- Compresión personalizada, puede elegir entre:
- Ordenar los selectores.
- Ordenar las propiedades.
- Fusionar aquellos selectores que posean las mismas propiedades.
- Fusionar aquellas propiedades en las que aplique el shorthand CSS.
- Comprimir el formato del color, si el formato está en RGB se lleva a Hexadecimal, si está en hexadecimal también trata de reducir su formato en aquellos casos que aplique el shorthand CSS.
- Convierte los selectores a minúsculas.
- Casos especiales para las propiedades:
- Convertir a minúsculas.
- Convertir a mayúsculas.
- Eliminar los simbolos
\innecesarios.
- Se ofrece la opción de guardar la salida en un fichero, lo que le permitirá ahorrar tiempo entre copiar y pegar en su editor de hojas de estilos en cascada favorito.
Pruebas
A continuación se realizarán una serie de pruebas, estas estarán basadas únicamente en dos parámetros, legibilidad y tamaño de los ficheros generados. Todas las pruebas hechas parten de un mismo fichero CSS, él código mostrado en este fichero presenta gran cantidad de comentarios y precario (adrede) uso de shorthands.
Tabla de Resultados
Herramienta
Característica
Antes
Después
Ahorro
CSS Optimiser
Caracteres
3143
601
2542
Lineas
128
41
N/A
Legibilidad
Muy alta
Alta
N/A
Porcentaje
N/A
N/A
81%
CSS Formatter & Optimiser
Caracteres
3143
802
2341
Lineas
128
57
N/A
Legibilidad
Muy alta
Alta
N/A
Porcentaje
N/A
N/A
74%
CSS Compressor
Caracteres
3143
1225
1918
Lineas
128
1
N/A
Legibilidad
Muy alta
Muy baja
N/A
Porcentaje
N/A
N/A
61%
CSScompiler
Caracteres
3143
1230
1913
Lineas
128
8
N/A
Legibilidad
Muy alta
Baja
N/A
Porcentaje
N/A
N/A
61%
N/A: No aplica
Observaciones
CSS Optimiser maneja muy bien la reducción de las declaraciones cuando es aplicable el shorthand, algo en lo falla un poco CSS Formatter & Optimiser, aunque éste último ofrece bastantes opciones, por lo que es bueno tomarlo en cuenta a la hora de reducir el tamaño en bytes de nuestras hojas de estilos. Si queremos hacer uso de CSS Optimiser y aún deseamos obtener una mayor compresión, es posible obtenerla si combinamos el resultado obtenido con la herramienta CSS Compressor, el cual eliminará los espacios existentes. Quizás la única falla que percibi en CSS Optimiser fue que aún no maneja adecuadamente las reducciones de aquellas reglas que presentan declaraciones comunes, leyendo ciertas notas del autor, me doy cuenta que está trabajando en ello.
He trabajado con una hoja de estilos bastante comentada y sin utilizar propiedades abreviadas (adrede) para realizar las pruebas, a continuación muestro los enlaces a cada uno de los ficheros de las hojas de estilos.
- Hoja sin ninguna compresión, original
- Hoja de estilos utilizando CSS Optimiser
- Hoja de estilos utilizando CSS Fomatter & Optimiser
- Hoja de estilos utilizando CSS Compressor
- Hoja de estilos utilizando CSScompiler
Si conoces alguna herramienta que permita la reducción del tamaño en bytes de las hojas de estilo en cascada no dudes en comentarlo, de esta manera, podría ampliar la revisión nuevamente.
CSScompiler, reduce el tamaño de tus hojas de estilos
Daniel Mota recientemente ha lanzado CSScompiler 1.0, se trata de un script que reduce al máximo el peso en bytes (unidad básica de almacenamiento de información) de tus hojas de estilo, esto puede ser significativo si existe excesiva cantidad de peticiones a dichos ficheros, el beneficio es ahorrar ancho de bando en nuestros servidores.
Ahora bien, ¿qué hace CSScompiler para reducir el tamaño de las hojas de estilos en cascada?, simplemente elimina los comentarios, saltos de líneas y el último punto y coma antes del cierre de los corchetes, además, se ofrecen otras funcionalidades que mejoran la sintaxis e interpretación de algunas propiedades.
Puedes obtener una descripción más detallada en el artículo CSScompiler. En el mismo artículo podrás encontrar dos ejemplos (uno compilado y el otro sin compilar) que te darán una idea acerca de la funcionalidad de este script.
Rediseñando NNL Newsletter II
En este artículo se mostrará la facilidad de emplear hojas de estilos en cascada o CSS cuando poseemos una buena estructura en nuestros documentos. Como estructura vamos a utilizar una modificación que he realizado de la primera edición de NNL Newsletter. La edición de la estructura se ha explicado en el artículo Rediseñando NNL Newsletter I.
Estableciendo valores a los márgenes y rellenos
Usualmente mi primera regla en CSS es establecer los márgenes y rellenos de todos los elementos XHTML (o HTML) a cero (0), ¿por qué hacer esto?, simplemente porque los Agentes de Usuario (p.ej. Navegadores) implementan distintas reglas sobre estas dos propiedades. Desde mi punto de vista, la mejor forma de controlar estas diferencias es ir estableciendo los valores de dichas propiedades de acuerdo a las necesidades que tengamos, aunque previamente se han inicializado a cero.
Muestra de ejemplo en CSS
<code>*{
margin: 0;
padding: 0;
}</code>
Creando nuestro Layout
Antes que nada debemos pensar en que tipo de contenido mostraremos y que extensos serán estos. En nuestro ejemplo de análisis, NNL Newsletter se basa principalmente en texto, estos textos suelen ser extensos, por lo que debemos ser precavidos a la hora de mostrarlos, la lectura no debe “cansar” al lector, debemos mostrar el mayor contraste posible. Partiendo de las características del sitio en particular, podemos concluir que lo mejor es implantar un layout elástico, este tipo de diagramación simplemente se basa en el concepto de medidas relativas tanto en los bloques de la página como en las tipografías, por lo que al usuario se le facilitará la ampliación (o disminución) de los elementos mostrados desde el panel de control del navegador.
Inicialmente vamos a centrar la página.
Muestra de ejemplo en CSS
<code>body{
text-align: center;
}
#wrapper{
margin: 3em auto;
width: 35em;
text-align: left;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
En las dos reglas anteriores, quien realmente hace el trabajo de centrado del documento es la declaración margin: 3em auto;, en donde se especifica que tanto el margen superior como el margen inferior sean iguales a 3em, los márgenes izquierdo y derecho tomarán valores automáticos idénticos, lo cual centrará nuestro documento, ahora bien, para que la declaración anterior funcione correctamente debe especificarse la anchura del bloque que queremos centrar, en nuestro ejemplo hemos seleccionado el valor de 35em. Respecto a la utilización de la declaración text-align sobre el selector body simplemente es para ampliar la compatibilidad de nuestro diseño con los usuarios de IE5 en sistemas Windows, sin dicha declaración la mayoría de los navegadores aún muostrarían el layout centrado, pero IE5/Win no.
Respecto al valor que se le ha asignado a la propiedad width que aplicara sobre el bloque #wrapper, la explicación dada por Nicolás Fantino en el artículo Ni fijo, ni líquido. Elástico, seguramente aclarará las posibles dudas.
Cualquiera que se haya dedicado en algún momento de su vida al diseño gráfico editorial sabrá que existen, o al menos habrá escuchado hablar de, ciertas normas o convenciones. Una de ellas define lo que se considera el ancho óptimo de una línea de texto para ser leído en bloque. Éste es de entre 30 em y 35 em. La unidad de medida de este ancho es el “em”. Un “em” mide exactamente el ancho de la letra “M” mayúscula de una tipografía dada y a un tamaño dado. Efectivamente, según esta definición un “em” no mide físicamente siempre lo mismo. ¿Por qué se usa esta medida? porque el ancho óptimo para la lectura dependerá, necesariamente, del tipo de letra que se use y, más necesariamente aún, del tamaño de ésta.
Para ampliar la compatibilidad del layout elástico con el navegador IE (sí, otra vez), debemos previamente definir un valor cuya unidad de medida sea el porcentaje a la tipografía en el selector body, por ejemplo:
<code>body{
font-size: 85%;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
Posteriormente dejaremos de usar la unidad de medida porcentaje, de ahora en adelante utilizaremos como unidad de medida em.
Antes de continuar, vamos a “maquillar” un poco nuestro layout.
<code>body{
font: 85%/145% "Trebuchet MS", Arial, Verdana, sans-serif;
color: #333;
border-top: 5px solid #bbb;
background: #eee url(bg-bottom.png) repeat-x bottom left fixed;
}
#wrapper{
border: 1px solid #bbb;
border-top: 5px solid #bbb;
background: #fff;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
Solamente hemos “jugado” un poco con los valores de: fuentes, colores, bordes y fondos. Se han utilizado modos abreviados de escritura de código CSS para ahorrarnos unos cuantos bytes.
Sustituyendo texto por una imagen
Desde mi punto de vista, es preferible no hacer uso de imágenes como título más importante, es conveniente utilizar un encabezado h1, pero a veces resulta conveniente sustituir ese título por el logo del sitio en particular, existen muchos métodos para hacerlo a través de CSS, yo utilizaré el método Shea Enhancement planteado por Dave Shea al final del artículo Revised Image Replacement
Nos aprovecharemos de la siguiente estructura en XHTML.
<code><h1 id="header" title="NNL Newsletter"><a href="http://www.nnlnews.com/"><span></span>NNL Newsletter</a></h1></code>
La imagen que sustituirá al título tiene una anchura de 134px y una altura de 130px. Ahora recurrimos a CSS y hacemos lo siguiente:
<code>h1{
font-size: 1.2em;
}
#header{
width: 134px;
height: 130px;
position: relative;
}
#header span{
background: url(logo.png) no-repeat top left;
width: 100%;
height: 100%;
position: absolute;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
Notas
Carlos Tori, encargado de la redacción de NNL Newsletter, acostumbra colocar un párrafo de notas al principio de las distintas ediciones, para distinguir dicho párrafo, hemos creado un clase llamada note, funciona de la siguiente manera:
<code>p{
margin: 0 1em 0.5em 1em;
}
p.note{
border-top: 2px solid #666;
background: #f5f5f5;
padding: 1em;
margin: 1em 0;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
En primera instancia declaramos los márgenes necesarios a todos los párrafos (p), luego vamos al caso particular de la nota, la cual, consiste de una párrafo cuya clase sea igual a note.
Listas Ordenadas
Carlos Tori, siempre coloca una lista ordenada de los puntos que tratará en la edición de NNL Newsletter, es conveniente implantar una lista ordenada de enlaces, esto facilitará el acceso a los diversos puntos que se tratan.
<code>ol{
margin: 1em 3em;
}
ol li{
list-style-type: none;
background: url(bullet.png) no-repeat left center;
padding-left: 16px;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
La primera regla aplica sobre las listas ordenadas, en ella establecemos los márgenes. En la segunda regla, en primera instancia evitamos mostrar el marcador de los ítems de la lista, esto lo hacemos a través de la propiedad list-style-type con un valor igual a none, luego empleamos la propiedad background para colocar un marcador de los ítems partiendo de una imagen, la cual estará posicionada hacia la izquierda horizontalmente y estará posicionada verticalmente en la parte central, esto se logra con las palabras claves left y center respectivamente, antes de finalizar la segunda regla, controlamos el relleno izquierdo con un valor fijo.
Listas de definición
De acuerdo a la estructura de NNL Newsletter, normalmente se plantea un tópico e inmediatamente se procede a describirlos, como Carlos define ciertos tópicos, me parece adecuado agruparlos dentro de una lista de definiciones. Ahora bien, vamos a “maquillar” dichas listas a través de las hojas de estilos en cascada.
Primero, vamos a encargarnos de los títulos de las definiciones.
<code>dt{
font-weight: bold;
font-size: 1.1em;
background: #eee;
margin-top: 14px;
padding: 6px 6px 7px 12px;
border-top: 2px solid #bbb;
}</code>
En la regla anterior, vamos a darle cierto peso (font-weight) a los títulos, definimos el tamaño de la fuente (font-size), seleccionamos un color de fondo (background), establecemos un margen superior (margin-top), establecemos los rellenos (padding) y finalmente decoramos los títulos con un borde superior (border-top).
Ahora definamos los rellenos de las descripciones de las definiciones.
<code>dd{
padding: 6px 6px 10px 8px;
}</code>
Vea el resultado de aplicar la regla de estilo a la estructura del documento.
Si detalla la muestra anterior, puede darse cuenta que después del tópico cuyo título de definición es: Feedback: Los lectores preguntaron…, la descripción de la definición de dicho es tópico es otra lista de definiciones, es decir, existe una lista de definiciones anidada, recuerde que las listas de definiciones también pueden utilizarse para representar dialogos según la especificación del XHTML. Vamos a diferenciar dicha lista de definiciones del resto.
<code>#feedback dl{
background: #ffe;
border: 1px solid #999;
border-top: 0;
margin: 13px 2px 8px 2px;
padding: 0 5px 10px 5px;
color: #000;
}
#feedback dt{
font-size: 0.95em;
color: #fff;
border: 0 none;
background: #c30;
margin: 0 -5px;
padding: 4px 10px;
}
#feedback .nnl, #feedback .ans{
background: #fcfcfc;
margin: 0 5px;
border-right: 1px solid #bbb;
border-left: 1px solid #bbb;
}
#feedback .ans{
color: #333;
border-top: 1px solid #bbb;
padding: 5px 11px 5px 9px;
}
#feedback .nnl{
border-bottom: 1px solid #bbb;
padding: 0 11px 10px 9px;
}
#feedback .to, #feedback .subject, #feedback .date{
font-style: italic;
}</code>
Vea el resultado de aplicar las reglas de estilo a la estructura del documento.
Simplemente es un “juego” con las propiedades: background, border, margin, padding, font-size, color y font-style; las cuales han sido explicadas con anterioridad.
Quizás deba resaltar la propiedad margin utilizada en la regla #feedback dt, la cual tiene valores negativos (-5px) para los márgenes izquierdo y derecho, esto lo hago simplemente con el fin de ocupar todo el espacio de la lista de definición, en la cual se ha definido previamente un relleno (padding) de 5px.
Código
Vamos a mejorar la presentación del código.
<code>code{
font-family: "Courier New", Courier, monospace;
background: #ffe;
font-size: 0.95em;
}
code.block{
overflow: auto;
width: 33em;
display: block;
}
pre{
text-align: center;
background: #ffe;
color: #000;
width: 33em;
border: 1px solid #bbb;
margin: 6px auto;
padding: 0;
overflow: auto;
height: 100%;
}
pre code{
display: block;
text-align: left;
margin: 6px 7px;
background: transparent;
}</code>
Vea el resultado de aplicar las reglas de estilo a la estructura del documento.
En primer lugar, se le asigna una tipografía distinta de la normal, para distinguir el código del resto del flujo, en algunas ocasiones Carlos emplea en línea código extremadamente largo, lo cual causa que el código rompa con el layout, por ello he creado una clase llamada block que convertirá el selector code, el cual es un elemento en línea, en un elemento en bloque. Para el caso de los bloques de código, estos se han centrado, para lograr tal efecto he utilizado el mismo método citado en principio para centrar el layout.
Es importante resaltar, que el único concepto aplicado que puede resultarle nuevo es el uso de la propiedad overflow, la cual solamente puede ser aplicada a elementos en bloque, esta propiedad es utilizable cuando el contenido sobresale o desborda de la caja que lo contiene, cuando esto sucede, se proporcionan barras de desplazamiento para visualizar el resto del contenido, evitando así romper el layout.
Enlaces
Es importante resaltar que ciertos navegadores podrían ignorar una o más reglas de pseudo clases en los enlaces, a menos que dichas pseudo clases sean listadas en el orden siguiente: :link, :visited, :hover y :active (LVHA). Según el Sr. Zeldman existe un mnemónico anglosajón que podría ayudarle a recordar dicho orden, dicho mnemónico es LoVe-HA!.
Seguramente ud. se estará preguntando en este instante lo siguiente: ¿qué es un selector de pseudo-clase?, en el mundo de las hojas de estilos en cascada, una clase es aquella que es especificada explicitamente con el atributo class dentro de la estructura del documento XHTML. Una pseudo clase es aquella que depende de la actividad del usuario o del estado que indique el navegador (:hover, :visited).
<code>a:link, a:visited{
font-size: 0.85em;
color: #c30;
background: transparent;
font-weight: bold;
text-decoration: none;
}
a:hover, a:active{
color: #999;
background: transparent;
text-decoration: underline;
}
a[hreflang]:after{
content: " [" attr(hreflang) "]";
}
#footer a:hover {
color: #666;
text-decoration: underline;
}</code>
Vea el resultado de aplicar las reglas de estilo a la estructura del documento.
Posiblemente la regla más complicada de las mostradas anteriormente es a[hreflang]:after, voy a explicar brevemente de que trata todo esto, a[hreflang], simplemente aplicará sobre todos aquellos enlaces que posean el atributo hreflang sin importar el valor que tengan. La propiedad content es utilizada en conjunto con los pseudo elementos :before o :after para generar contenido antes o después del elemento respectivamente, dentro de la propiedad content se utilizan dos cadenas de carácteres, tanto el corchete que abre como el corchete que cierra, dentro de los corchetes se utiliza el valor attr(hreflang), el cual devolverá como una cadena el valor del atributo hreflang ubicado dentro del selector a.
Pie de página
El pie de página normalmente es utilizado para indicar el tipo de copyright del contenido o algún tipo de firma en particular.
Se han realizado unos ajustes al pie de página, estos son los siguientes:
<code>#footer{
background: #fff url(bg-footer.png) repeat-x top left;
color: #333;
border-top: 2px solid #666;
}
#footer p{
margin: 0;
padding: 4px 9px 3px 10px;
}
#footer a{
color: #000;
}</code>
Vea el resultado de aplicar las reglas de estilo a la estructura del documento.
Todas las propiedades utilizadas en estas reglas se han descrito previamente, no considero necesario volver a hacerlo.
Referencias
Galería de Imágenes
En este artículo se describirá un método para implantar una galería de imágenes, esta guía será básica, se describirá la estructura (haciendo uso de XHTML) del documento, adicionalmente nos encargaremos de la presentación de la galería, haciendo uso de hojas de estilos en cascada o CSS. El tema del comportamiento de la galería lo dejaremos a criterio del usuario, ya que existen diversas formas para implantar este sistema, algunas más convenientes que otras.
En primera instancia, vamos a realizar la estructura del documento
<code><body>
<div id="wrapper">
<div id="main">
<p><img src="587x474.gif" alt="Texto Alternativo"
width="587px" height="474px" /></p>
</div>
<div id="thumbs">
<h2 id="muestras" title="Imágenes de Muestra">
<span></span>Imágenes de muestra</h2>
<ul>
<li><a href="#">
<img src="75x75.gif" alt="Texto Alternativo"
width="75px" height="75px" /></a></li>
...
</ul>
</div>
</div>
</body></code>
Vamos a explicar poco a poco la estructura del documento, en primer lugar se ha creado una división, wrapper, se utilizará para envolver todo el contenido, adicionalmente nos permitirá centrar la página (presentación) a través de hojas de estilo en cascada, a continuación se ha anidado otra divisón, la division main, en ésta será donde se expondrá la imagen principal, es decir, aca se expondrá la imagen más reciente o en caso que el usuario seleccione un thumbnail (los cuales se ubican dentro de la división thumbs), se mostrará una imagen con mayores dimensiones en la división main. Como se menciono anteriormente este comportamiento no será descrito, lo dejamos a criterio del usuario.
Cabe resaltar que en la división thumbs, se implementará en la etiqueta h2 un reemplazo de texto por una imagen, he seguido el método Shea Enhancement expuesto por Dave Shea, el cual es explicado al final del artículo Revised Image Replacement, también puede ampliar esta noticia en la excelente recopilación hecha por Kemie Guaida en el artículo Reemplazo de Textos - una comparación, allí podrá evaluar las distintas opciones existentes, sus ventajas y desventajas.
Ahora bien, comencemos con la presentación del documento. En primer lugar, debemos tener claro que los distintos navegadores presentan de manera distinta ciertos márgenes (margin) y rellenos (padding) de manera predeterminada, para evitar complicarnos la vida, es recomendable comenzar nuestra hojas de estilos en cascada anulando dichos márgenes y rellenos para todos los elementos XHTML, de la siguiente manera:
<code>* { margin: 0; padding: 0; }</code>
Con la regla anterior simplemente estamos obligando a todos los elementos tener márgenes y rellenos iguales a 0 (cero). Ahora bien, vamos a crear una regla para el cuerpo del documento (body).
<code>body{
font-size: small;
font-family: Georgia, "Times New Roman", serif;
background: #369 url(bg_bottom.gif) bottom left fixed repeat-x;
}</code>
Brevemente se explicará esta regla, aunque la mayoría de las declaraciones se explican por sí solas, esta regla se aplicará al selector body, dicho selector tendrá un tamaño en la fuente pequeño, la precedencia de las fuentes viene dada de izquierda a derecha, por ejemplo, la fuente de preferencia es Georgia, en caso de fallo, se utilizará la fuente Times New Roman, en caso de fallo, se utilizará la fuente predeteminada de la familia serif. Es importante recalcar que aquellos nombres de fuentes que poseen carácteres de espacio, debemos encerrarlas entre comillas dobles. La última declaración se encarga del fondo, se ha establecido el color de fondo al código hexadecimal #336699 (se ha utilizado una abreviatura que permiten las hojas de estilos en cascada), adicionalmente, se ha colocado una imagen en la parte inferior (bottom) izquierda (left) del cuerpo del documento, dicha imagen se repetirá horizontalmente (repeat-x), el valor fixed simplemente nos permitirá mantener fija la imagen aún cuando se realicen desplazamientos.
A continuación se procederá a centrar el documento, para ello nos referiremos a la divisón cuya id es wrapper, adicionalmente se agregará una declaración al selector body para evitar inconvenientes en la mala interpretación que hace IE.
<code>body{ text-align: center; }
#wrapper{
width: 603px;
margin: 20px auto;
text-align: left;
background: #fff;
border: 1px solid #333;
}</code>
Para no extenderme demasiado (y evitar así que ud. se duerma) en la explicación de esta guía básica, le recomiendo lea el artículo CSS Centering 101 de Dan Cederholm.
El método aplicado anteriormente para centrar el layout entero, también puede aplicarse a otros elementos en bloque. Por ello, vamos a aplicar el mismo método a la imagen principal, la ubicada en la división main, pero debe recordar que una imagen (img) es un elemento en línea, así que vamos a “convertirlo” en un elemento en bloque por medio de CSS.
<code>#main img{
display: block;
margin: 0 auto;
}</code>
Ya para finalizar, vamos a concentrarnos en la lista desordenada de imágenes que se encuentran anidadas en la divisiónthumbs. Sabemos que los elementos que se presentan en las listas son elementos en bloque, si queremos presentar uno al lado del otro debemos en primera instancia convertirlos en elementos en línea (esto lo haremos a través de la propiedad display), adicionalmente, debemos eliminar la apariencia de los marcadores de los ítems de la lista, para lograr esto, nos referiremos a la propiedad list-style-type, finalmente, controlaremos los márgenes.
<code>#thumbs li{
list-style-type: none;
display: inline;
margin: 10px -4px 0 8px;
}</code>
Es recomendable que examine el código fuente de la Galería de Imágenes que se ha creado, fijese que se han agregado algunas líneas de codigo CSS, pero la base se ha explicado en esta guía. *[ud.]: usted *[IE]: Internet Explorer
Charlas
Charla: Desarrollo web en Python usando el framework Django
El profesor Jacinto Dávila, en el marco de actividades del Jueves Libre, me ha invitado a dar una charla sobre Desarrollo web en Python usando el framework Django para el día de mañana, 20 30 de noviembre de 2006, el sitio de la charla será en el salón OS-02 del edificio B de la facultad de ingeniería, sector La Hechicera, a partir de las 11:00 a.m.
Básicamente estaré conversando sobre nuevas metodologías de desarrollo Web, el uso de frameworks, ¿en realidad promueven mejores prácticas de desarrollo?, acerca del modelo MVC y el principio DRY (Don’t Repeat Yourself).
A manera de introducción les dejo lo siguiente.
Django es un framework de alto nivel escrito en el lenguaje de programación Python con el objetivo de garantizar desarrollos web rápidos y limpios, con un diseño pragmático.
Un framework orientado al desarrollo Web es un software que facilita la implantación de aquellas tareas tediosas que se encuentran al momento de la construcción de un sitio de contenido dinámico. Se abstraen problemas inherentes al desarrollo Web y se proveen atajos en la programación de tareas comunes.
Con Django, usted construirá sitios web en cuestion de horas, no días; semanas, no años. Cada una de las partes del framework Django ha sido diseñada con el concepto de productividad en mente.
Django sigue la arquitectura MVC (Modelo-Vista-Controlador), en términos simples, es una manera de desarrollo de software en donde el código para definir y acceder a los datos (el modelo) se encuentra separado de la lógica de negocios (el controlador), a su vez está separado de la interfaz de usuario (la vista).
El framework Django ha sido escrito en Python, un lenguaje de programación interpretado de alto nivel que es poderoso, dinámicamente tipado, conciso y expresivo. Para desarrollar un sitio usando Django, debemos escribir código en Python, haciendo uso de las librerías de Django.
Finalmente, Django mantiene de manera estricta a lo largo de su propio código un diseño limpio, y le hace seguir las mejores prácticas cuando se refiere al desarrollo de su aplicación Web.
En resumen, Django facilita el hacer las cosas de manera correcta.
Para finalizar, espero poder hacer una demostración en vivo, ya que el tiempo que dispongo no es mucho.
Charla: Libre como un Mercado Libre
El Consejo de Computación Académica, la Corporación Parque Tecnológico de Mérida y el Centro Nacional de Cálculo Científico de la Universidad de Los Andes, invitan a la charla Libre como un Mercado Libre, cuyo ponente será el Profesor Jacinto Dávila.
El objetivo de la charla básicamente es el siguiente:
En esta presentación, pretendemos argumentar en favor de “libre como en el mercado libre”, una manera quizás desesperada de enfatizar el valor social del nuevo espacio para los negocios que se abre con el Software Libre. El Software Libre no es software gratis. De hecho, quienes desarrollen así pueden seguir cobrando lo que quieran por su trabajo, siempre que no impidan que otros conozcan los códigos fuentes, los usen y los compartan sin restricciones. Lamentablemente, las animosidades, sobretodo las políticas, están nublando toda discusión al respecto y destrozando el mayor logro del software libre: devolver a los tecnólogos a la especie humana.
Información adicional:
- Fecha: Jueves 2 de Marzo.
- Hora: 2:30 pm.
- Lugar: Núcleo La Hechicera, Facultad de Ciencias, Nivel Patio, Salón A9.
- Costo: Entrada Libre.
Algunas referencias que se recomienda leer.
- Petróleo por Software: La energía de los hidrocarburos y la apuesta a futuro con el Software Libre.
- El Copyleft es derechista (también)
Ambos artículos escritos por el profesor Jacinto Dávila.
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
Programando Libre 2005
El Grupo de Usuarios GNU/Linux del Estado Aragua (Venezuela) ha organizado el evento Programando Libre 2005, el cual tiene como objetivo discutir acerca de algunos de los lenguajes de programación más importantes dentro del mundo del Software Libre, tales como:
- Ruby
- PHP
- Perl
- Python
Las ponencias hasta ahora serán las siguientes:
- HTML::Template && Class::DBI (Perl) por Christian Sánchez.
- Descubriendo Ruby on Rails por Francisco Calderon.
- Programación en PHP por Juan Carlos Aleman.
- Por qué y para qué usar Python por Jesús Rivero.
Este evento se realizará el día 10 de Diciembre en la Universidad Bicentenaria del estado Aragua.
Si desean mayor información al respecto pueden visitar la página Velug - Maracay.
Registro de la segunda charla en el canal #ubuntu-es
Ya se encuentra disponible el registro de la segunda charla dada en el canal #ubuntu-es del servidor FreeNode. En esta charla se discutió lo siguiente:
- Ventajas y desventajas del uso de
aptitudefrente aaptysynaptic. - Resumen de comandos en
aptitude,apt,dpkg. - ¿Qué es un repositorio?.
- Agregando nuevos repositorios.
- Proyecto Ubuntu Backports.
- Editando el fichero
/etc/apt/sources.list. - Estructura de los repositorios.
- Ejemplos de uso de
aptitude. - Como actualizar de manera segura su sistema.
- ¿Es importante la firma de paquetes?.
- ¿Como verificamos la autencidad de los paquetes?.
- Como se importa la llave pública desde un servidor GPG.
- Como se exporta la llave pública y se añade a nuestra lista de claves seguras.
- Sesión de preguntas y respuestas.
Puede ver el registro de la charla al seguir el enlace anterior.
En ubuntuchannel.org estamos haciendo todo lo posible por mejorar cada día más, si está interesado en informarse acerca de las siguientes charlas puede ver como siempre nuestra sección de Eventos.
Recientemente nos hemos dedicado a realizar una especie de listado alfabético de
los comandos en GNU/Linux, dicha información se encuentra disponible en la
sección de Comandos, si desea
colaborar, su ayuda es bien recibida, solo recuerde comunicarse previamente
conmigo, para ello puede hacer uso del formulario de
contacto, para ponernos de acuerdo al
respecto. También puede recibir información de manera interactiva acerca del
proyecto en el canal IRC #ubuntu-es del
servidor FreeNode, sino me encuentro conectado (nick
[MilMazz]) en ese instante puede preguntarle al operador del canal (si se
encuentra conectado claro está), P3L|C4N0 con gusto le atenderá.
Charlas en #ubuntu-es
El día de ayer se llevo a cabo la primera de la serie de charlas que se
emitirán por el canal #ubuntu-es del servidor FreeNode, en esta oportunidad
el ponente ha sido zodman, el tema que abordo zodman
fue acerca de Cómo montar un servidor casero haciendo uso de Ubuntu Linux como
plataforma, en el transcurrir de la charla se explico como configurar y
establecer un servidor con los siguientes servicios.
- Apache2
- MySQL
- PHP4
- FTP
- SSH
También se hablo acerca de la configuración de dominios .com, .net y .org sin hacer uso de bind, aplicando dichas configuraciones en el servidor que se está estableciendo.
Si desgraciadamente no pudo estar presente en el evento, no se preocupe, ya he habilitado un registro de la charla. Por motivos de tiempo se decidio dividir la charla en dos partes, si le interesa asistir a la segunda parte de esta charla, esté atentos a los cambios en la sección de Eventos en Ubuntuchannel.org.
django
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
Mejoras en el comportamiento a la hora de eliminar un ForeignKey
Cuando un objeto referenciado por una clave foránea (ForeignKey) es eliminado, Django por omisión emula el comportamiento de la sentencia SQL ON DELETE CASCADE y también se elimina el objeto que contiene el ForeignKey.
A partir de la versión 1.3 de Django el comportamiento descrito en el párrafo anterior puede ser sobreescrito al especificar el argumento on_delete. Por ejemplo, si usted permite que una clave foránea pueda ser nula y usted desea que sea establecida a NULL cuando un objeto referenciado sea eliminado:
user = models.ForeignKey(User, blank=True, null=True, on_delete=models.SET_NULL)Los posibles valores para el argumento on_delete pueden encontrarse en django.db.models:
- CASCADE: Eliminación en cascada, el comportamiento por omisión.
- PROTECT: Prevee la eliminación del objeto referenciado al lanzar una excepción del tipo:
django.db-IntegrityError. - SET_NULL: Establece la clave foránea a
NULL, esto solo es posible si el argumentonullesTrue. - SET_DEFAULT: Establece la clave foránea a su valor por omisión, tenga en cuenta que un valor por omisión debe ser establecido.
- SET(): Establece el valor del
ForeignKeyindicado enSET(), si una función es invocada, el resultado de dicha función será el valor establecido. - DO_NOTHING: No tomar acciones. Si el gestor de base de datos requiere integridad referencial, esto causará una excepción del tipo
IntegrityError.
A continuación un par de ejemplos de esta nueva funcionalidad:
# models.py
from django.db import models
class Author(models.Model):
nickname = models.CharField(max_length=32)
def __unicode__(self):
return self.nickname
class Post(models.Model):
author = models.ForeignKey(Author, blank=True, null=True, on_delete=models.SET_NULL)
title = models.CharField(max_length=128)
def __unicode__(self):
return self.titleNuestra sesión interactiva con el API sería similar a la siguiente:
$ python manage.py shell
>>> from ondelete.models import Author, Post
>>> Author.objects.all()
[]
# Creamos el autor
>>> author = Author(nickname='milmazz')
# Guardamos el objeto en la base de datos al usar de manera explícita el método save()
>>> author.save()
# Obtenemos el autor en base a su id
>>> Author.objects.get(pk=1)
<Author: milmazz>
# Creamos par de artículos
>>> article1 = Post(author=author, title="Article 1")
>>> article1.save()
>>> article2 = Post(author=author, title="Article 2")
>>> article2.save()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.author))
Article 1 by milmazz
Article 2 by milmazz
# Eliminamos el autor
>>> author.delete()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.author))
Article 1 by None
Article 2 by NoneUn segundo ejemplo, ahora haciendo uso del valor SET() en el argumento on_delete:
# models.py
from django.db import models
from django.contrib.auth.models import User
def get_superuser():
return User.objects.get(pk=1)
class Post(models.Model):
user = models.ForeignKey(User, on_delete=models.SET(get_superuser))
title = models.CharField(max_length=128)
def __unicode__(self):
return self.titleNuestra sesión interactiva con el API sería similar a la siguiente:
$ python manage.py shell
>>> from ondelete.models import Post
>>> from django.contrib.auth.models import User
>>> User.objects.all()
[<User: milmazz>]
# Creamos un nuevo usuario
>>> author = User(username='milton')
# Guardamos el objeto en la base de datos,
# de manera explícita al invocar el método save()
>>> author.save()
# Vista de los usuarios registrados en la base de datos
>>> User.objects.all()
[<User: milmazz>, <User: milton>]
# Creamos par de artículos
>>> article1 = Post(user=author, title="Article 1")
>>> article1.save()
>>> article2 = Post(user=author, title="Article 2")
>>> article2.save()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.user))
Article 1 by milton
Article 2 by milton
# Eliminamos el usuario 'milton'
>>> author.delete()
>>> for article in Post.objects.all():
print("%s by %s" % (article.title, article.user))
Article 1 by milmazz
Article 2 by milmazzCharla: Desarrollo web en Python usando el framework Django
El profesor Jacinto Dávila, en el marco de actividades del Jueves Libre, me ha invitado a dar una charla sobre Desarrollo web en Python usando el framework Django para el día de mañana, 20 30 de noviembre de 2006, el sitio de la charla será en el salón OS-02 del edificio B de la facultad de ingeniería, sector La Hechicera, a partir de las 11:00 a.m.
Básicamente estaré conversando sobre nuevas metodologías de desarrollo Web, el uso de frameworks, ¿en realidad promueven mejores prácticas de desarrollo?, acerca del modelo MVC y el principio DRY (Don’t Repeat Yourself).
A manera de introducción les dejo lo siguiente.
Django es un framework de alto nivel escrito en el lenguaje de programación Python con el objetivo de garantizar desarrollos web rápidos y limpios, con un diseño pragmático.
Un framework orientado al desarrollo Web es un software que facilita la implantación de aquellas tareas tediosas que se encuentran al momento de la construcción de un sitio de contenido dinámico. Se abstraen problemas inherentes al desarrollo Web y se proveen atajos en la programación de tareas comunes.
Con Django, usted construirá sitios web en cuestion de horas, no días; semanas, no años. Cada una de las partes del framework Django ha sido diseñada con el concepto de productividad en mente.
Django sigue la arquitectura MVC (Modelo-Vista-Controlador), en términos simples, es una manera de desarrollo de software en donde el código para definir y acceder a los datos (el modelo) se encuentra separado de la lógica de negocios (el controlador), a su vez está separado de la interfaz de usuario (la vista).
El framework Django ha sido escrito en Python, un lenguaje de programación interpretado de alto nivel que es poderoso, dinámicamente tipado, conciso y expresivo. Para desarrollar un sitio usando Django, debemos escribir código en Python, haciendo uso de las librerías de Django.
Finalmente, Django mantiene de manera estricta a lo largo de su propio código un diseño limpio, y le hace seguir las mejores prácticas cuando se refiere al desarrollo de su aplicación Web.
En resumen, Django facilita el hacer las cosas de manera correcta.
Para finalizar, espero poder hacer una demostración en vivo, ya que el tiempo que dispongo no es mucho.
FeedJack: Ya está disponible
Ya había comentado acerca de ésta aplicación en la entrada FeedJack: Un Planet con esteroides, resulta que hace pocos días Gustavo Picón anunció la salida de la versión 0.9.6 bajo licencia BSD. Algunas de las características más resaltantes de esta aplicación son:
- Soporte de virtual hosts: Esto quiere decir que desde la misma instalación y la misma Base de Datos e interfaz de administración, se manejan múltiples planetas. Si hay feeds en común estos se bajan una sola vez para optimizar recursos.
- Temas (Themes): Cada sitio (virtual host) puede tener temas distintos.
- Soporte de folcsonomías (etiquetas o tags): Muy popular en las aplicaciones de la Web 2.0, se ha optimizado el algoritmo.
- Generación de páginas o feeds por folcsonomías: http://www.chichaplanet.org/tag/django/
- Generación de páginas o feeds por miembros: http://www.chichaplanet.org/user/1/
- Generación de páginas o feeds de una categoría en especial de un miembro particular: http://www.chichaplanet.org/user/1/tag/django/
- Generar un feed general: http://www.chichaplanet.org/feed/
- Histórico de entradas: Entre muchas otras cosas. La principal ventaja frente a Planet es el soporte de un histórico de entradas o posts, por el uso de una Base de Datos.
Para conocer los detalles acerca de los requerimientos, el proceso de instalación, configuración y la modificación de los temas lea con detenimiento la entrada Feedjack - A Django+Python Powered Feed Aggregator (Planet).
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
FeedJack: Un Planet con esteroides
FeedJack es una mejora hecha por Gustavo Picon (a.k.a. tabo) del muy conocido Planet, la mejor muestra de la funcionalidad de este software se puede apreciar en el planeta peruano ChichaPlanet.
Gustavo Picon, autor del reemplazo del Planet en Django, afirma que el código fuente todavía no está disponible, pero piensa hacerlo público bajo el esquema de código abierto tan pronto logre depurarlo un poco y redacte cierta documentación, coincido con el autor cuando éste afirma que: si un software no posee documentación, no existe.
FeedJack ofrece algunas características que le dan cierta ventaja sobre el Planet, algunas de ellas son:
- Maneja datos históricos. Por lo tanto, usted puede leer entradas antiguas.
- Realiza un análisis más exhaustivo de las entradas, incluyendo sus categorías.
- Es capaz de generar páginas de acuerdo a las categorías de las entradas.
- Brinda soporte al sistema de folcsonomías (etiquetas), opción muy popular en la Web 2.0.
- Utiliza el lenguaje de plantillas de Django
Mayor información y detalle en la entrada Django powered chicha planet with feedjack, de Gustavo Picon.
Noticias
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Proporcionando medios alternativos a las suscripciones RSS
Según un estudio de Nielsen//NetRatings, quienes se dedican al estudio de mercados y medios en internet, afirma que apenas el 11% de los lectores habituales de blogs, utilizan RSS (acrónimo de Sindicación Realmente Simple, Really Simple Syndication en inglés) para clasificar la lectura de la gran cantidad de blogs disponibles hoy día.
Del mismo estudio se desprende que apenas cerca del 5% de los lectores de blogs utiliza software de escritorio para leer sus suscripciones, mientras que un poco más del 6% utiliza un agregador en línea para ser notificado de los nuevos artículos existentes en los blogs.
A lo descrito previamente, tenemos que agregarle que se estima que el 23% de los lectores entiende lo qué es y para que sirven los RSS, pero en realidad no lo utilizan, mientras que el 66% de las personas en realidad no entienden de que trata la tecnología en discusión o nunca han escuchado de ella.
Ante esta situación, tendremos que buscar alternativas que quizás sean más efectivas que el uso de la sindicación de contenidos vía RSS para mantener informados a nuestros lectores acerca de los nuevos artículos disponibles en nuestras bitácoras.
¿Qué podemos hacer?, solamente tenemos que pensar en ofrecer un mecanismo alternativo, que sirva para que ese 89% pueda suscribirse a los contenidos que ofrecemos. En este artículo discutiremos sobre las suscripciones por correo electrónico.
Algunas ventajas del ofrecer suscripciones por correo son las siguientes:
- El usuario no necesita de una agregador de noticias, ya sea instalable en el escritorio o un servicio en línea. Lo anterior puede ser molesto o complejo para muchos usuarios.
- La mayoría de las personas reconocen lo que es un correo electrónico, incluso, manejan sus cuentas.
- Tanto teléfonos, como PDAs y otros dispositivos que pueden conectarse a la red pueden enviar y recibir correos electrónicos.
- El e-mail se ofrece como un medio alternativo en donde no es posible tener agregadores RSS.
- Puede realizar búsquedas de entradas antiguas, puesto que existen registros en su cuenta, tal cual como hace comúnmente con su correo electrónico.
- Hoy en día no deberiamos preocuparnos en borrar nuestros correos electrónicos, puesto que existen servicios que nos ofrecen gran capacidad de almacenamiento.
- Si el usuario lo desea, ¿por qué no ofrecerle otro medio de suscripción?.
Existen varios servicios que nos facilitan el ofrecer suscripciones a nuestros blogs por medio del correo electrónico. En este artículo discutiremos acerca de FeedBlitz.
FeedBlitz, es un servicio que convierte tus feeds (RSS y ATOM) en un correo electrónico y procederá a enviarlo a todas aquellas personas que se suscriban a este servicio.
Si estás familiarizado con el concepto de newsletter, puedes verlo como tal, pero el contenido de dicho newsletter son las entradas de los blogs a los que estás suscrito.
Algunos puntos que me parecen favorables del servicio es que el proceso de suscripción es muy sencillo, simplemente debe rellenarse un campo en el formulario, esto automáticamente registrará a los usuarios siempre y cuando estos sean nuevos con el servicio, generará una contraseña aleatoria para su cuenta. El usuario deberá simplemente responder al e-mail enviado por FeedBlitz y ¡eso es todo!. Con lo anterior nos aseguramos de obtener una cuenta de correo válida, este modo de verificación es común en muchos servicios que se ofrecen en la red.
Otro punto que me gusta de FeedBlitz es que te envia un solo correo diario, con el contenido actual de los blogs a los que estás suscrito, esto no lo hace por ejemplo RssFwd, el cual te envia un correo por cada nueva entrada existente en los blogs a los cuales estás suscrito, esto puede resultar frustrante (sobretodo en blogs muy activos) para muchos usuarios, me incluyo.
Además, FeedBlitz esta totalmente integrado con FeedBurner, servicio que utilizo para gestionar los RSS de esta bitácora.
Desde FeedBlitz puedes elegir el formato (Texto o HTML) en el que prefieras recibir las notificaciones en tu cuenta de correo electrónico.
¿No le gusto el servicio que ofrece FeedBlitz?, usted en cualquier momento puede dejar de recibir las notificaciones vía correo electrónico, en cada mensaje tiene la información necesaria para darse de baja del servicio.
Programando Libre 2005
El Grupo de Usuarios GNU/Linux del Estado Aragua (Venezuela) ha organizado el evento Programando Libre 2005, el cual tiene como objetivo discutir acerca de algunos de los lenguajes de programación más importantes dentro del mundo del Software Libre, tales como:
- Ruby
- PHP
- Perl
- Python
Las ponencias hasta ahora serán las siguientes:
- HTML::Template && Class::DBI (Perl) por Christian Sánchez.
- Descubriendo Ruby on Rails por Francisco Calderon.
- Programación en PHP por Juan Carlos Aleman.
- Por qué y para qué usar Python por Jesús Rivero.
Este evento se realizará el día 10 de Diciembre en la Universidad Bicentenaria del estado Aragua.
Si desean mayor información al respecto pueden visitar la página Velug - Maracay.
Planeta ubuntu-es
El día de hoy me siento muy contento por poder anunciarles un proyecto en el que me había animado en hacer desde hace ya un tiempo, estuve en conversaciones con varias personas y al darme muestras de apoyo decidí aventurarme.
El proyecto del que les hablo es Planeta ubuntu-es, sitio en el cual se pretende recopilar toda la información aportada por bloggers (personas que mantienen blogs o bitácoras) amigos y colaboradores de la Comunidad de Ubuntu Linux es castellano y que desean de una u otra manera compartir sus experiencias, críticas y temas relacionados con la distribución.
Cualquier blogger que le interese el tema puede contribuir, solamente se requiere cumplir ciertos requerimientos. El primero de ellos es tener cualquiera de las siguientes categorías en su blog.
- ubuntu
- kubuntu
- edubuntu
- xubuntu
Lo anterior se solicita para brindar mayor organización en los archivos de las entradas proporcionadas por los bloggers contribuyentes.
Como segundo requerimiento se tiene, aunque parezca evidente, redactar artículos acerca de Ubuntu Linux, sus derivados o noticias relacionadas. Al cumplir con los requisitos mencionados previamente puede ponerse en contacto con nosotros, puede hacernos llegar sus inquietudes, críticas, comentarios, sugerencias; así como también puede manifestarnos su intención de unirse al proyecto. Una vez que su solicitud haya sido aceptada, sus artículos comenzarán a aparecer en Planeta ubuntu-es.
Planeta ubuntu-es agradece a sus contribuyentes brindándoles promoción, en primer lugar, nuestra página principal mostrará enlaces de todos nuestros colaboradores, a su vez, los comentarios (al igual que los pings) en nuestro sitio han sido desactivados. Por lo tanto, los lectores que deseen discutir acerca de un tema en particular deberán hacerlo en los sitios de origen (sitios de los contribuyentes) de los artículos. De igual manera, todos los títulos de los artículos apuntarán a los sitios de origen. En resúmen, tanto lectores como bloggers se benefician del proyecto.
El proyecto tiene como meta reunir bloggers y lectores que tienen intereses en común, en este caso particular, la distribución ubuntu, sus derivados y noticias relacionadas. Por lo tanto, estaremos contribuyendo de alguna manera a la difusión y aceptación del Software Libre y el Open Source como soluciones reales en nuestros días, de igual manera, se busca la aceptación de Ubuntu como la distribución por excelencia tanto para usuarios no iniciados así como también aquellos usuarios expertos en sistemas GNU/Linux.
Para mayor información del proyecto, puede visitar las secciones:
WordPress
WordPress 2.0.3
Matt Mullenweg anunció hace pocos días la disponibilidad de la versión 2.0.3 para WordPress, la versión más reciente hasta ahora de la serie estable 2.0.
Características en la versión 2.0.3
En esta nueva versión se puede observar.
- Mejoras en cuanto al rendimiento.
- Mejora en el sistema que permite importar entradas o posts desde Movable Type o Typepad.
- Mejora en cuanto al manejo de los enclosures Un enclosure es una manera de adjuntar contenido multimedia a un feed RSS, simplemente asociando la URL del fichero a la entrada particular. Esta característica es de vital importancia para la difusión del podcasting. para podcasts Mayor información acerca del podcasting.
- Corrección de errores de seguridad.
Se corrige el error de seguridad que permitía la inyección de código PHP arbitrario si se encontraba activo el registro libre de usuarios, era necesario desmarcar la casilla de verificación Cualquiera puede registrarse para subsanar el error, dicha casilla puede encontrarla en el área administrativa bajo Opciones -> General.
Si lo desea, puede apreciar la lista completa de las correcciones realizadas para esta versión, algunas de las que llamaron mi atención fueron la #2463 y el #2548, en ambas correcciones se aprecia la optimización en cuanto al rendimiento de WordPress.
Pasos para actualizar desde la versión 2.0.2 a 2.0.3
- Eliminar el contenido de la carpeta /wp-admin.
- En caso de utilizar el directorio /wp-includes/languages, debe respaldarlo. (Opcional).
- Eliminar el contenido de la carpeta /wp-includes.
- Eliminar todos los ficheros del directorio raíz de tu instalación de WordPress, excepto el fichero de configuración, wp-config.php.
- Descargar y descomprimir la nueva versión de WordPress.
- Restaurar las carpetas /wp-admin y /wp-includes. En caso de haber realizado el paso 2, recuerda restaurar también la carpeta /wp-includes/languages.
- Restaurar los ficheros del directorio raíz de tu instalación de WordPress.
- En el paso anterior, no es necesario colocar los ficheros wp-config-sample.php, license.txt, ni el readme.html, bien puedes eliminarlos si gustas.
- Ingresa en el área administrativa, proceda a actualizar la base de datos.
Eso es todo, como siempre, recuerde que es recomendable eliminar los ficheros install.php y upgrade.php, los cuales se encuentran en el directorio /wp-admin
Después de actualizar a la versión 2.0.3
Aún después de actualizar WordPress, existen algunos comportamientos extraños. Cuando usted edita un comentario aparecerá un cuadro de dialogo que le preguntará si está seguro de realizar dicha acción, de igual manera sucede si usted intenta editar un enlace o un usuario, entre otras cosas.
Si usted quiere deshacerse de esos comportamientos extraños, le recomiendo instalar el plugin WordPress 2.0.3 Tuneup, los errores que corrige este plugin hasta su versión 0.3 son: #2760, #2761, #2764, #2776, #2782.
De acuerdo al roadmap de WordPress se espera que la versión 2.0.4 esté lista para el día 30/06/2006.
¡Maldito Spam!, nos invade
Según las estadísticas del plugin Akismet para el día de hoy, solamente 7.961 de 523.708 son comentarios, trackbacks o pingbacks válidos, mientras que el resto es Spam, eso quiere decir que aproximadamente el 1.5% es aceptable, el resto es escoria.
Seguramente alguno de mis 3 lectores en este instante se estará preguntando como funciona Akismet, en la sección de respuestas a preguntas frecuentes podrá resolver esta interrogante.
When a new comment, trackback, or pingback comes to your blog it is submitted to the Akismet web service which runs hundreds of tests on the comment and returns a thumbs up or thumbs down.
No sé que estara sucediendo con dichas pruebas últimamente, puesto que en los comentarios de mi blog han aparecido muchos trackbacks escoria. Ante el abrumador aumento (se puede observar que el aumento es prácticamente exponencial según las estadísticas proporcionadas en sitio oficial de Akismet) del spam, muchos han decidido cerrar sus comentarios, solo basta darse una vuelta por technorati bajo el tag spam y ver las acciones de algunos.
No puedo negar que el funcionamiento de Akismet en general es excelente, de hecho, antes de probar Akismet contaba con 2 ó más alternativas para combatir el spam, después de probarlo, no fue necesario mantener ningún otro plugin, pero creo que bajo esta situación es necesario comenzar a evaluar otras posibilidades que ayuden a Akismet.
Algunas de las cosas que podemos hacer bajo WordPress son las siguientes:
Mejorar nuestras listas de moderación o listas negras
En el área administrativa, bajo Opciones -> Discusión, sección Moderación de comentarios, colocar una lista de palabras claves que aparezcan en estos comentarios escoria. Algunos de ellos no tienen sentido, otros te felicitan por tu trabajo, por ejemplo: Good design, Nice site, todo ese conjunto de palabras clave deben incluirse, si le gusta ser radical incluya dichas palabras clave en la sección Lista negra de comentarios, tenga cuidado si decide elegir esta última opción.
Desactivar los trackbacks
En mi caso, Akismet ha fallado en la detección de trackbacks escoria, por lo tanto, si usted quiere ser realmente radical, puede cerrarlos.
Para desactivar las entradas futuras puede ir a Opciones -> Discusión, y desmarcar la casilla de verificación que dice Permitir notificaciones de enlace desde otros weblogs (pingbacks y trackbacks).
Ahora bien, a pesar de que la oleada de spam está atacando entradas recientes, podemos asegurarnos de cerrar los trackbacks para entradas anteriores ejecutando una sencilla consulta SQL:
UPDATE wp_posts SET ping_status = 'closed';
Moderar comentarios
Puede decidir si todos los comentarios realizados en su bitácora, deberán ser aprobados por el administrador, está acción quizá le evite que se muestren trackbacks escoria en su sitio, pero no le evitará la ardua tarea de eliminarlos uno por uno o masivamente. Si quiere establecer está opción puede hacerlo desde Opciones -> Discusión, en la sección de Para que un comentario aparezca deberá marcar la casilla de verificación Un administrador debe aprobar el comentario (independientemente de los valores de abajo)
Eliminar un rango considerable de comentarios escoria
Esta solución la encontre después de buscar la manera más sencilla de eliminar cientos de mensajes escoria desde una consulta en SQL.
En primer lugar debemos ejecutar la siguiente consulta:
SELECT * FROM wp_comments ORDER BY comment_ID DESC
En ella debemos observar el rango de comentarios recientes y que sean considerados spam. Por ejemplo, supongamos que los comentarios cuyos ID’s están entre los números 2053 y 2062 son considerados spam. Luego de haber anotado el rango de valores, debe proceder como sigue:
UPDATE wp_comments SET comment_approved = 'spam' WHERE comment_ID BETWEEN 2053 AND 2062
Recuerde sustituir apropiadamente los valores correspondientes al inicio y final de los comentarios a ser marcados como spam. Debe recordar también que los comentarios marcados como spam no desaparecerán de su base de datos, por lo tanto, estarán ocupando un espacio que puede llegar a ser considerable, le recomiendo borrarlos posteriormente.
Utilizar plugins compatibles con Akismet
En la sección de respuestas a preguntas frecuentes de Akismet podrán resolver esta interrogante.
We ask that you turn off all other spam plugins as they may reduce the effectiveness of Akismet. Besides, you shouldn’t need them anymore! :) But if you are investigating alternatives, we recommend checking out Bad Behavior and Spam Karma, both which integrate with Akismet nicely.
Ya había probado con anterioridad Bad Behavior, de hecho, lo tuve antes de probar Akismet y funcionaba excelente, ahora, falta probar como se comporta al combinarlo con Spam Karma 2. Las instrucciones de instalación y uso son sencillas.
Referencias:
Actualizando WordPress
Tenía cierto tiempo que no actualizaba la infraestructura que mantiene a MilMazz, el día de hoy he actualizado WordPress a su version 2.0.2, este proceso como siempre es realmente sencillo, no hubo problema alguno.
También he aprovechado la ocasión para actualizar el tema K2, creado por Michael Heilemann y Chris J. Davis, de igual manera, he actualizado la mayoría de los plugins.
Respecto al último punto mencionado en el párrafo anterior, algo extraño sucedió al actualizar el plugin Ultimate Tag Warrior, al revisar su funcionamiento me percaté que al intentar ingresar a una etiqueta particular se generaba un error 404, de inmediato supuse que era la estructura de los enlaces permanentes y las reglas de reescritura, para solucionar el problema simplemente actualice la estructura de enlaces permanentes desde las opciones de la interfaz administrativa de WordPress.
Si nota cualquier error le agradezco me lo haga saber a través de la sección de contacto.
WordPress 2.0
Anoche comencé a realizar algunos cambios a este blog, entre ellos, actualizar la plataforma de publicación que lo gestiona, WordPress. He pasado de la versión 1.5.2 a la 2.0 (nombre clave Duke, en honor al pianista y compositor de Jazz Duke Ellington), estoy muy contento con el cambio puesto que el área administrativa ha sufrido muchos cambios para bien.
Por supuesto, aún faltán muchos detalles por arreglar, en el transcurso de la semana iré traduciendo el tema que posee actualmente la bitácora y algunos plugins que recien comienzo a utilizarlos.
El anuncio de la nueva versión, así como las características que incluye esta nueva versión de WordPress, puede encontrarlas en la entrada WordPress 2, publicada por Matt.
En verdad fué muy fácil la actualización, a mi me tomo solo unos cuantos minutos siguiendo la guía del Codex de WordPress, pero si prefieres una guía en castellano y muy completa te recomiendo leer el artículo Actualización de WordPress de 1.5.x a 2.0.
Plugin generador del protocolo sitemap de Google en WordPress
El protocolo Sitemap de Google es un dialecto de XML para resumir la información relevante acerca de nuestras entradas, este sistema puede resultar una manera muy fácil de mejorar la cobertura de nuestras páginas en el índice de Google, por medio de Sitemaps informaremos cuando se realizan cambios o actualizaciones en nuestros medios. También se permite establecer de manera aproximada el tiempo que tardaremos en realizar cambios en las páginas incluidas.
Si utilizas WordPress, ya está disponible Google Sitemaps Generator, plugin que ofrece ciertas características que hacen de él una buena opción. Algunas de ellas son:
- Fácil de instalar.
- Provee una interfaz de usuario en la cual podrá personalizar ciertos parámetros como prioridades en las entradas, frecuencias de cambios, entre otros.
- Genera un fichero XML estático en el directorio del Blog, tanto la ruta como el nombre del fichero es personalizable.
- Calcula la prioridad de cada entrada, basándose en el número de comentarios (es posible desactivar esta característica).
- El fichero XML es reconstruido automáticamente si cambia, edita, crea, o publica una entrada.
Vía: Blogging Pro.
planet
FeedJack: Ya está disponible
Ya había comentado acerca de ésta aplicación en la entrada FeedJack: Un Planet con esteroides, resulta que hace pocos días Gustavo Picón anunció la salida de la versión 0.9.6 bajo licencia BSD. Algunas de las características más resaltantes de esta aplicación son:
- Soporte de virtual hosts: Esto quiere decir que desde la misma instalación y la misma Base de Datos e interfaz de administración, se manejan múltiples planetas. Si hay feeds en común estos se bajan una sola vez para optimizar recursos.
- Temas (Themes): Cada sitio (virtual host) puede tener temas distintos.
- Soporte de folcsonomías (etiquetas o tags): Muy popular en las aplicaciones de la Web 2.0, se ha optimizado el algoritmo.
- Generación de páginas o feeds por folcsonomías: http://www.chichaplanet.org/tag/django/
- Generación de páginas o feeds por miembros: http://www.chichaplanet.org/user/1/
- Generación de páginas o feeds de una categoría en especial de un miembro particular: http://www.chichaplanet.org/user/1/tag/django/
- Generar un feed general: http://www.chichaplanet.org/feed/
- Histórico de entradas: Entre muchas otras cosas. La principal ventaja frente a Planet es el soporte de un histórico de entradas o posts, por el uso de una Base de Datos.
Para conocer los detalles acerca de los requerimientos, el proceso de instalación, configuración y la modificación de los temas lea con detenimiento la entrada Feedjack - A Django+Python Powered Feed Aggregator (Planet).
Planeta Linux estrena instancia Chilena
Anoche, después de conversar con Damog, se habilitó una nueva instancia en Planeta Linux, en esta ocasión es Chile, la idea la sugirió a través de la lista de correos de Planeta Linux el sr. Flabio Pastén Valenzuela, así que cualquier chileno o chilena que esté interesado en participar en Planeta Linux solo debe escribir a la lista de correos [email protected] la siguiente información.
- Nombre Completo.
- URI del feed.
- Hackergothi, aunque es opcional.
- Instancia en la que deseas aparecer, en este caso, Chile.
Se le recomienda a quienes quieran participar en Planeta Linux leer en primera instancia su serie de respuestas a preguntas frecuentes y los lineamientos.
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
FeedJack: Un Planet con esteroides
FeedJack es una mejora hecha por Gustavo Picon (a.k.a. tabo) del muy conocido Planet, la mejor muestra de la funcionalidad de este software se puede apreciar en el planeta peruano ChichaPlanet.
Gustavo Picon, autor del reemplazo del Planet en Django, afirma que el código fuente todavía no está disponible, pero piensa hacerlo público bajo el esquema de código abierto tan pronto logre depurarlo un poco y redacte cierta documentación, coincido con el autor cuando éste afirma que: si un software no posee documentación, no existe.
FeedJack ofrece algunas características que le dan cierta ventaja sobre el Planet, algunas de ellas son:
- Maneja datos históricos. Por lo tanto, usted puede leer entradas antiguas.
- Realiza un análisis más exhaustivo de las entradas, incluyendo sus categorías.
- Es capaz de generar páginas de acuerdo a las categorías de las entradas.
- Brinda soporte al sistema de folcsonomías (etiquetas), opción muy popular en la Web 2.0.
- Utiliza el lenguaje de plantillas de Django
Mayor información y detalle en la entrada Django powered chicha planet with feedjack, de Gustavo Picon.
Planeta Linux
Hace tiempo que no revisaba algunas de las estadísticas del sitio, me he percatado que han llegado algunos enlaces desde Planeta Linux Venezuela. El principal objetivo de este sitio es:
Planeta Linux es un pequeño proyecto que pretende fomentar la comunicación e intercambio sencillo de información sobre cualquier usuario de GNU/Linux o software libre, en Venezuela. Con esta breve comunicación, podremos conformar una comunidad mucho má sólida, unificada e integral.
Lo anterior también es extensible para aquellas personas mexicanas, puesto que existe un Planeta Linux México.
¿Desea colaborar con el proyecto?
El proceso de registro es muy sencillo, solamente debes enviar un correo a lista de correos [email protected], si desea suscribirse a dicha lista solamente rellene los datos solicitados página de información de la lista de correos de Planeta Linux.
Para su admision usted debe suministrar los siguientes datos:
- Nombre completo
- Lugar de residencia
- URI del feed RSS/Atom
Opcionalmente puede enviar su Hackergotchi, imagen de un escritor que es utilizada como ícono para identificar al autor de un feed dado dentro de un agregador de blogs, ésta no debe exceder un ancho de 95 pixels y un alto de 95 pixels.
Conociendo un poco más acerca del proyecto
Me ha interesado mucho esta iniciativa, así que no dude en ponerme en contacto con David Moreno Garza (a.k.a. damog), él cual me ha contestado muy amablemente. En las siguientes líneas expongo nuestro intercambio de correos electrónicos.
- MilMazz: Hola David, en realidad no tengo el placer de conocerte personalmente, pero he notado recientemente algunos enlaces entrantes desde el Planeta Linux Venezuela, no se quien me dio de alta, se agradece, así que gracias.
- Damog: Hola Milton, no, al parecer no nos conocemos. Yo te di de alta en el rol debido a que José Parrella, a.k.a bureado, me pasó tu nombre y feed.
- MilMazz: El motivo de este mensaje es para pedirte un poco de informacion respecto al proyecto, para publicar un artículo en mi blog y así colaborar con la difusión de esta interesante idea.
- Damog: ¡Muchas gracias! Así es como el proyecto va ganando adeptos y más gente se va uniendo y leyendo el contenido de Planeta Linux.
- MilMazz: Espero no te molesten las siguientes preguntas, tomalo a manera de entrevista :)
- Damog: Desde luego que no, ¡bienvenidas! Antes que cualquier cosa, espero que no te importe que reenvíe este correo a la lista de Planeta Linux.
- MilMazz: ¿Quién o quienes se plantearon en principio la idea de crear Planeta Linux?, ¿quién lo llevaron a cabo?
- Damog: Debido al boom que han tenido los blogs entre usuarios y desarrolladores de software libre en el mundo, se ve la necesidad de crear nuevas herramientas para «monitorear» los contenidos dependiendo de los gustos de cada uno de los usuarios. Wieland Kublun, un mexicano radicado en Guadalajara, en el estado de Jalisco, en el occidente de México, alguna vez me comentó que estaría bien tener una especie de «planeta», como los que se han dado a conocer por proyectos grandes como Planet Debian o Planet GNOME. Creí que la idea era estupenda y empezamos a poner el agregador en marcha y añadiendo a nuestros conocidos al rol.
Otro factor que ha influído mucho en la gran proliferación de Planeta Linux es Jaws. Jaws es un proyecto, iniciado por Jonathan Hernández, radicado en Chihuahua, en el norte de México, de software libre para construir fácilmente un blog. El proyecto Jaws ha avanzado ya muchísimo, pues el software desarollado es altamente útil, funcional y bastante bonito. Por ende, muchos usuarios mexicanos empezaron a montar sus blogs en él y la mancha de usuarios blogueadores mexicanos creció mucho.
- MilMazz: Tengo entendido que el primer planeta de la “serie” fue el Planeta Linux Mexico, ¿desde cuando está en línea?
- Damog: Así es, fue el primero. Ha estado en línea desde octubre de 2004. Antes utilizábamos el dominio planetalinux.com.mx, pero recientemente abrimos el 2006 con el dominio, más genérico y permitible de expansión, planetalinux.org.
- MilMazz: ¿Por qué decidiste incluir a Venezuela como parte del Planeta Linux?, ¿alguna persona te pidio que lo hicieras?
- Damog: No. Personalmente tengo mucha relación con Venezuela, pues mi novia es de allá y tengo bastantes amigos, en el mundillo del software libre, allá. Quise lanzarlo por que empecé a conocer a gente que tenía un blog y llegó a un punto donde consideré pertinente lanzarlo, y donde la gente se interesaría por él. Mucha gente, hasta donde tengo entendido, ni siquiera sabe que está en el planeta. Como tú mismo, a muchas personas se han agregado teniendo conocimientos de ellos por terceras partes. Sin embargo, la forma de ver crecer un proyectito así es precisamente de boca en boca, de blog en blog.
- MilMazz: ¿Tienes pensado en el futuro incluir a mas paises?, si es así, ¿cuáles serían?
- Damog: Sí, la idea también era esa al iniciar con el dominio que usamos actualmente. Al principio creí que lo ideal sería empezar con México y Venezuela por razones ya explicadas, y además con Estados Unidos (sindicando a la gente latina que radica en ese país y que bloguea), usando la dirección us.planetalinux.org. Sin embargo, aún no se ha juntado suficiente gente para llevar a cabo tal subproyecto. En general cualquier país latinoamericano podría entrar mientras se junte suficiente gente y vaya creciendo como han ido creciendo los correspondientes a México y Venezuela. Creo que sería interesante seguirse luego con Brasil, donde hay una enorme actividad de software libre, o incluso en Argentina. Sin embargo, esto depende de la gente: Hace falta todavía escribir mucho contenido, hace falta escribir una especie de FAQ donde se explique qué pueden hacer si alguien quiere iniciar una instancia de Planeta Linux en un país donde no exista, hace falta hacer ese tipo de cosas y generar esos contenidos.
- MilMazz: Estaba por documentarme acerca de los lineamientos, al parecer el enlace de los lineamientos de Planeta Linux está roto por ahora, ¿cuáles serían los lineamientos que debe seguir un miembro del Planeta Linux?
- Damog: Bueno, como te digo, uno más de los contenidos inconclusos. Básicamente, los lineamientos establecerán algunos reglas o consejos, como que deberán hablar de Linux y Software Libre con cierta regularidad en su blog, que su feed debe ser válido, etc. Ese tipo de cosas.
- MilMazz: ¿Quienes pueden participar en el Planeta Linux?
- Damog: Cualquier persona que lleve un blog y toque periódicamente temas sobre Linux o Software Libre.
- MilMazz: ¿Deseas agregar algo más?
- Damog: Pues si alguien se quiere unir, es más que bienvenido. Simplemente escriban a la lista: [email protected] o suscríbanse.
Antes de culminar, quisiera agradecerle públicamente a José Parella por la sugerencia hecha a David Moreno Garza.
trac
Generar reporte en formato CSV de tickets en Trac desde Perl
El día de hoy recibí una llamada telefónica de un compañero de labores en donde me solicitaba con cierta preocupación un “pequeño” reporte del estado de un listado de tickets que recién me había enviado vía correo electrónico puesto que no contaba con conexión a la intranet, al analizar un par de tickets me dije que no iba a ser fácil realizar la consulta desde el asistente que brinda el mismo Trac. Así que inmediatamente puse las manos sobre un pequeño script en Perl que hiciera el trabajo sucio por mí.
Es de hacer notar que total de tickets a revisar era el siguiente:
$ wc -l tickets
126 tickets
Tomando en cuenta el resultado previo, era inaceptable hacer dicha labor de manera manual. Por lo tanto, confirmaba que realizar un script era la vía correcta y a la final iba a ser más divertido.
Tomando en cuenta que el formato de entrada era el siguiente:
#3460
#3493
...
El formato de la salida que esperaba era similar a la siguiente:
3460,"No expira la sesión...",closed,user
Básicamente el formato implica el id, sumario, estado y responsable asociado al ticket.
Net::Trac le ofrece una manera sencilla de interactuar con una instancia remota de Trac, desde el manejo de credenciales, consultas, revisión de tickets, entre otros. A la vez, se hace uso del módulo Class::CSV el cual le ofrece análisis y escritura de documentos en formato CSV.
#!/usr/bin/perl
use warnings;
use strict;
use Net::Trac;
use Class::CSV;
# Estableciendo la conexion a la instancia remota de Trac
my $trac = Net::Trac::Connection->new(
url => 'http://trac.example.com/project',
user => 'user',
password => 'password'
);
# Construccion del objecto CSV y definicion de opciones
my $csv = Class::CSV->new(
fields => [qw/ticket sumario estado responsable/],
line_separator => "\r\n",
csv_xs_options => { binary => 1, } # Manejo de caracteres non-ASCII
);
# Nos aseguramos que el inicio de sesion haya sido exitoso
if ( $trac->ensure_logged_in ) {
my $ticket = Net::Trac::Ticket->new( connection => $trac );
# Consultamos cada uno de los tickets indicados en el fichero de entrada
while ( my $line = <> ) {
chomp($line);
if ( $line =~ m/^#\d+$/ ) {
$line =~ s/^#(\d+)$/$1/;
$ticket->load($line);
$csv->add_line(
{
ticket => $ticket->id,
sumario => $ticket->summary,
estado => $ticket->status,
responsable => $ticket->owner
}
);
}
else {
print "[INFO] La linea no cumple el formato requerido: $line\n";
}
}
$csv->print();
}
else {
print "No se pudieron asegurar las credenciales";
}La manera de ejecutar el script es la siguiente:
$ perl trac_query.pl tickets
En donde trac_query.pl es el nombre del script y tickets es el fichero de
entrada.
Debo aclarar que el script carece de comentarios, mea culpa. Además, el manejo de opciones vía linea de comandos es inexistente, si desea mejorarlo puede hacer uso de Getopt::Long.
Cualquier comentario, sugerencia o corrección es bienvenida.
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234
Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Sistema de manejo y seguimiento de proyectos: Trac
Trac es un sistema multiplataforma desarrollado y mantenido por Edgewall Software, el cual está orientado al seguimiento y manejo de proyectos de desarrollo de software haciendo uso de un enfoque minimalista basado en la Web, su misión es ayudar a los desarrolladores a escribir software de excelente calidad mientras busca no interferir con el proceso y políticas de desarrollo. Incluye un sistema wiki que es adecuado para el manejo de la base de conocimiento del proyecto, fácil integración con sistemas de control de versiones ((Por defecto Trac se integra con subversion)). Además incluye una interfaz para el seguimiento de tareas, mejoras y reporte de errores por medio de un completo y totalmente personalizable sistema de tickets, todo esto con el fin de ofrecer una interfaz integrada y consistente para acceder a toda información referente al proyecto de desarrollo de software. Además, todas estas capacidades son extensibles por medio de plugins o complementos desarrollados específicamente para Trac.
Breve historia de Trac
El origen de Trac no es una idea original, algunos de sus objetivos se basan en los diversos sistemas de manejo y seguimiento de errores que existen en la actualidad, particularmente del sistema CVSTrac y sus autores.
Trac comenzó como la reimplementación del sistema CVSTrac en el lenguaje de programación Python y como ejercicio de entretenimiento, además de utilizar la base de datos embebida SQLite ((Hoy día también se le da soporte a PostgreSQL, mayor detalle en Database Backend)). En un corto lapso de tiempo, el alcance de estos esfuerzos iniciales crecieron en gran medida, se establecieron metas y en el presente Trac presenta un curso de desarrollo propio.
Los desarrolladores de Edgewall Software esperan que Trac sea una plataforma viable para explorar y expandir el cómo y qué puede hacerse con sistemas de manejo de proyectos de desarrollo de software basados en sistemas wiki.
Características de Trac
A continuación se presenta una descripción breve de las distintas características de Trac.
Herramienta de código abierto para el manejo de proyectos
Trac es una herramienta ligera para el manejo de proyectos basada en la Web, desarrollada en el lenguaje de programación Python. Está enfocada en el manejo de proyectos de desarrollo de software, aunque es lo suficientemente flexible para usarla en muchos tipos de proyectos. Al ser una herramienta de código abierto, si Trac no llena completamente sus necesidades, puede aplicar los cambios necesarios usted mismo, escribir complementos o plugins, o contratar a alguien calificado que lo haga por usted.
Sistema de tickets
El sistema de tickets le permite hacer seguimiento del progreso en la resolución de problemas de programación particulares, requerimientos de nuevas características, problemas e ideas, cada una de ellas en su propio ticket, los cuales son enumerados de manera ascendente. Puede resolver o reconciliar aquellos tickets que buscan un mismo objetivo o donde más de una persona reporta el mismo requerimiento. Permite hacer búsquedas o filtrar tickets por severidad, componente del proyecto, versión, responsable de atender el ticket, entre otros.
Para mejorar el seguimiento de los tickets Trac ofrece la posibilidad de activar notificaciones vía correo electrónico, de este modo se mantiene informado a los desarrolladores de los avances en la resolución de las actividades planificadas.
Vista de progreso
Existen varias maneras convenientes de estar al día con los acontecimientos y cambios que ocurren dentro de un proyecto. Puede establecer hitos y ver un mapa del progreso (así como los logros históricos) de manera resumida. Además, puede visualizar desde una interfaz centralizada los cambios ocurridos cronológicamente en el wiki, hitos, tickets y repositorios de código fuente, comenzando con los eventos más recientes, toda esta información es accesible vía Web o de manera alternativa Trac le ofrece la posibilidad de exportar esta información a otros formatos como el RSS, permitiendo que los usuarios puedan observar esos cambios fuera de la interfaz centralizada de Trac, así como la notificación por correo electrónico.
Vista del repositorio en línea
Una de las características de mayor uso en Trac es el navegador o visor del repositorio en línea, se le ofrece una interfaz bastante amigable para el sistema de control de versiones que esté usando ((Por defecto Trac se integra con subversion, la integración con otros sistemas es posible gracias a plugins o complementos.)). Este visualizador en línea le ofrece una manera clara y elegante de observar el código fuente resaltado, así como también la comparación de ficheros, apreciando fácilmente las diferencias entre ellos.
Manejo de usuarios
Trac ofrece un sistema de permisología para controlar cuales usuarios pueden acceder o no a determinadas secciones del sistema de manejo y seguimiento del proyecto, esto se logra a través de la interfaz administrativa. Además, esta interfaz es posible integrarla con la definición de permisos de lectura y escritura de los usuarios en el sistema de control de versiones, de ese modo se logra una administración centralizada de usuarios.
Wiki
El sistema wiki es ideal para mantener la base de conocimientos del proyecto, la cual puede ser usada por los desarrolladores o como medio para ofrecerles recursos a los usuarios. Tal como funcionan otros sistemas wiki, puede permitirse la edición compartida. La sintaxis del sistema wiki es bastante sencilla, si esto no es suficiente, es posible integrar en Trac un editor WYSIWYG (lo que se ve es lo que se obtiene, por sus siglas en inglés) que facilita la edición de los documentos.
Características adicionales
Al ser Trac un sistema modular puede ampliarse su funcionalidad por medio de complementos o plugins, desde sistemas anti-spam hasta diagramas de Gantt o sistemas de seguimiento de tiempo.
(X)HTML
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
Cómo mejorar la presentación de nuestros bloques de código
El día de ayer en la entrada Ctrl + Alt + Supr en
ubuntu el amigo (gracias al
canal ubuntu-es en el servidor Freenode) Red me
preguntaba lo siguiente:
quisiera saber que plugin de WP usas para que salga en un recuadro los comandos de la terminal?
Ahora bien, como en principio la pregunta no tiene que ver con la temática de la entrada, además, mi respuesta puede que sea algo extensa, prefiero responderle a través de esta entrada.
En realidad para la presentación de los bloques de código no hago uso de ningún agregado, solo uso correctamente (sin animos de parecer ostentoso) las etiquetas que nos ofrece el lenguaje de marcado XHTML (lenguaje extensible de marcado de hipertexto), dándole semántica a la estructura de la entrada, la presentación de dicho bloque de código lo realizo a través del uso de CSS (hojas de estilo en cascada).
En primer lugar vamos a ver como debe ser la estructura de los bloques de código.
<code><pre><code>#include <iostream>
int main()
{
std::cout << "Hola Mundo!!!" << std::endl;
return 0;
}
</code></pre></code>
Vea el ejemplo #1.
El bloque de código anterior muestra un programa muy sencillo en C++.
Estructura XHTML
Es hora de definir algunos conceptos muy interesantes.
El elemento <pre>
En primer lugar debemos recordar que el elemento <pre> es un elemento en bloque, los agentes de usuario visuales entenderán que el texto contenido dentro de este elemento vendrá con un formato previo.
Lo anterior implica ciertas ventajas, por ejemplo, pueden dejarse espacios en blanco, los cuales serán interpretados tal cual como se manifiestan de manera explícita. Adicionalmente, se pueden representar fuentes de ancho fijo dentro de estos bloques.
El elemento <code>
El elemento es un elemento en línea, la semántica detrás de este
elemento es indicar segmentos de código.
Mejorando la presentación del bloque de código
Una vez que comprendamos la estructura que deben seguir nuestros bloques de código, debemos hacer uso de las hojas de estilos en cascada para la presentación de dichos bloques. Esto será necesario realizarlo una sola vez.
Mi gusto particular es centrar los bloques de código, esto no tiene porque ser entonces una regla estándar, a continuación describiré como realizar esto vía CSS, solamente debemos seguir las siguientes reglas.
<code>pre{
text-align: center;
width: 30em;
margin: 1em auto;
white-space: pre; /* CSS 2 */
}
pre code{
display: block;
text-align: left;
}</code>
Vea el ejemplo #2.
Al selector pre le he asignado una anchura de 30em, este valor es relativo
a la fuente, pero también podría especificarse en px, es importante resaltar
que haciendo uso de la unidad em se permite generar un bloque líquido.
La declaración que está realizando todo el trabajo de centrar el bloque es
margin: 1em **auto**;, en ella se indica que tanto el margen superior como
inferior sea de 1em, de igual manera se especifica que tanto el margen
izquierdo como el derecho sean auto, por lo tanto, sus valores serán iguales,
esto nos asegura que la caja quede centrada.
Ahora bien, para brindar mayor accesibilidad a nuestro bloque de código, será
necesario hacer uso de la propiedad text-align: center; en el selector pre,
la razón por la cual se usa la declaración anterior es para brindar una buena
presentación en aquellos usuarios de IE5 bajo sistemas Windows. Sin esta regla,
la mayoría de los agentes de usuario visuales podrán mostrar el bloque de
código centrado, pero no aquellos usuarios de IE5/Win.
La declaración white-space: pre; se utiliza para especificar como serán
tratados los espacios en blanco dentro del elemento. Cuando se indica el
valor pre los agentes de usuario visuales impedirán el cierre de las
secuencias de espacios en blanco.
Finalmente, en el selector pre code, debemos reescribir la declaración de
alineación del texto (text-align). En ella estamos alineando el texto de
nuevo a la izquierda, si no lo hacemos, el texto se mostrará centrado debido a
la declaracion de alineación de texto en el selector pre.
El uso de la declaración display: block; modifica la manera en que se muestra
el elemento code, como se mencionó previamente, el elemento code es un
elemento en línea, al hacer uso de esta instrucción, nos permitirá mostrar al
elemento code como un elemento en bloque.
Ahora bien, todavía existe una interrogante que debemos contestar, dicha interrogante es: ¿Qué sucede si el contenido del bloque de código es demasiado extenso horizontalmente?, simplemente el texto se desbordará por encima del bloque, esto es un problema, pero existen dos maneras de solucionarlo.
¿Cómo solucionar un posible desborde del contenido sobre el bloque de código?
La primera solución que podriamos pensar es hacer uso de la declaración
overflow: auto;, la propiedad overflow especifica si el contenido de un
elemento en bloque puede ser recortado o nó cuando éste desborda a dicho
elemento. El valor auto nos permite proporcionar un mecanismo de
desplazamiento en el caso de aquellas cajas que presenten un desborde.
La solución anterior también implica otra inquietud, en este caso particular, la usabilidad, según el gurú de la usabilidad, Jakob Nielsen, los usuarios detestan el tener que hacer uso de las barras de desplazamiento horizontales, el parecer el desplazamiento vertical parece estar bien, puesto que es más común.
Por los motivos descritos en el párrafo anterior, el hacer uso de la barra de desplazamiento horizontal no es la mejor solución. Veamos la solucion definitiva.
La única posibilidad que tenemos para evitar hacer uso de la barra de desplazamiento horizontal es que al ocurrir un desborde, el contenido que desborda pase a la siguiente línea.
Ahora bien, lo que se mostrará a continuación puede resultarle confuso, no se preocupe, trataré de explicarlo, pero recuerde, no soy ningún experto, solo un entusiasta :)
<code>pre{
/* Reglas especificas para algunos navegadores y CSS 3 */
white-space: -moz-pre-wrap; /* Mozilla, soportado desde 1999 */
white-space: -hp-pre-wrap; /* Impresoras HP */
white-space: -o-pre-wrap; /* Opera 7 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: pre-wrap; /* CSS 2.1 */
white-space: pre-line; /* CSS 3 (y 2.1 tambien, actualmente) */
word-wrap: break-word; /* IE 5.5+ */</code>
Vea el archivo maestro.
La versión original del código mostrado previamente pertenece a Ian Hickson quien distribuye su trabajo bajo licencia GPL.
Bajo CSS2, no existe una manera explícita de indicar
que los espacios y nuevas líneas deban preservarse, pero en el caso en el cual
el texto alcance el extremo del bloque que le contiene, se le puede envolver.
Lo más cercano que nos podemos encontrar es white-space: pre, sino no es
posible envolverlo. Antes de que CSS2.1 sea la
recomendación candidata, los agentes de usuario no podrán implementarla, por
eso se han implementado ciertas extensiones propietarias, en el código mostrado
previamente se muestran todas estas posibilidades, los agentes de usuario
tomarán aquellas declaraciones que soporten.
La declaración word-wrap: break-word es una extensión propietaria de IE, la
cual no es parte de ningún estándar.
Para dejar las cosas en claro, pre-wrap actúa como pre pero cubrirá cuando
sea necesario, mientras que pre-line actúa como normal pero preserva nuevas
líneas. Según la opinión de Lim Chee
Aun, la propiedad pre-wrap será
realmente útil en aquellos casos en los cuales deban mostrarse largas líneas de
código que posiblemente desborden en otros elementos o simplemente se muestren
fuera de pantalla.
Ahora bien, ¿qué hay del soporte de los agentes de usuario visuales?, bien, la
mayoría de los navegadores modernos soportan correctamente la propiedad pre,
normal y nowrap. Firefox soporta la propiedad -moz-pre-wrap pero no
soporta pre-wrap y pre-line todavía. Opera 8 soporta pre-wrap incluyendo
sus extensiones previas, -pre-wrap y -o-pre-wrap, pero no pre-line.
Referencias:
Rediseñando NNL Newsletter I
Hace ya bastante tiempo que llevo siguiendo esta interesante lista de correo, orientada sobretodo al mundo IT, tambien se publican noticias relacionadas al mundo GNU/Linux, lo cual capto mi atencion de inmediato.
Pero este articulo no tratara sobre el excelente contenido que presenta regularmente Carlos Tori (el hombre detras de NNL Newsletter), este articulo tratara mas bien una propuesta de rediseño en los boletines que se presentan.
El rediseño que le plantee a Carlos Tori captó su atencion, aun no se ha implantado en el sitio oficial debido a mi “retraso” (algo en lo que mis estudios en la Universidad ha tenido mucho que ver) en la depuracion de los actuales 25 boletines, queda aun mucho trabajo por hacer, solo quiero mostrarle una anticipacion a mis dos fieles lectores. Espero les guste.
Comenzamos
Si observamos los boletines que presenta NNL Newsletter podemos darnos cuenta que aun mantienen el formato usual de mensajes de correo electronico, todo esto a pesar del avance que ha presentado la lista, ahora se puede catalogar como un sitio web en donde se podra leer noticias interesantes, dichas noticias aparecen cada cierto tiempo, agrupadas en un mismo documento, al final de cada documento se anexa el soporte que le ha brindado Carlos Tori a sus fervientes lectores.
Desde mi perspectiva debe darse un “lavado de cara” al Newsletter. Comencemos por la semántica de los documentos. Tomare como muestra el NNL Newsletter » 1.
Eliminando lo innecesario
En primer lugar elimine los estilos incrustados en el mismo documento, la ventaja que nos otorga el uso de hojas de estilos en cascada o CSS es separar la estructura que describe el contenido del documento de su presentacion. Por lo cual, controlaremos la presentacion de los 25 boletines (y posteriores) a través de un solo documento CSS. A continuacion se muestra el bloque eliminado:
<code><style type="text/css">
<!--
.style1 {
font-family: "Courier New", Courier, mono;
font-size: 12px;
}
.style2 {color: #000000}
.style11 {font-size: 1px}
.style12 {color: #FFFFFF}
-->
</style></code>
Posteriormente procedi a eliminar el uso excesivo de las etiquetas <br>, de igual manera se eliminaron el uso de las clases: style1, style2, style11 y style12. Esto es realmente sencillo hacerlo, simplemente buscamos en nuestro editor favorito (en mi caso: Bluefish) la opcion de Reemplazo (Edicion -> Reemplazar), introducimos los parametros de busqueda y reemplazo y el editor hara el trabajo por nosotros.
Siguiendo con el proceso de eliminacion nos encontramos con el logo de NNL Newsletter, el cual tiene ciertos inconvenientes:
<code><p><img src="../logo.png" width="134" height="130"></p></code>
El primer inconveniente es el semantico, en realidad un Agente de Usuario no sabra definir la importancia de esta parte del codigo, simplemente lo tratara como un parrafo mas, adicionalmente, se comete el error de emplear una imagen que el Agente de Usuario (P.ej. Un buscador) no sabria interpretar, ya que no se presenta siquiera un texto alternativo, el uso del atributo alt en las imagenes es vital. Ahora bien, lo que en realidad le daria la importancia que se merece esta parte del codigo seria usar un encabezado que le corresponda.
<code><h1><span></span>NNL Newsletter</h1></code>
¡Ahora si!, hemos conseguido darle un alto nivel de importancia al nombre del newsletter, ahora bien, muchos se preguntaran, ¿Por que de manera tan drastica ha eliminado la imagen?, ¿Acaso para lograr documentos realmente semanticos debemos deshacernos de las imagenes?, desde mi perspectiva el uso de imagenes con fines superfluos o unicamente con fines presentacionales deben dejarse del lado de las hojas de estilo en cascada, simplemente se hara (posteriormente) un reemplazo del encabezado por la imagen via CSS (por eso de la etiqueta span vacia en el encabezado h1), este reemplazo via CSS no disminuira el valor semantico de nuestro documento.
Haciendo algunos cambios necesarios
Carlos Tori, mantiene un formato en su newsletter, normalmente, da una breve introduccion, posteriormente presenta una lista ordenada de los topicos a los cuales hara mencion en el boletin. Seguidamente procede a desglosar cada uno de esos topicos, entre otras cosas. Podemos cambiar ciertas cosas en el boletin.
Primero, la lista ordenada que presenta el newsletter comunmente, la unica salvedad son los diferentes topicos a los cuales puede hacer mencion.
<code><p>1- Nota: CGI inseguro<br>
2- Pequeños grandes consejos al admin: .bash_history<br>
3- Mini análisis de xploits privados: RPC Sunos - 0day -<br>
4- Feedback: Los lectores preguntaron...<br>
5- N de la R. ( Notas de la redacción. ) / Next</p></code>
De manera visual puede que parezca una lista, pero debemos darle a las cosas el significado que tienen en realidad, es decir, le agregaremos un valor semantico, de esta manera sera comprensible para cualquier Agente de Usuario la estructura del contenido mostrado.
<code><ol>
<li><a href="#nnl_1_1" title="Vea el
tópico">CGI inseguro</a></li>
<li><a href="#nnl_1_2" title="Vea el
tópico">Pequeños grandes consejos al admin:
.bash_history</a></li>
<li><a href="#nnl_1_3" title="Vea el
tópico">Mini análisis de xploits privados:
RPC Sunos -0day-</a></li>
<li><a href="#nnl_1_4" title="Vea el
tópico">Feedback: Los lectores preguntaron...</a></li>
<li><a href="#nnl_1_5" title="Vea el
tópico"><abbr title="Notas de la Redacción"
xml:lang="es">N de la R.</abbr> (Notas
de la Redacción) / Next</a></li>
</ol></code>
En la lista ordenada mostrada arriba debemos hacer notar el uso de las entidades de caracteres. Adicionalmente hemos mejorado la semantica de la abreviacion que hace el autor acerca de las Notas de la Redaccion. Por ultimo, pero no menos importante, es el uso de vinculos que llevan como valor (precediendole el caracter almohadilla ‘#’) en el atributo href el valor de los atributos id de otros elementos, esto beneficiara a aquel lector que desea dedicarse a una parte especifica del newsletter, no debera desplazarse por todo el documento, solo debera dar click en el enlace y este le llevara a la parte requerida, es un gran beneficio para el lector, ya que en algunas ocasiones el newsletter presenta un contenido realmente extenso.
En este punto eliminaremos ciertos separadores que son utilizados para seccionar los topicos y le daremos el significado correcto a los titulos de cada topico. Debemos considerar que es una lista de puntos a los cuales se le da una definicion, por lo cual, me parece bastante adecuado utilizar una lista de definiciones en este caso.
Version de Carlos Tori.
<code><p>***************************************************
((2)) Pequeños grandes consejos al admin: ".bash_history"</p>
<p>Amigo administrador: Sabias que una forma rápida de
conseguir privilegios de root es leyendo los .bash_history
de los usuarios de tu server ? Sí, en efecto es asi.
Muchos admins y users pastean sus dificilisimos passwords
durante algún lapsus mental tipo "su ##@|2ks89u" o
"su root##@|2ks89u" o bien pastean el pass "##@|2ks89u" y
dan enter... y lo dejan allí, a la espera de que alguien
lo lea. Controlen a los usuarios que disponen de dicho
pass, y mas aún sus ".bash_history". Amén.</p></code>
Ahora, presentamos una mejora de la version anterior:
<code><dl>
...
<dt id="nnl_1_2">Pequeños
grandes consejos al admin: <code>.bash_history</code></dt>
<dd><p>Amigo administrador: ¿Sabías
que una forma rápida de
conseguir privilegios de <code>root</code> es leyendo los <code>.bash_history</code>
de los usuarios de tu server? Sí, en efecto es asi.</p>
<p>Muchos admins y users pastean sus dificilisimos passwords
durante algún lapsus mental tipo
<code>su ##@|2ks89u</code> o
<code>su root##@|2ks89u</code> o bien pastean el pass <code>##@|2ks89u</code> y
dan enter... y lo dejan allí, a la espera de que alguien
lo lea. Controlen a los usuarios que disponen de dicho
pass, y mas aún sus <code>.bash_history</code>. Amén.</p></dd>
...
</dl></code>
En principio, a cada elemento dt le colocamos el atributo id, con el fin de poder enlazar a dicho elemento desde otra ubicacion, en nuestro caso, lo hacemos desde la lista ordenada presentada mas arriba, esto facilitara el desplazamiento por el documento, sobretodo si un lector desea dedicarse en especial a este topico.
Segun la especificacion, las listas de definiciones consisten en dos partes, la primera de ellas sera el termino a definir, la segunda parte es la definicion en si. El termino a definir (dado por dt) puede contener elementos en linea, mas no en elementos en bloque. En cambio, la definicion del termino contiene elementos en bloque.
<code><p>***************************************************</p>
<p>((4)) Feedback: Los lectores preguntaron...
---------------------------------------------------
From: MP emonicap@*
To: [email protected]
Subject: Consulta disquetera
Gracias por permitir consultas :)
Saben si hay alguna manera por software de inhabilitar
la escritura en la disquetera?
Desde ya gracias
Mónica</p>
<p>R: Hablando de una simple plataforma Windows como opciones
tenes varias... o bien podes deshabilitarla desde
propiedades en "MI PC", sino hablando en un plano command-
line tenes Floplock.exe ( Lock Floppy Disk Drives )
disponible en el resource kit de NT o por ultimo
> http://www.protect-me.com/dl/ - software -</p></code>
Haremos algunos cambios en la estructura anterior…
<code><dl>
...
<dt id="nnl_1_4">Feedback: Los lectores preguntaron...</dt>
<dd id="feedback">
<dl>
<dt class="ask">From: MP emonicap@*</dt>
<dd class="message">
<p class="to"><strong>To:</strong> [email protected]</p>
<p class="subject"><strong>Subject:</strong> Consulta disquetera</p>
<p>Gracias por permitir consultas :)</p>
<p>¿Saben si hay alguna manera por software de inhabilitar
la escritura en la disquetera?</p>
<p>Desde ya gracias,
Monica</p>
</dd>
<dt class="ans"><strong>From:</strong> [email protected]</dt>
<dd class="nnl">
<p><strong><abbr title="Respuesta"
xml:lang="es">R:></abbr></strong>
Hablando de una simple plataforma Windows como opciones tenes varias...
o bien podes deshabilitarla desde propiedades en "MI PC",
sino hablando en un plano command-line tenes Floplock.exe
(<span xml:lang="en">Lock Floppy Disk Drives</span>)
disponible en el resource kit de NT o por último
<a href="http://www.protect-me.com/dl/"
hreflang="en">http://www.protect-me.com/dl/</a>
-software-</p>
</dd>
</dl>
...
<dl>
<dt class="ask">...</dt>
<dd class="message">...</dd>
<dt class="ans">...</dt>
<dd class="nnl">...</dd>
</dl>
...
</dd>
...
</dl></code>
Ahora realmente ud. pensara que yo estoy muy loco, ¿Como se le ocurre hacer una anidamiento de listas de definiciones?. En defensa propia y evitar que me “encasillen”, me remito a la especificacion.
Otra aplicación de DL es, por ejemplo, dar formato a un diálogo, de modo que cada DT identifica al hablante, y cada DD contiene sus palabras.
El elemento dd id="feedback" va a contener todas las preguntas/respuestas hechas/dadas a/por Carlos Tori por/a sus fieles lectores, esa seria la descripcion del termino: Feedback: Los lectores preguntaron…. Ahora bien, dentro del elemento dd id="feedback" nos encontraremos con varias listas de definiciones, la cuales mostraran los distintos “dialogos” que mantiene Carlos Tori con sus lectores. Se han marcado debidamente los distintos elementos.
dt class=”ask”
Identificamos al lector, en nuestro caso indicamos sus direcciones de correo electronico.
dd class=”message”
Indicamos el mensaje del lector, adicionalmente se coloca el **Asunto** y a quien va dirijido el mensaje (aunque sea obvio).
dt class=”ans”
Identifica a Carlos Tori, en nuestro caso indicamos su direccion de correo electronico.
dd class=”nnl”
Indicamos la respuesta dada por Carlos Tori al lector.
Ya para finalizar esta primera entrega, mejoramos el pie de pagina y le agregamos un contenedor a nuestro documento.
Mejora en el pie de pagina:
<code><div id="footer">
<p><em>Carlos Tori</em><br />
<a href="http://www.wedoit.com.ar/">WedoIT</a> - NNL Newsletter<br />
<acronym title="Pretty Good Privacy" xml:lang="en">PGP</acronym> ID 0x7F81D818</p>
<p>Feedback, trabajo, sponsors, notas, contribuciones, dirigirse a:
<a href="mailto:[email protected]">
[email protected]</a>.</p>
</div></code>
Agregamos un contenedor al documento:
<code><body>
<div id="wrapper">
...
</div>
</body></code>
Vea una muestra de los cambios hechos al documento.
En la proxima entrega vendra lo divertido para muchos, mejorar la presentacion del documento a traves de hojas de estilos en cascada o CSS.
Nota:
Este artículo lo publique el día 29 de Marzo de este mismo año en BdW. *[ud.]: usted *[P.ej.]: Por ejemplo
Galería de Imágenes
En este artículo se describirá un método para implantar una galería de imágenes, esta guía será básica, se describirá la estructura (haciendo uso de XHTML) del documento, adicionalmente nos encargaremos de la presentación de la galería, haciendo uso de hojas de estilos en cascada o CSS. El tema del comportamiento de la galería lo dejaremos a criterio del usuario, ya que existen diversas formas para implantar este sistema, algunas más convenientes que otras.
En primera instancia, vamos a realizar la estructura del documento
<code><body>
<div id="wrapper">
<div id="main">
<p><img src="587x474.gif" alt="Texto Alternativo"
width="587px" height="474px" /></p>
</div>
<div id="thumbs">
<h2 id="muestras" title="Imágenes de Muestra">
<span></span>Imágenes de muestra</h2>
<ul>
<li><a href="#">
<img src="75x75.gif" alt="Texto Alternativo"
width="75px" height="75px" /></a></li>
...
</ul>
</div>
</div>
</body></code>
Vamos a explicar poco a poco la estructura del documento, en primer lugar se ha creado una división, wrapper, se utilizará para envolver todo el contenido, adicionalmente nos permitirá centrar la página (presentación) a través de hojas de estilo en cascada, a continuación se ha anidado otra divisón, la division main, en ésta será donde se expondrá la imagen principal, es decir, aca se expondrá la imagen más reciente o en caso que el usuario seleccione un thumbnail (los cuales se ubican dentro de la división thumbs), se mostrará una imagen con mayores dimensiones en la división main. Como se menciono anteriormente este comportamiento no será descrito, lo dejamos a criterio del usuario.
Cabe resaltar que en la división thumbs, se implementará en la etiqueta h2 un reemplazo de texto por una imagen, he seguido el método Shea Enhancement expuesto por Dave Shea, el cual es explicado al final del artículo Revised Image Replacement, también puede ampliar esta noticia en la excelente recopilación hecha por Kemie Guaida en el artículo Reemplazo de Textos - una comparación, allí podrá evaluar las distintas opciones existentes, sus ventajas y desventajas.
Ahora bien, comencemos con la presentación del documento. En primer lugar, debemos tener claro que los distintos navegadores presentan de manera distinta ciertos márgenes (margin) y rellenos (padding) de manera predeterminada, para evitar complicarnos la vida, es recomendable comenzar nuestra hojas de estilos en cascada anulando dichos márgenes y rellenos para todos los elementos XHTML, de la siguiente manera:
<code>* { margin: 0; padding: 0; }</code>
Con la regla anterior simplemente estamos obligando a todos los elementos tener márgenes y rellenos iguales a 0 (cero). Ahora bien, vamos a crear una regla para el cuerpo del documento (body).
<code>body{
font-size: small;
font-family: Georgia, "Times New Roman", serif;
background: #369 url(bg_bottom.gif) bottom left fixed repeat-x;
}</code>
Brevemente se explicará esta regla, aunque la mayoría de las declaraciones se explican por sí solas, esta regla se aplicará al selector body, dicho selector tendrá un tamaño en la fuente pequeño, la precedencia de las fuentes viene dada de izquierda a derecha, por ejemplo, la fuente de preferencia es Georgia, en caso de fallo, se utilizará la fuente Times New Roman, en caso de fallo, se utilizará la fuente predeteminada de la familia serif. Es importante recalcar que aquellos nombres de fuentes que poseen carácteres de espacio, debemos encerrarlas entre comillas dobles. La última declaración se encarga del fondo, se ha establecido el color de fondo al código hexadecimal #336699 (se ha utilizado una abreviatura que permiten las hojas de estilos en cascada), adicionalmente, se ha colocado una imagen en la parte inferior (bottom) izquierda (left) del cuerpo del documento, dicha imagen se repetirá horizontalmente (repeat-x), el valor fixed simplemente nos permitirá mantener fija la imagen aún cuando se realicen desplazamientos.
A continuación se procederá a centrar el documento, para ello nos referiremos a la divisón cuya id es wrapper, adicionalmente se agregará una declaración al selector body para evitar inconvenientes en la mala interpretación que hace IE.
<code>body{ text-align: center; }
#wrapper{
width: 603px;
margin: 20px auto;
text-align: left;
background: #fff;
border: 1px solid #333;
}</code>
Para no extenderme demasiado (y evitar así que ud. se duerma) en la explicación de esta guía básica, le recomiendo lea el artículo CSS Centering 101 de Dan Cederholm.
El método aplicado anteriormente para centrar el layout entero, también puede aplicarse a otros elementos en bloque. Por ello, vamos a aplicar el mismo método a la imagen principal, la ubicada en la división main, pero debe recordar que una imagen (img) es un elemento en línea, así que vamos a “convertirlo” en un elemento en bloque por medio de CSS.
<code>#main img{
display: block;
margin: 0 auto;
}</code>
Ya para finalizar, vamos a concentrarnos en la lista desordenada de imágenes que se encuentran anidadas en la divisiónthumbs. Sabemos que los elementos que se presentan en las listas son elementos en bloque, si queremos presentar uno al lado del otro debemos en primera instancia convertirlos en elementos en línea (esto lo haremos a través de la propiedad display), adicionalmente, debemos eliminar la apariencia de los marcadores de los ítems de la lista, para lograr esto, nos referiremos a la propiedad list-style-type, finalmente, controlaremos los márgenes.
<code>#thumbs li{
list-style-type: none;
display: inline;
margin: 10px -4px 0 8px;
}</code>
Es recomendable que examine el código fuente de la Galería de Imágenes que se ha creado, fijese que se han agregado algunas líneas de codigo CSS, pero la base se ha explicado en esta guía. *[ud.]: usted *[IE]: Internet Explorer
Distribuciones
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
Elive
Elive es un proyecto alojado en debianitas.net, este LiveCD contiene una distribución basada en Debian que trabaja con el ambiente de escritorio enlightenment (tanto la version 16.7 como la 17), contiene todas las librerias EFL, las cuales son requeridas para ejecutar aplicaciones relacionadas a dichas librerias.
Elive incluye una gran parte de los programas relacionados con el proyecto Enlightenment, adicionalmente se incluyen aquellos que son programados usando las EFL (Enlightenment Foundation Libraries), sin dejar de lado una buena selección de las mejores aplicaciones del mundo GNU/Linux.
La versión 0.2 de Elive (la cual aún está en desarrollo) promete la posibilidad de ser instalada en el disco duro, una excelente personalización del ambiente E17, drivers para Nvidia, entre otras nuevas características.
GIMP
GRUB: Mejorando nuestro gestor de arranque
Anteriormente había comentado en la primera entrega del artículo Debian: Bienvenido al Sistema Operativo Universal que por medidas de seguridad establezco las opciones de montaje ro, nodev, nosuid, noexec en la partición /boot, donde se encuentran los ficheros estáticos del gestor de arranque.
El gestor de arranque que manejo es GRUB. Por lo tanto, el motivo de este artículo es explicar como suelo personalizarlo, tanto para dotarle de seguridad como mejorar su presentación.
Seguridad
Lo primero que hago es verificar el dueño y los permisos que posee el fichero /boot/grub/menu.lst, en mi opinión la permisología más abierta y peligrosa sería 644, pero normalmente la establezco en 600, evitando de ese modo que todos los usuarios (excepto el dueño del fichero, que en este caso será root) puedan leer y escribir en dicho fichero. Para lograr esto recurrimos al comando chmod.
# chmod 600 /boot/grub/menu.lst
Si usted al igual que yo mantiene a /boot como una partición de solo lectura, deberá montar de nuevo la partición /boot estableciendo la opción de escritura, para lo cual hacemos:
# mount -o remount,rw /boot
Después de ello si podrá cambiar la permisología del fichero /boot/grub/menu.lst de ser necesario.
El segundo paso es evitar que se modifique de manera interactiva las opciones de inicio del kernel desde el gestor de arranque, para ello estableceremos una contraseña para poder editar dichas opciones, pero primero nos aseguraremos de cifrar esa contraseña con el algoritmo MD5. Por lo tanto, haremos uso de grub-md5-crypt
# grub-md5-crypt
Password:
Retype password:
$1$56z5r1$yMeSchRfnxdS3QDzLpovV1
La última línea es el resultado de aplicarle el algoritmo MD5 a nuestra contraseña, la copiaremos e inmediatamente procedemos a modificar de nuevo el fichero /boot/grub/menu.lst, el cual debería quedar más o menos como se muestra a continuación.
password --md5 $1$56z5r1$yMeSchRfnxdS3QDzLpovV1
title Debian GNU/Linux, kernel 2.6.18-3-686
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro
initrd /initrd.img-2.6.18-3-686
savedefault
title Debian GNU/Linux, kernel 2.6.18-3-686 (single-user mode)
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro single
initrd /initrd.img-2.6.18-3-686
savedefault
La instrucción password --md5 aplica a nivel global, así que cada vez que desee editar las opciones de inicio del kernel, tendrá que introducir la clave (deberá presionar la tecla p para que la clave le sea solicitada) que le permitirá editar dichas opciones.
Presentación del gestor de arranque
A muchos quizá no les agrade el aspecto inicial que posee el GRUB, una manera de personalizar la presentación de nuestro gestor de arranque puede ser la descrita en la segunda entrega de la entrada Debian: Bienvenido al Sistema Operativo Universal en donde instalaba el paquete grub-splashimages y posteriormente establecía un enlace simbólico, el problema de esto es que estamos limitados a las imágenes que trae solo ese paquete.
A menos que a usted le guste diseñar sus propios fondos, puede usar los siguientes recursos:
Después de escoger la imagen que servirá de fondo para el gestor de arranque, la descargamos y la colocamos dentro del directorio /boot/grub/, una vez allí procedemos a modificar el fichero /boot/grub/menu.lst y colocaremos lo siguiente:
splashimage=(hd0,1)/grub/debian.xpm.gz
En la línea anterior he asumido lo siguiente:
- La imagen que he colocado dentro del directorio
/boot/grub/lleva por nombredebian.xpm.gz -
He ajustado la ubicación de mi partición
/boot, es probable que en su caso sea diferente, para obtener dicha información puede hacerlo al leer la tabla de particiones confdisk -lo haciendo uso del comandomount.$ mount | grep /boot /dev/sda2 on /boot type ext2 (rw,noexec,nosuid,nodev)
fdisk -l | grep ^/dev/sda2
/dev/sda2 1217 1226 80325 83 Linux
Por lo tanto, la ubicación de la partición /boot es en el primer disco duro, en la segunda partición, recordando que la notación en el grub comienza a partir de cero y no a partir de uno, tenemos como resultado hd0,1.
También puede darse el caso que ninguno de los fondos para el gestor de arranque mostrados en los recursos señalados previamente sean de su agrado. En ese caso, puede que le sirva el siguiente video demostrativo sobre como convertir un fondo de escritorio en un Grub Splash Image (2 MB) haciendo uso de The Gimp, espero le sea útil.
Después de personalizar el fichero /boot/grub/menu.lst recuerde ejecutar el comando update-grub como superusuario para actualizar las opciones.
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
Atajos Dinámicos en GIMP
Muchas de las opciones en GIMP no ofrecen una combinación de teclas o atajo (shortcut) que nos permita utilizar dichas opciones de manera rápida. En este artículo plantearemos la creación de atajos dinámicos en GIMP.
En
primer lugar debemos tener abierto GIMP, parece evidente, ¿verdad?, seguidamente
nos vamos al menú de GIMP y seleccionamos Archivos -> Preferencias. Una vez
ubicados en la ventana de Preferencias seleccionamos la opción Interfaz de
la lista de categorías que se nos presenta. Seguidamente seleccionamos la
casilla de verificación que hace referencia a Usar combinaciones de teclas
dinámicas y aceptamos los cambios presionando el botón OK.
Una vez hecho lo anterior vamos a crear un nuevo fichero, no importan sus
medidas, la idea es asignarle un atajo a una opción cualquiera, o aquellas que
usamos comúnmente y que no disponen de una combinación de teclas, en este
artículo tomaré como ejemplo la opción Imagen -> Tamaño del lienzo…, el
atajo combinación de teclas que le asignaré a dicha opcion será Ctrl + F11. Para
lograr lo planteado anteriomente simplemente debe posicionarse con el cursor del
mouse en dicha opción, mientrás se encuentra encima de ella, proceda a
escribir la combinación de teclas que desee.
Universidad
Charla: Desarrollo web en Python usando el framework Django
El profesor Jacinto Dávila, en el marco de actividades del Jueves Libre, me ha invitado a dar una charla sobre Desarrollo web en Python usando el framework Django para el día de mañana, 20 30 de noviembre de 2006, el sitio de la charla será en el salón OS-02 del edificio B de la facultad de ingeniería, sector La Hechicera, a partir de las 11:00 a.m.
Básicamente estaré conversando sobre nuevas metodologías de desarrollo Web, el uso de frameworks, ¿en realidad promueven mejores prácticas de desarrollo?, acerca del modelo MVC y el principio DRY (Don’t Repeat Yourself).
A manera de introducción les dejo lo siguiente.
Django es un framework de alto nivel escrito en el lenguaje de programación Python con el objetivo de garantizar desarrollos web rápidos y limpios, con un diseño pragmático.
Un framework orientado al desarrollo Web es un software que facilita la implantación de aquellas tareas tediosas que se encuentran al momento de la construcción de un sitio de contenido dinámico. Se abstraen problemas inherentes al desarrollo Web y se proveen atajos en la programación de tareas comunes.
Con Django, usted construirá sitios web en cuestion de horas, no días; semanas, no años. Cada una de las partes del framework Django ha sido diseñada con el concepto de productividad en mente.
Django sigue la arquitectura MVC (Modelo-Vista-Controlador), en términos simples, es una manera de desarrollo de software en donde el código para definir y acceder a los datos (el modelo) se encuentra separado de la lógica de negocios (el controlador), a su vez está separado de la interfaz de usuario (la vista).
El framework Django ha sido escrito en Python, un lenguaje de programación interpretado de alto nivel que es poderoso, dinámicamente tipado, conciso y expresivo. Para desarrollar un sitio usando Django, debemos escribir código en Python, haciendo uso de las librerías de Django.
Finalmente, Django mantiene de manera estricta a lo largo de su propio código un diseño limpio, y le hace seguir las mejores prácticas cuando se refiere al desarrollo de su aplicación Web.
En resumen, Django facilita el hacer las cosas de manera correcta.
Para finalizar, espero poder hacer una demostración en vivo, ya que el tiempo que dispongo no es mucho.
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
gUsLA: Grupo de Usuarios de Software Libre de la Universidad de Los Andes
Un grupo de compañeros de estudio y mi persona por fin hemos iniciado una serie de actividades para formar el Grupo de Usuarios de Software Libre de la Universidad de Los Andes.
El día de hoy, hicimos entrega de una carta al Consejo de Escuela de Ingeniería de Sistemas, solicitando un aval académico para lograr llevar a cabo las siguientes actividades:
- Charlas.
- Festivales de instalación.
- Atención al usuario.
- Otras actividades de naturaleza académica.
Esta solicitud la hicimos ya que consideramos necesaria la creación de un Grupo de Usuarios que se encargue de:
- Difundir y promover el Software Libre en la Universidad de los Andes.
- Difundir las bases filosóficas detrás del modelo del Software Libre.
- Demostrar la calidad técnica del Software Libre.
- Demostrar a los usuarios finales cuan fácil es utilizar GNU/Linux.
- Fomentar el intercambio de conocimientos en Talleres, Foros, Charlas y/o encuentros con grupos de usuarios de otras latitudes.
- Adaptación al proceso de cambio fomentado por el ente público (decreto 3390).
En este momento hemos contactado a ciertos profesores que han mostrado interés en la iniciativa, la idea es involucrar a todas aquellas personas relacionadas con la Universidad de Los Andes.
En resumen, el objetivo principal que pretende alcanzar nuestro grupo es: El estudio, desarrollo, promoción, difusión, educación, enseñanza y uso de sistemas operativos GNU/Linux, GNU/Hurd, FreeBSD, y de las herramientas libres que interactúan con estos, tanto en el ámbito nacional como en el internacional. Es importante resaltar en este instante que No se perseguirán fines de lucro, ni tendremos finalidades o actividades políticas, partidistas ni religiosas; seremos un grupo apolítico, abierto, pluralista y con fines académicos.
Personalmente, debo agradecer a José Parrella por haberme facilitado un borrador del documento constitutivo/estatutario del Grupo de Usuarios de Linux de la Universidad Central de Venezuela (UCVLUG), lo hemos utilizado como base para formar el nuestro, aunque será discutido por ahora en una lista privada de estudiantes y profesores que han manifestado interés en participar.
Esperamos con ansiedad la decisión del Consejo de Escuela de Ingeniería de Sistemas.
Decisión del Consejo de Facultad de la Universidad de Los Andes
Según informa la profesora Flor Narciso en un comunicado, el Consejo de Facultad de la Universidad de Los Andes en una sesión ordinaria llevada a cabo el día de ayer, 13 de Junio de 2006, se aprobó la reprogramación del semestre.
Esta noticia toma por sorpresa a muchas personas, me incluyo, imagínense tener que asistir a clases cinco sábados seguidos para lograr culminar las actividades el día 21 de Julio de 2006, por supuesto, debemos agradecerles a todos esos revolucionarios que generaron caos en la ciudad por esta decisión del Consejo de Facultad, en verdad, ¡muchas gracias!.
Los días 17, 24 de Junio y los días 1, 8 y 15 de Julio las clases se dictarán en el mismo horario, correspondiente a los días Lunes, Martes, Miércoles, Jueves y Viernes respectivamente.
La fecha que corresponde a la finalización de las evaluaciones queda para el día 21 de Julio de 2006.
Todas asignaturas con proyectos, en mi caso 4, la entrega de los mismos será realizada el día 4 de Septiembre de 2006.
Las notas definitivas serán dadas a conocer en el intervalo comprendido del 4 al 8 de Septiembre de este mismo año.
Ya para culminar, en definitiva, citando al profesor y amigo Richard Márquez: Se pasaron…
javascript
How to document your Javascript code
Someone that knows something about Java probably knows about JavaDoc. If you know something about Python you probably document your code following the rules defined for Sphinx (Sphinx uses reStructuredText as its markup language). Or in C, you follow the rules defined for Doxygen (Doxygen also supports other programming languages such as Objective-C, Java, C#, PHP, etc.). But, what happens when we are coding in JavaScript? How can we document our source code?
As a developer that interacts with other members of a team, the need to document all your intentions must become a habit. If you follow some basic rules and stick to them you can gain benefits like the automatic generation of documentation in formats like HTML, PDF, and so on.
I must confess that I’m relatively new to JavaScript, but one of the first things that I implement is the source code documentation. I’ve been using JSDoc for documenting all my JavaScript code, it’s easy, and you only need to follow a short set of rules.
/**
* @file Working with Tags
* @author Milton Mazzarri <[email protected]>
* @version 0.1
*/
var Tag = $(function(){
/**
* The Tag definition.
*
* @param {String} id - The ID of the Tag.
* @param {String} description - Concise description of the tag.
* @param {Number} min - Minimum value accepted for trends.
* @param {Number} max - Maximum value accepted for trends.
* @param {Object} plc - The ID of the {@link PLC} object where this tag belongs.
*/
var Tag = function(id, description, min, max, plc) {
id = id;
description = description;
trend_min = min;
trend_max = max;
plc = plc;
};
return {
/**
* Get the current value of the tag.
*
* @see [Example]{@link http://example.com}
* @returns {Number} The current value of the tag.
*/
getValue: function() {
return Math.random;
}
};
}());
In the previous example, I have documented the index of the file, showing the author and version, you can also include other things such as a copyright and license note. I have also documented the class definition including parameters and methods specifying the name, and type with a concise description.
After you process your source code with JSDoc the result looks like the following:
In the previous image you see the documentation in HTML format, also you see a table that displays the parameters with appropriate links to your source code, and finally, JSDoc implements a very nice style to your document.
If you need further details I recommend you check out the JSDoc documentation.
Grunt: The Javascript Task Manager
When you play the Web Developer role, sometimes you may have to endure some repetitive tasks like minification, unit testing, compilation, linting, beautify or unpack Javascript code and so on. To solve this problems, and in the meantime, try to keep your mental health in a good shape, you desperately need to find a way to automate this tasks. Grunt offers you an easy way to accomplish this kind of automation.
The DRY principle
The DRY (Don’t Repeat Yourself) principle it basically consist in the following:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
That said, it’s almost clear that the DRY principle is against the code duplication, something that in the long-term affect the maintenance phase, it doesn’t facilitate the improvement or code refactoring and, in some cases, it can generate some contradictions, among other problems.
jQuery best practices
After some time working with C programming language in a *NIX like operating system, recently I came back again to Web Programming, mostly working with HTML, CSS and JavaScript in the client-side and other technologies in the backend area.
The current project I’ve been working on, heavily relies on jQuery and Highcharts/Highstock libraries, I must confess that at the beginning of the project my skills in the client-side were more than rusted, so, I began reading a lot of articles about new techniques and good practices to catch up very quickly, in the meantime, I start taking some notes about “best practices”1 that promotes a better use of jQuery2
miniblog
Indice alfabético de la línea de comandos en BASH
Arte ASCII en su máxima expresión
Increible los alcances del arte ASCII, para muestra un botón. [Vía].
Cinco razones para NO usar Linux
Traducción hecha por Jaime Iniesta del artículo Five reasons NOT to use Linux publicado originalmente en Linux Watch.
La influencia del software libre
Ricardo Galli hace pública la traducción de un artículo de Lawrence Lessig publicado en Technology Review. Según Ricardo Galli la traducción abarca los tópicos más importantes acerca de la influencia del software libre en el proyecto de cultura libre en Brasil. También se habla entre otras cosas de Software Libre, DRM, Licencias y el modelo de negocio en el sector.
subversion
Subversion: Notificaciones vía correo electrónico
Al darse un proceso de desarrollo colectivo es recomendable mantener una o varias listas de notificación acerca de los cambios hechos (commits) en el repositorio de código fuente. Para este tipo de actividades es muy útil emplear SVN::Notify.
SVN::Notify le ofrece un número considerable de opciones, a continuación resumo algunas de ellas:
- Obtiene información relevante acerca de los cambios ocurridos en el repositorio Subversion.
- Realiza análisis sobre la información recolectada y brinda la posibilidad de reconocer distintos formatos vía filtros (Ej. Textile, Markdown, Trac).
- Puede obtener la salida tanto en texto sin formato como en XHTML.
- Le brinda la posibilidad de construir correos electrónicos en base a la salida obtenida.
- Permite el envío de correo, ya sea por el comando
sendmailo SMTP. - Es posible indicar el método de autenticación ante el servidor SMTP.
Para instalar el SVN::Notify en sistemas Debian o derivados proceda de la siguiente manera:
# aptitude install libsvn-notify-perlUna vez instalado SVN::Notify, es hora de definir su comportamiento. Aunque es posible hacerlo vía comando svnnotify y empotrarlo en un script escrito en Bash he preferido hacerlo en Perl, es más natural y legible hacerlo de este modo.
#!/usr/bin/perl -w
use strict;
use SVN::Notify;
my $path = $ARGV[0];
my $rev = $ARGV[1];
my %params = (
repos_path => $path,
revision => $rev,
handler => 'HTML::ColorDiff',
trac_url => 'http://trac.example.com/project',
filters => ['Trac'],
with_diff => 1,
diff_switches => '--no-diff-added --no-diff-deleted',
subject_cx => 1,
strip_cx_regex => [ '^trunk/', '^branches/', '^tags/' ],
footer => 'Administrado por: BOFH ',
max_sub_length => 72,
max_diff_length => 1024,
from => '[email protected]',
subject_prefix => '[project]',
smtp => 'smtp.example.com',
smtp_user => 'example',
smtp_pass => 'example',
);
my $developers = '[email protected]';
my $admins = '[email protected]';
$params{to_regex_map} = {
$developers => '^trunk|^branches',
$admins => '^tags|^trunk'
};
my $notifier = SVN::Notify->new(%params);
$notifier->prepare;
$notifier->execute;Si seguimos con el ejemplo indicado en el artículo anterior, Instalación básica de Trac y Subversion, este hook lo vamos a colocar en /srv/svn/project/hooks/post-commit, dicho fichero deberá tener permisos de ejecución para el Servidor Web Apache.
Con este sencillo script en Perl se ha logrado lo siguiente:
- La salida se generará en XHTML.
- Las diferencias de código serán resaltadas o coloreadas, esto es posible por el handler
SVN::Notify::ColorDiff - El sistema de notificación está integrado a la sintaxis de enlaces de Trac. Por lo tanto, los commits que posean este tipo de enlaces serán interpretados correctamente. Ej.
#123 changeset:234 r234
Aunque el código es sucinto y claro, trataré de resumir cada uno de los parámetros utilizados.
-
repos_path: Define la ruta al repositorio Subversion, la cual es obtenida a partir del primer argumento que pasa Subversion al ejecutar el hookpost-commit. -
revision: El número de la revisión del commit actual. El número de la revisión se obtiene a partir del segundo argumento que pasa Subversion al ejecutar el hookpost-commit -
handler: Especifica una subclase deSVN::Notifyque será utilizada para el manejo de las notificaciones. En el ejemplo se hace uso deHTML::ColorDiff, el cual permite colorear o resaltar la sintaxis del comandosvnlook diff -
trac_url: Este parámetro será usado para generar enlaces al Trac para los números de revisiones y similares en el mensaje de notificación. -
filters: Especifica la carga de más módulos que terminan de difinir la salida de la notificación. En el ejemplo, se hace uso del filtroTrac, filtro que convierte el log del commit que cumple con el formato de Trac a HTML. -
with_diff: Valor lógico que especifica si será o no incluida la salida del comandosvnlook diffen la notificación vía correo electrónico. -
diff_switches: Permite el pase de opciones al comandosvnlook diff, en particular recomiendo utilizar--no-diff-deletedy--no-diff-addedpara evitar ver las diferencias para los archivos borrados y añadidos respectivamente. -
subject_cx: Valor lógico que indica si incluir o nó el contexto del commit en la línea de asunto del correo electrónico de notificación. -
strip_cx_regex: Acá se indican las expresiones regulares que serán utilizadas para eliminar información del contexto de la línea de asunto del correo electrónico de notificación. -
footer: Agrega la cadena definida al final del cuerpo del correo electrónico de notificación -
max_sub_length: Indica la longitud máxima de la línea de asunto del correo electrónico de notificación. -
max_diff_length: Máxima longitud deldiff(esté adjunto o en el cuerpo de la notificación). -
from: Define la dirección de correo que será usada en la líneaFrom. Si no se especifica será utilizado el nombre de usuario definido en el commit, esta información se obtiene vía el comandosvnlook. -
subject_prefix: Define una cadena de texto que será el prefijo de la línea correspondiente al asunto del correo electrónico de notificación. -
smtp: Indica la dirección para el servidor SMTP que el cual se enviarán las notificaciones de correo electrónico. Si no se utiliza este parámetro,SVN::Notifyutilizará el comandosendmailpara el envío del mensaje. -
smtp_user: El nombre de usuario para la autenticación SMTP. -
smtp_pass: Contraseña para la autenticación SMTP -
to_regex_map: Este parámetro contiene un hash que mantiene referencias de direcciones de correo electrónico contra expresiones regulares. La idea es enviar las notificaciones si y solo si el nombre de uno o más directorios son afectados por un commit y dicha ruta coincide con las expresiones regulares definidas. Este parámetro resulta muy útil en proyectos de desarrollo de software grandes y donde es posible disponer de varias listas de correo para informar a los desarrolladores interesados en secciones específicas. Para mayor detalle de las opciones mencionadas previamente veaSVN::Notify, acá también encontrará más opciones de configuración.
Observación
Hasta ahora he encontrado que el coloreado o resaltado de la sintaxis no funciona en algunos sistemas Webmail, como por ejemplo Gmail, SquirrelMail. Sin embargo, en otros sistemas Webmail como RoundCube si funciona. Este comportamiento se presenta porque en sistemas como Gmail las hojas de estilos en cascada (CSS) internas no son aplicadas en la interfaz. Es por ello que en estos casos es necesario recurrir a la definición de estilos en línea.
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Consideraciones para el envío de cambios en Subversion
Hoy día pareciese que los sistemas de control de versiones centralizados están pasando de moda ante la aparición de sistemas de control de versiones descentralizados poderosos como Git, del cual espero poder escribir en próximos artículos. Sin embargo, puede que la adopción de estos sistemas descentralizados tarden en controlar el mundo de los SCM, al menos por ahora las métricas de ohloh.net indican que Subversion sigue siendo bastante empleado, mayor detalle en el artículo Subversion - As Strong As Ever.
En este artículo se expondrán algunas políticas que suelen definirse para la sana convivencia entre colaboradores de un proyecto de desarrollo de software, estas reglas no solo aplican a Subversion en particular, son de uso común en otros sistemas de control de versiones centralizados.
Analice bien los cambios hechos antes de enviarlos
Cualquier cambio en la línea base de su proyecto puede traer consecuencias, tome en cuenta que los demás desarrolladores obtendrán sus cambios una vez que estén en el repositorio centralizado. Si usted no se preocupó por validar que todo funcionara correctamente antes de enviar sus cambios, es probable que algún compañero le recrimine por su irresponsabilidad, esto afecta de cierta forma el anillo de confianza entre los colaboradores del proyecto.
Nunca envíe cambios que hagan fallar la construcción del proyecto
Siempre verifique que su proyecto compile, si el proyecto presenta errores debido a los cambios hechos por usted atiendalos inmediatamente, evite los errores de sintaxis, tenga siempre presente respetar las políticas de estilo de código definidas para su proyecto.
Si ha ingresado nuevos ficheros o directorios al proyecto recuerde ejecutar el comando svn add para programar la adición en Subversion, si omite este paso es posible que su copia de trabajo funcione o compile, pero la del resto de sus compañeros no, evite de nuevo ser recriminado por los demás colaboradores del proyecto.
Si su proyecto pretende ser multiplataforma, trate de imaginar las consecuencias de sus cambios bajo otro sistema operativo o arquitectura. Por ejemplo, he visto más de una vez este tipo de error:
path = "dir/subdir/fichero.txt" # Malo
path = os.path.join(os.path.dirname(__file__), 'dir', 'subdir', 'fichero.txt') # CorrectoPruebe los cambios antes de hacer el envío
Antes de realizar un envío al repositorio centralizado actualice su copia de trabajo (svn up), verifique que las pruebas unitarias, regresión de su proyecto arrojan resultados positivos, de igual manera haga pruebas funcionales del sistema.
Al momento de hacer la actualización de su copia de trabajo tome nota de los ficheros editados por los demás colaboradores del proyecto, verifique que no existan conflictos, nuevos ficheros que no haya considerado, entre otros. Una vez que haya solventado la actualización de su copia de trabajo, construya (su proyecto tiene un sistema de autoconstrucción, ¿verdad?) el paquete, inicie su aplicación que contiene los cambios locales y asegúrese que el comportamiento obtenido sea igual al esperado.
Promueva un histórico de cambios descriptivo
El histórico de cambios debe ser comprensible por cualquier colaborador del proyecto solamente con la información suministrada en dicho registro, evite depender de información fuera del contexto del envío de cambios. Se le recomienda colocar toda la información importante que no pueda obtenerse a partir de un svn diff del código fuente.
¿Está corrigiendo un error?
Si usted está reparando un error en la aplicación que se encuentra presente en la rama principal de desarrollo (trunk), considere seriamente portar esa reparación a otras ramas de desarrollo (branches) en el caso que su proyecto posea una versión estable que requiere actualmente de mantenimiento. Trate en lo posible de aprovechar el mismo commit para enviar la corrección de la rama principal de desarrollo (trunk) y las ramas de mantenimiento.
Si el error fue reportado a través del sistema de seguimiento de errores (usted mantiene un sistema de seguimiento de errores, ¿verdad?), agregue en el registro del mensaje de envío el número del ticket, boleto o reporte que usted está atendiendo. Seguidamente proceda a cerrar el ticket o boleto en el sistema de seguimiento de errores.
No agregue ficheros generados por otras herramientas al repositorio
No agregue ficheros innecesarios al repositorio, el origen de estos ficheros suele ser:
- Proceso de autoconstrucción (Ej. distutils, autotools, scons, entre otros).
- Herramientas de verificación de calidad del código (Ej. PyLint, CppLint, entre otros).
- Herramientas para generar documentación (Ej. Doxygen, Sphinx, entre otros).
Estos ficheros generados por otras herramientas no es necesario versionarlos, puede considerarlos cache, este tipo de datos son localmente generados como resultado de operaciones I/O o cálculos, las herramientas deben ser capaces de regenerar o restaurar estos datos a partir del código presente en el repositorio central.
Realice envíos atómicos
Recuerde que SVN le brinda la posibilidad de enviar más de un fichero en un solo commit. Por lo tanto, envíe todos los cambios relacionados en múltiples ficheros, incluso si los cambios se extienden a lo largo de varios directorios en un mismo commit. De esta manera, se logra que SVN se mantenga en un estado compatible antes y después del commit.
Recuerde asegurarse al enviar un cambio al repositorio central reflejar un solo propósito, el cual puede ser la corrección de un error de programación o bug, agregar una nueva funcionalidad al sistema, ajustes de estilo del código o alguna tarea adicional.
Separe los ajustes de formato de código de otros envíos
Ajustar el formato del código, como la sangría, los espacios en blanco, el largo de la línea incrementa considerablemente los resultados del diff, si usted mezcla los cambios asociados al ajuste de formato de código con otros estará dificultando un posterior análisis al realizar un svn diff.
Haga uso intensivo de la herramienta de seguimiento de errores
Trate en lo posible de crear enlaces bidireccionales entre el conjunto de cambios hechos en el repositorio de subversion y la herramienta de seguimientos de errores tanto como sea posible.
- Trate de hacer una referencia al id o número del ticket al cual está dando solución desde su mensaje de registro o log previo a realizar el commit.
- Cuando agregue información o responda a un ticket, ya sea para describir su avance o simplemente para cerrar el ticket, indique el número o números de revisión que atienden o responden a dichos cambios.
Indique en el registro de envío el resultado del merge
Cuando usted está enviando el resultado de un merge, asegúrese de indicar sus acciones en el registro de envío, tanto aquello que fue fusionado como los números de revisiones que fueron tomadas en cuenta. Ejemplo:
Fusión de las revisiones 10:40 de /branches/foo a /trunk.
Tenga claro cuando es oportuno crear una rama
Esto es un tema polémico. Sin embargo, dependiendo del proyecto en el que esté involucrado usted puede definir una estrategia o mezcla de ellas para manejar el desarrollo del proyecto. Generalmente puede encontrar lo siguiente:
Los proyectos que requieren un alto manejo y supervisión recurren a estrategias de siempre crear ramas, acá puede encontrarse que cada colaborador crea o trabaja en una rama privada para cada tarea de codificación. Cuando el trabajo individual ha finalizado, algún responsable, ya sea el fundador del proyecto, un revisor técnico, analiza los cambios hechos por el colaborador y hace la fusión con la línea principal de desarrollo. En estos casos la rama principal de desarrollo suele ser bastante estable. Sin embargo, este modo de trabajo conlleva normalmente a crear mayores conflictos en la etapa de fusión o merge, además, las labores de fusión bajo este esquema son constantemente requeridas.
Existe otro enfoque que permite mantener una línea base de desarrollo estable, el cual consiste en crear ramas de desarrollo solo cuando se ameritan. Sin embargo, esto requiere que los colaboradores tengan mayor dominio del uso de Subversion y una constante comunicación entre ellos. Además de aumentar el número de pruebas antes de cada envío al repositorio centralizado.
Estudie, analice las distintas opciones y defina un método para la creación de ramas en su proyecto. Una vez definido, es sumamente importante que cada colaborador tenga clara esta estrategia de trabajo.
Las estrategias antes mencionadas y otras más pueden verse en detalle en:
Los sistemas de control de versiones no substituyen la comunicación entre los colaboradores
Por último pero no menos importante, los sistemas de control de versiones no substituyen la comunicación entre los desarrolladores o colaboradores del proyecto de software. Cuando usted tenga planes de hacer un cambio que pueda afectar una cantidad de código considerable en su proyecto, establezca un control de cambios, haga un análisis de las posibles consecuencias o impacto de los mismos, difunda esta información a través de una lista de discusión (usted mantiene una lista de discusión para desarrolladores, ¿verdad?) y espere la respuesta, preocupaciones, sugerencias de los demás colaboradores, quizá juntos se encuentre un modo más eficaz de aplicar los cambios.
Referencias:
- Subversion Best Practices (presentación)
- SVN commit basic policy guide
- Subversion Best Practices
- Subversion Best Practices (presentación)
subversion: Recuperar cambios y eliminaciones hechas
Muchos compañeros de trabajo y amigos en general que recién comienzan con el manejo de sistemas de control de versiones centralizados, en particular subversion, regularmente tienen inquietudes en cuanto al proceso de recuperación de cambios una vez que han sido enviados al repositorio, así como también la recuperación de ficheros y directorios que fueron eliminados en el pasado. Trataré de explicar algunos casos en base a ejemplos para que se tenga una idea más clara del problema y su respectiva solución.
En el primero de los casos se tiene recuperar la revisión previa a la actual, suponga que usted mantiene un repositorio de recetas, una de ellas en particular es la ensalada caprese, por error o descuido añadió el ingrediente Mostaza tipo Dijón a la lista, si usted posee siquiera un lazo con italinos sabe que está cometiendo un error que puede devenir en escarnio público, desprecio e insultos.
~/svn/wc/trunk$ svn diff -r 2:3 ${URL}/trunk/caprese
Index: caprese
===================================================================
--- caprese (revision 2)
+++ caprese (revision 3)
@@ -7,3 +7,4 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
+ - Mostaza tipo Dijon
Note que el comando anterior muestra las diferencias entre las revisiones 2 y 3 del repositorio, en el resumen se puede apreciar que en la revisión 3 ocurrió el error. Un modo rápido de recuperarlo es como sigue.
~/svn/wc/trunk$ svn merge -c -3 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
En este caso particular se están aplicando las diferencias entre las revisiones consecutivas a la copia de trabajo. Es hora de verificar que los cambios hechos sean los deseados:
~/svn/wc/trunk$ svn status
M caprese
~/svn/wc/trunk$ svn diff
Index: caprese
===================================================================
--- caprese (revision 3)
+++ caprese (working copy)
@@ -7,4 +7,3 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
- - Mostaza tipo Dijon
Una vez verificado enviamos los cambios hechos al repositorio a través de comando svn commit.
Seguramente usted se estará preguntando ahora que sucede si las revisiones del ficheros no son consecutivas como en el caso mostrado previamente. En este caso es importante hacer notar que la opción -c 3 es equivalente a -r 2:3 al usar el comando svn merge, en nuestro caso particular -c -3 es equivalente a -r 3:2 (a esto se conoce como una fusión reversa), substituyendo la opción -c (o --changes) en el caso previo obtenemos lo siguiente:
~/svn-tests/wc/trunk$ svn merge -r 3:2 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
Referencias: svn help merge, svn help diff, svn help status.
Recuperando ficheros o directorios eliminados
Una manera bastante sencilla de recuperar ficheros o directorios eliminados es haciendo uso de comando svn cp o svn copy, una vez determinada la revisión del fichero o directorio que desea recuperar la tarea es realmente sencilla:
~/svn-tests/wc/trunk$ svn cp ${URL}/trunk/panzanella@6 panzanella
A panzanella
En este caso se ha duplicado la revisión 6 del fichero panzanella en la copia de trabajo local, se ha programado para su adición incluyendo su historial, esto último puede verificarse en detalle al observar el signo ’+’ en la cuarta columna del comando svn status.
~/svn-tests/wc/trunk$ svn status
A + panzanella
Referencias: svn help copy, svn help status.
ula
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
gUsLA: Grupo de Usuarios de Software Libre de la Universidad de Los Andes
Un grupo de compañeros de estudio y mi persona por fin hemos iniciado una serie de actividades para formar el Grupo de Usuarios de Software Libre de la Universidad de Los Andes.
El día de hoy, hicimos entrega de una carta al Consejo de Escuela de Ingeniería de Sistemas, solicitando un aval académico para lograr llevar a cabo las siguientes actividades:
- Charlas.
- Festivales de instalación.
- Atención al usuario.
- Otras actividades de naturaleza académica.
Esta solicitud la hicimos ya que consideramos necesaria la creación de un Grupo de Usuarios que se encargue de:
- Difundir y promover el Software Libre en la Universidad de los Andes.
- Difundir las bases filosóficas detrás del modelo del Software Libre.
- Demostrar la calidad técnica del Software Libre.
- Demostrar a los usuarios finales cuan fácil es utilizar GNU/Linux.
- Fomentar el intercambio de conocimientos en Talleres, Foros, Charlas y/o encuentros con grupos de usuarios de otras latitudes.
- Adaptación al proceso de cambio fomentado por el ente público (decreto 3390).
En este momento hemos contactado a ciertos profesores que han mostrado interés en la iniciativa, la idea es involucrar a todas aquellas personas relacionadas con la Universidad de Los Andes.
En resumen, el objetivo principal que pretende alcanzar nuestro grupo es: El estudio, desarrollo, promoción, difusión, educación, enseñanza y uso de sistemas operativos GNU/Linux, GNU/Hurd, FreeBSD, y de las herramientas libres que interactúan con estos, tanto en el ámbito nacional como en el internacional. Es importante resaltar en este instante que No se perseguirán fines de lucro, ni tendremos finalidades o actividades políticas, partidistas ni religiosas; seremos un grupo apolítico, abierto, pluralista y con fines académicos.
Personalmente, debo agradecer a José Parrella por haberme facilitado un borrador del documento constitutivo/estatutario del Grupo de Usuarios de Linux de la Universidad Central de Venezuela (UCVLUG), lo hemos utilizado como base para formar el nuestro, aunque será discutido por ahora en una lista privada de estudiantes y profesores que han manifestado interés en participar.
Esperamos con ansiedad la decisión del Consejo de Escuela de Ingeniería de Sistemas.
Decisión del Consejo de Facultad de la Universidad de Los Andes
Según informa la profesora Flor Narciso en un comunicado, el Consejo de Facultad de la Universidad de Los Andes en una sesión ordinaria llevada a cabo el día de ayer, 13 de Junio de 2006, se aprobó la reprogramación del semestre.
Esta noticia toma por sorpresa a muchas personas, me incluyo, imagínense tener que asistir a clases cinco sábados seguidos para lograr culminar las actividades el día 21 de Julio de 2006, por supuesto, debemos agradecerles a todos esos revolucionarios que generaron caos en la ciudad por esta decisión del Consejo de Facultad, en verdad, ¡muchas gracias!.
Los días 17, 24 de Junio y los días 1, 8 y 15 de Julio las clases se dictarán en el mismo horario, correspondiente a los días Lunes, Martes, Miércoles, Jueves y Viernes respectivamente.
La fecha que corresponde a la finalización de las evaluaciones queda para el día 21 de Julio de 2006.
Todas asignaturas con proyectos, en mi caso 4, la entrega de los mismos será realizada el día 4 de Septiembre de 2006.
Las notas definitivas serán dadas a conocer en el intervalo comprendido del 4 al 8 de Septiembre de este mismo año.
Ya para culminar, en definitiva, citando al profesor y amigo Richard Márquez: Se pasaron…
XXXII Aniversario EISULA
Según lo manifiesta la profesora Flor Narciso en un comunicado, el día de mañana, 14/06/2006, se celebrará una misa conmemorativa del XXXII Aniversario de la Escuela de Ingeniería de Sistemas a las 9:00 a.m. en la Sala de Reuniones de la Escuela.
Además, en el horario comprendido de 4:00 a 6:00 p.m. se llevará a cabo el seminario titulado Técnicas Emergentes en Automatización Industrial a cargo de los ingenieros Jesús Durán, Lisbeth Pérez y Jorge Vento.
El seminario se realizará en el Auditorio A de la Facultad de Ingeniería de la Universidad de Los Andes.
Están todos cordialmente invitados a participar en estas actividades.
Ingeniería del Software
Sistema de manejo y seguimiento de proyectos: Trac
Trac es un sistema multiplataforma desarrollado y mantenido por Edgewall Software, el cual está orientado al seguimiento y manejo de proyectos de desarrollo de software haciendo uso de un enfoque minimalista basado en la Web, su misión es ayudar a los desarrolladores a escribir software de excelente calidad mientras busca no interferir con el proceso y políticas de desarrollo. Incluye un sistema wiki que es adecuado para el manejo de la base de conocimiento del proyecto, fácil integración con sistemas de control de versiones ((Por defecto Trac se integra con subversion)). Además incluye una interfaz para el seguimiento de tareas, mejoras y reporte de errores por medio de un completo y totalmente personalizable sistema de tickets, todo esto con el fin de ofrecer una interfaz integrada y consistente para acceder a toda información referente al proyecto de desarrollo de software. Además, todas estas capacidades son extensibles por medio de plugins o complementos desarrollados específicamente para Trac.
Breve historia de Trac
El origen de Trac no es una idea original, algunos de sus objetivos se basan en los diversos sistemas de manejo y seguimiento de errores que existen en la actualidad, particularmente del sistema CVSTrac y sus autores.
Trac comenzó como la reimplementación del sistema CVSTrac en el lenguaje de programación Python y como ejercicio de entretenimiento, además de utilizar la base de datos embebida SQLite ((Hoy día también se le da soporte a PostgreSQL, mayor detalle en Database Backend)). En un corto lapso de tiempo, el alcance de estos esfuerzos iniciales crecieron en gran medida, se establecieron metas y en el presente Trac presenta un curso de desarrollo propio.
Los desarrolladores de Edgewall Software esperan que Trac sea una plataforma viable para explorar y expandir el cómo y qué puede hacerse con sistemas de manejo de proyectos de desarrollo de software basados en sistemas wiki.
Características de Trac
A continuación se presenta una descripción breve de las distintas características de Trac.
Herramienta de código abierto para el manejo de proyectos
Trac es una herramienta ligera para el manejo de proyectos basada en la Web, desarrollada en el lenguaje de programación Python. Está enfocada en el manejo de proyectos de desarrollo de software, aunque es lo suficientemente flexible para usarla en muchos tipos de proyectos. Al ser una herramienta de código abierto, si Trac no llena completamente sus necesidades, puede aplicar los cambios necesarios usted mismo, escribir complementos o plugins, o contratar a alguien calificado que lo haga por usted.
Sistema de tickets
El sistema de tickets le permite hacer seguimiento del progreso en la resolución de problemas de programación particulares, requerimientos de nuevas características, problemas e ideas, cada una de ellas en su propio ticket, los cuales son enumerados de manera ascendente. Puede resolver o reconciliar aquellos tickets que buscan un mismo objetivo o donde más de una persona reporta el mismo requerimiento. Permite hacer búsquedas o filtrar tickets por severidad, componente del proyecto, versión, responsable de atender el ticket, entre otros.
Para mejorar el seguimiento de los tickets Trac ofrece la posibilidad de activar notificaciones vía correo electrónico, de este modo se mantiene informado a los desarrolladores de los avances en la resolución de las actividades planificadas.
Vista de progreso
Existen varias maneras convenientes de estar al día con los acontecimientos y cambios que ocurren dentro de un proyecto. Puede establecer hitos y ver un mapa del progreso (así como los logros históricos) de manera resumida. Además, puede visualizar desde una interfaz centralizada los cambios ocurridos cronológicamente en el wiki, hitos, tickets y repositorios de código fuente, comenzando con los eventos más recientes, toda esta información es accesible vía Web o de manera alternativa Trac le ofrece la posibilidad de exportar esta información a otros formatos como el RSS, permitiendo que los usuarios puedan observar esos cambios fuera de la interfaz centralizada de Trac, así como la notificación por correo electrónico.
Vista del repositorio en línea
Una de las características de mayor uso en Trac es el navegador o visor del repositorio en línea, se le ofrece una interfaz bastante amigable para el sistema de control de versiones que esté usando ((Por defecto Trac se integra con subversion, la integración con otros sistemas es posible gracias a plugins o complementos.)). Este visualizador en línea le ofrece una manera clara y elegante de observar el código fuente resaltado, así como también la comparación de ficheros, apreciando fácilmente las diferencias entre ellos.
Manejo de usuarios
Trac ofrece un sistema de permisología para controlar cuales usuarios pueden acceder o no a determinadas secciones del sistema de manejo y seguimiento del proyecto, esto se logra a través de la interfaz administrativa. Además, esta interfaz es posible integrarla con la definición de permisos de lectura y escritura de los usuarios en el sistema de control de versiones, de ese modo se logra una administración centralizada de usuarios.
Wiki
El sistema wiki es ideal para mantener la base de conocimientos del proyecto, la cual puede ser usada por los desarrolladores o como medio para ofrecerles recursos a los usuarios. Tal como funcionan otros sistemas wiki, puede permitirse la edición compartida. La sintaxis del sistema wiki es bastante sencilla, si esto no es suficiente, es posible integrar en Trac un editor WYSIWYG (lo que se ve es lo que se obtiene, por sus siglas en inglés) que facilita la edición de los documentos.
Características adicionales
Al ser Trac un sistema modular puede ampliarse su funcionalidad por medio de complementos o plugins, desde sistemas anti-spam hasta diagramas de Gantt o sistemas de seguimiento de tiempo.
Consideraciones para el envío de cambios en Subversion
Hoy día pareciese que los sistemas de control de versiones centralizados están pasando de moda ante la aparición de sistemas de control de versiones descentralizados poderosos como Git, del cual espero poder escribir en próximos artículos. Sin embargo, puede que la adopción de estos sistemas descentralizados tarden en controlar el mundo de los SCM, al menos por ahora las métricas de ohloh.net indican que Subversion sigue siendo bastante empleado, mayor detalle en el artículo Subversion - As Strong As Ever.
En este artículo se expondrán algunas políticas que suelen definirse para la sana convivencia entre colaboradores de un proyecto de desarrollo de software, estas reglas no solo aplican a Subversion en particular, son de uso común en otros sistemas de control de versiones centralizados.
Analice bien los cambios hechos antes de enviarlos
Cualquier cambio en la línea base de su proyecto puede traer consecuencias, tome en cuenta que los demás desarrolladores obtendrán sus cambios una vez que estén en el repositorio centralizado. Si usted no se preocupó por validar que todo funcionara correctamente antes de enviar sus cambios, es probable que algún compañero le recrimine por su irresponsabilidad, esto afecta de cierta forma el anillo de confianza entre los colaboradores del proyecto.
Nunca envíe cambios que hagan fallar la construcción del proyecto
Siempre verifique que su proyecto compile, si el proyecto presenta errores debido a los cambios hechos por usted atiendalos inmediatamente, evite los errores de sintaxis, tenga siempre presente respetar las políticas de estilo de código definidas para su proyecto.
Si ha ingresado nuevos ficheros o directorios al proyecto recuerde ejecutar el comando svn add para programar la adición en Subversion, si omite este paso es posible que su copia de trabajo funcione o compile, pero la del resto de sus compañeros no, evite de nuevo ser recriminado por los demás colaboradores del proyecto.
Si su proyecto pretende ser multiplataforma, trate de imaginar las consecuencias de sus cambios bajo otro sistema operativo o arquitectura. Por ejemplo, he visto más de una vez este tipo de error:
path = "dir/subdir/fichero.txt" # Malo
path = os.path.join(os.path.dirname(__file__), 'dir', 'subdir', 'fichero.txt') # CorrectoPruebe los cambios antes de hacer el envío
Antes de realizar un envío al repositorio centralizado actualice su copia de trabajo (svn up), verifique que las pruebas unitarias, regresión de su proyecto arrojan resultados positivos, de igual manera haga pruebas funcionales del sistema.
Al momento de hacer la actualización de su copia de trabajo tome nota de los ficheros editados por los demás colaboradores del proyecto, verifique que no existan conflictos, nuevos ficheros que no haya considerado, entre otros. Una vez que haya solventado la actualización de su copia de trabajo, construya (su proyecto tiene un sistema de autoconstrucción, ¿verdad?) el paquete, inicie su aplicación que contiene los cambios locales y asegúrese que el comportamiento obtenido sea igual al esperado.
Promueva un histórico de cambios descriptivo
El histórico de cambios debe ser comprensible por cualquier colaborador del proyecto solamente con la información suministrada en dicho registro, evite depender de información fuera del contexto del envío de cambios. Se le recomienda colocar toda la información importante que no pueda obtenerse a partir de un svn diff del código fuente.
¿Está corrigiendo un error?
Si usted está reparando un error en la aplicación que se encuentra presente en la rama principal de desarrollo (trunk), considere seriamente portar esa reparación a otras ramas de desarrollo (branches) en el caso que su proyecto posea una versión estable que requiere actualmente de mantenimiento. Trate en lo posible de aprovechar el mismo commit para enviar la corrección de la rama principal de desarrollo (trunk) y las ramas de mantenimiento.
Si el error fue reportado a través del sistema de seguimiento de errores (usted mantiene un sistema de seguimiento de errores, ¿verdad?), agregue en el registro del mensaje de envío el número del ticket, boleto o reporte que usted está atendiendo. Seguidamente proceda a cerrar el ticket o boleto en el sistema de seguimiento de errores.
No agregue ficheros generados por otras herramientas al repositorio
No agregue ficheros innecesarios al repositorio, el origen de estos ficheros suele ser:
- Proceso de autoconstrucción (Ej. distutils, autotools, scons, entre otros).
- Herramientas de verificación de calidad del código (Ej. PyLint, CppLint, entre otros).
- Herramientas para generar documentación (Ej. Doxygen, Sphinx, entre otros).
Estos ficheros generados por otras herramientas no es necesario versionarlos, puede considerarlos cache, este tipo de datos son localmente generados como resultado de operaciones I/O o cálculos, las herramientas deben ser capaces de regenerar o restaurar estos datos a partir del código presente en el repositorio central.
Realice envíos atómicos
Recuerde que SVN le brinda la posibilidad de enviar más de un fichero en un solo commit. Por lo tanto, envíe todos los cambios relacionados en múltiples ficheros, incluso si los cambios se extienden a lo largo de varios directorios en un mismo commit. De esta manera, se logra que SVN se mantenga en un estado compatible antes y después del commit.
Recuerde asegurarse al enviar un cambio al repositorio central reflejar un solo propósito, el cual puede ser la corrección de un error de programación o bug, agregar una nueva funcionalidad al sistema, ajustes de estilo del código o alguna tarea adicional.
Separe los ajustes de formato de código de otros envíos
Ajustar el formato del código, como la sangría, los espacios en blanco, el largo de la línea incrementa considerablemente los resultados del diff, si usted mezcla los cambios asociados al ajuste de formato de código con otros estará dificultando un posterior análisis al realizar un svn diff.
Haga uso intensivo de la herramienta de seguimiento de errores
Trate en lo posible de crear enlaces bidireccionales entre el conjunto de cambios hechos en el repositorio de subversion y la herramienta de seguimientos de errores tanto como sea posible.
- Trate de hacer una referencia al id o número del ticket al cual está dando solución desde su mensaje de registro o log previo a realizar el commit.
- Cuando agregue información o responda a un ticket, ya sea para describir su avance o simplemente para cerrar el ticket, indique el número o números de revisión que atienden o responden a dichos cambios.
Indique en el registro de envío el resultado del merge
Cuando usted está enviando el resultado de un merge, asegúrese de indicar sus acciones en el registro de envío, tanto aquello que fue fusionado como los números de revisiones que fueron tomadas en cuenta. Ejemplo:
Fusión de las revisiones 10:40 de /branches/foo a /trunk.
Tenga claro cuando es oportuno crear una rama
Esto es un tema polémico. Sin embargo, dependiendo del proyecto en el que esté involucrado usted puede definir una estrategia o mezcla de ellas para manejar el desarrollo del proyecto. Generalmente puede encontrar lo siguiente:
Los proyectos que requieren un alto manejo y supervisión recurren a estrategias de siempre crear ramas, acá puede encontrarse que cada colaborador crea o trabaja en una rama privada para cada tarea de codificación. Cuando el trabajo individual ha finalizado, algún responsable, ya sea el fundador del proyecto, un revisor técnico, analiza los cambios hechos por el colaborador y hace la fusión con la línea principal de desarrollo. En estos casos la rama principal de desarrollo suele ser bastante estable. Sin embargo, este modo de trabajo conlleva normalmente a crear mayores conflictos en la etapa de fusión o merge, además, las labores de fusión bajo este esquema son constantemente requeridas.
Existe otro enfoque que permite mantener una línea base de desarrollo estable, el cual consiste en crear ramas de desarrollo solo cuando se ameritan. Sin embargo, esto requiere que los colaboradores tengan mayor dominio del uso de Subversion y una constante comunicación entre ellos. Además de aumentar el número de pruebas antes de cada envío al repositorio centralizado.
Estudie, analice las distintas opciones y defina un método para la creación de ramas en su proyecto. Una vez definido, es sumamente importante que cada colaborador tenga clara esta estrategia de trabajo.
Las estrategias antes mencionadas y otras más pueden verse en detalle en:
Los sistemas de control de versiones no substituyen la comunicación entre los colaboradores
Por último pero no menos importante, los sistemas de control de versiones no substituyen la comunicación entre los desarrolladores o colaboradores del proyecto de software. Cuando usted tenga planes de hacer un cambio que pueda afectar una cantidad de código considerable en su proyecto, establezca un control de cambios, haga un análisis de las posibles consecuencias o impacto de los mismos, difunda esta información a través de una lista de discusión (usted mantiene una lista de discusión para desarrolladores, ¿verdad?) y espere la respuesta, preocupaciones, sugerencias de los demás colaboradores, quizá juntos se encuentre un modo más eficaz de aplicar los cambios.
Referencias:
- Subversion Best Practices (presentación)
- SVN commit basic policy guide
- Subversion Best Practices
- Subversion Best Practices (presentación)
Programación Extrema
La Programación Extrema es ideal en aquellos proyectos en donde se requiere un desarrollo a corto plazo, en donde los requerimientos pueden ser cambiados en cualquier instante, de hecho, su principal objetivo es reducir los costos generados por los cambios en los requerimientos. Se propone como un paradigma en donde se proveen numerosas ventajas en la reutilización del código.
Se evita el diseño extensivo que presentan los modelos tradicionales, en donde los requerimientos del sistema son determinados al inicio del desarrollo del proyecto y a menudo son corregidos desde ese punto, esto implica que los costos ocasionados por los cambios de los requerimientos en una fase avanzada del proyecto sean bastante elevados, esto evidentemente es un problema para empresas que presentan cambios constantes.
Las prácticas principales en la Programación Extrema son aquellas que generalmente son aceptadas como buenas, pero en este paradigma se llevan al extremo.
La comunicación entre los desarrolladores y los clientes debe ser excelente. De hecho, se supone que un grupo de desarrollores tenga al menos un cliente en el sitio, que especifique y dé prioridad al trabajo que realizan los desarrolladores, que responda las preguntas tan pronto como se presenten.
Se busca la simplicidad en la escritura del código fuente, cuando éste se vuelve complejo, se recomienda una reescritura del código.
Las revisiones del código también se llevan al extremo, el paradigma de la Programación Extrema propone que los desarrolladores trabajen en parejas, compartiendo la pantalla y el teclado del ordenador, esto a la vez de promover la comunicación entre los desarrolladores permite que el código sea revisado mientras se escribe.
La Programación Extrema asegura la calidad en la aplicación desarrollada al momento de realizar lo que ellos llaman refactorización, el cual es un proceso de reestructuración del sistema, en donde se elimina la duplicación, se promueve simplificación y se le agrega flexibilidad sin cambiar la funcionalidad de operación del código.
Este paradigma funciona mejor en proyectos de pequeña o mediana escala (los grupos de desarrolladores no deben sobrepasar las 10 personas cada uno). Ideal en aquellas aplicaciones que necesitan una nueva versión cada 2 ó 3 semanas.
Internet
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Planeta Linux estrena instancia Chilena
Anoche, después de conversar con Damog, se habilitó una nueva instancia en Planeta Linux, en esta ocasión es Chile, la idea la sugirió a través de la lista de correos de Planeta Linux el sr. Flabio Pastén Valenzuela, así que cualquier chileno o chilena que esté interesado en participar en Planeta Linux solo debe escribir a la lista de correos [email protected] la siguiente información.
- Nombre Completo.
- URI del feed.
- Hackergothi, aunque es opcional.
- Instancia en la que deseas aparecer, en este caso, Chile.
Se le recomienda a quienes quieran participar en Planeta Linux leer en primera instancia su serie de respuestas a preguntas frecuentes y los lineamientos.
Femfox: una campaña no oficial con mucho glamour
 Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
Literatura
Libro oficial de Ubuntu
La primera edición del libro The Official Ubuntu Book estará lista para el día 4 de Agosto de este mismo año y contará con 320 páginas; la información anterior puede encontrarse en la preventa del libro realizada en Amazon.
Los autores del libro The Official Ubuntu Book son los siguientes:
- Benjamin Mako Hill: Autor del famoso libro Debian GNU/Linux 3.x Bible, desarrollador debian/ubuntu.
- Jono Bacon: Co-autor del libro Linux Desktop Hacks, publicado por O’Reilly, entre otras cosas, Jono colabora con el proyecto KDE.
- Corey Burger: Administrador del proyecto Ubuntu Documentation Project.
- Otros autores: Entre ellos se encuentran Ivan Krstic y Jonathan Jesse.
Este libro tendrá una licencia Creative Commons.
O3 Magazine
O3 Magazine es una revista distribuida de manera electrónica en formato PDF. El enfoque que pretende O3 es promover el uso/integración de programas basados en Software Libre y Código Abierto (FOSS) en ambientes empresariales.
O3 ha sido creada usando exclusivamente herramientas de código abierto. Como por ejemplo:
Scribus, permite crear publicaciones de escritorio profesionales, es usado para definir el layout y producir los PDFs. The Gimp, usado para la creación y manipulación de imágenes y Open Office, el cual es usado por los escritores para la creación de los artículos.
Cada edición de la revista O3 tratará de cubrir los siguientes tópicos:
- Seguridad
- Internet
- Tecnologías web
- Negocios
- Voz/Multimedia (VoIP)
- Redes
- Aplicaciones para redes
- Seguridad en redes
O3 Magazine pretende demostrar a sus lectores los beneficios y el ahorro que se genera al usar soluciones de código abierto en el ambiente de los negocios. También puede interesar a aquellos dueños de pequeñas y medianas empresas que estén interesados en una infraestructura IT fuerte, segura y escalable sin incurrir en altos costos.
Si desean tener la primera edición de O3 Magazine, pueden hacerlo en: Issue #1 (November 2005)
Como era de esperarse la publicación viene en inglés. De hecho, todas las revistas electrónicas que conozco y leo vienen en este idioma. Por lo descrito previamente me atrevo a preguntarles lo siguiente, ¿conocen alguna publicación electrónica de buena calidad que venga en español?.
Libros sobre Perl
Victor Reyes, miembro de la lista de correos para consultas técnicas de VELUG (Grupo de Usuario Linux de Venezuela), nos facilita de su biblioteca personal la excelente recopilación The Perl CD Bookshelf, el cual contiene 6 excelentes libros de la editorial O’Reilly sobre el lenguaje de programación Perl.
Actualización:
En la página principal de Victor Reyes podrán conseguir mayor documentación sobre otros temas, menciono solo algunos de ellos:
- Java
- TCP/IP
- Unix
- Java Enterprise
- Linux
- Oracle PL/SQL
- WWW
- FreeBSD
Ocio
Recuperando una antigua Logitech Quickcam Express
No se porque motivo o razón comencé a revisar en unas cajas de mi cuarto, cuando de repente me encontré con la primera cámara web que compre, de hecho, vino como accesorio a mi máquina de escritorio Compaq Presario 5006LA. Así que me pregunté, ¿será que todavía funciona esta reliquia?.
Lo primero que hice fue conectar el dispositivo en cuestión a mi portátil actual, enseguida ejecuté el comando:
$ lsusb | grep -i logitech
Bus 002 Device 002: ID 046d:0840 Logitech, Inc. QuickCam Express</code>
Una vez conocido el PCI ID (046d:0840) del dispositivo realicé una búsqueda rápida en Google y llegué a un sitio muy interesante, en donde podemos obtener una descripción de los dispositivos USB para Linux, al usar la función de búsqueda en la base de datos del sitio mencionado previamente ingreso el dato correspondiente al Vendor ID (en mi caso, 046d), posteriormente filtre los resultados por el Product ID (en mi caso, 0840), sentía que ya estaba dando con la solución a mi problema, había encontrado información detallada acerca de mi Logitech Quickcam Express. Al llegar acá descubrí el Linux QuickCam USB Web Camera Driver Project.
En la página principal del Linux QuickCam USB Web Camera Driver Project observo que mi vejestorio de cámara es soportada por el driver qc-usb.
Con la información anterior decido hacer uso del manejador de paquetes aptitude y en los resultados avisté el nombre de un paquete qc-usb-source, así que definitivamente nuestra salvación es module-assistant.
# aptitude install qc-usb-source \\
build-essential \\
module-assistant \\
modconf \\
linux-headers-`uname -r`
# m-a update
# m-a prepare
# m-a a-i qc-usb
Una vez realizado el paso anterior recurro a la utilidad de configuración de módulos en Debian modconf e instalo el módulo quickcam, el cual se encuentra en /lib/modules/2.6.18-4-686/misc/quickcam.ko y verificamos.
# tail /var/log/messages
May 14 21:16:57 localhost kernel: Linux video capture interface: v2.00
May 14 21:16:57 localhost kernel: quickcam: QuickCam USB camera found (driver version QuickCam USB 0.6.6 $Date: 2006/11/04 08:38:14 $)
May 14 21:16:57 localhost kernel: quickcam: Kernel:2.6.18-4-686 bus:2 class:FF subclass:FF vendor:046D product:0840
May 14 21:16:57 localhost kernel: quickcam: Sensor HDCS-1000/1100 detected
May 14 21:16:57 localhost kernel: quickcam: Registered device: /dev/video0
May 14 21:16:57 localhost kernel: usbcore: registered new driver quickcam
Como puede observarse el dispositivo es reconocido y se ha registrado en /dev/video0. En este instante que poseemos los módulos del driver qc-sub para nuestro kernel, podemos instalar la utilidad qc-usb-utils, esta utilidad nos permitirá modificar los parámetros de nuestra Logitech QuickCam Express.
# aptitude install qc-usb-utils
Ahora podemos hacer una prueba rápida de nuestra cámara, comienza la diversión, juguemos un poco con mplayer.
$ mplayer tv:// -tv driver=v4l:width=352:height=288:outfmt=rgb24:device=/dev/video0:noaudio -flip
A partir de ahora podemos probar más aplicaciones ;)
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
campaign
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
dapper
Ubuntu Dapper Drake Flight 6
Flight 6, es la última versión alpha disponible de Ubuntu Dapper Drake, esta versión ha sido probada razonablemente, pero recuerde que a pesar de ello todavía es una versión alpha, así que no se recomienda su uso en medios en producción. Esta versión puede descargarla desde:
- Europa:
- Reino unido y el resto del mundo:
- Bittorent: Se recomienda su uso si es posible.
- Sitios Espejos: Una lista de sitios espejos puede encontrarse en: Ubuntu Mirror System.
Una lista con los cambios notables en esta sexta versión alpha pueden ser encontrados en Dapper Flight 6.
nVIDIA en Ubuntu 6.04
Hace unos días actualicé mi Ubuntu 5.10 a una de sus últimas versiones de testing: Flight 5. Debo admitir que quedé anonadado por lo cambios en la distribución, ya que con todas las mejoras que tiene parece que hubiera pasado, no sólo 6 meses sino años. El Dapper Drake (Flight 5, Ubuntu 6.04) es mucho mejor que sus antecesores. Pero la razón por la cual me decidí a escribir éste artículo es otra: la instalación de los drivers de mi tarjeta nVIDIA y su puesta en funcionamiento a punto.
Cuando actualicé mi sistema no hubo ningún problema, y lo digo en serio, ningún problema de ninguna índole. Toda mi configuración de escritorio quedó intacta; pero empecé a notar que la configuración de la tarjeta de video no se cargaba con el sistema. Entonces supe que, por alguna razón, los drivers de la tarjeta habían cambiado, es decir, el sistema asignó el driver por defecto para la tarjeta, más no los drivers de la tarjeta misma. Entonces tuve que ponerme a configurar la tarjeta.
Lo primero que hice fué verificar que los drivers vinieran con la distribución. Lo hice con la siguiente línea:
$ sudo aptitude search nvidia
Con lo cual obtuve lo siguiente:
i nvidia-glx - NVIDIA binary XFree86 4.x/X.Org driver
v nvidia-kernel-1.0.7174 -
v nvidia-kernel-1.0.8178 -
i nvidia-kernel-common - NVIDIA binary kernel module common files
Entonces ya sabía que los drivers venían con la distro, lo cual me pareció fascinante, ya que en realidad el Flight 5, no es la versión definitiva del Dapper Drake. Luego procedí a verificar la documentación de dicho paquete. Ésto lo hice con la siguiente línea de comandos:
$ sudo aptitude show nvidia-glx
Esto lo hice para verificar que no haya alguna clase de conflictos con otros paquetes, pero en realidad no es un paso necesario, ya que aptitude resuelve todo tipo de conflictos y dependencias. Después de verificar que todo estaba en orden me decidí a instalar los drivers. Ésto lo hice con la siguiente linea de comandos:
$ sudo aptitude install nvidia-glx
Con lo cual quedaron instalados los drivers de la tarjeta de manera trasparente y rápida. Lo siguiente que debía hacer, era activar la configuración de la tarjeta. Lo cual hice con la siguiente línea de comandos:
$ sudo nvidia-glx-config enable
Una vez hecho ésto ya podía configurar la tarjeta. Algo que hay que hacer notar es que, para las distribuciones anteriores de Ubuntu, había que instalar de manera separada el paquete nvidia-glx y el nvidia-settings, sin embargo, aquí queda todo instalado de una vez. Lo que sigue es iniciar la configuración de la tarjeta, lo cual hice con la siguiente línea de comandos:
$ nvidia-settings
Y ya tenía acceso a la configuración de mi tarjeta. Sin embargo, al hacer todo ésto, la configuración no se carga al iniciar el sistema, pero no fué problema, porque lo solucioné colocando en los programas de inicio del gnome-session-manager los siguiente:
nvidia-settings -l
Este comando carga la configuración de nvidia-settings que tengamos actualmente. Es lo mismo que, una vez que haya cargado el sistema, ejecutemos en la consola éste comando, sólo que ahora se va a ejecutar apenas inicie el sistema operativo.
Otros ajustes…
Si quieren colocar un lanzador en los menús del panel de gnome deben hacer los siguiente:
$ sudo gedit /usr/share/applications/NVIDIA-Settings.desktop
Y luego insertar lo siguiente en dicho fichero:
[Desktop Entry]
Name=Configuración nVIDIA
Comment=Abre la configuración de nVIDIA
Exec=nvidia-settings
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya tendrán un lanzador en los menús del panel de gnome. Una opción sería utilizar el editor de menús Alacarte.
nvidia-xconf
nvidia-xconf es una utilidad diseñada para hacer fácil la edición de la configuración de X. Para ejecutarlo simplemente debemos escribir en nuestra consola lo siguiente:
$ sudo nvidia-xconfig
Pero en realidad, ¿qué hace nvidia-xconfig? nvidia-xconfig, encontrará el fichero de configuración de X y lo modificará para usar el driver nVIDIA X. Cada vez que se necesite reconfigurar el servidor X se puede ejecutar desde la terminal. Algo interesante es que cada vez que modifiquemos el fichero de configuración de X con nvidia-xconfig, éste hará una copia de respaldo del fichero y nos mostrará el nombre de dicha copia. Algo muy parecido a lo que sucede cada vez que hacemos:
dpkg-reconfigure xserver-xorg
Una opción muy útil de nvidia-xconfig es que podemos añadir resoluciones al fichero de configuración de X simplemente haciendo:
$ sudo nvidia-xconfig --mode=1280x1024
…por ejemplo.
Ubuntu (Dapper Drake) Flight 3
La tercera versión alpha de Ubuntu 6.04 (Dapper Drake), continúa mostrando mejoras e incluye nuevo software.
Las mejoras incluyen una actualización en el tema, el cual desde la segunda versión alpha es manejado por gfxboot.
Ademas se incluye X Window System versión X11R7, GNOME 2.13.4, también se observan mejoras y simplificación de los menús, algunas nuevas aplicaciones como XChat-GNOME, un LiveCD más rápido y que permite almacenar nuestras configuraciones.
También se notan algunas mejoras estéticas en el cuadro de dialógo de cierre de sesión.
En cuanto a la mejora y simplificación de los menús, la idea básicamente es obviar aquellas opciones que pueden llegar a ser confusas para los usuarios, también se evita la duplicación de opciones, esto permite que exista un solo punto para acceder a cada función del sistema, mejorando de esta manera la usabilidad en nuestro escritorio favorito.
Se ha creado un nuevo dialógo que indica cuando es necesario reiniciar el sistema, esto sucede cuando se realizan importantes actualizaciones al sistema, en donde es recomendable reiniciar el sistema para que dichas actualizaciones surtan efecto.
¿Qué mejoras incluye la versión LiveCD?
Quién haya usado alguna vez en su vida un LiveCD puede haberse percatado que éstos presentan ciertos problemas, uno de ellos es la lentitud en el tiempo de carga del sistema, en este sentido se han realizado algunas mejoras en el cargador utilizado en el arranque, el tiempo de carga se ha reducido aproximadamente de unos 368 segundos a 231 segundos, esta mejora es bastante buena, aunque se espera mejorar aún mas este tiempo de carga del LiveCD.
Otro de los problemas encontrados en los LiveCD, es que el manejo de los datos no es persistente, esta nueva versión incluye una mejora que permite recordar las configuraciones, esto quiere decir que la siguiente vez que usted utilice el LiveCD dichas configuraciones serán recordadas. Esto es posible ya que el LiveCD permite guardar sus cambios en un dispositivo externo (al CD) como por ejemplo un llavero usb. Por lo tanto, si usted especifica el parámetro persistent cuando usted esta iniciando el LiveCD, éste buscará el dispositivo externo que mantiene las configuraciones que usted ha almacenado. Si desea conocer más acerca de esta nueva funcionalidad en el LiveCD vea el documento LiveCDPersistence.
Si usted desea descargar esta tercera versión alpha de Ubuntu 6.04, puede hacerlo en Ubuntu (Dapper Drake) Flight CD 3.
Mayor detalle acerca de las nuevas características que presenta esta nueva versión en el documento DapperFlight3.
Nota: Esta versión no es recomendable instalarla en entornos de producción, la versión estable de Dapper Drake se espera para Abril de este mismo año.
planetalinux
Planeta Linux estrena instancia Chilena
Anoche, después de conversar con Damog, se habilitó una nueva instancia en Planeta Linux, en esta ocasión es Chile, la idea la sugirió a través de la lista de correos de Planeta Linux el sr. Flabio Pastén Valenzuela, así que cualquier chileno o chilena que esté interesado en participar en Planeta Linux solo debe escribir a la lista de correos [email protected] la siguiente información.
- Nombre Completo.
- URI del feed.
- Hackergothi, aunque es opcional.
- Instancia en la que deseas aparecer, en este caso, Chile.
Se le recomienda a quienes quieran participar en Planeta Linux leer en primera instancia su serie de respuestas a preguntas frecuentes y los lineamientos.
Lavado de cara para Planeta Linux
Desde las 2:00 p.m. (hora local) del día de hoy, con la asistencia del compañero Damog, hemos ido actualizando el layout de Planeta Linux, aún falta mucho trabajo por hacer, pero al menos ya hemos dado los primeros pasos.
Cualquier opinión, crítica, sugerencia, comentario agradecemos enviar un correo electrónico a la lista de correos de Planeta Linux. *[p.m.]: Post meridiem
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
security
Fortaleciendo nuestras contraseñas
Si una de las promesas que tiene para este cierre de año es fortalecer las
contraseñas en sus equipos personales, cambiarlas mensualmente y no repetir la
misma contraseña en al menos doce cambios. En este artículo se le explicará como
hacerlo sin tener que invertir una uva en ello, todo esto gracias al paquete
libpam-cracklib en Debian, el procedimiento mostrado debe aplicarse a otras
distribuciones derivadas de Debian.
Pareciese lógico que algunas de las mejores prácticas para el fortalecimiento de las contraseñas son las siguientes:
- Cambiar las contraseñas periódicamente.
- Establecer una longitud mínima en las contraseñas.
- Establecer buenas reglas para las nuevas contraseñas, es decir, mezcla entre letras mayúsculas, minúsculas, dígitos y caracteres alfanuméricos.
- Mantener un histórico de las contraseñas usadas previamente, de ese modo, alentamos a los usuarios establecer nuevas contraseñas.
- Indicarle a los usuarios que es inaudito que se anoten las contraseñas en un post-it y se dejen pegadas en los monitores o incluso en las gavetas de sus archivadores.
El primer paso es instalar el paquete libpam-cracklib
# apt-get install libpam-cracklib
A partir de la versión 1.0.1-6 de PAM se recomienda manejar la configuración vía
pam-auth-update. Por lo tanto, por favor tome un momento y lea la sección 8
del manual del comando pam-auth-update para aclarar su uso y ventajas.
$ man 8 pam-auth-update
Ahora establezca una configuración similar a la siguiente, vamos primero con la
exigencia en la fortaleza de las contraseñas, para ello edite o cree el fichero
/usr/share/pam-configs/cracklib.
Name: Cracklib password strength checking
Default: yes
Priority: 1024
Conflicts: unix-zany
Password-Type: Primary
Password:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
Password-Initial:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
NOTA: Le recomiendo leer la sección 8 del manual de pam_cracklib para
encontrar un mayor numero de opciones de configuración. Esto es solo un ejemplo.
En versiones previas el modulo pam_cracklib hacia uso del fichero
/etc/security/opasswd para conocer si la propuesta de cambio de contraseña no
había sido utilizada previamente. Dicha funcionalidad ahora corresponde al nuevo
modulo pam_pwhistory
Definamos el funcionamiento de pam_pwhistory a través del fichero
/usr/share/pam-configs/history.
Name: PAM module to remember last passwords
Default: yes
Priority: 1023
Password-Type: Primary
Password:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
Password-Initial:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
NOTA: Para mayor detalle de las opciones puede revisar la sección 8 del
manual de pam_pwhistory
Seguidamente proceda a actualizar la configuración de PAM vía pam-auth-update.
Una vez cubierta la fortaleza de las contraseñas nuevas y de evitar la reutilización de las ultimas 12, de acuerdo al ejemplo mostrado, resta cubrir la definición de los periodos de cambio de las contraseñas.
Para futuros usuarios debemos ajustar ciertos valores en el fichero
/etc/login.defs
#
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 30
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Las reglas previas no aplicaran para los usuarios existentes, pero para este
tipo de usuarios podremos hacer uso del comando chage de la siguiente manera:
# chage -m 0 -M 30 -W 5 ${user}
Donde el valor de ${user} debe ser reemplazo por el username.
Generando contraseñas aleatorias con Perl
El día de hoy se manifestó la necesidad de generar una serie de claves aleatorias para un proyecto en el que me he involucrado recientemente, la idea es que la entrada que tenemos corresponde más o menos al siguiente formato:
username_1
username_2
...
username_n
La salida que se desea obtener debe cumplir con el siguiente formato:
username_1 pass_1
username_2 pass_2
username_3 pass_3
...
username_n pass_n
En este caso debía cumplir un requisito fundamental, las contraseñas deben ser suficientemente seguras.
No pensaba en otra cosa que usar el lenguaje de programación Perl para realizar esta tarea, así fue, hice uso del poderío que brinda Perl+CPAN y en menos de 5 minutos ya tenía la solución al problema planteado, el tiempo restante me sirvió para comerme un pedazo de torta que me dió mi hermana, quien estuvo de cumpleaños el día de ayer.
En primer lugar, debemos instalar el módulo String::MkPasswd, el cual nos permitirá generar contraseñas de manera aleatoria. Si usted disfruta de una distribución decente como DebianRecuerde, Debian es inexorable la instalación del módulo es realmente trivial.
# aptitude install libstring-mkpasswd-perl
Además, si usted se detiene unos segundos y lee la documentación del módulo String::MkPasswd Este modulo en particular no solo se encuentra perfectamente integrado con nuestra distribución favorita, sino que además sus dependencias están resueltas. Esto es una simple muestra del poderío que ofrece una distribución como Debian., se dará cuenta que la función mkpasswd() toma un hash de argumentos opcionales. Si no le pasa ningún argumento a esta función estará generando constraseñas aleatorias con las siguientes características:
- La longitud de la contraseña será de 9.
- El número mínimo de dígitos será de 2.
- El número mínimo de caracteres en minúsculas será de 2.
- El número mínimo de caracteres en mayúsculas será de 2.
- El número mínimo de caracteres no alfanuméricos será de 1.
- Los caracteres no serán distribuidos entre los lados izquierdo y derecho del teclado.
Ahora bien, asumiendo que el fichero de entrada es users.data, la tarea con Perl es resumida en una línea de la siguiente manera.
perl -MString::MkPasswd=mkpasswd -nli -e 'print $_, " ", mkpasswd()' users.data
La línea anterior hace uso de la función mkpasswd del módulo String::MkPasswd para generar las contraseñas aleatorias para cada uno de los usuarios que se encuentran en el fichero de entrada users.data, además, la opción -iPara mayor información acerca de las distintas opciones usadas se le sugiere referirse a man perlrun permite editar el fichero de entrada in situ, ahora bien, quizá para algunos paranoicos (me incluyo) no sea suficiente todo esto, así que vamos a generar contraseñas aleatorias aún más complicadas.
#!/usr/bin/perl -li
use strict;
use warnings;
use String::MkPasswd qw(mkpasswd);
while(<>){
chomp;
print $_, " ", mkpasswd(
-length => 16,
-minnum => 5,
-minlower => 5,
-minupper => 3,
-minspecial => 3,
-distribute => 1
);
}En esta ocasión el la función mkpasswd() generará claves aún más complejas, dichas claves cumplirán con las siguientes condiciones.
-
-length: La longitud total de la contraseña, 16 en este caso. -
-minnum: El número mínimo de digitos. 5 en este caso. -
-minlower: El número mínimo de caracteres en minúsculas, en este caso 5. -
-minupper: El número mínimo de caracterés en mayúsculas, en este caso 3. -
-minspecial: El número mínimo de caracteres no alfanuméricos, en este caso será de 3. -
-distribute: Los caracteres de la contraseña serán distribuidos entre el lado izquierdo y derecho del teclado, esto hace más díficil que un fisgón vea la contraseña que uno está escribiendo. El valor predeterminado es falso, en este caso el valor es verdadero.
El script mostrado anteriormente lo podemos reducir a una línea, aunque preferí guardarlo en un fichero al que denomine genpasswd.pl por cuestiones de legibilidad.
Vulnerabilidad grave corregida en ubuntu
La vulnerabilidad en ubuntu donde cualquiera con acceso al shell podía ver la contraseña del instalador del sistema ha sido reparada.
Los paquetes afectados son base-config y passwd en Ubuntu 5.10 (Breezy Badger), el problema puede ser corregido al actualizar los paquetes afectados a las versiones 2.67ubuntu20 (base-config) y 1:4.0.3-37ubuntu8 (passwd). En general, una actualización del sistema es suficiente para que los cambios surtan efecto.
La vulnerabilidad en donde era posible ver la constraseña del instalador de ubuntu y así tener acceso a privilegios de superusuario (por supuesto, si la contraseña no había sido cambiada desde la instalación) fue descubierta por Karl Øie, el instalador de Ubuntu 5.10 falla en la limpieza de contraseñas en los ficheros de registros de instalación. Dichos ficheros pueden ser leidos por cualquiera, de este modo cualquier usuario local pudiese ver las contraseñas del primer usuario, el cual tiene privilegios por completo en una instalación por defecto.
El paquete actualizado eliminará las contraseñas almacenadas en texto plano en los ficheros de registro de instalación y adicionalmente hará que los registros sean leídos únicamente por el superusuario.
Esta vulnerabilidad no afecta a los instaladores de las versiones 4.10, 5.04, o la que está por llegar, 6.04. Sin embargo, considere necesario aplicar el parche si usted ha actualizado su sistema desde Ubuntu 5.10 a la actual versión en desarrollo 6.04 (Dapper Drake), en este caso verifique que ha actualizado el paquete passwd a la versión 1:4.0.13-7ubuntu2.
wireless
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
Haciendo el cambio de ipw3945 a iwl3945
Si usted es de esas personas que cuenta con una tarjeta inalámbrica Intel Corporation PRO/Wireless 3945, seguramente sabrá que existen al menos dos proyectos que le dan soporte. El primero de ellos es ipw3945 y se encuentra obsoleto, el desarrollo pasó al proyecto iwlwifi.
Aprovechando que recientemente ha ingresado a la versión inestable de Debian la serie del kernel 2.6.24, este contiene el nuevo modulo iwl3945 que reemplaza al viejo ipw3945. Una de las ventajas de este cambio es que ya no hay necesidad de tener activo el demonio ipw3945d. Sin embargo, aun se necesita del firmware que se encuentra en la sección non-free del repositorio de Debian.
Hasta donde he leído el plan será remover los paquetes ipw3945-modules-* e ipw3945d de los repositorios de Debian (al menos en testing y en unstable) una vez que la serie 2.6.24 del kernel llegue a la versión de pruebas (testing). Aquellos que se encuentren hoy día en la versión inestable (unstable) de Debian deberán cambiar el driver desde ipw3945 a iwl3945. Para aquellos que trabajan en etch también es posible usar el driver iwl3945 si actualiza su versión del kernel por medio del repositorio etch-backports (el nuevo stack mac80211 que usa iwlwifi se encuentra a partir de la versión del kernel 2.6.22).
Las instrucciones que verá a continuación se han aplicado en Debian inestable, si usted desea instalar iwlwifi en etch puede seguir estas instrucciones.
Obteniendo algunos datos de interés antes de proceder con la actualización.
Versión del kernel:
$ uname -r
2.6.22-3-686
Verifique que en realidad tiene una tarjeta Intel Corporation PRO/Wireless 3945 $ lspci -nn | grep Wireless 03:00.0 Network controller [0280]: Intel Corporation PRO/Wireless 3945ABG Network Connection [8086:4227] (rev 02)
Paquetes necesarios
Ahora bien, es necesario instalar el nuevo kernel y el firmware necesario para hacer funcionar a iwlwifi
# aptitude install linux-image-2.6-686 \\
linux-image-2.6.24-1-686 \\
firmware-iwlwifi
Evitando problemas
Verifique que no existe alguna entrada que haga referencia al modulo ipw3945 en el fichero /etc/modules. Para ello recurrimos a Perl que nos facilita la vida.
# perl -i -ne 'print unless /^ipw3945/' /etc/modules
Debido a algunos problemas que se presentan en el paquete network-manager si anteriormente ha venido usando el modulo ipw3945 se recomienda eliminar la entrada que genera udev para dicho modulo en el fichero /etc/udev/rules.d/z25_persistent-net.rules, la entrada es similar a la siguiente:
# PCI device 0x8086:0x4227 (ipw3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTRS{address}=="00:13:02:4c:12:12", NAME="eth2"
Fichero /etc/network/interfaces
Este paso es opcional, agregamos la nueva interfaz wlan0 al fichero /etc/network/interfaces y procedemos a configurarla de acuerdo a nuestras necesidades.
auto lo
iface lo inet loopback
auto wlan0
iface wlan0 inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-key-mgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
En este caso particular se está indicando que nos vamos a conectar a un Access Point cuyo ssid es foo con tipo de cifrado WPA-PSK/WPA2-PSK, haciendo uso del driver wext que funciona como backend para wpa_supplicant. Es de hacer notar que el driver wext es utilizado por todos los adaptadores Intel Pro Wireless, eso incluye ipw2100, ipw2200 e ipw3945.
Para hacer funcionar WPA recuerde que debe haber instalado previamente el paquete wpasupplicant.
# aptitude install wpasupplicant
De igual manera se le recuerda adaptar todos aquellos parámetros como wpa-ssid y wpa-psk a aquellos adecuados en su caso. En particular el campo wpa-psk lo puede generar con el siguiente comando:
$ wpa_passphrase su_ssid su_passphrase
Aunque mi recomendación es usar el comando wpa_passphrase de la siguiente manera.
$ wpa_passphrase su_ssid
Posteriormente deberá introducir su_passphrase desde la entrada estándar, esto evitará que su_passphrase quede en el historial de comandos.
Para mayor detalle de los campos expuestos en la configuración del fichero /etc/network/interfaces se le recomienda leer la documentación expuesta en /usr/share/doc/wpasupplicant/README.modes.gz.
Una vez concluidos estos pasos reiniciamos el sistema y seleccionamos en nuestro Gestor de Arranque (ej. GRUB) la versión del kernel recien instalada. Al momento de iniciar su sesión verifique que su tarjeta inalámbrica esté funcionando, de lo contrario haga las revisiones que se indican en la siguiente sección.
En caso de persistir los problemas
Remueva y reinserte el modulo iwl3945
# modprobe -r iwl3945
# modprobe iwl3945
De manera adicional compruebe que udev haya generado una nueva entrada para iwl3945.
$ cat /etc/udev/rules.d/z25_persistent-net.rules
...
# PCI device 0x8086:0x4227 (iwl3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTR{address}=="00:13:02:4c:12:12", ATTR{type}=="1", NAME="wlan0"
Finalmente, reestablecemos la interfaz de red.
# ifdown wlan0
# ifup wlan0
Elimine ipw3945
Una vez verificado el correcto funcionamiento del módulo iwl3945 puede eliminar con seguridad todo aquello relacionado con el modulos ipw3945.
# aptitude --purge remove firmware-ipw3945 \\
ipw3945-modules-$(uname -r) \\
ipw3945-source ipw3945d
Estas instrucciones también aplican para el modulo iwl4965. Mayor información en Debian Wiki § iwlwifi.
Network Manager: Facilitando el manejo de redes inalámbricas
En la entrada previa, Establecer red inalámbrica en Dell m1210, comencé a describir el proceso que seguí para lograr hacer funcionar la tarjeta Broadcom Corporation Dell Wireless 1390 WLAN Mini-PCI Card (rev 01) en una portátil Dell m1210. El motivo de esta entrada se debe a que muchos usuarios hoy día no les interesa ni debe interesarles estar lidiando con la detección de redes inalámbricas, por eso les pasaré a comentar acerca de NetworkManager.
NetworkManager es una aplicación cuyo objetivo es que el usuario nunca tenga que lidiar con la línea de comandos o la edición de ficheros de configuración para manejar sus redes (ya sea cableada o inalámbrica), haciendo que la detección de dichas redes simplemente funcione tanto como se pueda y que interrumpa lo menos posible el flujo de trabajo del usuario. De manera que cuando usted se dirija a áreas en las cuales usted ha estado antes, NetworkManager se conectará automáticamente a la última red que haya escogido. Asimismo, cuando usted esté de vuelta al escritorio, NetworkManager cambiará a la red cableada más rápida y confiable.
Por los momentos, NetworkManager soporta redes cifradas WEP, el soporte para el cifrado WPA está contemplado para un futuro cercano. Respecto al soporte de VPN, NetworkManager soporta hasta ahora vpnc, aunque también está contemplado darle pronto soporte a otros clientes.
Para hacer funcionar NetworkManager en Debian los pasos que debemos seguir son los siguientes. En primera instancia instalamos el paquete.
# aptitude -r install network-manager-gnome
Que conste que NetworkManager funciona para entornos de escritorios como GNOME, KDE, XFCE, entre otros. En este caso particular estoy instalando el paquete disponible en Debian para GNOME en conjunto con sus recomendaciones.
De acuerdo al fichero /usr/share/doc/network-manager/README.Debian NetworkManager consiste en dos partes: uno a nivel del demonio del sistema que se encarga de manejar las conexiones y recoge información acerca de las nuevas redes. La otra parte es un applet que el usuario emplea para interactuar con el demonio de NetworkManager, dicha interacción se lleva a cabo a través de D-Bus.
En Debian por seguridad, los usuarios que necesiten conectarse al demonio de NetworkManager deben estar en el grupo netdev. Si usted desea agregar un usuario al grupo netdev utilice el comando adduser usuario netdev, luego de ello tendrá que recargar dbus haciendo uso del comando /etc/init.d/dbus reload.
Es necesario saber que NetworkManager manejará todos aquellos dispositivos que no estén listados en el fichero /etc/network/interfaces, o aquellos que estén listados en dicho fichero con la opción auto o dhcp, de esta manera usted puede establecer una configuración para un dispositivo que sea estática y puede estar seguro que NetworkManager no tratará de sobreescribir dicha configuración. Para mayor información le recomiendo leer detenidamente el fichero /usr/share/doc/network-manager/README.Debian.
Si usted desea que NetworkManager administre todas las interfaces posibles en su ordenador, lo más sencillo que puede hacer es dejar solo lo siguiente en el fichero /etc/network/interfaces.
$ cat /etc/network/interfaces
auto lo
iface lo inet loopback
Una vez que se ha modificado el fichero /etc/network/interfaces reiniciamos NetworkManager con el comando service network-manager restart. El programa ahora se encargará de detectar las redes inalámbricas disponibles. Para ver una lista de las redes disponibles, simplemente haga clic en el icono, tal como se muestra en la figura al principio de este artículo.
Había mencionado previamente que NetworkManager se conectará automáticamente a las redes de las cuales tiene conocimiento con anterioridad, pero usted necesitará conectarse manualmente a una red al menos una vez. Para ello, simplemente seleccione una red de la lista y NetworkManager automáticamente intentará conectarse. Si la red requiere una llave de cifrado, NetworkManager le mostrará un cuadro de dialogo en el cual le preguntará acerca de ella. Una vez ingresada la llave correcta, la conexión se establecerá.
Para cambiar entre redes, simplemente escoja otra red desde el menú que le ofrece el applet.
apache
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
Vulnerabilidad en Apache
Según un anuncio hecho el día de hoy por Adam Conrad a la lista de seguridad de ubuntu existe una vulnerabilidad que podría permitirle a una página web maligna (o un correo electrónico maligno en HTML) utilizar técnicas de Cross Site Scripting en Apache. Esta vulnerabilidad afecta a las versiones: Ubuntu 4.10 (Warty Warthog), Ubuntu 5.04 (Hoary Hedgehog) y Ubuntu 5.10 (Breezy Badger).
De manera adicional, Hartmut Keil descubre una vulnerabilidad en el módulo SSL (mod_ssl), que permitiría realizar una denegación de servicio (DoS), lo cual pone en riesgo la integridad del servidor. Esta última vulnerabilidad solo afecta a apache2, siempre y cuando esté usando la implementación “worker” (apache2-mpm-worker).
Los paquetes afectados son los siguientes:
apache-commonapache2-commonapache2-mpm-worker
Los problemas mencionados previamente pueden ser corregidos al actualizar los paquetes mencionados.
bittorrent
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
blogging
Amigas se unen a la blogocosa
Así como lo indica el título de esta entrada, dos mujeres muy importantes en mi vida, se unen a la blogocosa, la primera, mi novia Ana Rangel, la segunda es mi querida amiga Gaby Márquez, ambas comparten conmigo estudios en la carrera de Ing. de Sistemas en la Universidad de Los Andes, espero que realmente inviertan tiempo a esta tarea. Estaré atento a sus artículos y trataré de darles ánimo.
Ana y Gaby, bienvenidas a la blogocosa.
Actualizando WordPress
Tenía cierto tiempo que no actualizaba la infraestructura que mantiene a MilMazz, el día de hoy he actualizado WordPress a su version 2.0.2, este proceso como siempre es realmente sencillo, no hubo problema alguno.
También he aprovechado la ocasión para actualizar el tema K2, creado por Michael Heilemann y Chris J. Davis, de igual manera, he actualizado la mayoría de los plugins.
Respecto al último punto mencionado en el párrafo anterior, algo extraño sucedió al actualizar el plugin Ultimate Tag Warrior, al revisar su funcionamiento me percaté que al intentar ingresar a una etiqueta particular se generaba un error 404, de inmediato supuse que era la estructura de los enlaces permanentes y las reglas de reescritura, para solucionar el problema simplemente actualice la estructura de enlaces permanentes desde las opciones de la interfaz administrativa de WordPress.
Si nota cualquier error le agradezco me lo haga saber a través de la sección de contacto.
bug
WordPress 2.0.3
Matt Mullenweg anunció hace pocos días la disponibilidad de la versión 2.0.3 para WordPress, la versión más reciente hasta ahora de la serie estable 2.0.
Características en la versión 2.0.3
En esta nueva versión se puede observar.
- Mejoras en cuanto al rendimiento.
- Mejora en el sistema que permite importar entradas o posts desde Movable Type o Typepad.
- Mejora en cuanto al manejo de los enclosures Un enclosure es una manera de adjuntar contenido multimedia a un feed RSS, simplemente asociando la URL del fichero a la entrada particular. Esta característica es de vital importancia para la difusión del podcasting. para podcasts Mayor información acerca del podcasting.
- Corrección de errores de seguridad.
Se corrige el error de seguridad que permitía la inyección de código PHP arbitrario si se encontraba activo el registro libre de usuarios, era necesario desmarcar la casilla de verificación Cualquiera puede registrarse para subsanar el error, dicha casilla puede encontrarla en el área administrativa bajo Opciones -> General.
Si lo desea, puede apreciar la lista completa de las correcciones realizadas para esta versión, algunas de las que llamaron mi atención fueron la #2463 y el #2548, en ambas correcciones se aprecia la optimización en cuanto al rendimiento de WordPress.
Pasos para actualizar desde la versión 2.0.2 a 2.0.3
- Eliminar el contenido de la carpeta /wp-admin.
- En caso de utilizar el directorio /wp-includes/languages, debe respaldarlo. (Opcional).
- Eliminar el contenido de la carpeta /wp-includes.
- Eliminar todos los ficheros del directorio raíz de tu instalación de WordPress, excepto el fichero de configuración, wp-config.php.
- Descargar y descomprimir la nueva versión de WordPress.
- Restaurar las carpetas /wp-admin y /wp-includes. En caso de haber realizado el paso 2, recuerda restaurar también la carpeta /wp-includes/languages.
- Restaurar los ficheros del directorio raíz de tu instalación de WordPress.
- En el paso anterior, no es necesario colocar los ficheros wp-config-sample.php, license.txt, ni el readme.html, bien puedes eliminarlos si gustas.
- Ingresa en el área administrativa, proceda a actualizar la base de datos.
Eso es todo, como siempre, recuerde que es recomendable eliminar los ficheros install.php y upgrade.php, los cuales se encuentran en el directorio /wp-admin
Después de actualizar a la versión 2.0.3
Aún después de actualizar WordPress, existen algunos comportamientos extraños. Cuando usted edita un comentario aparecerá un cuadro de dialogo que le preguntará si está seguro de realizar dicha acción, de igual manera sucede si usted intenta editar un enlace o un usuario, entre otras cosas.
Si usted quiere deshacerse de esos comportamientos extraños, le recomiendo instalar el plugin WordPress 2.0.3 Tuneup, los errores que corrige este plugin hasta su versión 0.3 son: #2760, #2761, #2764, #2776, #2782.
De acuerdo al roadmap de WordPress se espera que la versión 2.0.4 esté lista para el día 30/06/2006.
Vulnerabilidad grave corregida en ubuntu
La vulnerabilidad en ubuntu donde cualquiera con acceso al shell podía ver la contraseña del instalador del sistema ha sido reparada.
Los paquetes afectados son base-config y passwd en Ubuntu 5.10 (Breezy Badger), el problema puede ser corregido al actualizar los paquetes afectados a las versiones 2.67ubuntu20 (base-config) y 1:4.0.3-37ubuntu8 (passwd). En general, una actualización del sistema es suficiente para que los cambios surtan efecto.
La vulnerabilidad en donde era posible ver la constraseña del instalador de ubuntu y así tener acceso a privilegios de superusuario (por supuesto, si la contraseña no había sido cambiada desde la instalación) fue descubierta por Karl Øie, el instalador de Ubuntu 5.10 falla en la limpieza de contraseñas en los ficheros de registros de instalación. Dichos ficheros pueden ser leidos por cualquiera, de este modo cualquier usuario local pudiese ver las contraseñas del primer usuario, el cual tiene privilegios por completo en una instalación por defecto.
El paquete actualizado eliminará las contraseñas almacenadas en texto plano en los ficheros de registro de instalación y adicionalmente hará que los registros sean leídos únicamente por el superusuario.
Esta vulnerabilidad no afecta a los instaladores de las versiones 4.10, 5.04, o la que está por llegar, 6.04. Sin embargo, considere necesario aplicar el parche si usted ha actualizado su sistema desde Ubuntu 5.10 a la actual versión en desarrollo 6.04 (Dapper Drake), en este caso verifique que ha actualizado el paquete passwd a la versión 1:4.0.13-7ubuntu2.
cnti
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
Campaña CNTI vs. Software Libre
Javier E. Pérez P. planteaba en el tema HOY MARTES debemos colocar los banners y escritos sobre el caso IBM y CNTI!!!! de la lista de correos de Softwarelibre (Lista General de Discusión Sobre Software Libre) lo siguiente.
… tambien creo que seria bueno hacer una banner flotante como los hace la fundacion make poverty history [1] el cual es un javascript que coloca en la parte superior de la pagina una banda [2].
Después de ver el código que propone la fundación mencionada por Javier me puse a trabajar en Inkscape y The Gimp, me he basado en uno de los textos desarrollados por el profesor Francisco Palm y el resultado lo puede apreciar al principio de esta entrada o en la parte superior derecha de la página principal de este blog.
¿Desea unirse a la campaña?
Si le gusta la idea puede colocar la banda en su sitio web, solamente debe agregar el siguiente código debajo de la etiqueta <body>.
<script type="text/javascript"
src="http://blog.milmazz.com.ve/cnti/cntivssl.js"></script><noscript><a
href="http://bureado.com.ve/solve.html">http://bureado.com.ve/solve.html</a></noscript>
Además, si lo prefiere, puede descargar el trabajo que he realizado.
Actualización: Si decide usar la banda y unirse a esta campaña en contra de la gestión actual del CNTI, sería agradable que me comunicara a través de un comentario en esta entrada o por privado para conocerles y agregarles a la lista de sitios que poseen la banda.
¿Quiénes se han unido a la campaña?
Le recuerdo que: ¡cualquier sugerencia es bienvenida!.
cpan
Generando contraseñas aleatorias con Perl
El día de hoy se manifestó la necesidad de generar una serie de claves aleatorias para un proyecto en el que me he involucrado recientemente, la idea es que la entrada que tenemos corresponde más o menos al siguiente formato:
username_1
username_2
...
username_n
La salida que se desea obtener debe cumplir con el siguiente formato:
username_1 pass_1
username_2 pass_2
username_3 pass_3
...
username_n pass_n
En este caso debía cumplir un requisito fundamental, las contraseñas deben ser suficientemente seguras.
No pensaba en otra cosa que usar el lenguaje de programación Perl para realizar esta tarea, así fue, hice uso del poderío que brinda Perl+CPAN y en menos de 5 minutos ya tenía la solución al problema planteado, el tiempo restante me sirvió para comerme un pedazo de torta que me dió mi hermana, quien estuvo de cumpleaños el día de ayer.
En primer lugar, debemos instalar el módulo String::MkPasswd, el cual nos permitirá generar contraseñas de manera aleatoria. Si usted disfruta de una distribución decente como DebianRecuerde, Debian es inexorable la instalación del módulo es realmente trivial.
# aptitude install libstring-mkpasswd-perl
Además, si usted se detiene unos segundos y lee la documentación del módulo String::MkPasswd Este modulo en particular no solo se encuentra perfectamente integrado con nuestra distribución favorita, sino que además sus dependencias están resueltas. Esto es una simple muestra del poderío que ofrece una distribución como Debian., se dará cuenta que la función mkpasswd() toma un hash de argumentos opcionales. Si no le pasa ningún argumento a esta función estará generando constraseñas aleatorias con las siguientes características:
- La longitud de la contraseña será de 9.
- El número mínimo de dígitos será de 2.
- El número mínimo de caracteres en minúsculas será de 2.
- El número mínimo de caracteres en mayúsculas será de 2.
- El número mínimo de caracteres no alfanuméricos será de 1.
- Los caracteres no serán distribuidos entre los lados izquierdo y derecho del teclado.
Ahora bien, asumiendo que el fichero de entrada es users.data, la tarea con Perl es resumida en una línea de la siguiente manera.
perl -MString::MkPasswd=mkpasswd -nli -e 'print $_, " ", mkpasswd()' users.data
La línea anterior hace uso de la función mkpasswd del módulo String::MkPasswd para generar las contraseñas aleatorias para cada uno de los usuarios que se encuentran en el fichero de entrada users.data, además, la opción -iPara mayor información acerca de las distintas opciones usadas se le sugiere referirse a man perlrun permite editar el fichero de entrada in situ, ahora bien, quizá para algunos paranoicos (me incluyo) no sea suficiente todo esto, así que vamos a generar contraseñas aleatorias aún más complicadas.
#!/usr/bin/perl -li
use strict;
use warnings;
use String::MkPasswd qw(mkpasswd);
while(<>){
chomp;
print $_, " ", mkpasswd(
-length => 16,
-minnum => 5,
-minlower => 5,
-minupper => 3,
-minspecial => 3,
-distribute => 1
);
}En esta ocasión el la función mkpasswd() generará claves aún más complejas, dichas claves cumplirán con las siguientes condiciones.
-
-length: La longitud total de la contraseña, 16 en este caso. -
-minnum: El número mínimo de digitos. 5 en este caso. -
-minlower: El número mínimo de caracteres en minúsculas, en este caso 5. -
-minupper: El número mínimo de caracterés en mayúsculas, en este caso 3. -
-minspecial: El número mínimo de caracteres no alfanuméricos, en este caso será de 3. -
-distribute: Los caracteres de la contraseña serán distribuidos entre el lado izquierdo y derecho del teclado, esto hace más díficil que un fisgón vea la contraseña que uno está escribiendo. El valor predeterminado es falso, en este caso el valor es verdadero.
El script mostrado anteriormente lo podemos reducir a una línea, aunque preferí guardarlo en un fichero al que denomine genpasswd.pl por cuestiones de legibilidad.
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
feedjack
FeedJack: Ya está disponible
Ya había comentado acerca de ésta aplicación en la entrada FeedJack: Un Planet con esteroides, resulta que hace pocos días Gustavo Picón anunció la salida de la versión 0.9.6 bajo licencia BSD. Algunas de las características más resaltantes de esta aplicación son:
- Soporte de virtual hosts: Esto quiere decir que desde la misma instalación y la misma Base de Datos e interfaz de administración, se manejan múltiples planetas. Si hay feeds en común estos se bajan una sola vez para optimizar recursos.
- Temas (Themes): Cada sitio (virtual host) puede tener temas distintos.
- Soporte de folcsonomías (etiquetas o tags): Muy popular en las aplicaciones de la Web 2.0, se ha optimizado el algoritmo.
- Generación de páginas o feeds por folcsonomías: http://www.chichaplanet.org/tag/django/
- Generación de páginas o feeds por miembros: http://www.chichaplanet.org/user/1/
- Generación de páginas o feeds de una categoría en especial de un miembro particular: http://www.chichaplanet.org/user/1/tag/django/
- Generar un feed general: http://www.chichaplanet.org/feed/
- Histórico de entradas: Entre muchas otras cosas. La principal ventaja frente a Planet es el soporte de un histórico de entradas o posts, por el uso de una Base de Datos.
Para conocer los detalles acerca de los requerimientos, el proceso de instalación, configuración y la modificación de los temas lea con detenimiento la entrada Feedjack - A Django+Python Powered Feed Aggregator (Planet).
FeedJack: Un Planet con esteroides
FeedJack es una mejora hecha por Gustavo Picon (a.k.a. tabo) del muy conocido Planet, la mejor muestra de la funcionalidad de este software se puede apreciar en el planeta peruano ChichaPlanet.
Gustavo Picon, autor del reemplazo del Planet en Django, afirma que el código fuente todavía no está disponible, pero piensa hacerlo público bajo el esquema de código abierto tan pronto logre depurarlo un poco y redacte cierta documentación, coincido con el autor cuando éste afirma que: si un software no posee documentación, no existe.
FeedJack ofrece algunas características que le dan cierta ventaja sobre el Planet, algunas de ellas son:
- Maneja datos históricos. Por lo tanto, usted puede leer entradas antiguas.
- Realiza un análisis más exhaustivo de las entradas, incluyendo sus categorías.
- Es capaz de generar páginas de acuerdo a las categorías de las entradas.
- Brinda soporte al sistema de folcsonomías (etiquetas), opción muy popular en la Web 2.0.
- Utiliza el lenguaje de plantillas de Django
Mayor información y detalle en la entrada Django powered chicha planet with feedjack, de Gustavo Picon.
gnome
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
Restaurando la vieja barra de localización en nautilus
Si usted al igual que yo no le gusta la nueva manera en que se presenta la barra de localización en nautilus bajo Breezy, en donde se emplean las barras de rutas, es posible regresar a la vieja configuración (tal cual como en Hoary) en donde se especificaba de manera textual la ruta actual en la barra de localización.
Si ud. quiere cambiar este comportamiento, es tan sencillo como dirijirse a /apps/nautilus/preferences/ y proceder a marcar la casilla de verificación always_use_location_entry.
Lo anterior lo puede hacer desde el Editor de configuración, el cual lo puede encontrar en Aplicaciones -> Herramientas del Sistema.
gnu
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
Planeta Linux
Hace tiempo que no revisaba algunas de las estadísticas del sitio, me he percatado que han llegado algunos enlaces desde Planeta Linux Venezuela. El principal objetivo de este sitio es:
Planeta Linux es un pequeño proyecto que pretende fomentar la comunicación e intercambio sencillo de información sobre cualquier usuario de GNU/Linux o software libre, en Venezuela. Con esta breve comunicación, podremos conformar una comunidad mucho má sólida, unificada e integral.
Lo anterior también es extensible para aquellas personas mexicanas, puesto que existe un Planeta Linux México.
¿Desea colaborar con el proyecto?
El proceso de registro es muy sencillo, solamente debes enviar un correo a lista de correos [email protected], si desea suscribirse a dicha lista solamente rellene los datos solicitados página de información de la lista de correos de Planeta Linux.
Para su admision usted debe suministrar los siguientes datos:
- Nombre completo
- Lugar de residencia
- URI del feed RSS/Atom
Opcionalmente puede enviar su Hackergotchi, imagen de un escritor que es utilizada como ícono para identificar al autor de un feed dado dentro de un agregador de blogs, ésta no debe exceder un ancho de 95 pixels y un alto de 95 pixels.
Conociendo un poco más acerca del proyecto
Me ha interesado mucho esta iniciativa, así que no dude en ponerme en contacto con David Moreno Garza (a.k.a. damog), él cual me ha contestado muy amablemente. En las siguientes líneas expongo nuestro intercambio de correos electrónicos.
- MilMazz: Hola David, en realidad no tengo el placer de conocerte personalmente, pero he notado recientemente algunos enlaces entrantes desde el Planeta Linux Venezuela, no se quien me dio de alta, se agradece, así que gracias.
- Damog: Hola Milton, no, al parecer no nos conocemos. Yo te di de alta en el rol debido a que José Parrella, a.k.a bureado, me pasó tu nombre y feed.
- MilMazz: El motivo de este mensaje es para pedirte un poco de informacion respecto al proyecto, para publicar un artículo en mi blog y así colaborar con la difusión de esta interesante idea.
- Damog: ¡Muchas gracias! Así es como el proyecto va ganando adeptos y más gente se va uniendo y leyendo el contenido de Planeta Linux.
- MilMazz: Espero no te molesten las siguientes preguntas, tomalo a manera de entrevista :)
- Damog: Desde luego que no, ¡bienvenidas! Antes que cualquier cosa, espero que no te importe que reenvíe este correo a la lista de Planeta Linux.
- MilMazz: ¿Quién o quienes se plantearon en principio la idea de crear Planeta Linux?, ¿quién lo llevaron a cabo?
- Damog: Debido al boom que han tenido los blogs entre usuarios y desarrolladores de software libre en el mundo, se ve la necesidad de crear nuevas herramientas para «monitorear» los contenidos dependiendo de los gustos de cada uno de los usuarios. Wieland Kublun, un mexicano radicado en Guadalajara, en el estado de Jalisco, en el occidente de México, alguna vez me comentó que estaría bien tener una especie de «planeta», como los que se han dado a conocer por proyectos grandes como Planet Debian o Planet GNOME. Creí que la idea era estupenda y empezamos a poner el agregador en marcha y añadiendo a nuestros conocidos al rol.
Otro factor que ha influído mucho en la gran proliferación de Planeta Linux es Jaws. Jaws es un proyecto, iniciado por Jonathan Hernández, radicado en Chihuahua, en el norte de México, de software libre para construir fácilmente un blog. El proyecto Jaws ha avanzado ya muchísimo, pues el software desarollado es altamente útil, funcional y bastante bonito. Por ende, muchos usuarios mexicanos empezaron a montar sus blogs en él y la mancha de usuarios blogueadores mexicanos creció mucho.
- MilMazz: Tengo entendido que el primer planeta de la “serie” fue el Planeta Linux Mexico, ¿desde cuando está en línea?
- Damog: Así es, fue el primero. Ha estado en línea desde octubre de 2004. Antes utilizábamos el dominio planetalinux.com.mx, pero recientemente abrimos el 2006 con el dominio, más genérico y permitible de expansión, planetalinux.org.
- MilMazz: ¿Por qué decidiste incluir a Venezuela como parte del Planeta Linux?, ¿alguna persona te pidio que lo hicieras?
- Damog: No. Personalmente tengo mucha relación con Venezuela, pues mi novia es de allá y tengo bastantes amigos, en el mundillo del software libre, allá. Quise lanzarlo por que empecé a conocer a gente que tenía un blog y llegó a un punto donde consideré pertinente lanzarlo, y donde la gente se interesaría por él. Mucha gente, hasta donde tengo entendido, ni siquiera sabe que está en el planeta. Como tú mismo, a muchas personas se han agregado teniendo conocimientos de ellos por terceras partes. Sin embargo, la forma de ver crecer un proyectito así es precisamente de boca en boca, de blog en blog.
- MilMazz: ¿Tienes pensado en el futuro incluir a mas paises?, si es así, ¿cuáles serían?
- Damog: Sí, la idea también era esa al iniciar con el dominio que usamos actualmente. Al principio creí que lo ideal sería empezar con México y Venezuela por razones ya explicadas, y además con Estados Unidos (sindicando a la gente latina que radica en ese país y que bloguea), usando la dirección us.planetalinux.org. Sin embargo, aún no se ha juntado suficiente gente para llevar a cabo tal subproyecto. En general cualquier país latinoamericano podría entrar mientras se junte suficiente gente y vaya creciendo como han ido creciendo los correspondientes a México y Venezuela. Creo que sería interesante seguirse luego con Brasil, donde hay una enorme actividad de software libre, o incluso en Argentina. Sin embargo, esto depende de la gente: Hace falta todavía escribir mucho contenido, hace falta escribir una especie de FAQ donde se explique qué pueden hacer si alguien quiere iniciar una instancia de Planeta Linux en un país donde no exista, hace falta hacer ese tipo de cosas y generar esos contenidos.
- MilMazz: Estaba por documentarme acerca de los lineamientos, al parecer el enlace de los lineamientos de Planeta Linux está roto por ahora, ¿cuáles serían los lineamientos que debe seguir un miembro del Planeta Linux?
- Damog: Bueno, como te digo, uno más de los contenidos inconclusos. Básicamente, los lineamientos establecerán algunos reglas o consejos, como que deberán hablar de Linux y Software Libre con cierta regularidad en su blog, que su feed debe ser válido, etc. Ese tipo de cosas.
- MilMazz: ¿Quienes pueden participar en el Planeta Linux?
- Damog: Cualquier persona que lleve un blog y toque periódicamente temas sobre Linux o Software Libre.
- MilMazz: ¿Deseas agregar algo más?
- Damog: Pues si alguien se quiere unir, es más que bienvenido. Simplemente escriban a la lista: [email protected] o suscríbanse.
Antes de culminar, quisiera agradecerle públicamente a José Parella por la sugerencia hecha a David Moreno Garza.
java
Instalando dependencias no-libres de JAVA en ambientes pbuilder
El día de hoy asumí la construcción de unos paquetes internos compatibles con
Debian 5.0 (a.k.a. Lenny) que anteriormente eran responsabilidad de
ex-compañeros de labores. El paquete en cuestión posee una dependencia
no-libre, sun-java6-jre. En este artículo se describirá como lograr
adecuar su configuración de pbuilder para la correcta construcción del
paquete.
Asumiendo que tiene un configuración similar a la siguiente:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
Para mayor información sobre estas opciones sírvase leer:
$ man 5 pbuilderrc
Mientras intenta compilar su paquete en el ambiente proporcionado por pbuilder
el proceso fallará ya que no se mostró la ventana para aceptar la licencia de
JAVA. Podrá observar en el registro de la construcción del build un mensaje
similar al siguiente:
Unpacking sun-java6-jre (from .../sun-java6-jre_6-20-0lenny1_all.deb) ...
sun-dlj-v1-1 license could not be presented
try 'dpkg-reconfigure debconf' to select a frontend other than noninteractive
dpkg: error processing /var/cache/apt/archives/sun-java6-jre_6-20-0lenny1_all.deb (--unpack):
subprocess pre-installation script returned error exit status 2
Para evitar esto altere la configuración del fichero pbuilderrc de la
siguiente manera:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
export DEBIAN_FRONTEND="readline"
Una vez alterada la configuración podrá interactuar con las opciones que le
ofrece debconf.
Ahora bien, si usted constantemente tiene que construir paquetes con dependencias no-libres como las de JAVA, es probable que le interese lo que se menciona a continuación.
Si lee detenidamente la página del manual de pbuilder en su sección 8 podrá
encontrar lo siguiente:
$ man 8 pbuilder
...
--save-after-login
--save-after-exec
Save the chroot image after exiting from the chroot instead of deleting changes. Effective for login and execute session.
...
Por lo tanto, usaremos esta funcionalidad que ofrece pbuilder para insertar
valores por omisión en la base de datos de debconf para que no se nos pregunte
si deseamos aceptar la licencia de JAVA:
# pbuilder login --save-after-login
I: Building the build Environment
I: extracting base tarball [/var/cache/pbuilder/base.tgz]
I: creating local configuration
I: copying local configuration
I: mounting /proc filesystem
I: mounting /dev/pts filesystem
I: Mounting /var/cache/pbuilder/ccache
I: policy-rc.d already exists
I: Obtaining the cached apt archive contents
I: entering the shell
File extracted to: /var/cache/pbuilder/build//27657
pbuilder:/# cat > java-license << EOF
> sun-java6-bin shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jdk shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jre shared/accepted-sun-dlj-v1-1 boolean true
> EOF
pbuilder:/# debconf-set-selections < java-license
pbuilder:/# exit
logout
I: Copying back the cached apt archive contents
I: Saving the results, modifications to this session will persist
I: unmounting /var/cache/pbuilder/ccache filesystem
I: unmounting dev/pts filesystem
I: unmounting proc filesystem
I: creating base tarball [/var/cache/pbuilder/base.tgz]
I: cleaning the build env
I: removing directory /var/cache/pbuilder/build//27657 and its subdirectories
Cómo cambiar entre versiones de JAVA bajo Breezy
Si usted tiene instaladas múltiples versiones de JAVA bajo Breezy, puede cambiar fácilmente entre dichas versiones cuando usted lo desee.
Simplemente debe hacer uso del comando update-alternatives --config java y luego podrá escoger su versión de java preferida.
$ sudo update-alternatives --config java
There are 3 alternatives which provide `java'.
Selection Alternative
-----------------------------------------------
1 /usr/bin/gij-wrapper-4.0
+ 2 /usr/lib/jvm/java-gcj/bin/java
* 3 /usr/lib/j2re1.5-sun/bin/java
Press enter to keep the default[*], or type selection number:
Si usted es amante de las soluciones gráficas, no se preocupe, existe una alternativa, con galternatives podrá elegir qué programa le prestará un servicio en particular, para instalar galternatives debe teclear el siguiente comando:
$ sudo aptitude install galternatives
Para ejecutarlo debe hacer lo siguiente:
$ sudo galternatives
Su interfaz de uso es muy sencilla, si desea cambiar la versión de JAVA que desea utilizar simplemente escoga java en la sección de alternativas, seguidamente seleccione la versión que más crea conveniente en la sección de opciones
jquery
The DRY principle
The DRY (Don’t Repeat Yourself) principle it basically consist in the following:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
That said, it’s almost clear that the DRY principle is against the code duplication, something that in the long-term affect the maintenance phase, it doesn’t facilitate the improvement or code refactoring and, in some cases, it can generate some contradictions, among other problems.
jQuery best practices
After some time working with C programming language in a *NIX like operating system, recently I came back again to Web Programming, mostly working with HTML, CSS and JavaScript in the client-side and other technologies in the backend area.
The current project I’ve been working on, heavily relies on jQuery and Highcharts/Highstock libraries, I must confess that at the beginning of the project my skills in the client-side were more than rusted, so, I began reading a lot of articles about new techniques and good practices to catch up very quickly, in the meantime, I start taking some notes about “best practices”1 that promotes a better use of jQuery2
layout
Lavado de cara para Planeta Linux
Desde las 2:00 p.m. (hora local) del día de hoy, con la asistencia del compañero Damog, hemos ido actualizando el layout de Planeta Linux, aún falta mucho trabajo por hacer, pero al menos ya hemos dado los primeros pasos.
Cualquier opinión, crítica, sugerencia, comentario agradecemos enviar un correo electrónico a la lista de correos de Planeta Linux. *[p.m.]: Post meridiem
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
pylint
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
Pylint: Análisis estático del código en Python
Básicamente el análisis estático del código se refiere al proceso de evaluación del código fuente sin ejecutarlo, es en base a este análisis que se obtendrá información que nos permita mejorar la línea base de nuestro proyecto, sin alterar la semántica original de la aplicación.
Pylint es una herramienta que todo programador en Python debe considerar en su proceso de integración continua (Ej. Bitten), básicamente su misión es analizar código en Python en busca de errores o síntomas de mala calidad en el código fuente. Cabe destacar que por omisión, la guía de estilo a la que se trata de apegar Pylint es la descrita en el PEP-8.
Es importante resaltar que Pylint no sustituye las labores de revisión continua de alto nivel en el Proyecto, con esto quiero decir, su estructura, arquitectura, comunicación con elementos externos como bibliotecas, diseño, entre otros.
Tome en cuenta que Pylint puede arrojar falsos positivos, esto puede entenderse al recibir una alerta por parte de Pylint de alguna cuestión que usted realizó conscientemente. Ciertamente algunas de las advertencias encontradas por Pylint pueden ser peligrosas en algunos contextos, pero puede que en otros no lo sea, o simplemente Pylint haga revisiones de cosas que a usted realmente no le importan. Puede ajustar la configuración de Pylint para no ser informado acerca de ciertos tipos de advertencias o errores.
Entre la serie de revisiones que hace Pylint al código fuente se encuentran las siguientes:
- Revisiones básicas:
- Presencia de cadenas de documentación (docstring).
- Nombres de módulos, clases, funciones, métodos, argumentos, variables.
- Número de argumentos, variables locales, retornos y sentencias en funciones y métodos.
- Atributos requeridos para módulos.
- Valores por omisión no recomendados como argumentos.
- Redefinición de funciones, métodos, clases.
- Uso de declaraciones globales.
- Revisión de variables:
- Determina si una variable o
importno está siendo usado. - Variables indefinidas.
- Redefinición de variables proveniente de módulos builtins o de ámbito externo.
- Uso de una variable antes de asignación de valor.
- Determina si una variable o
- Revisión de clases:
- Métodos sin
selfcomo primer argumento. - Acceso único a miembros existentes vía
self - Atributos no definidos en el método
__init__ - Código inalcanzable.
- Métodos sin
- Revisión de diseño:
- Número de métodos, atributos, variables locales, entre otros.
- Tamaño, complejidad de funciones, métodos, entre otros.
- Revisión de imports:
- Dependencias externas.
-
imports relativos o importe de todos los métodos, variables vía
*(wildcard). - Uso de imports cíclicos.
- Uso de módulos obsoletos.
- Conflictos entre viejo/nuevo estilo:
- Uso de
property,__slots__,super. - Uso de
super.
- Uso de
- Revisiones de formato:
- Construcciones no autorizadas.
- Sangrado estricto del código.
- Longitud de la línea.
- Uso de
<>en vez de!=.
- Otras revisiones:
- Notas de alerta en el código como
FIXME,XXX. - Código fuente con caracteres non-ASCII sin tener una declaración de encoding. PEP-263
- Búsqueda por similitudes o duplicación en el código fuente.
- Revisión de excepciones.
- Revisiones de tipo haciendo uso de inferencia de tipos.
- Notas de alerta en el código como
Mientras Pylint hace el análisis estático del código muestra una serie de mensajes así como también algunas estadísticas acerca del número de advertencias y errores encontrados en los diferentes ficheros. Estos mensajes son clasificados bajo ciertas categorías, entre las cuales se encuentran:
- Refactorización: Asociado a una violación en alguna buena práctica.
- Convención: Asociada a una violación al estándar de codificación.
- Advertencia: Asociadas a problemas de estilo o errores de programación menores.
- Error: Asociados a errores de programación importantes, es probable que se trate de un bug.
- Fatal: Asociados a errores que no permiten a Pylint avanzar en su análisis.
Un ejemplo de este reporte lo puede ver a continuación:
Messages by category
--------------------
+-----------+-------+---------+-----------+
|type |number |previous |difference |
+===========+=======+=========+===========+
|convention |969 |1721 |-752.00 |
+-----------+-------+---------+-----------+
|refactor |267 |182 |+85.00 |
+-----------+-------+---------+-----------+
|warning |763 |826 |-63.00 |
+-----------+-------+---------+-----------+
|error |78 |291 |-213.00 |
+-----------+-------+---------+-----------+
Cabe resaltar que el formato de salida del ejemplo utilizado está en modo texto, usted puede elegir entre: coloreado, texto, msvs (Visual Estudio) y HTML.
Pylint le ofrece una sección dedicada a los reportes, esta se encuentra inmediatamente después de la sección de mensajes de análisis, cada uno de estos reportes se enfocan en un aspecto particular del proyecto, como el número de mensajes por categorías (mostrado arriba), dependencias internas y externas de los módulos, número de módulos procesados, el porcentaje de errores y advertencias encontradas por módulo, el total de errores y advertencias encontradas, el porcentaje de clases, funciones y módulos con docstrings y su respectiva comparación con un análisis previo (si existe). El porcentaje de clases, funciones y módulos con nombres correctos (de acuerdo al estándar de codificación), entre otros.
Al final del reporte arrojado por Pylint podrá observar una puntuación general por su código, basado en el número y la severidad de los errores y advertencias encontradas a lo largo del código fuente. Estos resultados suelen motivar a los desarrolladores a mejorar cada día más la calidad de su código fuente.
Si usted ejecuta Pylint varias veces sobre el mismo código, podrá ver el puntaje de la corrida previa junto al resultado de la corrida actual, de esta manera puede saber si ha mejorado la calidad de su código o no.
Global evaluation
-----------------
Your code has been rated at 7.74/10 (previous run: 4.64/10)
If you commit now, people should not be making nasty comments about you on c.l.py
Una de las grandes ventajas de Pylint es que es totalmente configurable, además, se pueden escribir complementos o plugins para agregar una funcionalidad que nos pueda ser útil.
Si usted quiere probar desde ya Pylint le recomiendo seguir la guía introductoria descrita en Pylint tutorial. Si desea una mayor ayuda respecto a los códigos indicados por Pylint, puede intentar el comando pylint --help-msg=CODIGO, si eso no es suficiente, le recomiendo visitar el wiki PyLint Messages para obtener una rápida referencia de los mensajes arrojados por Pylint, organizados de varias maneras para hacer más fácil y agradable la búsqueda. Además de encontrar explicaciones de cada mensaje, especialmente útiles para aquellos programadores que recién comienzan en Python.
Referencias
tips
subversion: Recuperar cambios y eliminaciones hechas
Muchos compañeros de trabajo y amigos en general que recién comienzan con el manejo de sistemas de control de versiones centralizados, en particular subversion, regularmente tienen inquietudes en cuanto al proceso de recuperación de cambios una vez que han sido enviados al repositorio, así como también la recuperación de ficheros y directorios que fueron eliminados en el pasado. Trataré de explicar algunos casos en base a ejemplos para que se tenga una idea más clara del problema y su respectiva solución.
En el primero de los casos se tiene recuperar la revisión previa a la actual, suponga que usted mantiene un repositorio de recetas, una de ellas en particular es la ensalada caprese, por error o descuido añadió el ingrediente Mostaza tipo Dijón a la lista, si usted posee siquiera un lazo con italinos sabe que está cometiendo un error que puede devenir en escarnio público, desprecio e insultos.
~/svn/wc/trunk$ svn diff -r 2:3 ${URL}/trunk/caprese
Index: caprese
===================================================================
--- caprese (revision 2)
+++ caprese (revision 3)
@@ -7,3 +7,4 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
+ - Mostaza tipo Dijon
Note que el comando anterior muestra las diferencias entre las revisiones 2 y 3 del repositorio, en el resumen se puede apreciar que en la revisión 3 ocurrió el error. Un modo rápido de recuperarlo es como sigue.
~/svn/wc/trunk$ svn merge -c -3 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
En este caso particular se están aplicando las diferencias entre las revisiones consecutivas a la copia de trabajo. Es hora de verificar que los cambios hechos sean los deseados:
~/svn/wc/trunk$ svn status
M caprese
~/svn/wc/trunk$ svn diff
Index: caprese
===================================================================
--- caprese (revision 3)
+++ caprese (working copy)
@@ -7,4 +7,3 @@
- Albahaca fresca
- Aceite de oliva
- Pimienta
- - Mostaza tipo Dijon
Una vez verificado enviamos los cambios hechos al repositorio a través de comando svn commit.
Seguramente usted se estará preguntando ahora que sucede si las revisiones del ficheros no son consecutivas como en el caso mostrado previamente. En este caso es importante hacer notar que la opción -c 3 es equivalente a -r 2:3 al usar el comando svn merge, en nuestro caso particular -c -3 es equivalente a -r 3:2 (a esto se conoce como una fusión reversa), substituyendo la opción -c (o --changes) en el caso previo obtenemos lo siguiente:
~/svn-tests/wc/trunk$ svn merge -r 3:2 ${URL}/trunk/caprese
--- Reverse-merging r3 into 'caprese':
U caprese
Referencias: svn help merge, svn help diff, svn help status.
Recuperando ficheros o directorios eliminados
Una manera bastante sencilla de recuperar ficheros o directorios eliminados es haciendo uso de comando svn cp o svn copy, una vez determinada la revisión del fichero o directorio que desea recuperar la tarea es realmente sencilla:
~/svn-tests/wc/trunk$ svn cp ${URL}/trunk/panzanella@6 panzanella
A panzanella
En este caso se ha duplicado la revisión 6 del fichero panzanella en la copia de trabajo local, se ha programado para su adición incluyendo su historial, esto último puede verificarse en detalle al observar el signo ’+’ en la cuarta columna del comando svn status.
~/svn-tests/wc/trunk$ svn status
A + panzanella
Referencias: svn help copy, svn help status.
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
xmms
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
Reproducir de manera automática los CDs o DVDs con XMMS y VLC
Si desea reproducir automáticamente los CDs de audio (o DVDs) al ser insertados con XMMS (o con VLC) simplemente cumpla los siguientes pasos:
En primer lugar diríjase a Sistema -> Preferencias -> Unidades y soportes extraíbles, desde la lengüeta Multimedia proceda de la siguiente manera:
Si desea reproducir automáticamente un CD de sonido al insertarlo:
- Marque la casilla de verificación Reproducir CD de sonido al insertarlo
- En la sección de comando escriba lo siguiente:
xmms -p /media/cdrom0
Si desea reproducir automáticamente un DVD de vídeo al insertarlo
- Marque la casilla de verificación Reproducir DVD de vídeo al insertarlo
- En la sección de comando escriba lo siguiente:
wxvlc dvd:///dev/dvd
Nota: En XMMS puede ser necesario configurar el plugin de entrada de audio que se refiere al Reproductor de CD de audio (libcdaudio.so), puede configurarlo desde las preferencias del programa.
Duke
WordPress 2.0
Anoche comencé a realizar algunos cambios a este blog, entre ellos, actualizar la plataforma de publicación que lo gestiona, WordPress. He pasado de la versión 1.5.2 a la 2.0 (nombre clave Duke, en honor al pianista y compositor de Jazz Duke Ellington), estoy muy contento con el cambio puesto que el área administrativa ha sufrido muchos cambios para bien.
Por supuesto, aún faltán muchos detalles por arreglar, en el transcurso de la semana iré traduciendo el tema que posee actualmente la bitácora y algunos plugins que recien comienzo a utilizarlos.
El anuncio de la nueva versión, así como las características que incluye esta nueva versión de WordPress, puede encontrarlas en la entrada WordPress 2, publicada por Matt.
En verdad fué muy fácil la actualización, a mi me tomo solo unos cuantos minutos siguiendo la guía del Codex de WordPress, pero si prefieres una guía en castellano y muy completa te recomiendo leer el artículo Actualización de WordPress de 1.5.x a 2.0.
Enlightenment
COMO instalar e17 desde los repositorios de shadoi en Breezy
Nota: Antes que nada es importante resaltar que E17 está todavía en desarrollo. Si desea intentar utilizar E17, sepa que este software es todavía un versión pre-alfa, que aún esta en constante desarrollo y por tanto su uso puede implicar algunos riesgos.
Enlightenment DR17 combina características presentes en los manejadores de ventanas como en los manejadores de ficheros. Provee una interfaz gráfica de usuario que le permitirá manejar los elementos del escritorio, al igual que ficheros y ventanas. El entorno gráfico de Enlightenment es realmente impresionante, es muy agradable para el usuario, también es muy configurable.
Después de una breve introducción, vamos a entrar en acción.
Hace ya algunos días atrás shadoi anunciaba lo siguiente:
Once that new server is in place and all the sites have been moved over, I’ll be quickly adding support for more Debian architectures, distributions and derivatives like Ubuntu.
Posteriormente shadoi (aka Blake Barnett) confirma la noticia.
Ahora para instalar E17 solo necesitará de 4 pasos. La información que será mostrada a continuación es tomada del wiki de shadoi.
Paso #1
Agregar la siguiente línea al fichero /etc/apt/sources.list:
deb http://soulmachine.net/breezy/ unstable/
También debe agregar lo siguiente al fichero /etc/apt/preferences (si no
existe dicho fichero proceda a crearlo).
Package: enlightenment
Pin: version 0.16.999*
Pin-Priority: 999
Package: enlightenment-data
Pin: version 0.16.999*
Pin-Priority: 999
Paso #2
Instalar la clave pública del repositorio, para ello desde la consola escriba lo siguiente:
$ wget soulmachine.net/public.key
$ sudo apt-key add public.key
Paso #3
Actualice la lista de paquetes disponibles, para ello desde la consola escriba lo siguiente:
$ sudo aptitude update
Paso #4
Instale enligtenment, para ello desde la consola escriba lo siguiente:
$ sudo aptitude install <ins datetime="2005-12-10T05:54:58+00:00">enlightenment=0.16.999.018-1 enlightenment-data</ins>
Notas
Aunque shadoi ha anunciado que el paquete de evidence (gestor de ficheros especialmente desarrollado para ser usado con enlightenment) pronto lo tendrá listo, por ahora puede hacer uso de esta versión, después de finalizada la descarga debe escribir en consola lo siguiente:
$ sudo dpkg -i evidence_0.9.8-20050305-hoaryGMW_i386.deb
El paquete que se ha instalado previamente aunque fue construido en principio para la versión de Ubuntu Hoary, funciona en Breezy. Para la versión reciente de Ubuntu aún no está construido este paquete en particular.
También es importante resaltar que E17 brinda soporte al castellano.
Humor
Maestro, es Windows XP un virus?
Ps:
Háblame, estoy atento a tus palabras, mi Maestro.
M:
Los virus se reproducen rápidamente por todo el planeta.
Ps:
Bueno, windows XP hace eso.
M:
Los virus consumen varios recursos del sistema, ralentizándolo.
PS:
Bueno, windows XP también hace eso.
M:
Los virus de vez en cuando arruinan tu disco duro.
Ps:
Oopss!! pues windows XP también lo hace!
M:
Normalmente los virus se trasmiten, de forma que el usuario no lo sepa, junto con valiosos programas y sistemas.
PS:
Por los dioses del cielo!!...Windows XP hace eso también!!!
M:
Ocasionalmente los virus harán creer al usuario que su sistema es demasiado lento y el infeliz comprará hardware nuevo.
PS:
Cielos, maestro!!! eso también va con windows XP.
M:
Mira pequeño saltamontes, hasta ahora parece que windows XP es un virus, pero hay diferencias fundamentales: Los virus están bien soportados por sus autores, funcionan en la mayoría de los sistemas, su código es rápido, compacto y eficiente, y tienden a sofisticarse más y más a medida que maduran.
Ps:
Ahhhhh, entonces windows XP no es un virus.
M:
No pequeño saltamontes, no es un virus. Es un [bug!](http://es.wikipedia.org/wiki/Error_de_software).
Vía: Seguridad0.info
Kubuntu
Versión Previa a Kubuntu Breezy
Una vez hecho el anuncio de la versión previa a Ubuntu 5.10 (Breezy Badger), era de esperarse otro anuncio por parte del proyecto relacionado Kubuntu.
¿Qué hay de nuevo en esta versión?
-
KDE 3.4.2
-
OpenOffice 2 (Beta 2)
-
X.org 6.8.2
Se incluyen otras características tentadoras, como por ejemplo editores de imágenes, una mejora en la usabilidad para el manejo de las preferencias del sistema, entre otras.
Al igual que Ubuntu, la versión previa a la salida oficial de Kubuntu Breezy está disponible tanto en CD instalable como en en LiveCD para tres arquitecturas: x86 (PC), AMD64 (PC 64 bits) y PowerPC (Mac).
Puede descargar la imagen de esta versión en Kubuntu 5.10 (Breezy Badger) Preview. Recuerde usar en la medida de lo posible BitTorrent, para evitar la sobrecarga del servidor.
Si lo desea, puede ver el anuncio de esta versión previa.
Opinión
Goobuntu, Google y los rumores…
Todo comenzo el día martes de esta misma semana, al ser publicado el artículo Google at work on desktop Linux en The Register, para mí todo aquello tenía la esencia de un nuevo rumor acerca Google, no en el sentido de utilizar una adaptación, denominada Goobuntu, de Ubuntu para las personas que laboran dentro de Google, sino en el hecho que el artículo enfatizaba la posibilidad de distribuir al público en general la adaptación de Ubuntu hecha por Google.
En el artículo mencionado al comienzo del párrafo anterior nos encontramos con afirmaciones tales como las siguientes:
Google is preparing its own distribution of Linux for the desktop, in a possible bid to take on Microsoft in its core business - desktop software.
Un poco más tarde nos encontramos con esto.
But it’s possible Google plans to distribute it to the general public, as a free alternative to Windows.
La posible distribución de “Goobuntu” al público fue desmentida pocas horas después de publicada la noticia, el responsable de proyectos open source de Google, Chris DiBona, lo aclara en este comentario hecho en Slashdot [Vía], en donde afirma lo siguiente:
Goobuntu is our internal desktop distribution. It’s awesome, but we’re not going to be releasing it. Unless you work here it wouldn’t work anyway.
Una de las cosas que me impresionó de todo esto, fué lo rápido que se extendió esta noticia. Estaba por todos lados, en los blogs que comúnmente leo, en Technorati, bajo el tag ubuntu, solo se hablaba de ello. Más y más sitios se unían rápidamente a este grupo.
Me da la impresión que cada vez que termina un rumor acerca del probable Google OS o Google Browser comienza uno nuevo, ¿esto acabará algún día?, ¿es sano adorar tanto a Google?, acaso Google es tan cool que le hace olvidar a las personas los malos productos que ha sacado últimamente, pareciese que sí.
Siguiendo con el tema, llegados a este punto, ¿alguien recuerda el lanzamiento de Google Analytics?, este servicio de estadísticas gratis para sitios web desde el mismo día de su lanzamiento no dejó de dar problemas, fué un total desastre, ¿era muy difícil prever que este servicio iba a tener una demanda excesiva?, no lo creo, su rendimiento daba lastima, los servidores estaban saturados, páginas en mantenimiento después del lanzamiento, ¿acaso Google estaba jugando con nosotros?.
Supongo que Google ha olvidado esa parte de la mercadotecnia en donde se logra satisfacer las necesidades y requisitos de los consumidores, al fin y al cabo es una empresa que intenta responder a una economía de mercado, pero lo está haciendo mal.
Google ha demostrado su interes en el escritorio, aplicaciones como Google Desktop Search, Google Talk, Google Earth, Google Pack dan fé de ello. No puedo dar mi opinión acerca de estas últimas aplicaciones, puesto que no los he probado al ser solo para sistemas Windows, pero con los antecedentes que se está ganando últimamente Google, pareciese que no hace falta probarlos para sacar una conclusión de ellos. Sebastian Delmont puede aclarar un poco esta situación en el artículo El paquete de Google decepciona.
Personal
Amigas se unen a la blogocosa
Así como lo indica el título de esta entrada, dos mujeres muy importantes en mi vida, se unen a la blogocosa, la primera, mi novia Ana Rangel, la segunda es mi querida amiga Gaby Márquez, ambas comparten conmigo estudios en la carrera de Ing. de Sistemas en la Universidad de Los Andes, espero que realmente inviertan tiempo a esta tarea. Estaré atento a sus artículos y trataré de darles ánimo.
Ana y Gaby, bienvenidas a la blogocosa.
alsa
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
amigas
Amigas se unen a la blogocosa
Así como lo indica el título de esta entrada, dos mujeres muy importantes en mi vida, se unen a la blogocosa, la primera, mi novia Ana Rangel, la segunda es mi querida amiga Gaby Márquez, ambas comparten conmigo estudios en la carrera de Ing. de Sistemas en la Universidad de Los Andes, espero que realmente inviertan tiempo a esta tarea. Estaré atento a sus artículos y trataré de darles ánimo.
Ana y Gaby, bienvenidas a la blogocosa.
apt-get
apt-get detrás de proxy con autenticación NTLM
Por motivos que no vienen al caso discutir en este artículo tuve que instalar Debian GNU/Linux detrás de un proxy que aún utiliza NTLM como medio de autenticación, aunque NTLM ya no es recomendado por Microsoft desde hace años en pro de usar Kerberos.
Una vez instalada la distribución quería utilizar apt-get para actualizarla e
instalar nuevos paquetes, el resultado fue que apt-get no funciona de manera
transparente detrás de un proxy con autenticación NTLM. La solución fue
colocar un proxy interno que esté atento a peticiones en un puerto particular
en el host, el proxy interno se encargará de proveer de manera correcta las
credenciales al proxy externo.
La solución descrita previamente resulta sencilla al utilizar cntlm. En
principio será necesario instalarlo vía dpkg, posteriormente deberá editar los
campos apropiados en el fichero /etc/cntlm.conf
- Username
- Domain
- Password
- Proxy
Seguidamente reinicie el servicio:
# /etc/init.d/cntlm restart
Ahora solo resta configurar apt-get para que utilice nuestro proxy interno,
para ello edite el fichero /etc/apt.conf.d/02proxy
Acquire::http::Proxy "http://127.0.0.1:3128";
NOTA: Se asume que el puerto de escucha de cntlm es el 3128.
Ahora puede hacer uso correcto de apt-get:
# apt-get update
# apt-get upgrade
...
NOTA FINAL: Es evidente que cualquier comando o herramienta que necesite
autenticarse contra el proxy externo deberá configurarlo para que utilice el
proxy interno, lo explicado en este artículo no solo aplica para el comando
apt-get.
audioconverter
audioconverter v0.3.1
El día de hoy me comentaba Fernando Arenas, quien me contacto vía correo electrónico, que se había percatado de un pequeño bug en el script audioconverter, específicamente cuando se realizaba la conversión del formato .wma a .mp3.
Para quienes utilizan el script, les recomiendo actualizar a la versión más reciente, audioconverter-v0.3.1. También pueden emplearlo todas esas personas que deseen probar el programa (al menos por curiosidad), cualquier comentario es bienvenido.
Espero poder traerles una nueva versión del script audioconverter en el mes de Enero, mejorando la interfaz e incluyendo algunas características que me han mencionado en el transcurso del desarrollo de la aplicación. Espero poder complacerles. De nuevo, cualquier sugerencia es bienvenida.
Referencias
azureus
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
bad-behavior
¡Maldito Spam!, nos invade
Según las estadísticas del plugin Akismet para el día de hoy, solamente 7.961 de 523.708 son comentarios, trackbacks o pingbacks válidos, mientras que el resto es Spam, eso quiere decir que aproximadamente el 1.5% es aceptable, el resto es escoria.
Seguramente alguno de mis 3 lectores en este instante se estará preguntando como funciona Akismet, en la sección de respuestas a preguntas frecuentes podrá resolver esta interrogante.
When a new comment, trackback, or pingback comes to your blog it is submitted to the Akismet web service which runs hundreds of tests on the comment and returns a thumbs up or thumbs down.
No sé que estara sucediendo con dichas pruebas últimamente, puesto que en los comentarios de mi blog han aparecido muchos trackbacks escoria. Ante el abrumador aumento (se puede observar que el aumento es prácticamente exponencial según las estadísticas proporcionadas en sitio oficial de Akismet) del spam, muchos han decidido cerrar sus comentarios, solo basta darse una vuelta por technorati bajo el tag spam y ver las acciones de algunos.
No puedo negar que el funcionamiento de Akismet en general es excelente, de hecho, antes de probar Akismet contaba con 2 ó más alternativas para combatir el spam, después de probarlo, no fue necesario mantener ningún otro plugin, pero creo que bajo esta situación es necesario comenzar a evaluar otras posibilidades que ayuden a Akismet.
Algunas de las cosas que podemos hacer bajo WordPress son las siguientes:
Mejorar nuestras listas de moderación o listas negras
En el área administrativa, bajo Opciones -> Discusión, sección Moderación de comentarios, colocar una lista de palabras claves que aparezcan en estos comentarios escoria. Algunos de ellos no tienen sentido, otros te felicitan por tu trabajo, por ejemplo: Good design, Nice site, todo ese conjunto de palabras clave deben incluirse, si le gusta ser radical incluya dichas palabras clave en la sección Lista negra de comentarios, tenga cuidado si decide elegir esta última opción.
Desactivar los trackbacks
En mi caso, Akismet ha fallado en la detección de trackbacks escoria, por lo tanto, si usted quiere ser realmente radical, puede cerrarlos.
Para desactivar las entradas futuras puede ir a Opciones -> Discusión, y desmarcar la casilla de verificación que dice Permitir notificaciones de enlace desde otros weblogs (pingbacks y trackbacks).
Ahora bien, a pesar de que la oleada de spam está atacando entradas recientes, podemos asegurarnos de cerrar los trackbacks para entradas anteriores ejecutando una sencilla consulta SQL:
UPDATE wp_posts SET ping_status = 'closed';
Moderar comentarios
Puede decidir si todos los comentarios realizados en su bitácora, deberán ser aprobados por el administrador, está acción quizá le evite que se muestren trackbacks escoria en su sitio, pero no le evitará la ardua tarea de eliminarlos uno por uno o masivamente. Si quiere establecer está opción puede hacerlo desde Opciones -> Discusión, en la sección de Para que un comentario aparezca deberá marcar la casilla de verificación Un administrador debe aprobar el comentario (independientemente de los valores de abajo)
Eliminar un rango considerable de comentarios escoria
Esta solución la encontre después de buscar la manera más sencilla de eliminar cientos de mensajes escoria desde una consulta en SQL.
En primer lugar debemos ejecutar la siguiente consulta:
SELECT * FROM wp_comments ORDER BY comment_ID DESC
En ella debemos observar el rango de comentarios recientes y que sean considerados spam. Por ejemplo, supongamos que los comentarios cuyos ID’s están entre los números 2053 y 2062 son considerados spam. Luego de haber anotado el rango de valores, debe proceder como sigue:
UPDATE wp_comments SET comment_approved = 'spam' WHERE comment_ID BETWEEN 2053 AND 2062
Recuerde sustituir apropiadamente los valores correspondientes al inicio y final de los comentarios a ser marcados como spam. Debe recordar también que los comentarios marcados como spam no desaparecerán de su base de datos, por lo tanto, estarán ocupando un espacio que puede llegar a ser considerable, le recomiendo borrarlos posteriormente.
Utilizar plugins compatibles con Akismet
En la sección de respuestas a preguntas frecuentes de Akismet podrán resolver esta interrogante.
We ask that you turn off all other spam plugins as they may reduce the effectiveness of Akismet. Besides, you shouldn’t need them anymore! :) But if you are investigating alternatives, we recommend checking out Bad Behavior and Spam Karma, both which integrate with Akismet nicely.
Ya había probado con anterioridad Bad Behavior, de hecho, lo tuve antes de probar Akismet y funcionaba excelente, ahora, falta probar como se comporta al combinarlo con Spam Karma 2. Las instrucciones de instalación y uso son sencillas.
Referencias:
beamer
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
beryl
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
blog
Amigas se unen a la blogocosa
Así como lo indica el título de esta entrada, dos mujeres muy importantes en mi vida, se unen a la blogocosa, la primera, mi novia Ana Rangel, la segunda es mi querida amiga Gaby Márquez, ambas comparten conmigo estudios en la carrera de Ing. de Sistemas en la Universidad de Los Andes, espero que realmente inviertan tiempo a esta tarea. Estaré atento a sus artículos y trataré de darles ánimo.
Ana y Gaby, bienvenidas a la blogocosa.
bluefish
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
books
Libro oficial de Ubuntu
La primera edición del libro The Official Ubuntu Book estará lista para el día 4 de Agosto de este mismo año y contará con 320 páginas; la información anterior puede encontrarse en la preventa del libro realizada en Amazon.
Los autores del libro The Official Ubuntu Book son los siguientes:
- Benjamin Mako Hill: Autor del famoso libro Debian GNU/Linux 3.x Bible, desarrollador debian/ubuntu.
- Jono Bacon: Co-autor del libro Linux Desktop Hacks, publicado por O’Reilly, entre otras cosas, Jono colabora con el proyecto KDE.
- Corey Burger: Administrador del proyecto Ubuntu Documentation Project.
- Otros autores: Entre ellos se encuentran Ivan Krstic y Jonathan Jesse.
Este libro tendrá una licencia Creative Commons.
browser
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
canaima
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
charla
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
chile
Planeta Linux estrena instancia Chilena
Anoche, después de conversar con Damog, se habilitó una nueva instancia en Planeta Linux, en esta ocasión es Chile, la idea la sugirió a través de la lista de correos de Planeta Linux el sr. Flabio Pastén Valenzuela, así que cualquier chileno o chilena que esté interesado en participar en Planeta Linux solo debe escribir a la lista de correos [email protected] la siguiente información.
- Nombre Completo.
- URI del feed.
- Hackergothi, aunque es opcional.
- Instancia en la que deseas aparecer, en este caso, Chile.
Se le recomienda a quienes quieran participar en Planeta Linux leer en primera instancia su serie de respuestas a preguntas frecuentes y los lineamientos.
cms
WordPress 2.0.3
Matt Mullenweg anunció hace pocos días la disponibilidad de la versión 2.0.3 para WordPress, la versión más reciente hasta ahora de la serie estable 2.0.
Características en la versión 2.0.3
En esta nueva versión se puede observar.
- Mejoras en cuanto al rendimiento.
- Mejora en el sistema que permite importar entradas o posts desde Movable Type o Typepad.
- Mejora en cuanto al manejo de los enclosures Un enclosure es una manera de adjuntar contenido multimedia a un feed RSS, simplemente asociando la URL del fichero a la entrada particular. Esta característica es de vital importancia para la difusión del podcasting. para podcasts Mayor información acerca del podcasting.
- Corrección de errores de seguridad.
Se corrige el error de seguridad que permitía la inyección de código PHP arbitrario si se encontraba activo el registro libre de usuarios, era necesario desmarcar la casilla de verificación Cualquiera puede registrarse para subsanar el error, dicha casilla puede encontrarla en el área administrativa bajo Opciones -> General.
Si lo desea, puede apreciar la lista completa de las correcciones realizadas para esta versión, algunas de las que llamaron mi atención fueron la #2463 y el #2548, en ambas correcciones se aprecia la optimización en cuanto al rendimiento de WordPress.
Pasos para actualizar desde la versión 2.0.2 a 2.0.3
- Eliminar el contenido de la carpeta /wp-admin.
- En caso de utilizar el directorio /wp-includes/languages, debe respaldarlo. (Opcional).
- Eliminar el contenido de la carpeta /wp-includes.
- Eliminar todos los ficheros del directorio raíz de tu instalación de WordPress, excepto el fichero de configuración, wp-config.php.
- Descargar y descomprimir la nueva versión de WordPress.
- Restaurar las carpetas /wp-admin y /wp-includes. En caso de haber realizado el paso 2, recuerda restaurar también la carpeta /wp-includes/languages.
- Restaurar los ficheros del directorio raíz de tu instalación de WordPress.
- En el paso anterior, no es necesario colocar los ficheros wp-config-sample.php, license.txt, ni el readme.html, bien puedes eliminarlos si gustas.
- Ingresa en el área administrativa, proceda a actualizar la base de datos.
Eso es todo, como siempre, recuerde que es recomendable eliminar los ficheros install.php y upgrade.php, los cuales se encuentran en el directorio /wp-admin
Después de actualizar a la versión 2.0.3
Aún después de actualizar WordPress, existen algunos comportamientos extraños. Cuando usted edita un comentario aparecerá un cuadro de dialogo que le preguntará si está seguro de realizar dicha acción, de igual manera sucede si usted intenta editar un enlace o un usuario, entre otras cosas.
Si usted quiere deshacerse de esos comportamientos extraños, le recomiendo instalar el plugin WordPress 2.0.3 Tuneup, los errores que corrige este plugin hasta su versión 0.3 son: #2760, #2761, #2764, #2776, #2782.
De acuerdo al roadmap de WordPress se espera que la versión 2.0.4 esté lista para el día 30/06/2006.
cntlm
apt-get detrás de proxy con autenticación NTLM
Por motivos que no vienen al caso discutir en este artículo tuve que instalar Debian GNU/Linux detrás de un proxy que aún utiliza NTLM como medio de autenticación, aunque NTLM ya no es recomendado por Microsoft desde hace años en pro de usar Kerberos.
Una vez instalada la distribución quería utilizar apt-get para actualizarla e
instalar nuevos paquetes, el resultado fue que apt-get no funciona de manera
transparente detrás de un proxy con autenticación NTLM. La solución fue
colocar un proxy interno que esté atento a peticiones en un puerto particular
en el host, el proxy interno se encargará de proveer de manera correcta las
credenciales al proxy externo.
La solución descrita previamente resulta sencilla al utilizar cntlm. En
principio será necesario instalarlo vía dpkg, posteriormente deberá editar los
campos apropiados en el fichero /etc/cntlm.conf
- Username
- Domain
- Password
- Proxy
Seguidamente reinicie el servicio:
# /etc/init.d/cntlm restart
Ahora solo resta configurar apt-get para que utilice nuestro proxy interno,
para ello edite el fichero /etc/apt.conf.d/02proxy
Acquire::http::Proxy "http://127.0.0.1:3128";
NOTA: Se asume que el puerto de escucha de cntlm es el 3128.
Ahora puede hacer uso correcto de apt-get:
# apt-get update
# apt-get upgrade
...
NOTA FINAL: Es evidente que cualquier comando o herramienta que necesite
autenticarse contra el proxy externo deberá configurarlo para que utilice el
proxy interno, lo explicado en este artículo no solo aplica para el comando
apt-get.
conac
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
conocimiento+libre
Charla: Libre como un Mercado Libre
El Consejo de Computación Académica, la Corporación Parque Tecnológico de Mérida y el Centro Nacional de Cálculo Científico de la Universidad de Los Andes, invitan a la charla Libre como un Mercado Libre, cuyo ponente será el Profesor Jacinto Dávila.
El objetivo de la charla básicamente es el siguiente:
En esta presentación, pretendemos argumentar en favor de “libre como en el mercado libre”, una manera quizás desesperada de enfatizar el valor social del nuevo espacio para los negocios que se abre con el Software Libre. El Software Libre no es software gratis. De hecho, quienes desarrollen así pueden seguir cobrando lo que quieran por su trabajo, siempre que no impidan que otros conozcan los códigos fuentes, los usen y los compartan sin restricciones. Lamentablemente, las animosidades, sobretodo las políticas, están nublando toda discusión al respecto y destrozando el mayor logro del software libre: devolver a los tecnólogos a la especie humana.
Información adicional:
- Fecha: Jueves 2 de Marzo.
- Hora: 2:30 pm.
- Lugar: Núcleo La Hechicera, Facultad de Ciencias, Nivel Patio, Salón A9.
- Costo: Entrada Libre.
Algunas referencias que se recomienda leer.
- Petróleo por Software: La energía de los hidrocarburos y la apuesta a futuro con el Software Libre.
- El Copyleft es derechista (también)
Ambos artículos escritos por el profesor Jacinto Dávila.
cowbell
Cowbell: Organiza tu música
Cowbell, es una aplicación que te permite organizar tus compilaciones musicales de una manera fácil y divertida, ya no tienes que aburrirte por horas al intentar organizar tus colección musical manualmente.
Una de las cosas que me han agradado de este programa es que aparte de poder editar las etiquetas manualmentede en una interfaz bastante agradable y sencilla, también puedes obtener toda la información necesaria a través de Amazon Web Services, lo anterior incluye: Número, Título, Año, Estilo, Portada y demás información relacionada con las canciones. Al utilizar este servicio cuentas con una amplia bases de datos, lo anterior en realidad permite ahorrar mucho tiempo.
Dentro de las preferencias de este programa nos encontraremos con opciones que nos permitirán renombrar ficheros de acuerdo a un patrón, el cual lo podemos generar al combinar cualquiera de las siguientes palabras claves.
- Artist
- Album
- Title
- Track
- Genre
- Year
Las palabras claves anteriores se explican por sí solas. Simplemente escoge el patrón que más se ajuste a tus necesidades. Entre otras de las características de este programa, cabe mencionar la posibilidad de generar un fichero de lista de reproducción del álbum.
¿Tienes una larga colección de música cuyas etiquetas debes arreglar?, no te preocupes, Cowbell también puedes usar desde la línea de comandos, la manera de invocar el comando es la siguiente:
$ cowbell --batch /ruta/a/tu/musica
Donde evidentemente debes modificar el directorio /ruta/a/tu/musica de acuerdo a tus necesidades.
Para instalar esta aplicación en ubuntu debes tener activo el repositorio universe en tu fichero /etc/apt/sources.list. Una vez actualizada la lista de repositorios, puedes instalar Cowbell de la siguiente manera:
$ sudo aptitude cowbell
cracklib
Fortaleciendo nuestras contraseñas
Si una de las promesas que tiene para este cierre de año es fortalecer las
contraseñas en sus equipos personales, cambiarlas mensualmente y no repetir la
misma contraseña en al menos doce cambios. En este artículo se le explicará como
hacerlo sin tener que invertir una uva en ello, todo esto gracias al paquete
libpam-cracklib en Debian, el procedimiento mostrado debe aplicarse a otras
distribuciones derivadas de Debian.
Pareciese lógico que algunas de las mejores prácticas para el fortalecimiento de las contraseñas son las siguientes:
- Cambiar las contraseñas periódicamente.
- Establecer una longitud mínima en las contraseñas.
- Establecer buenas reglas para las nuevas contraseñas, es decir, mezcla entre letras mayúsculas, minúsculas, dígitos y caracteres alfanuméricos.
- Mantener un histórico de las contraseñas usadas previamente, de ese modo, alentamos a los usuarios establecer nuevas contraseñas.
- Indicarle a los usuarios que es inaudito que se anoten las contraseñas en un post-it y se dejen pegadas en los monitores o incluso en las gavetas de sus archivadores.
El primer paso es instalar el paquete libpam-cracklib
# apt-get install libpam-cracklib
A partir de la versión 1.0.1-6 de PAM se recomienda manejar la configuración vía
pam-auth-update. Por lo tanto, por favor tome un momento y lea la sección 8
del manual del comando pam-auth-update para aclarar su uso y ventajas.
$ man 8 pam-auth-update
Ahora establezca una configuración similar a la siguiente, vamos primero con la
exigencia en la fortaleza de las contraseñas, para ello edite o cree el fichero
/usr/share/pam-configs/cracklib.
Name: Cracklib password strength checking
Default: yes
Priority: 1024
Conflicts: unix-zany
Password-Type: Primary
Password:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
Password-Initial:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
NOTA: Le recomiendo leer la sección 8 del manual de pam_cracklib para
encontrar un mayor numero de opciones de configuración. Esto es solo un ejemplo.
En versiones previas el modulo pam_cracklib hacia uso del fichero
/etc/security/opasswd para conocer si la propuesta de cambio de contraseña no
había sido utilizada previamente. Dicha funcionalidad ahora corresponde al nuevo
modulo pam_pwhistory
Definamos el funcionamiento de pam_pwhistory a través del fichero
/usr/share/pam-configs/history.
Name: PAM module to remember last passwords
Default: yes
Priority: 1023
Password-Type: Primary
Password:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
Password-Initial:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
NOTA: Para mayor detalle de las opciones puede revisar la sección 8 del
manual de pam_pwhistory
Seguidamente proceda a actualizar la configuración de PAM vía pam-auth-update.
Una vez cubierta la fortaleza de las contraseñas nuevas y de evitar la reutilización de las ultimas 12, de acuerdo al ejemplo mostrado, resta cubrir la definición de los periodos de cambio de las contraseñas.
Para futuros usuarios debemos ajustar ciertos valores en el fichero
/etc/login.defs
#
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 30
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Las reglas previas no aplicaran para los usuarios existentes, pero para este
tipo de usuarios podremos hacer uso del comando chage de la siguiente manera:
# chage -m 0 -M 30 -W 5 ${user}
Donde el valor de ${user} debe ser reemplazo por el username.
csv
Generar reporte en formato CSV de tickets en Trac desde Perl
El día de hoy recibí una llamada telefónica de un compañero de labores en donde me solicitaba con cierta preocupación un “pequeño” reporte del estado de un listado de tickets que recién me había enviado vía correo electrónico puesto que no contaba con conexión a la intranet, al analizar un par de tickets me dije que no iba a ser fácil realizar la consulta desde el asistente que brinda el mismo Trac. Así que inmediatamente puse las manos sobre un pequeño script en Perl que hiciera el trabajo sucio por mí.
Es de hacer notar que total de tickets a revisar era el siguiente:
$ wc -l tickets
126 tickets
Tomando en cuenta el resultado previo, era inaceptable hacer dicha labor de manera manual. Por lo tanto, confirmaba que realizar un script era la vía correcta y a la final iba a ser más divertido.
Tomando en cuenta que el formato de entrada era el siguiente:
#3460
#3493
...
El formato de la salida que esperaba era similar a la siguiente:
3460,"No expira la sesión...",closed,user
Básicamente el formato implica el id, sumario, estado y responsable asociado al ticket.
Net::Trac le ofrece una manera sencilla de interactuar con una instancia remota de Trac, desde el manejo de credenciales, consultas, revisión de tickets, entre otros. A la vez, se hace uso del módulo Class::CSV el cual le ofrece análisis y escritura de documentos en formato CSV.
#!/usr/bin/perl
use warnings;
use strict;
use Net::Trac;
use Class::CSV;
# Estableciendo la conexion a la instancia remota de Trac
my $trac = Net::Trac::Connection->new(
url => 'http://trac.example.com/project',
user => 'user',
password => 'password'
);
# Construccion del objecto CSV y definicion de opciones
my $csv = Class::CSV->new(
fields => [qw/ticket sumario estado responsable/],
line_separator => "\r\n",
csv_xs_options => { binary => 1, } # Manejo de caracteres non-ASCII
);
# Nos aseguramos que el inicio de sesion haya sido exitoso
if ( $trac->ensure_logged_in ) {
my $ticket = Net::Trac::Ticket->new( connection => $trac );
# Consultamos cada uno de los tickets indicados en el fichero de entrada
while ( my $line = <> ) {
chomp($line);
if ( $line =~ m/^#\d+$/ ) {
$line =~ s/^#(\d+)$/$1/;
$ticket->load($line);
$csv->add_line(
{
ticket => $ticket->id,
sumario => $ticket->summary,
estado => $ticket->status,
responsable => $ticket->owner
}
);
}
else {
print "[INFO] La linea no cumple el formato requerido: $line\n";
}
}
$csv->print();
}
else {
print "No se pudieron asegurar las credenciales";
}La manera de ejecutar el script es la siguiente:
$ perl trac_query.pl tickets
En donde trac_query.pl es el nombre del script y tickets es el fichero de
entrada.
Debo aclarar que el script carece de comentarios, mea culpa. Además, el manejo de opciones vía linea de comandos es inexistente, si desea mejorarlo puede hacer uso de Getopt::Long.
Cualquier comentario, sugerencia o corrección es bienvenida.
cultura
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
dbconfig-common
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
debconf
Instalando dependencias no-libres de JAVA en ambientes pbuilder
El día de hoy asumí la construcción de unos paquetes internos compatibles con
Debian 5.0 (a.k.a. Lenny) que anteriormente eran responsabilidad de
ex-compañeros de labores. El paquete en cuestión posee una dependencia
no-libre, sun-java6-jre. En este artículo se describirá como lograr
adecuar su configuración de pbuilder para la correcta construcción del
paquete.
Asumiendo que tiene un configuración similar a la siguiente:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
Para mayor información sobre estas opciones sírvase leer:
$ man 5 pbuilderrc
Mientras intenta compilar su paquete en el ambiente proporcionado por pbuilder
el proceso fallará ya que no se mostró la ventana para aceptar la licencia de
JAVA. Podrá observar en el registro de la construcción del build un mensaje
similar al siguiente:
Unpacking sun-java6-jre (from .../sun-java6-jre_6-20-0lenny1_all.deb) ...
sun-dlj-v1-1 license could not be presented
try 'dpkg-reconfigure debconf' to select a frontend other than noninteractive
dpkg: error processing /var/cache/apt/archives/sun-java6-jre_6-20-0lenny1_all.deb (--unpack):
subprocess pre-installation script returned error exit status 2
Para evitar esto altere la configuración del fichero pbuilderrc de la
siguiente manera:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
export DEBIAN_FRONTEND="readline"
Una vez alterada la configuración podrá interactuar con las opciones que le
ofrece debconf.
Ahora bien, si usted constantemente tiene que construir paquetes con dependencias no-libres como las de JAVA, es probable que le interese lo que se menciona a continuación.
Si lee detenidamente la página del manual de pbuilder en su sección 8 podrá
encontrar lo siguiente:
$ man 8 pbuilder
...
--save-after-login
--save-after-exec
Save the chroot image after exiting from the chroot instead of deleting changes. Effective for login and execute session.
...
Por lo tanto, usaremos esta funcionalidad que ofrece pbuilder para insertar
valores por omisión en la base de datos de debconf para que no se nos pregunte
si deseamos aceptar la licencia de JAVA:
# pbuilder login --save-after-login
I: Building the build Environment
I: extracting base tarball [/var/cache/pbuilder/base.tgz]
I: creating local configuration
I: copying local configuration
I: mounting /proc filesystem
I: mounting /dev/pts filesystem
I: Mounting /var/cache/pbuilder/ccache
I: policy-rc.d already exists
I: Obtaining the cached apt archive contents
I: entering the shell
File extracted to: /var/cache/pbuilder/build//27657
pbuilder:/# cat > java-license << EOF
> sun-java6-bin shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jdk shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jre shared/accepted-sun-dlj-v1-1 boolean true
> EOF
pbuilder:/# debconf-set-selections < java-license
pbuilder:/# exit
logout
I: Copying back the cached apt archive contents
I: Saving the results, modifications to this session will persist
I: unmounting /var/cache/pbuilder/ccache filesystem
I: unmounting dev/pts filesystem
I: unmounting proc filesystem
I: creating base tarball [/var/cache/pbuilder/base.tgz]
I: cleaning the build env
I: removing directory /var/cache/pbuilder/build//27657 and its subdirectories
dell
Establecer red inalámbrica en Dell m1210
Hace ya algunos días Ana me comentaba que no le estaba funcionando la configuración que tenía para su red inalámbrica, eso ocurrió una vez que actualizó la versión del kernel de linux, espero entrar en detalle acerca de los pasos que seguí para configurarle todo como se debe bajo Debian Etch.
Lo primero que debía saber era el tipo de componente PCI al que me estaba enfrentando.
$ lspci -nn | grep Wireless
0c:00.0 Network controller [0280]:
Broadcom Corporation Dell Wireless 1390
WLAN Mini-PCI Card [14e4:4311] (rev 01)
Lo anterior dice que nos estamos enfrentando ante una Broadcom cuyo chipset id es el 4311, debemos saber que el módulo para linux de estos chips es el bcm43xx y ha sido incluido al kernel de linux desde la versión 2.6.17-rc2Fuente: http://bcm43xx.berlios.de/, al revisar la lista de dispositivos soportados me percaté que el soporte para este chipset id aún es inestable, así que el siguiente paso era eliminar su presencia si aplicaba.
$ lsmod | grep bcm43xx
bcm43xx 148500 0
ieee80211softmac 40704 1 bcm43xx
ieee80211 39112 2 bcm43xx,ieee80211softmac
Como se puede observar en este caso aplica, así que comenzamos a eliminar su presencia.
# grep -q '^blacklist bcm43xx' /etc/modprobe.d/blacklist \\
|| tee -a 'blacklist bcm43xx' /etc/modprobe.d/blacklist
La inclusión de la línea blacklist bcm43xx al fichero /etc/modprobe.d/blacklist si aplica me permite indicar que dicho módulo no debe cargarse como resultado de la expansión de su alias, es decir, bcm43xx, esto se hace con el propósito de evitar que el subsistema hotplug lo carge, aunque esto no evita que el módulo se carge automáticamente por el kernel.
Luego verifique el fichero /etc/modules, el cual contiene los nombre de los módulos que serán cargados a la hora del inicio del sistema, no había entrada para el módulo bcm43xx, ahora es necesario remover dicho módulo, para lo cual hacemos:
# modprobe -r bcm43xx
Una vez culminado este proceso es necesario hacer uso de ndiswrapper, el cual es un módulo que me permite cargar y ejecutar drivers propietarios de Windows para tarjetas inalámbricas.
# aptitude -r install build-essential \\
module-assistant ndiswrapper-common
# m-a update
# m-a prepare
# m-a a-i ndiswrapper
# modprobe ndiswrapper
Una vez cargado el módulo ndiswrapper es necesario instalar el nuevo driver propietario, para ello debemos encontrar el fichero con extensión inf, este fichero especifica que ficheros necesitan estar presentes o descargarse para que el componente funcione correctamente, para dicho driver. Al consultar en la lista de tarjetas que funcionan con ndiswrapper me percato que han habido problemas de seguridad en algunos de los drivers recomendados para esta tarjeta, así que para asegurarme de obtener las versiones más recientes ingreso al sitio oficial de Dell, bajo la sección USA -> Support search: “m1210” -> Drivers and Downloads -> Network & Internet -> Network Driver, ingreso el campo correspondiente al service tag, y finalmente descargo el fichero R151517.EXE.
El siguiente paso es extraer los ficheros que se encuentran dentro de R151517.EXE, para ello:
unzip R151517.EXE
Ahora nos interesa el fichero bcmwl5.inf que está dentro del directorio DRIVER.
$ tree R151517/DRIVER/
R151517/DRIVER/
|-- bcm43xx.cat
|-- bcm43xx64.cat
|-- bcmwl5.inf
|-- bcmwl5.sys
`-- bcmwl564.sys
Una vez extraídos los ficheros, procedemos a cargar el driver, para ello hacemos lo siguiente:
# ndiswrapper -i R151517/DRIVER/bcmwl5.inf
Comprobamos que el driver se ha instalado correctamente.
# ndiswrapper -l
installed drivers:
bcmwl5 driver installed, hardware (14E4:4324) present (alternate driver: bcm43xx)
Luego verificamos nuestro trabajo al ejecutar el comando dmesg, tal como se muestra a continuación:
$ dmesg
[44093.473325] ndiswrapper version 1.27 loaded (preempt=no,smp=yes)
[44095.311236] ndiswrapper (link_pe_images:577): fixing KI_USER_SHARED_DATA address in the driver
[44093.482777] ndiswrapper: driver bcmwl5 (Broadcom,03/23/2006, 4.40.19.0) loaded
[44093.483250] ACPI: PCI Interrupt 0000:0c:00.0[A] -> GSI 17 (level, low) -> IRQ 177
[44093.483367] PCI: Setting latency timer of device 0000:0c:00.0 to 64
[44093.491760] ndiswrapper: using IRQ 177
[44094.162703] wlan0: vendor:
[44094.162708] wlan0: ethernet device 00:18:f3:6b:fc:3b using NDIS driver bcmwl5, 14E4:4311.5.conf
[44094.162772] wlan0: encryption modes supported: WEP; TKIP with WPA, WPA2, WPA2PSK; AES/CCMP with WPA, WPA2, WPA2PSK
[44094.166554] usbcore: registered new driver ndiswrapper
[44094.167390] ndiswrapper: changing interface name from 'wlan0' to 'eth1'
En este preciso instante el comando ifconfig -a debe mostrarnos la nueva interfaz, y el comando iwlist eth1 scan al ejecutarse como superusuario devolverá la lista de redes que han sido detectadas.
Recuerde que para que todo esto siga funcionando aún después de reiniciar el sistema, es necesario cargar el módulo de ndiswrapper, para ello hago uso del comando modconf.
*[PCI]: Peripheral Component Interconnect
design
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
dictionary
StarDict: El diccionario que buscaba
Leyendo el ejemplar #14 de la revista Tux Magazine me encuentro con un interesante artículo, Learning Foreign Languages with jVLT and StarDict, la segunda aplicación descrita en dicho artículo, StartDict, llamó mi atención, así que a continuación se dará una breve revisión de la aplicación en cuestión.
¿Qué es StarDict?
StarDict es un diccionario internacional multiplataforma escrito en Gtk2, puede ser utilizado sin conexión a la web.
Características
-
Búsqueda de patrones: Usted puede buscar patrones de cadenas o caracteres usando comodines, por ejemplo, podrá usar el comodín
*para buscar una cadena arbitraria, el resultado puede ser vacío, mientras que con el uso del comodín?buscará una coincidencia con un carácter arbitrario. e.g. Suponiendo que tiene instalado el diccionario Inglés – Español, al buscar el patrón hell? encontrará como resultado la traducción de hello, mientras que con el uso del patrón hell* encontrará todas aquellas posibles coincidencias que comiencen con la cadena hell, hell (infierno en inglés), hell (suerte en noruego), los resultados encontrados dependerá de los diccionarios que haya instalado. - Búsqueda difusa: Si usted por casualidad no recuerda exactamente como deletrear una palabra, podrá intentar realizar dicha búsqueda desde StarDict, éste utilizará el algoritmo de la Distancia de Levenshtein El algoritmo de la Distancia de Levenshtein o la distancia de edición entre dos cadenas, se refiere al número mínimo de operaciones necesarias para transformar una cadena en otra, bajo éste algoritmo se considera una operación a la inserción, eliminación o substitución de un carácter. Para mayor información le recomiendo leer el artículo Levenshtein Distance, in Three Flavors.. Para utilizar esta característica simplemente comience la búsqueda con el carácter /, e.g., suponga que tiene instalado el diccionario Español – Inglés, usted cree que la palabra acero realmente se escribe así: asero, simplemente introduzca en el formulario la cadena /asero, obtendrá el resultado deseado.
-
Búsqueda por palabras seleccionadas: Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada.
-
Manejo de diccionarios: StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen).
- ¿No encuentra lo que necesita?: StarDict le permite realizar búsquedas en la web, solo deberá seleccionar el botón de búsqueda en Internet y escoger cualquiera de las 10 opciones actuales de búsqueda.
Ahora bien, seguramente esta aplicación resultará útil para muchas personas, si usted es uno de ellos y está interesado en instalarlo, es muy sencillo.
¿Cómo instalar StarDict?
Si usted es tan afortunado como yo, debe estar usando Debian, así que simplemente tendrá que hacer:
# aptitude install stardict
Ahora bien, si usted utiliza por ejemplo, Ubuntu, también puede instalarlo fácilmente, ¿cómo?, en primer lugar debe activar el repositorio universe (recuerde actualizar la lista de paquetes disponibles), posteriormente debe hacer:
$ sudo aptitude install stardict
Si usted utiliza otra distribución de GNU+Linux o es usuario de Windows, lea la documentación de la página oficial del proyecto, lamento informarle que este artículo es una revisión breve de la aplicación StarDict.
¿Cómo instalar diccionarios?
Primero que nada, debe descargar los diccionarios que necesite, para ello le recomiendo ir a la página de Descarga de Diccionarios del proyecto.
Una vez que haya descargado los diccionarios, debe proceder como sigue:
tar -C /usr/share/stardict/dic -x -v -j -f \\
diccionario.tar.bz2
Personalizando la aplicación
Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Una característica de StarDict que puede resultar realmente molesta es cuando se encuentra activo el modo Scan, es decir, toda palabra o frase resaltada con el ratón generará un cuadro de dialogo con la definición de dicha palabra o frase, si usted desea controlar este comportamiento, le recomiendo activar las siguientes casillas de verificación:
- Only do scanning while modifier key being pressed.
- Hide floating window when modifier key pressed.
Las casillas de verificación previamente mencionadas podrá encontrarlas bajo la sección Dictionary -> Scan Selection.
Si usted esta inconforme con las opciones de búsqueda en Internet, puede agregar las que usted desea desde la sección Main Window -> Search Website.
dijkstra
El algoritmo de Dijkstra en Perl
Hace ya algunos días nos fué asignado en la cátedra de Redes de Computadoras encontrar el camino más corto entre dos vértices de un grafo dirigido que no tuviese costos negativos en sus arcos, para ello debíamos utilizar el algoritmo de Dijkstra. Además de ello, debía presentarse el grafo y la ruta más corta en una imagen, para visualizarlo de mejor manera.
Cuando un profesor te dice: No se preocupen por la implementación del algoritmo de Dijkstra, utilice la que usted prefiera, pero les agradezco que la analicen. Además, pueden utilizar el lenguaje de programación de su preferencia. Estas palabras te alegran el día, simplemente eres feliz.
Por algunos problemas que tuve con algunos módulos en Python, no lo hice en dicho lenguaje de programación, no vale la pena explicar en detalle los problemas que se me presentaron.
Lo importante de todo esto, es que asumí el reto de realizar la asignación en un lenguaje de programación practicamente nuevo para mí, aunque debo reconocer que la resolución no me causó dolores de cabezas en lo absoluto, a continuación algunos detalles.
En primer lugar, formularse las preguntas claves, ¿existe algún módulo en Perl que implemente el algoritmo de Dijkstra para encontrar el camino más corto?, ¿existe algún módulo en Perl que implemente GraphViz?
En segundo lugar, buscar en el lugar correcto, y cuando hablamos de Perl el sitio ideal para buscar es search.cpan.org, efectivamente, en cuestión de segundos encontre los dos módulos que me iban a facilitar la vida, Bio::Coordinate::Graph, para encontrar la ruta más corta entre dos vértices en un grafo y GraphViz, para pintar el grafo.
En tercer lugar, verificar en tu distro favorita, Debian, si existe un paquete precompilado listo pasa ser usado, para GraphViz existe uno, libgraphviz-perl, así que para instalarlo es tan fácil como:
# aptitude install libgraphviz-perl
Para instalar el módulo Bio::Coordinate::Graph, primero debía debianizarlo, eso es tan sencillo como hacer.
# dh-make-perl --build --cpan Bio::Coordinate::Graph
Luego debe proceder a instalar el fichero .deb que se generó con dh-make-perl, para lograrlo hago uso del comando dpkg, eso es todo. Por cierto, acerca del comando dh-make-perl ya había hablado en la entrada Perl: Primeras experiencias.
Encontrando el camino más corto
Según dice la documentación del módulo Bio::Coordinate::Graph debemos hacer uso de un hash de hashes anónimos para representar la estructura del grafo, en ese momento recordé algunas palabras que José Luis Rey nos comentó en la primera parte del curso de Perl, vale resalta la siguiente: Si usted no utiliza un hash, no lo está haciendo bien.
my $hash = {
'6' => undef,
'1' => {
'2' => 1
},
'2' => {
'6' => 4,
'4' => 1,
'3' => 1
},
'3' => {
'6' => 1
},
'4' => {
'5' => 1
},
'5' => undef
};Algo que es importante saber es que en Perl las estructuras de datos son planas, lo cual es conveniente. Por lo tanto, vamos a tener que utilizar referencias en este caso, pero luego nos preocuparemos por ello. Ahora solo resta decir que, la estructura hecha a través de un hash de hashes es sencilla de interpretar, las llaves o keys del hash principal representan los vértices del grafo, ahora bien, las llaves de los hashes más internos representan los vértices vecinos de cada vértice descrito en el hash principal, el valor de los hashes más internos representa el peso, distancia o costo que existe entre ambos vértices, para aclarar la situación un poco: El vértice 2, tiene como vecinos a los vértices 3, 4 y 6, con costos de 1, 1 y 4 respectivamente. Puede ver una muestra del grafo resultante.
De manera alternativa puede utilizar un hash de arrays para representar la estructura del grafo, siempre y cuando todos los costos entre los vértices sean igual a 1, este método es menos general que el anterior y además, este tipo de estructura es convertida a un hash de hashes, así que a la final resulta ineficiente.
Una vez definida la estructura del grafo corresponde crear el objeto, esto es realmente sencillo.
my $graph = Bio::Coordinate::Graph->new(-graph => $hash);Lo que resta es definir el vértice de inicio y el vértice final, yo los he definido en las variables $start y $end, luego de ello, debemos invocar al método shortest_path, de la siguiente manera:
my @path = $graph->shortest_path($start, $end);En el array @path encontraremos los vértices involucrados en el camino más corto.
Pintando el grafo
Una vez hallado el camino más corto entre dos vértices dados en un grafo dirigido con un costo en los arcos siempre positivos, lo que resta es hacer uso del módulo GraphViz, hacemos uso del constructor del objeto de la siguiente manera:
my $g = GraphViz->new();Usted puede invocar al constructor con distintos atributos, para saber cuales usar le recomiendo leer la documentación del módulo.
Ahora bien, yo quería distinguir aquellos vértices involucrados en el camino más corto de aquellos que no pertenecían, así que lo más sencillo es generar una lista de atributos que será usada posteriormente. Por ejemplo:
my @shortest_path_attrs = (
color => 'red',
);Una vez definidos los atributos, debemos generar cada uno de sus vértices y además, establecer los arcos entre cada uno de ellos. Para ello haremos uso de los métodos add_node, add_edge.
foreach my $key (keys %$hash){
$g->add_node($key);
foreach my $neighbor (keys %{$hash->{$key}}){
$g->add_edge($key => $neighbor, label => $hash->{$key}->{$neighbor});
}
}El bloque de código anterior lo que hace es agregar cada uno de los vértices que se encuentran en el hash que representa la estructura del grafo, para cada uno de estos vértices, se añade cada uno de los arcos que lo conectan con sus vecinos, nótese el manejo del operador flecha (->) para desreferenciar las referencias al hash de hashes anónimos.
Una vez construidos los nodos y sus arcos, ¿cómo reconocer aquellos que pertenecen al camino más corto?, bueno, toda esa información la podemos extraer del array que hemos denominado @path.
for (my $count=0; $count < = $#path; $count++){
$g->add_node($path[$count], @shortest_path_attrs);
$g->add_edge($path[$count] => $path[$count+1], @shortest_path_attrs) unless ($count+1 > $#path);
}Según dice la documentación del módulo GraphViz todos los atributos de un vértice del grafo no tienen que definirse de una sola vez, puede hacerse después, ya que las declaraciones sucesivas tienen efecto acumulativo, eso quiere decir lo siguiente:
$g->add_node('1', color => 'red');Es equivalente a hacer las siguientes declaraciones sucesivas.
$g->add_node('1');
$g->add_node('1', color => 'red');Lo que resta por hacer en este instante es exportar el objeto creado, puede crear por ejemplo un PNG, texto sin formato, PostScript, entre otros.
Yo decidí generar un fichero PostScript:
$g->as_ps("dijkstra.ps");Por supuesto, les dejo una muestra de los resultados. Los vértices cuyo borde es rojo, son aquellos involucrados en el camino más corto desde el vértice inicio al vértice final, los arcos que marcan la ruta más corta también han sido coloreados.
Como siempre, todas las recomendaciones, comentarios, sugerencias son bienvenidas.
documental
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
drake
Ubuntu Dapper Drake Flight 6
Flight 6, es la última versión alpha disponible de Ubuntu Dapper Drake, esta versión ha sido probada razonablemente, pero recuerde que a pesar de ello todavía es una versión alpha, así que no se recomienda su uso en medios en producción. Esta versión puede descargarla desde:
- Europa:
- Reino unido y el resto del mundo:
- Bittorent: Se recomienda su uso si es posible.
- Sitios Espejos: Una lista de sitios espejos puede encontrarse en: Ubuntu Mirror System.
Una lista con los cambios notables en esta sexta versión alpha pueden ser encontrados en Dapper Flight 6.
edubuntu
edubuntu es adaptable al ambiente familiar?
Es importante hacer notar que el objetivo primordial de edubuntu es ofrecer una alternativa para el ambiente escolar (puede ser igualmente usable por los niños en casa), ofreciendo dos modos de instalación (servidor y estación de trabajo), el primero de los modos de instalación es ideal para ambientes escolares donde existen laboratorios, se provee LTSP (Linux Terminal Server Project), el cual permite que otros ordenadores (los cuales fungen como clientes) se conecten al servidor y utilicen los recursos de éste para ejecutar sus aplicaciones de escritorio.
Lo anterior resulta muy interesante porque permite mantener todas las aplicaciones en un solo lugar (el servidor), cualquier actualización que se haga ocurrirá únicamente en éste. Por lo tanto, cada vez que un cliente inicie sesión, automáticamente estará ejecutando un sistema actualizado.
La aclaración anterior viene dada por el artículo Review: Is Edubuntu truly the operating system for families?, redactado por Jay Allen, en donde el autor hace una revisión de uno de los sabores de ubuntu, edubuntu, pensando que éste estaba orientado exclusivamente a los niños de la casa.
El autor intenta dar su punto de vista como un padre de familia con pocos conocimientos de informática y no como el desarrollador de software que ha sido por 12 años.
| Muchos de los lectores seguramente sabrán que los sabores orientados a los usuarios de casa son: Ubuntu, Kubuntu y quizás Xubuntu, pero no le podemos decir a un padre de familia que tiene pocos conocimientos en el área lo suguiente: Instala (X | K)ubuntu y seguidamente procede a instalar el paquete edubuntu-desktop. Esta opción quedará descartada en el siguiente artículo ya que desde el punto de un padre con pocos conocimientos en informática pero que esté preocupado por la educación de sus hijos preferirá tener el sistema que el realmente desea en un instante, en vez de tener que instalar ciertos paquetes para obtener lo que él en realidad necesita. |
Edubuntu brinda un sistema operativo lleno de paquetes educacionales, juegos, herramientas de publicación, edición gráfica y más. Todo lo descrito previamente de manera gratuita (sin cargo alguno y comprometido con los principios del Software Libre y el Código de Fuente Abierta), se realiza un gran trabajo para ofrecer una excelente infraestructura de accesibilidad, incluso para aquellos usuarios que no están acostumbrados al manejo de ordenadores, dentro de esa infraestructura de accesibilidad se considera el lenguaje, edubuntu brinda un sistema operativo que se adapta a cualquier usuario sin importar su lenguaje.
Edubuntu puede ser la respuesta a aquellas familias con pocos recursos económicos, en donde el tener acceso a un ordenador de altas prestaciones es un lujo, o en aquellos casos donde se tenga que pagar altas sumas de dinero anualmente por mantener un sistema operativo ineficiente y lleno de problemas.
Edubuntu le brindaría a estos niños (y familias) todo el poder y flexibilidad que ofrecen los sistemas *nix, todos estos beneficios a muy bajos costos.
He considerado importante esta revisión hecha por Jay Allen acerca de edubuntu, porque no es difícil imaginar que esos millones (espero) de niños que utilizan edubuntu en sus escuelas por horas, también quisieran tener ese sistema operativo tan agradable en sus casas.
Según la opinion del autor de la revisión, Jay Allen, después de experimentar con edubuntu por un día con sus hijos Neve, Jaxon, Veda de 8, 6 y 4 años respectivamente, afirma que edubuntu aún no está totalmente listo para aquellas familias con pocos conocimientos en el campo de la tecnología, pero con las características que ofrece hasta ahora es capaz de mantener satisfechos tanto a adultos como niños.
Puntos a favor para edubuntu
- Edubuntu es ideal para ordenadores de bajos recursos, por ejemplo, el autor de la revisión instaló edubuntu en una máquina con procesador Celeron a 550 MHz, 17 GB de disco duro, 4 GB en un disco duro secundario y con 192 MB de RAM.
- Respecto al punto anterior, edubuntu es capaz de brindar una mejor experiencia para los niños en un ordenador de bajos recursos que tenga instalado por ejemplo Windows 98.
- Una vez instalado edubuntu, éste ofrece una interfaz sencilla, usable y muy rápida.
- El sistema viene precargado con una serie de características muy amenas para los niños. De igual manera, se ofrecen características muy atractivas para los adultos de la casa, entre las que se encuentran, una suite ofimática realmente completa, herramientas para la manipulación de imágenes, visualización de películas y videos.
- Mozilla Firefox es incluido por defecto en la instalación, así que si está acostumbrado a él en otros ambientes, la transición no será traumática.
- Algunos de sus niños ni siquiera se dará cuenta del cambio, tal es el caso de Veda, el menor de los hijos de Jay Allen, ni siquiera se percató que su padre secretamente reemplazó Windows XP por edubuntu.
- Al pasar las semanas y sus hijos se hayan acostumbrado al sistema, puede mostrarle características más avanzadas de edubuntu sin mucha dificultad, es más, seguramente ellos ya las sepan, recuerde que los niños son muy curiosos.
Puntos en contra para edubuntu
- ¿Cuántos padres o madres en realidad entenderán lo que significan cada uno de los modos de instalación que ofrece edubuntu?, sobretodo si éstos optan por el modo de instalación por defecto, el cual es modo servidor (server), cuando en realidad deben elegir el modo de estación de trabajo (workstation).
- Muchos de los mensajes que muestra el asistente para la instalación contienen un lenguaje técnico, lo cual no es ideal en aquellos padres o madres con pocos o nulos conocimientos al respecto.
- El asistente de instalación ofrece la creación de una única cuenta, la cual puede en cualquier instante tener permisos administrativos a través del comando
sudo(acerca de ello explico un poco en el artículo ¿Es necesario activar la cuenta root en Ubuntu?), esto puede ser terrible en esos casos donde los padres o madres posean pocos o nulos conocimientos respecto a la creación de usuarios desde la cuenta predeterminada, permisos administrativos, entre otras cuestiones. Según la opinión de Jay Allen, preferiría alguna de las siguientes opciones, que el mismo asistente le dé la oportunidad de crear otra cuenta con permisos limitados o que pueda crear una cuenta para cada uno de sus hijos. - Otro punto en contra es el uso de nombre un tanto crípticos en la suite de educación KDE, incluso, la hija de Jay Allen, Neve (8 años de edad), se preguntaba en voz alta el por qué de la existencia del prefijo K en los nombres de las aplicaciones de la suite, para ella simplemente no tenía sentido. En este caso, lo más lógico sería colocar nombres más explicativos en las aplicaciones. Por lo tanto, no tendría que ser necesario abrir una aplicación solamente para saber de que trata o que soluciones puede brindarle.
- Otro punto en contra es el hecho que el programa Mozilla Firefox no traiga por defecto una sección que permita de cierta manera controlar la navegación de sus hijos, para evitar que estos últimos vean contenido explícito para adultos. Respecto a este punto en particular no es responsabilidad de edubuntu como tal, debido a que el nombre Firefox es una marca registrada (esto puede ser conveniente para el control de calidad de la aplicación como tal), a pesar que el proyecto de la Fundación Mozilla es código abierto, no se pueden realizar cambios a la aplicación original y distribuirla bajo el mismo nombre. Por lo tanto, los desarrolladores de edubuntu deben elegir entre dejar de usar el reconocido nombre Firefox, o no incluir ninguna extensión útil. Más adelante se darán detalles acerca de como solucionar este problema.
Propuestas
De la revisón hecha por Jay Allen, han salido algunas propuestas, entre ellas, una de las que me llamó la atención fué la de distribuir de manera separada los dos modos de instalación de edubuntu, lo anterior sería ideal en esos casos (que deben ser cientos) donde el padre (o madre) no posea muchos conocimientos acerca del tema, éste no sabrá que opción elegir, cuando él (o ella) ni siquiera sabe lo que significa instalación en modo servidor o modo estación de trabajo. También podría considerarse cambiar el modo de instalación por defecto, en vez de ser servidor, cambiarlo por estación de trabajo.
Otra propuesta interesante es la necesidad de proporcionar tutoriales interactivos que de alguna manera introduzcan a los niños de diversas edades en las características, capacidades y beneficios que les proporciona el sistema que manejan.
Si edubuntu no quiere prescindir del conocido nombre Firefox, debe facilitar después de la instalación una guía que indique los pasos necesarios para establecer el control de la navegación de los niños. Sería ideal colocar una guía para instalar dicha extensión o plugin en la página inicial de Firefox, o proporcionar un acceso directo a esta guía de “Primeros Pasos” desde el escritorio de la cuenta predeterminada.
emerald
Beryl y Emerald en Debian “Etch” AMD64
Sin mucho preámbulo, sólo tengo que decir que voy explicar cómo tener instalado éste famoso escritorio 3D (Beryl) en nuestros sistemas Debian AMD64. El proceso en general es muy fácil y se resume en unos pocos pasos. Antes que nada debo mencionar que la placa de video que uso es nVIDIA y que para poder utilizar el Beryl hay que hacer ciertas modificaciones al xorg.conf.
Lo primero que debemos hacer es modificar nuestro /etc/apt/sources.list para añadir una nueva entrada que va a ser el servidor desde donde se van a instalar Beryl y Emerald. Ésto lo logramos con la siguiente línea de comandos en una terminal:
# vim /etc/apt/sources.list
La línea que vamos a agregar a nuestro sources.list es la que se corresponde con el repositorio de Beryl para Debian y es la siguiente:
deb http://debian.beryl-project.org/ etch main
Luego, como han de sospechar, hay que actualizar la base de datos del aptitude, lo cual se logra así:
# aptitude update
Una vez actualizada la base de datos procedemos a instalar el Beryl con la siguente línea de comandos:
# aptitude install -ry beryl
Ésta última línea nos va a instalar el Beryl automáticamente con todos los paquetes recomendados y va a asumir “Sí” como respuesta para poder realizar la instalación. Una vez que está instalado podremos ejecutarlo desde Aplicaciones –> Herramientas del sistema –> Beryl Manager y los temas del Emeral los podemos seleccionar en Escritorio –> Preferencias –> Emerald Theme Manager. Las opciones del Beryl pueden ser modificadas con el Beryl Settings Manager, el cual puede ser localizado en la misma ruta que el Beryl Manager. Si queremos que el Beryl Manager sea ejecutado cada vez que iniciamos sesión debemos añadirlo a la lista de programas al inicio. Ésto lo hacemos ejecutando Escritorio –> Preferencias –> Sesiones _ y en la pestaña _Programas al inicio hacemos click en Añadir y escribimos beryl-manager. A continuación algunos atajos del teclado para lograr los efectos más comunes:
- Modo de movimiento de imagen borrosas = Ctrl + F12
- Rotar escritorios como un cubo = Ctrl + Alt + Flechas direccionales
- Efecto de lluvia = Shift + F9
- Zoom = Super + Scroll
- Selector de ventanas escalar = Super + Pausa
- Rotar ventana entre espacios de trabajo con el cubo = Ctrl + Alt + Shif + Teclas direccionales
- Modificar la opacidad de la ventana actual = Alt + Scroll
Por último un artículo donde explican las virtudes del Beryl 0.2 y dos videos, que a mi criterio son las mejores demostraciones de Beryl que jamas haya visto.
entities
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
etch
Debian GNU/Linux 4.0
Según puede verse en el sitio oficial del Proyecto Debian, en una noticia aparecida el día de hoy, Upcoming Release of Debian GNU/Linux 4.0, se confirma que el próximo mes de diciembre del presente año será la fecha de publicación de la siguiente versión 4.0 de Debian GNU/Linux, cuyo código nombre es “etch”.
Entre las novedades que podremos observar en esta nueva versión se encuentran las siguientes:
- Será la primera versión que ofrezca soporte oficial a la arquitectura AMD64. De manera simultánea, esta versión se publicará para 11 arquitecturas.
- La versión 4.0 ofrecerá la versión 2.6.17 del núcleo linux de manera predeterminada. Además, esta misma versión se utilizará en todas las arquitecturas y a su vez en el instalador.
- Debian GNU/Linux 4.0 presentará la colección de compiladores de GNU versión 4.1.
- Debian GNU/Linux deja de utilizar XFree86 como implementación de X11 (sistema de ventanas X) para darle paso a X.Org.
- Al menejador de paquetes APT seguramente se le añadan algunas mejoras en cuanto a seguridad, admitiendo criptografía modo paranoico y firmas digitales.
Reuniones para eliminar fallos
En la misma noticia podemos enterarnos que el Proyecto Debian está planeando algunas reuniones previas al nuevo lanzamiento en búsqueda de fallos y establecer las debidas correcciones, de esta manera, se ofrecerá al público una versión que presente la mínima cantidad de errores críticos de programación.
Estas reuniones se llevarán a cabo en varias ciudades alrededor del mundo. Por lo tanto, podrá participar el mayor número de personas en la búsqueda y corrección de estos errores de programación.
Si usted está interesado en participar pero no puede reunirse personalmente con los desarrolladores en las distintas ciudades que se describen en BSPMarathon, puede conectarse al canal #debian-bugs en el servidor irc.debian.org y de esta manera participar.
La situación en Venezuela
En mi humilde opinión, considero oportuno que la comunidad Debian Venezuela debe tomar las riendas en este asunto, organizar reuniones para eliminar fallos en nuestra distribución favorita, aprovechando la cercanía del Día Debian para organizar actividades de este tipo. ¿Qué opinan en este sentido?.
fedora
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
feed
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
femfox
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
find
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
firefox
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
flickr
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
flisol
Breve reseña del FLISOL 2006, Capítulo Mérida-Venezuela
Al llegar a eso de las 9:30 a.m. (hora local) estaban transmitiendo el video Trusted Computing (subtítulos español), un excelente video en donde nos muestran cuan peligroso puede ser la “mala interpretación” que tiene la industria acerca del concepto “Trusted Computing”, modelo en el cual la industria no le permite a los usuarios (comunidad) elegir entre lo que ellos consideran malo o nó, el problema es que ya deciden por tí, simplemente porque la industria no confía en nosotros.
Después de mostrar el video, Hector Colina, uno de los coordinadores del evento, procedió a dar la bienvenida a los asistentes al II Festival Latinoamericano de Instalación de Software Libre, capítulo Mérida, Venezuela. De inmediato, Hector continúo hablando y nos sorprendió con una charla denominada Software Libre y Libre Empresa, en donde nos hablaba de la interesante filosofía detrás del modelo de Software Libre, algunos piensan equivocadamente que bajo el esquema de Software Libre no se es posible generar ganancias, se demostró que es posible hacerlo. También hablo sobre las ventajas técnicas que brinda el Software Libre frente al Software Privativo.
Posteriormente se dió comienzo a las demostraciones de LTSP (Linux Terminal Server Project) por parte de José David Gutierrez, quien también coordinó el evento y es miembro de la Cooperativa AndiNuX, no recuerdo en este instante cuales eran las características que poseía el servidor, pero recuerdo que el cliente sobre el cual se hizo la demostración tenía apenas 40 MB de RAM (sí, leyo bien, 40 MB) y se logró levantar el entorno de escritorio KDE y ejecutar algunas aplicaciones, José comentaba que los requisitos mínimos de memoria RAM eran 16, mientras que lo óptimo erán 32 MB de RAM, así que amigo, si usted esta leyendo esto, no bote su potecito (equipo de bajo recursos de hardware), bajo el esquema de Software Libre podemos recuperarlo, quizá podría donarlo y regalarle una sonrisa a un niño que reciba educación en una escuela con pocos recursos.
Posteriormente comenzaron a colocar algunos videos a los asistentes, entre los cuales recuerdo haber visto Revolution OS, en paralelo, se realizaba el proceso de instalación desde tempranas horas de la mañana, al final de la jornada se lograron contabilizar más de 20 máquinas a las cuales se instaló GNU/Linux, incluyendo potecitos de 32 MB de RAM hasta máquinas de escritorio con procesadores de 64 bits, por supuesto, a una que otra portátil también se le instaló GNU/Linux, además, se regalaron CDs de Debian, Ubuntu, entre otros.
En la tarde el profesor Francisco Palm comenzó su charla Carpintería del Software Libre: un enfoque desde el lenguaje de Programación Python, en ella se nos hace reflexionar acerca de nuestra realidad actual en Venezuela, presentamos poca penetración de internet en nuestra sociedad. Bajo el esquema de Software Privativo, no se le brinda apoyo a la comunidad, no se presenta una innovación alguna.
El profesor Palm también converso sobre puntos interesantes acerca de la Ingeniería de Software Libre, como la Fundación Apache, Debian o Mozilla no presentan certificaciones y no les importa éste hecho en particular, puesto que su desarrollo es robusto, de hecho, muestran como funcionan por dentro. Entre otras cosas bastante interesantes.
Enseguida comenzaron otra charla 2 pupilos del profesor Palm, Diego Díaz y Freddy López, en donde se expuso el Proyecto SIGMA: Soluciones Libres para el mundo Científico, en esta charla pudimos observar una serie de demostraciones del sistema estadistico R. El proyecto SIGMA resulta de una iniciativa de los miembros de la Escuela de Estadística y el Instituto de Estadística Aplicada y Computación (IEAC) de la Universidad de Los Andes.
Sin mucho receso, Leonardo Caballero comenzó su charla acerca de Desarrollo Web con Mozilla FireFox, aca se explicó acerca de las extensiones que resultan muy útiles al desarrollador de páginas web, como por ejemplo, la extensión Web Developer, de manera adicional, se demostró cuan personalizable (desde utilizar temas hasta incluso simular comportarse como otro navegador) puede ser Firefox para un usuario particular, desde extensiones para el clima (ForecastFox) hasta herramientas de blogging.
Particularmente, para el desarrollo web utilizo más extensiones de las que mencionó Leonardo, entre ellas puedo mencionar: CSS Validator, ColorZilla, entre otras. Prefiero no continuar mencionando la lista de extensiones que poseo, se supone que sea una breve reseña, quizá en otro artículo hablaremos acerca de las extensiones de Firefox.
Un poco más tarde, el licenciado Axel Pizzi, quien pertenece a la agencia de traducción y servicios lingüisticos translinguas, conversó acerca del uso de herramientas CAT (Computer aided Translation) bajo el esquema de Software Libre, simplemente se mostraba las bondades de la traducción asistida por computadora, es una manera de traducir contenido en donde el ser humano (traductor) utiliza software diseñado para brindar soporte y facilitar ésta ardua tarea.
Algo nervioso se encontraba Jesús Rivero (no confundir con neurogeek, ok?), pues se estaba haciendo tarde para su charla, Cooperativismo y Software Libre, en donde Jesús mostró como el esquema de desarrollo colaborativo es sumamente útil en las Cooperativas.
Y ya para finalizar la jornada, comence mi charla sobre Desarrolo Web en Python utilizando el framework Django, a manera de introducción, comence a hablar del lenguaje de programación Python, sus bondades, que empresas le utilizan actualmente y que proyectos han desarrollado, entre dicha lista se incluyen las siguientes: Google, Yahoo!, empresas farmacéuticas (AstraZeneca) de gran escala mundial, Industrial Light & Magic (sí, esa misma que está pensando, es la empresa iniciada por George Lucas en el año de 1.975, la encargada de los efectos especiales de la saga “Star Wars”, no solo eso, en su lista se incluyen películas como “Forrest Gump”, “Jurassic Park”, “Terminator 2”, entre otros).
Posteriormente comence a adentrarme ya en el tema que me interesaba, Desarrollo Web, en mi caso particular, hable sobre como utilizar el framework Django, desde la instalación del framework, la instalación de PostgreSQL (recomendada) y del adaptador a dicha base de datos en python, psycopg, hasta la construcción de la aplicación. Para mayor detalle acerca de esta presentación solo esperen un próxima entrada, quisiera ampliar algunos tópicos para dejarlos un poco más claros.
Si desean ver algunas fotos que logré tomar del II Festival Latinoamericano de Instalación de Software Libre (FLISOL), Capítulo Mérida - Venezuela, pueden revisar el set de fotos FLISOL 2006 de mi cuenta en flickr.
Debo confesar que estaba bastante nervioso al principio porque era mi primera charla. Espero que todo haya salido bien y les haya gustado.
Bueno, finalizamos las actividades como a las 7:30 p.m. (hora local), luego de ello ayudamos a los muchachos a acomodar las cosas y guardarlas en las oficinas de Fundacite Mérida.
Desde mi punto de vista, ha sido una grata experiencia, cualquier corrección a la reseña es bienvenida, pido disculpas si he dejado a alguien por fuera, esta reseña no estaba anotada en ningún medio escrito, solo he comenzado a describir las situaciones que recuerdo, lo más seguro es que olvide algún detalle importante, andaba un poco distraído instalando Debian y Ubuntu en el Festival.
Por supuesto, cualquier corrección, crítica constructiva acerca de la charla que dí se los agradecería, todo sea por mejorar dicho material y publicarlo, por supuesto, manteniendo una licencia libre.
foro
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
framework
Charla: Desarrollo web en Python usando el framework Django
El profesor Jacinto Dávila, en el marco de actividades del Jueves Libre, me ha invitado a dar una charla sobre Desarrollo web en Python usando el framework Django para el día de mañana, 20 30 de noviembre de 2006, el sitio de la charla será en el salón OS-02 del edificio B de la facultad de ingeniería, sector La Hechicera, a partir de las 11:00 a.m.
Básicamente estaré conversando sobre nuevas metodologías de desarrollo Web, el uso de frameworks, ¿en realidad promueven mejores prácticas de desarrollo?, acerca del modelo MVC y el principio DRY (Don’t Repeat Yourself).
A manera de introducción les dejo lo siguiente.
Django es un framework de alto nivel escrito en el lenguaje de programación Python con el objetivo de garantizar desarrollos web rápidos y limpios, con un diseño pragmático.
Un framework orientado al desarrollo Web es un software que facilita la implantación de aquellas tareas tediosas que se encuentran al momento de la construcción de un sitio de contenido dinámico. Se abstraen problemas inherentes al desarrollo Web y se proveen atajos en la programación de tareas comunes.
Con Django, usted construirá sitios web en cuestion de horas, no días; semanas, no años. Cada una de las partes del framework Django ha sido diseñada con el concepto de productividad en mente.
Django sigue la arquitectura MVC (Modelo-Vista-Controlador), en términos simples, es una manera de desarrollo de software en donde el código para definir y acceder a los datos (el modelo) se encuentra separado de la lógica de negocios (el controlador), a su vez está separado de la interfaz de usuario (la vista).
El framework Django ha sido escrito en Python, un lenguaje de programación interpretado de alto nivel que es poderoso, dinámicamente tipado, conciso y expresivo. Para desarrollar un sitio usando Django, debemos escribir código en Python, haciendo uso de las librerías de Django.
Finalmente, Django mantiene de manera estricta a lo largo de su propio código un diseño limpio, y le hace seguir las mejores prácticas cuando se refiere al desarrollo de su aplicación Web.
En resumen, Django facilita el hacer las cosas de manera correcta.
Para finalizar, espero poder hacer una demostración en vivo, ya que el tiempo que dispongo no es mucho.
freeloader
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
gedit
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
glamour
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
gnickr
Gnickr: Gnome + Flickr
Gnickr le permite manejar las fotos de su cuenta del sitio Flickr como si fueran archivos locales de su escritorio Gnome. Todo lo anterior lo hace creando un sistema de ficheros virtual de su cuenta en Flickr.
Hasta ahora, Gnickr le permite realizar las siguientes operaciones:
- Subir fotos.
- Renombrar fotos y set de fotos.
- Borrar fotos.
- Insertar fotos en sets previamente creados.
- Eficiente subida de fotos, escala las imágenes a
1024 x 768
Se planea que en futuras versiones se pueda editar la descripción de cada foto, la creación/eliminación de sets de fotos, establecer las opciones de privacidad en cada una de las fotos, así como también integrar el proceso de autorización en nautilus.
Si desea instalar Gnickr, previamente debe cumplir con los siguientes requisitos.
- Gnome 2.12
- Python 2.4
- gnome-python >= 2.12.3
- Librería de imágenes de Python (PIL)
Instalando Gnickr en Ubuntu Breezy
En primer lugar debemos actualizar el paquete gnome-python (en ubuntu recibe el nombre de python2.4-gnome2) como mínimo a la versión 2.12.3, para ello descargamos el paquete python2.4-gnome2_2.12.1-0ubuntu2_i386.deb.
Seguidamente descargamos el paquete Gnickr-0.0.3 para Ubuntu Breezy. Una vez descargados los paquetes procedemos a instalar cada uno de ellos, para ello hacemos.
$ sudo dpkg -i python2.4-gnome2_2.12.1-0ubuntu2_i386.deb
$ sudo dpkg -i gnickr_0.0.3-1_i386.deb
Una vez que hemos instalado el paquete Gnickr para Ubuntu Breezy debemos autorizarlo en nuestra cuenta Flickr para que éste programa pueda manipular las fotos, para ello hacemos lo siguiente.
$ gnickr-auth.py
Simplemente debe seguiremos las instrucciones que nos indica el cuadro de dialogo. Una vez completado el proceso de autorización debe reiniciar nautilus.
$ pkill nautilus
Uso de Gnickr
El manejo de Gnickr es muy sencillo, para acceder a sus fotos en su cuenta Flickr simplemente apunte nautilus a flickr:///.
$ nautilus flickr:///
También puede ver las fotos de cualquier otra cuenta en Flickr apuntando a flickr://[nombreusuario].
Para agregar fotos a un set, simplemente arrastre desde la carpeta Unsorted hasta la carpeta que representa el set de fotos que usted desea, lo anterior también puede aplicarse para mover una foto de un set a otro.
Para renombrar una foto, simplemente modifique el nombre del fichero de la foto.
gnupg
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
goobuntu
Goobuntu, Google y los rumores…
Todo comenzo el día martes de esta misma semana, al ser publicado el artículo Google at work on desktop Linux en The Register, para mí todo aquello tenía la esencia de un nuevo rumor acerca Google, no en el sentido de utilizar una adaptación, denominada Goobuntu, de Ubuntu para las personas que laboran dentro de Google, sino en el hecho que el artículo enfatizaba la posibilidad de distribuir al público en general la adaptación de Ubuntu hecha por Google.
En el artículo mencionado al comienzo del párrafo anterior nos encontramos con afirmaciones tales como las siguientes:
Google is preparing its own distribution of Linux for the desktop, in a possible bid to take on Microsoft in its core business - desktop software.
Un poco más tarde nos encontramos con esto.
But it’s possible Google plans to distribute it to the general public, as a free alternative to Windows.
La posible distribución de “Goobuntu” al público fue desmentida pocas horas después de publicada la noticia, el responsable de proyectos open source de Google, Chris DiBona, lo aclara en este comentario hecho en Slashdot [Vía], en donde afirma lo siguiente:
Goobuntu is our internal desktop distribution. It’s awesome, but we’re not going to be releasing it. Unless you work here it wouldn’t work anyway.
Una de las cosas que me impresionó de todo esto, fué lo rápido que se extendió esta noticia. Estaba por todos lados, en los blogs que comúnmente leo, en Technorati, bajo el tag ubuntu, solo se hablaba de ello. Más y más sitios se unían rápidamente a este grupo.
Me da la impresión que cada vez que termina un rumor acerca del probable Google OS o Google Browser comienza uno nuevo, ¿esto acabará algún día?, ¿es sano adorar tanto a Google?, acaso Google es tan cool que le hace olvidar a las personas los malos productos que ha sacado últimamente, pareciese que sí.
Siguiendo con el tema, llegados a este punto, ¿alguien recuerda el lanzamiento de Google Analytics?, este servicio de estadísticas gratis para sitios web desde el mismo día de su lanzamiento no dejó de dar problemas, fué un total desastre, ¿era muy difícil prever que este servicio iba a tener una demanda excesiva?, no lo creo, su rendimiento daba lastima, los servidores estaban saturados, páginas en mantenimiento después del lanzamiento, ¿acaso Google estaba jugando con nosotros?.
Supongo que Google ha olvidado esa parte de la mercadotecnia en donde se logra satisfacer las necesidades y requisitos de los consumidores, al fin y al cabo es una empresa que intenta responder a una economía de mercado, pero lo está haciendo mal.
Google ha demostrado su interes en el escritorio, aplicaciones como Google Desktop Search, Google Talk, Google Earth, Google Pack dan fé de ello. No puedo dar mi opinión acerca de estas últimas aplicaciones, puesto que no los he probado al ser solo para sistemas Windows, pero con los antecedentes que se está ganando últimamente Google, pareciese que no hace falta probarlos para sacar una conclusión de ellos. Sebastian Delmont puede aclarar un poco esta situación en el artículo El paquete de Google decepciona.
Goobuntu, Google y los rumores…
Todo comenzo el día martes de esta misma semana, al ser publicado el artículo Google at work on desktop Linux en The Register, para mí todo aquello tenía la esencia de un nuevo rumor acerca Google, no en el sentido de utilizar una adaptación, denominada Goobuntu, de Ubuntu para las personas que laboran dentro de Google, sino en el hecho que el artículo enfatizaba la posibilidad de distribuir al público en general la adaptación de Ubuntu hecha por Google.
En el artículo mencionado al comienzo del párrafo anterior nos encontramos con afirmaciones tales como las siguientes:
Google is preparing its own distribution of Linux for the desktop, in a possible bid to take on Microsoft in its core business - desktop software.
Un poco más tarde nos encontramos con esto.
But it’s possible Google plans to distribute it to the general public, as a free alternative to Windows.
La posible distribución de “Goobuntu” al público fue desmentida pocas horas después de publicada la noticia, el responsable de proyectos open source de Google, Chris DiBona, lo aclara en este comentario hecho en Slashdot [Vía], en donde afirma lo siguiente:
Goobuntu is our internal desktop distribution. It’s awesome, but we’re not going to be releasing it. Unless you work here it wouldn’t work anyway.
Una de las cosas que me impresionó de todo esto, fué lo rápido que se extendió esta noticia. Estaba por todos lados, en los blogs que comúnmente leo, en Technorati, bajo el tag ubuntu, solo se hablaba de ello. Más y más sitios se unían rápidamente a este grupo.
Me da la impresión que cada vez que termina un rumor acerca del probable Google OS o Google Browser comienza uno nuevo, ¿esto acabará algún día?, ¿es sano adorar tanto a Google?, acaso Google es tan cool que le hace olvidar a las personas los malos productos que ha sacado últimamente, pareciese que sí.
Siguiendo con el tema, llegados a este punto, ¿alguien recuerda el lanzamiento de Google Analytics?, este servicio de estadísticas gratis para sitios web desde el mismo día de su lanzamiento no dejó de dar problemas, fué un total desastre, ¿era muy difícil prever que este servicio iba a tener una demanda excesiva?, no lo creo, su rendimiento daba lastima, los servidores estaban saturados, páginas en mantenimiento después del lanzamiento, ¿acaso Google estaba jugando con nosotros?.
Supongo que Google ha olvidado esa parte de la mercadotecnia en donde se logra satisfacer las necesidades y requisitos de los consumidores, al fin y al cabo es una empresa que intenta responder a una economía de mercado, pero lo está haciendo mal.
Google ha demostrado su interes en el escritorio, aplicaciones como Google Desktop Search, Google Talk, Google Earth, Google Pack dan fé de ello. No puedo dar mi opinión acerca de estas últimas aplicaciones, puesto que no los he probado al ser solo para sistemas Windows, pero con los antecedentes que se está ganando últimamente Google, pareciese que no hace falta probarlos para sacar una conclusión de ellos. Sebastian Delmont puede aclarar un poco esta situación en el artículo El paquete de Google decepciona.
google+evil
Goobuntu, Google y los rumores…
Todo comenzo el día martes de esta misma semana, al ser publicado el artículo Google at work on desktop Linux en The Register, para mí todo aquello tenía la esencia de un nuevo rumor acerca Google, no en el sentido de utilizar una adaptación, denominada Goobuntu, de Ubuntu para las personas que laboran dentro de Google, sino en el hecho que el artículo enfatizaba la posibilidad de distribuir al público en general la adaptación de Ubuntu hecha por Google.
En el artículo mencionado al comienzo del párrafo anterior nos encontramos con afirmaciones tales como las siguientes:
Google is preparing its own distribution of Linux for the desktop, in a possible bid to take on Microsoft in its core business - desktop software.
Un poco más tarde nos encontramos con esto.
But it’s possible Google plans to distribute it to the general public, as a free alternative to Windows.
La posible distribución de “Goobuntu” al público fue desmentida pocas horas después de publicada la noticia, el responsable de proyectos open source de Google, Chris DiBona, lo aclara en este comentario hecho en Slashdot [Vía], en donde afirma lo siguiente:
Goobuntu is our internal desktop distribution. It’s awesome, but we’re not going to be releasing it. Unless you work here it wouldn’t work anyway.
Una de las cosas que me impresionó de todo esto, fué lo rápido que se extendió esta noticia. Estaba por todos lados, en los blogs que comúnmente leo, en Technorati, bajo el tag ubuntu, solo se hablaba de ello. Más y más sitios se unían rápidamente a este grupo.
Me da la impresión que cada vez que termina un rumor acerca del probable Google OS o Google Browser comienza uno nuevo, ¿esto acabará algún día?, ¿es sano adorar tanto a Google?, acaso Google es tan cool que le hace olvidar a las personas los malos productos que ha sacado últimamente, pareciese que sí.
Siguiendo con el tema, llegados a este punto, ¿alguien recuerda el lanzamiento de Google Analytics?, este servicio de estadísticas gratis para sitios web desde el mismo día de su lanzamiento no dejó de dar problemas, fué un total desastre, ¿era muy difícil prever que este servicio iba a tener una demanda excesiva?, no lo creo, su rendimiento daba lastima, los servidores estaban saturados, páginas en mantenimiento después del lanzamiento, ¿acaso Google estaba jugando con nosotros?.
Supongo que Google ha olvidado esa parte de la mercadotecnia en donde se logra satisfacer las necesidades y requisitos de los consumidores, al fin y al cabo es una empresa que intenta responder a una economía de mercado, pero lo está haciendo mal.
Google ha demostrado su interes en el escritorio, aplicaciones como Google Desktop Search, Google Talk, Google Earth, Google Pack dan fé de ello. No puedo dar mi opinión acerca de estas últimas aplicaciones, puesto que no los he probado al ser solo para sistemas Windows, pero con los antecedentes que se está ganando últimamente Google, pareciese que no hace falta probarlos para sacar una conclusión de ellos. Sebastian Delmont puede aclarar un poco esta situación en el artículo El paquete de Google decepciona.
graph
El algoritmo de Dijkstra en Perl
Hace ya algunos días nos fué asignado en la cátedra de Redes de Computadoras encontrar el camino más corto entre dos vértices de un grafo dirigido que no tuviese costos negativos en sus arcos, para ello debíamos utilizar el algoritmo de Dijkstra. Además de ello, debía presentarse el grafo y la ruta más corta en una imagen, para visualizarlo de mejor manera.
Cuando un profesor te dice: No se preocupen por la implementación del algoritmo de Dijkstra, utilice la que usted prefiera, pero les agradezco que la analicen. Además, pueden utilizar el lenguaje de programación de su preferencia. Estas palabras te alegran el día, simplemente eres feliz.
Por algunos problemas que tuve con algunos módulos en Python, no lo hice en dicho lenguaje de programación, no vale la pena explicar en detalle los problemas que se me presentaron.
Lo importante de todo esto, es que asumí el reto de realizar la asignación en un lenguaje de programación practicamente nuevo para mí, aunque debo reconocer que la resolución no me causó dolores de cabezas en lo absoluto, a continuación algunos detalles.
En primer lugar, formularse las preguntas claves, ¿existe algún módulo en Perl que implemente el algoritmo de Dijkstra para encontrar el camino más corto?, ¿existe algún módulo en Perl que implemente GraphViz?
En segundo lugar, buscar en el lugar correcto, y cuando hablamos de Perl el sitio ideal para buscar es search.cpan.org, efectivamente, en cuestión de segundos encontre los dos módulos que me iban a facilitar la vida, Bio::Coordinate::Graph, para encontrar la ruta más corta entre dos vértices en un grafo y GraphViz, para pintar el grafo.
En tercer lugar, verificar en tu distro favorita, Debian, si existe un paquete precompilado listo pasa ser usado, para GraphViz existe uno, libgraphviz-perl, así que para instalarlo es tan fácil como:
# aptitude install libgraphviz-perl
Para instalar el módulo Bio::Coordinate::Graph, primero debía debianizarlo, eso es tan sencillo como hacer.
# dh-make-perl --build --cpan Bio::Coordinate::Graph
Luego debe proceder a instalar el fichero .deb que se generó con dh-make-perl, para lograrlo hago uso del comando dpkg, eso es todo. Por cierto, acerca del comando dh-make-perl ya había hablado en la entrada Perl: Primeras experiencias.
Encontrando el camino más corto
Según dice la documentación del módulo Bio::Coordinate::Graph debemos hacer uso de un hash de hashes anónimos para representar la estructura del grafo, en ese momento recordé algunas palabras que José Luis Rey nos comentó en la primera parte del curso de Perl, vale resalta la siguiente: Si usted no utiliza un hash, no lo está haciendo bien.
my $hash = {
'6' => undef,
'1' => {
'2' => 1
},
'2' => {
'6' => 4,
'4' => 1,
'3' => 1
},
'3' => {
'6' => 1
},
'4' => {
'5' => 1
},
'5' => undef
};Algo que es importante saber es que en Perl las estructuras de datos son planas, lo cual es conveniente. Por lo tanto, vamos a tener que utilizar referencias en este caso, pero luego nos preocuparemos por ello. Ahora solo resta decir que, la estructura hecha a través de un hash de hashes es sencilla de interpretar, las llaves o keys del hash principal representan los vértices del grafo, ahora bien, las llaves de los hashes más internos representan los vértices vecinos de cada vértice descrito en el hash principal, el valor de los hashes más internos representa el peso, distancia o costo que existe entre ambos vértices, para aclarar la situación un poco: El vértice 2, tiene como vecinos a los vértices 3, 4 y 6, con costos de 1, 1 y 4 respectivamente. Puede ver una muestra del grafo resultante.
De manera alternativa puede utilizar un hash de arrays para representar la estructura del grafo, siempre y cuando todos los costos entre los vértices sean igual a 1, este método es menos general que el anterior y además, este tipo de estructura es convertida a un hash de hashes, así que a la final resulta ineficiente.
Una vez definida la estructura del grafo corresponde crear el objeto, esto es realmente sencillo.
my $graph = Bio::Coordinate::Graph->new(-graph => $hash);Lo que resta es definir el vértice de inicio y el vértice final, yo los he definido en las variables $start y $end, luego de ello, debemos invocar al método shortest_path, de la siguiente manera:
my @path = $graph->shortest_path($start, $end);En el array @path encontraremos los vértices involucrados en el camino más corto.
Pintando el grafo
Una vez hallado el camino más corto entre dos vértices dados en un grafo dirigido con un costo en los arcos siempre positivos, lo que resta es hacer uso del módulo GraphViz, hacemos uso del constructor del objeto de la siguiente manera:
my $g = GraphViz->new();Usted puede invocar al constructor con distintos atributos, para saber cuales usar le recomiendo leer la documentación del módulo.
Ahora bien, yo quería distinguir aquellos vértices involucrados en el camino más corto de aquellos que no pertenecían, así que lo más sencillo es generar una lista de atributos que será usada posteriormente. Por ejemplo:
my @shortest_path_attrs = (
color => 'red',
);Una vez definidos los atributos, debemos generar cada uno de sus vértices y además, establecer los arcos entre cada uno de ellos. Para ello haremos uso de los métodos add_node, add_edge.
foreach my $key (keys %$hash){
$g->add_node($key);
foreach my $neighbor (keys %{$hash->{$key}}){
$g->add_edge($key => $neighbor, label => $hash->{$key}->{$neighbor});
}
}El bloque de código anterior lo que hace es agregar cada uno de los vértices que se encuentran en el hash que representa la estructura del grafo, para cada uno de estos vértices, se añade cada uno de los arcos que lo conectan con sus vecinos, nótese el manejo del operador flecha (->) para desreferenciar las referencias al hash de hashes anónimos.
Una vez construidos los nodos y sus arcos, ¿cómo reconocer aquellos que pertenecen al camino más corto?, bueno, toda esa información la podemos extraer del array que hemos denominado @path.
for (my $count=0; $count < = $#path; $count++){
$g->add_node($path[$count], @shortest_path_attrs);
$g->add_edge($path[$count] => $path[$count+1], @shortest_path_attrs) unless ($count+1 > $#path);
}Según dice la documentación del módulo GraphViz todos los atributos de un vértice del grafo no tienen que definirse de una sola vez, puede hacerse después, ya que las declaraciones sucesivas tienen efecto acumulativo, eso quiere decir lo siguiente:
$g->add_node('1', color => 'red');Es equivalente a hacer las siguientes declaraciones sucesivas.
$g->add_node('1');
$g->add_node('1', color => 'red');Lo que resta por hacer en este instante es exportar el objeto creado, puede crear por ejemplo un PNG, texto sin formato, PostScript, entre otros.
Yo decidí generar un fichero PostScript:
$g->as_ps("dijkstra.ps");Por supuesto, les dejo una muestra de los resultados. Los vértices cuyo borde es rojo, son aquellos involucrados en el camino más corto desde el vértice inicio al vértice final, los arcos que marcan la ruta más corta también han sido coloreados.
Como siempre, todas las recomendaciones, comentarios, sugerencias son bienvenidas.
graphviz
El algoritmo de Dijkstra en Perl
Hace ya algunos días nos fué asignado en la cátedra de Redes de Computadoras encontrar el camino más corto entre dos vértices de un grafo dirigido que no tuviese costos negativos en sus arcos, para ello debíamos utilizar el algoritmo de Dijkstra. Además de ello, debía presentarse el grafo y la ruta más corta en una imagen, para visualizarlo de mejor manera.
Cuando un profesor te dice: No se preocupen por la implementación del algoritmo de Dijkstra, utilice la que usted prefiera, pero les agradezco que la analicen. Además, pueden utilizar el lenguaje de programación de su preferencia. Estas palabras te alegran el día, simplemente eres feliz.
Por algunos problemas que tuve con algunos módulos en Python, no lo hice en dicho lenguaje de programación, no vale la pena explicar en detalle los problemas que se me presentaron.
Lo importante de todo esto, es que asumí el reto de realizar la asignación en un lenguaje de programación practicamente nuevo para mí, aunque debo reconocer que la resolución no me causó dolores de cabezas en lo absoluto, a continuación algunos detalles.
En primer lugar, formularse las preguntas claves, ¿existe algún módulo en Perl que implemente el algoritmo de Dijkstra para encontrar el camino más corto?, ¿existe algún módulo en Perl que implemente GraphViz?
En segundo lugar, buscar en el lugar correcto, y cuando hablamos de Perl el sitio ideal para buscar es search.cpan.org, efectivamente, en cuestión de segundos encontre los dos módulos que me iban a facilitar la vida, Bio::Coordinate::Graph, para encontrar la ruta más corta entre dos vértices en un grafo y GraphViz, para pintar el grafo.
En tercer lugar, verificar en tu distro favorita, Debian, si existe un paquete precompilado listo pasa ser usado, para GraphViz existe uno, libgraphviz-perl, así que para instalarlo es tan fácil como:
# aptitude install libgraphviz-perl
Para instalar el módulo Bio::Coordinate::Graph, primero debía debianizarlo, eso es tan sencillo como hacer.
# dh-make-perl --build --cpan Bio::Coordinate::Graph
Luego debe proceder a instalar el fichero .deb que se generó con dh-make-perl, para lograrlo hago uso del comando dpkg, eso es todo. Por cierto, acerca del comando dh-make-perl ya había hablado en la entrada Perl: Primeras experiencias.
Encontrando el camino más corto
Según dice la documentación del módulo Bio::Coordinate::Graph debemos hacer uso de un hash de hashes anónimos para representar la estructura del grafo, en ese momento recordé algunas palabras que José Luis Rey nos comentó en la primera parte del curso de Perl, vale resalta la siguiente: Si usted no utiliza un hash, no lo está haciendo bien.
my $hash = {
'6' => undef,
'1' => {
'2' => 1
},
'2' => {
'6' => 4,
'4' => 1,
'3' => 1
},
'3' => {
'6' => 1
},
'4' => {
'5' => 1
},
'5' => undef
};Algo que es importante saber es que en Perl las estructuras de datos son planas, lo cual es conveniente. Por lo tanto, vamos a tener que utilizar referencias en este caso, pero luego nos preocuparemos por ello. Ahora solo resta decir que, la estructura hecha a través de un hash de hashes es sencilla de interpretar, las llaves o keys del hash principal representan los vértices del grafo, ahora bien, las llaves de los hashes más internos representan los vértices vecinos de cada vértice descrito en el hash principal, el valor de los hashes más internos representa el peso, distancia o costo que existe entre ambos vértices, para aclarar la situación un poco: El vértice 2, tiene como vecinos a los vértices 3, 4 y 6, con costos de 1, 1 y 4 respectivamente. Puede ver una muestra del grafo resultante.
De manera alternativa puede utilizar un hash de arrays para representar la estructura del grafo, siempre y cuando todos los costos entre los vértices sean igual a 1, este método es menos general que el anterior y además, este tipo de estructura es convertida a un hash de hashes, así que a la final resulta ineficiente.
Una vez definida la estructura del grafo corresponde crear el objeto, esto es realmente sencillo.
my $graph = Bio::Coordinate::Graph->new(-graph => $hash);Lo que resta es definir el vértice de inicio y el vértice final, yo los he definido en las variables $start y $end, luego de ello, debemos invocar al método shortest_path, de la siguiente manera:
my @path = $graph->shortest_path($start, $end);En el array @path encontraremos los vértices involucrados en el camino más corto.
Pintando el grafo
Una vez hallado el camino más corto entre dos vértices dados en un grafo dirigido con un costo en los arcos siempre positivos, lo que resta es hacer uso del módulo GraphViz, hacemos uso del constructor del objeto de la siguiente manera:
my $g = GraphViz->new();Usted puede invocar al constructor con distintos atributos, para saber cuales usar le recomiendo leer la documentación del módulo.
Ahora bien, yo quería distinguir aquellos vértices involucrados en el camino más corto de aquellos que no pertenecían, así que lo más sencillo es generar una lista de atributos que será usada posteriormente. Por ejemplo:
my @shortest_path_attrs = (
color => 'red',
);Una vez definidos los atributos, debemos generar cada uno de sus vértices y además, establecer los arcos entre cada uno de ellos. Para ello haremos uso de los métodos add_node, add_edge.
foreach my $key (keys %$hash){
$g->add_node($key);
foreach my $neighbor (keys %{$hash->{$key}}){
$g->add_edge($key => $neighbor, label => $hash->{$key}->{$neighbor});
}
}El bloque de código anterior lo que hace es agregar cada uno de los vértices que se encuentran en el hash que representa la estructura del grafo, para cada uno de estos vértices, se añade cada uno de los arcos que lo conectan con sus vecinos, nótese el manejo del operador flecha (->) para desreferenciar las referencias al hash de hashes anónimos.
Una vez construidos los nodos y sus arcos, ¿cómo reconocer aquellos que pertenecen al camino más corto?, bueno, toda esa información la podemos extraer del array que hemos denominado @path.
for (my $count=0; $count < = $#path; $count++){
$g->add_node($path[$count], @shortest_path_attrs);
$g->add_edge($path[$count] => $path[$count+1], @shortest_path_attrs) unless ($count+1 > $#path);
}Según dice la documentación del módulo GraphViz todos los atributos de un vértice del grafo no tienen que definirse de una sola vez, puede hacerse después, ya que las declaraciones sucesivas tienen efecto acumulativo, eso quiere decir lo siguiente:
$g->add_node('1', color => 'red');Es equivalente a hacer las siguientes declaraciones sucesivas.
$g->add_node('1');
$g->add_node('1', color => 'red');Lo que resta por hacer en este instante es exportar el objeto creado, puede crear por ejemplo un PNG, texto sin formato, PostScript, entre otros.
Yo decidí generar un fichero PostScript:
$g->as_ps("dijkstra.ps");Por supuesto, les dejo una muestra de los resultados. Los vértices cuyo borde es rojo, son aquellos involucrados en el camino más corto desde el vértice inicio al vértice final, los arcos que marcan la ruta más corta también han sido coloreados.
Como siempre, todas las recomendaciones, comentarios, sugerencias son bienvenidas.
grub
GRUB: Mejorando nuestro gestor de arranque
Anteriormente había comentado en la primera entrega del artículo Debian: Bienvenido al Sistema Operativo Universal que por medidas de seguridad establezco las opciones de montaje ro, nodev, nosuid, noexec en la partición /boot, donde se encuentran los ficheros estáticos del gestor de arranque.
El gestor de arranque que manejo es GRUB. Por lo tanto, el motivo de este artículo es explicar como suelo personalizarlo, tanto para dotarle de seguridad como mejorar su presentación.
Seguridad
Lo primero que hago es verificar el dueño y los permisos que posee el fichero /boot/grub/menu.lst, en mi opinión la permisología más abierta y peligrosa sería 644, pero normalmente la establezco en 600, evitando de ese modo que todos los usuarios (excepto el dueño del fichero, que en este caso será root) puedan leer y escribir en dicho fichero. Para lograr esto recurrimos al comando chmod.
# chmod 600 /boot/grub/menu.lst
Si usted al igual que yo mantiene a /boot como una partición de solo lectura, deberá montar de nuevo la partición /boot estableciendo la opción de escritura, para lo cual hacemos:
# mount -o remount,rw /boot
Después de ello si podrá cambiar la permisología del fichero /boot/grub/menu.lst de ser necesario.
El segundo paso es evitar que se modifique de manera interactiva las opciones de inicio del kernel desde el gestor de arranque, para ello estableceremos una contraseña para poder editar dichas opciones, pero primero nos aseguraremos de cifrar esa contraseña con el algoritmo MD5. Por lo tanto, haremos uso de grub-md5-crypt
# grub-md5-crypt
Password:
Retype password:
$1$56z5r1$yMeSchRfnxdS3QDzLpovV1
La última línea es el resultado de aplicarle el algoritmo MD5 a nuestra contraseña, la copiaremos e inmediatamente procedemos a modificar de nuevo el fichero /boot/grub/menu.lst, el cual debería quedar más o menos como se muestra a continuación.
password --md5 $1$56z5r1$yMeSchRfnxdS3QDzLpovV1
title Debian GNU/Linux, kernel 2.6.18-3-686
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro
initrd /initrd.img-2.6.18-3-686
savedefault
title Debian GNU/Linux, kernel 2.6.18-3-686 (single-user mode)
root (hd0,1)
kernel /vmlinuz-2.6.18-3-686 root=/dev/sda1 ro single
initrd /initrd.img-2.6.18-3-686
savedefault
La instrucción password --md5 aplica a nivel global, así que cada vez que desee editar las opciones de inicio del kernel, tendrá que introducir la clave (deberá presionar la tecla p para que la clave le sea solicitada) que le permitirá editar dichas opciones.
Presentación del gestor de arranque
A muchos quizá no les agrade el aspecto inicial que posee el GRUB, una manera de personalizar la presentación de nuestro gestor de arranque puede ser la descrita en la segunda entrega de la entrada Debian: Bienvenido al Sistema Operativo Universal en donde instalaba el paquete grub-splashimages y posteriormente establecía un enlace simbólico, el problema de esto es que estamos limitados a las imágenes que trae solo ese paquete.
A menos que a usted le guste diseñar sus propios fondos, puede usar los siguientes recursos:
Después de escoger la imagen que servirá de fondo para el gestor de arranque, la descargamos y la colocamos dentro del directorio /boot/grub/, una vez allí procedemos a modificar el fichero /boot/grub/menu.lst y colocaremos lo siguiente:
splashimage=(hd0,1)/grub/debian.xpm.gz
En la línea anterior he asumido lo siguiente:
- La imagen que he colocado dentro del directorio
/boot/grub/lleva por nombredebian.xpm.gz -
He ajustado la ubicación de mi partición
/boot, es probable que en su caso sea diferente, para obtener dicha información puede hacerlo al leer la tabla de particiones confdisk -lo haciendo uso del comandomount.$ mount | grep /boot /dev/sda2 on /boot type ext2 (rw,noexec,nosuid,nodev)
fdisk -l | grep ^/dev/sda2
/dev/sda2 1217 1226 80325 83 Linux
Por lo tanto, la ubicación de la partición /boot es en el primer disco duro, en la segunda partición, recordando que la notación en el grub comienza a partir de cero y no a partir de uno, tenemos como resultado hd0,1.
También puede darse el caso que ninguno de los fondos para el gestor de arranque mostrados en los recursos señalados previamente sean de su agrado. En ese caso, puede que le sirva el siguiente video demostrativo sobre como convertir un fondo de escritorio en un Grub Splash Image (2 MB) haciendo uso de The Gimp, espero le sea útil.
Después de personalizar el fichero /boot/grub/menu.lst recuerde ejecutar el comando update-grub como superusuario para actualizar las opciones.
grunt
Grunt: The Javascript Task Manager
When you play the Web Developer role, sometimes you may have to endure some repetitive tasks like minification, unit testing, compilation, linting, beautify or unpack Javascript code and so on. To solve this problems, and in the meantime, try to keep your mental health in a good shape, you desperately need to find a way to automate this tasks. Grunt offers you an easy way to accomplish this kind of automation.
gulmer
Enviando correos con Perl
Regularmente los administradores de sistemas requieren notificar, vía correo electrónico, a sus usuarios de ciertos cambios o nuevos servicios disponibles. La experiencia me ha indicado que el usuario aprecia más un correo personalizado que uno general. Sin embargo, lograr lo primero de manera manual es bastante tedioso e ineficaz. Por lo tanto, es lógico pensar en la posibilidad de automatizar el proceso de envío de correos electrónicos personalizados, en este artículo, explicaré una de las tantas maneras de lograrlo haciendo uso del lenguaje de programación Perl.
En CPAN podrá encontrar muchas alternativas, recuerde el
principio
TIMTOWTDI.
Sin embargo, la opción que más me atrajo fue MIME::Lite:TT, básicamente este
módulo en Perl es un wrapper de MIME::Lite que le permite el uso de
plantillas, vía Template::Toolkit, para el cuerpo del mensaje del correo
electrónico. También puede encontrar MIME::Lite::TT::HTML que le permitirá
enviar correos tanto en texto sin formato (MIME::Lite::TT) como en formato
HTML. Sin embargo, estoy en contra de enviar correos en formato HTML, lo dejo a
su criterio.
Una de las ventajas de utilizar Template::Toolkit para el cuerpo del mensaje
es separar en capas nuestra script, si se observa desde una versión muy
simplificada del patrón
MVC, el
control de la lógica de programación reside en el script en Perl, la plantilla
basada en Template Toolkit ofrecería la vista de los datos, de modo tal que
podríamos garantizar que la presentación está separada de los datos, los cuales
pueden encontrarse desde una base de datos o un simple fichero CSV. Otra ventaja
evidente es el posible reuso de componentes posteriormente.
Un primer ejemplo del uso de MIME::Lite:TT puede ser el siguiente:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
my %params;
$params{first_name} = "Milton";
$params{last_name} = "Mazzarri";
$params{username} = "milmazz";
$params{groups} = "sysadmin";
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => '[email protected]',
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();Y el cuerpo del correo electrónico, lo que en realidad es una plantilla basada
en Template::Toolkit, vendría definido en el fichero example.txt.tt de la
siguiente manera:
Hola [% last_name %], [% first_name %].
Tu nombre de usuario es [% username %].
Un saludo, feliz día.
Su querido BOFH de siempre.En el script en Perl mostrado previamente podemos percatarnos que los datos del destinario se encuentran inmersos en la lógica. Por lo tanto, el siguiente paso sería desacoplar esta parte de la siguiente manera:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Class::CSV;
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => '[email protected]',
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
$msg->send();
}Ahora los datos de los destinarios los extraemos de un fichero en formato CSV,
en este ejemplo, el fichero en formato CSV lo hemos denominado example.csv.
Cabe aclarar que $msg->send() realiza el envío por medio de Net::SMTP y
podrá usar las opciones que se describen en dicho módulo. Sin embargo, si
necesita establecer una conexión SSL con el servidor SMTP es oportuno recurrir a
Net::SMTP::SSL:
#!/usr/bin/perl
use strict;
use warnings;
use MIME::Lite::TT;
use Net::SMTP::SSL;
use Class::CSV;
my $from = '[email protected]';
my $host = 'mail.example.com';
my $user = 'jdoe';
my $pass = 'example';
my %options;
$options{INCLUDE_PATH} = '/home/jdoe/example';
# Lectura del fichero CSV
my $csv = Class::CSV->parse(
filename => 'example.csv',
fields => [qw/last_name first_name username email/],
csv_xs_options => { binary => 1, }
);
foreach my $line ( @{ $csv->lines() } ) {
my %params;
$params{first_name} = $line->first_name();
$params{last_name} = $line->last_name();
$params{username} = $line->username();
my $msg = MIME::Lite::TT->new(
From => $from,
To => $line->email(),
Charset => 'utf8',
TimeZone => 'America/Caracas',
Subject => 'Example',
Template => 'example.txt.tt',
TmplOptions => \%options,
TmplParams => \%params,
);
my $smtp = Net::SMTP::SSL->new( $host, Port => 465 )
or die "No pude conectarme";
$smtp->auth( $user, $pass )
or die "No pude autenticarme:" . $smtp->message();
$smtp->mail($from) or die "Error:" . $smtp->message();
$smtp->to( $line->email() ) or die "Error:" . $smtp->message();
$smtp->data() or die "Error:" . $smtp->message();
$smtp->datasend( $msg->as_string ) or die "Error:" . $smtp->message();
$smtp->dataend() or die "Error:" . $smtp->message();
$smtp->quit() or die "Error:" . $smtp->message();
}Note en este último ejemplo que la representación en cadena de caracteres del
cuerpo del correo electrónico viene dado por $msg->as_string.
Para finalizar, es importante mencionar que también podrá adjuntar ficheros de
cualquier tipo a sus correos electrónicos, solo debe prestar especial atención
en el tipo MIME de los ficheros que adjunta, es decir, si enviará un fichero
adjunto PDF debe utilizar el tipo application/pdf, si envía una imagen en el
formato GIF, debe usar el tipo image/gif. El método a seguir para adjuntar uno
o más ficheros lo dejo para su investigación ;)
hardware
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
html
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
hwinfo
hwinfo: Detectando el hardware actual
hwinfo es un programa que nos permite conocer rápidamente el hardware detectado actualmente en nuestros ordenadores, por ejemplo, si deseamos obtener los datos de dispositivo SCSI, simplemente utilizamos el comando hwinfo --scsi.
Para instalar este programa en Ubuntu Linux en primer lugar debemos tener activados el repositorio universe, seguidamente haremos uso de aptitude, tal cual como sigue:
$ sudo aptitude install hwinfo
Si deseamos conocer el uso de este programa de manera detallada, simplemente escribimos hwinfo --help.
En el caso que haga uso del comando hwinfo sin parámetro alguno nos mostrará la lista completa del hardware detectado actualmente, es importante resaltar que esta lista puede ser muy extensa, por lo cual le recomiendo hacer uso de un pipe para administrar la salida generada por hwinfo y poder visualizarla página a página, tal cual como sigue.
$ hwinfo | less
Si por el contrario, usted solo desea conocer una lista resumida del hardware detectado haga uso del parámetro --short, lo anterior quedaría de la siguiente manera:
$ hwinfo --short
Este programa nos brinda bastantes opciones, es recomendable hacer uso de los parámetros cuando necesitamos información referente a un dispositivo en específico, por ejemplo, si deseamos conocer la información acerca de la tarjeta de sonido, hacemos lo siguiente:
$ hwinfo --sound
Como le mencione anteriormente, para conocer en detalle las opciones que nos brinda este programa, le recomiendo leer el manual. Espero sea de provecho ;)
icons
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
ifdown
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
ifup
Configurando nuestras interfaces de red con ifupdown
Si usted es de esas personas que suele mover su máquina portátil entre varias redes que no necesariamente proveen DHCP y usualmente vuelve a configurar sus preferencias de conexión, seguramente este artículo llame su atención puesto que se explicará acerca de la configuración de diversos perfiles de conexión vía línea de comandos.
En los sistemas Debian y los basados en él, Ubuntu por ejemplo, para lograr la configuración de las redes existe una herramienta de alto nivel que consiste en los comandos ifup e ifdown, adicionalmente se cuenta con el fichero de configuración /etc/network/interfaces. También el paquete wireless-tools incluye un script en /etc/network/if-pre-up.d/wireless-tools que hace posible preparar el hardware de la interfaz inalámbrica antes de darla de alta, dicha configuración se hace a través del comando iwconfig.
Para hacer uso de las ventajas que nos ofrece la herramienta de alto nivel ifupdown, en primer lugar debemos editar el fichero /etc/network/interfaces y establecer nuestros perfiles de la siguiente manera:
auto lo
iface lo inet loopback
# Conexión en casa usando WPA
iface home inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-keymgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
# Conexión en la oficina
# sin DHCP
iface office inet static
wireless-essid bar
wireless-key s:egg
address 192.168.1.97
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-search company.com #[email protected]
dns-nameservers 192.168.1.2 192.168.1.3 #[email protected]
# Conexión en reuniones
iface meeting inet dhcp
wireless-essid ham
wireless-key s:jam
En este ejemplo se encuentran 3 configuraciones particulares (home, work y meeting), la primera de ellas define que nos vamos a conectar con un Access Point cuyo ssid es foo con un tipo de cifrado WPA-PSK/WPA2-PSK, esto fue explicado en detalle en el artículo Haciendo el cambio de ipw3945 a iwl3945. La segunda configuración indica que nos vamos a conectar a un Access Point con una IP estática y configuramos los parámetros search y nameserver del fichero /etc/resolv.conf (para más detalle lea la documentación del paquete resolvconf). Finalmente se define una configuración similar a la anterior, pero en este caso haciendo uso de DHCP.
Llegados a este punto es importante aclarar lo que ifupdown considera una interfaz lógica y una interfaz física. La interfaz lógica es un valor que puede ser asignado a los parámetros de una interfaz física, en nuestro caso home, office, meeting. Mientras que la interfaz física es lo que propiamente conocemos como la interfaz, en otras palabras, lo que regularmente el kernel reconoce como eth0, wlan0, ath0, ppp0, entre otros.
Como puede verse en el ejemplo previo las definiciones adyacentes a iface hacen referencia a interfaces lógicas, no a interfaces físicas.
Ahora bien, para dar de alta la interfaz física wlan0 haciendo uso de la interfaz lógica home, como superusuario puede hacer lo siguiente:
# ifup wlan0=home
Si usted ahora necesita reconfigurar la interfaz física wlan0, pero en este caso particular haciendo uso de la interfaz lógica work, primero debe dar de baja la interfaz física wlan0 de la siguiente manera:
# ifdown wlan0
Seguidamente deberá ejecutar el siguiente comando:
# ifup wlan0=work
Es importante hacer notar que tal como está definido ahora el fichero /etc/network/interfaces ya no es posible dar de alta la interfaz física wlan0 ejecutando solamente lo siguiente:
ifup wlan0
La razón de este comportamiento es que el comando ifup utiliza el nombre de la interfaz física como el nombre de la interfaz lógica por omisión y evidentemente ahora no está definido en el ejemplo un nombre de interfaz lógica igual a wlan0.
En un próximo artículo se harán mejoras en la definición del fichero /etc/network/interfaces y su respectiva integración con una herramienta para la detección de redes que tome como entrada una lista de perfiles de redes candidatas, cada una de ellas incluyendo casos de pruebas. Teniendo esto como entrada ya no será necesario indicar la interfaz lógica a la que se hace referencia ya que la herramienta se encargará de probar todos los perfiles en paralelo y elegirá aquella que cumpla en primera instancia con los casos de prueba. De modo tal que ya podremos dar de alta nuestra interfaz física con solo hacer ifup wlan0.
inkscape
Propuesta de diseño para Planeta Linux
En estos últimos días he estado trabajando en mi propuesta de diseño para Planeta Linux, sitio del cual escribí previamente en la entrada acerca de Planeta Linux, hasta ahora considero que está bastante avanzado el diseño.
A continuación, algunos detalles acerca del por qué y el cómo del trabajo realizado hasta ahora.
La estructura del diseño
La estructura del diseño es bastante sencilla, consiste en 3 partes:
- Cabecera
- Contenido
- Pie de página
Hasta ahora el pie de página presenta cierta redundancia de datos, puesto que la documentación que se ubicará en la página principal aún no está completa (que conste que no es una medida de presión para Damog).
El modo en el cual se presenta la información pretende darle prioridad al contenido expuesto por cada uno de los miembros del Planeta Linux, facilitándole la tarea al lector, es decir, encontrar la información que él desea en el menor tiempo posible, esto es de suma importancia en estos tiempos tan agitados.
Se le ha agregado cierta presencia al pie de página, pero no tanta como a la sección de contenido; la funcionalidad del pie de página ahora reemplaza al uso de la común barra lateral. Regularmente el pie de página es ocupado solo para mostrar notas sin mayor relevancia y el copyright que aplique, en esta propuesta, las cosas cambian un poco.
¿Qué herramientas he utilizado?
Todo el trabajo se ha realizado usando herramientas libres, entre ellas sobresalen:
Respecto a los iconos
Los iconos que he usado hasta ahora se encuentran en la serie Silk, la cual cuenta con más de 700 iconos de 16x16 pixels en formato PNG, estos iconos están bajo la licencia Creative Commons Attribution 2.5 License.
Para las banderas que se muestran en la barra de navegación de la cabecera, he usado la serie Flag, ésta serie cuenta con 239 banderas, tanto en formato GIF como PNG, se pueden utilizar libremente para cualquier propósito.
También he utilizado el set de íconos nuoveXT, el cual provee una completa gama de iconos tanto para GNOME como KDE.
Ya para finalizar la sección de los iconos, Damog hizo bien al recomendarme el set de iconos propuesto en Tango Desktop Project.
TODO (cosas por hacer)
- Hacer que el contenido se ajuste a un determinado porcentaje de la resolución de la pantalla, para aprovechar el espacio en resoluciones muy altas.
-
Eliminar el efecto scroll. Se ha eliminado en la versión 0.2 - Mejorar la barra de navegación de la cabecera.
- Diseñar un logo decente, quizá Jonathan Hernández (líder del proyecto Jaws) nos ayude en esto, según contaba Damog en la lista de correos de Planeta Linux.
- ¿Sería conveniente colocar el URI del feed del autor correspondiente en su campo de información?, la cual está ubicada antes de cada globo de dialógo.
Por supuesto, cualquier actividad que haga falta será añadida a la lista de cosas por hacer
Cualquier sugerencia, corrección, comentario es bienvenido.
instalinux
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
intel
Haciendo el cambio de ipw3945 a iwl3945
Si usted es de esas personas que cuenta con una tarjeta inalámbrica Intel Corporation PRO/Wireless 3945, seguramente sabrá que existen al menos dos proyectos que le dan soporte. El primero de ellos es ipw3945 y se encuentra obsoleto, el desarrollo pasó al proyecto iwlwifi.
Aprovechando que recientemente ha ingresado a la versión inestable de Debian la serie del kernel 2.6.24, este contiene el nuevo modulo iwl3945 que reemplaza al viejo ipw3945. Una de las ventajas de este cambio es que ya no hay necesidad de tener activo el demonio ipw3945d. Sin embargo, aun se necesita del firmware que se encuentra en la sección non-free del repositorio de Debian.
Hasta donde he leído el plan será remover los paquetes ipw3945-modules-* e ipw3945d de los repositorios de Debian (al menos en testing y en unstable) una vez que la serie 2.6.24 del kernel llegue a la versión de pruebas (testing). Aquellos que se encuentren hoy día en la versión inestable (unstable) de Debian deberán cambiar el driver desde ipw3945 a iwl3945. Para aquellos que trabajan en etch también es posible usar el driver iwl3945 si actualiza su versión del kernel por medio del repositorio etch-backports (el nuevo stack mac80211 que usa iwlwifi se encuentra a partir de la versión del kernel 2.6.22).
Las instrucciones que verá a continuación se han aplicado en Debian inestable, si usted desea instalar iwlwifi en etch puede seguir estas instrucciones.
Obteniendo algunos datos de interés antes de proceder con la actualización.
Versión del kernel:
$ uname -r
2.6.22-3-686
Verifique que en realidad tiene una tarjeta Intel Corporation PRO/Wireless 3945 $ lspci -nn | grep Wireless 03:00.0 Network controller [0280]: Intel Corporation PRO/Wireless 3945ABG Network Connection [8086:4227] (rev 02)
Paquetes necesarios
Ahora bien, es necesario instalar el nuevo kernel y el firmware necesario para hacer funcionar a iwlwifi
# aptitude install linux-image-2.6-686 \\
linux-image-2.6.24-1-686 \\
firmware-iwlwifi
Evitando problemas
Verifique que no existe alguna entrada que haga referencia al modulo ipw3945 en el fichero /etc/modules. Para ello recurrimos a Perl que nos facilita la vida.
# perl -i -ne 'print unless /^ipw3945/' /etc/modules
Debido a algunos problemas que se presentan en el paquete network-manager si anteriormente ha venido usando el modulo ipw3945 se recomienda eliminar la entrada que genera udev para dicho modulo en el fichero /etc/udev/rules.d/z25_persistent-net.rules, la entrada es similar a la siguiente:
# PCI device 0x8086:0x4227 (ipw3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTRS{address}=="00:13:02:4c:12:12", NAME="eth2"
Fichero /etc/network/interfaces
Este paso es opcional, agregamos la nueva interfaz wlan0 al fichero /etc/network/interfaces y procedemos a configurarla de acuerdo a nuestras necesidades.
auto lo
iface lo inet loopback
auto wlan0
iface wlan0 inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-key-mgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
En este caso particular se está indicando que nos vamos a conectar a un Access Point cuyo ssid es foo con tipo de cifrado WPA-PSK/WPA2-PSK, haciendo uso del driver wext que funciona como backend para wpa_supplicant. Es de hacer notar que el driver wext es utilizado por todos los adaptadores Intel Pro Wireless, eso incluye ipw2100, ipw2200 e ipw3945.
Para hacer funcionar WPA recuerde que debe haber instalado previamente el paquete wpasupplicant.
# aptitude install wpasupplicant
De igual manera se le recuerda adaptar todos aquellos parámetros como wpa-ssid y wpa-psk a aquellos adecuados en su caso. En particular el campo wpa-psk lo puede generar con el siguiente comando:
$ wpa_passphrase su_ssid su_passphrase
Aunque mi recomendación es usar el comando wpa_passphrase de la siguiente manera.
$ wpa_passphrase su_ssid
Posteriormente deberá introducir su_passphrase desde la entrada estándar, esto evitará que su_passphrase quede en el historial de comandos.
Para mayor detalle de los campos expuestos en la configuración del fichero /etc/network/interfaces se le recomienda leer la documentación expuesta en /usr/share/doc/wpasupplicant/README.modes.gz.
Una vez concluidos estos pasos reiniciamos el sistema y seleccionamos en nuestro Gestor de Arranque (ej. GRUB) la versión del kernel recien instalada. Al momento de iniciar su sesión verifique que su tarjeta inalámbrica esté funcionando, de lo contrario haga las revisiones que se indican en la siguiente sección.
En caso de persistir los problemas
Remueva y reinserte el modulo iwl3945
# modprobe -r iwl3945
# modprobe iwl3945
De manera adicional compruebe que udev haya generado una nueva entrada para iwl3945.
$ cat /etc/udev/rules.d/z25_persistent-net.rules
...
# PCI device 0x8086:0x4227 (iwl3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTR{address}=="00:13:02:4c:12:12", ATTR{type}=="1", NAME="wlan0"
Finalmente, reestablecemos la interfaz de red.
# ifdown wlan0
# ifup wlan0
Elimine ipw3945
Una vez verificado el correcto funcionamiento del módulo iwl3945 puede eliminar con seguridad todo aquello relacionado con el modulos ipw3945.
# aptitude --purge remove firmware-ipw3945 \\
ipw3945-modules-$(uname -r) \\
ipw3945-source ipw3945d
Estas instrucciones también aplican para el modulo iwl4965. Mayor información en Debian Wiki § iwlwifi.
ipw3945
Haciendo el cambio de ipw3945 a iwl3945
Si usted es de esas personas que cuenta con una tarjeta inalámbrica Intel Corporation PRO/Wireless 3945, seguramente sabrá que existen al menos dos proyectos que le dan soporte. El primero de ellos es ipw3945 y se encuentra obsoleto, el desarrollo pasó al proyecto iwlwifi.
Aprovechando que recientemente ha ingresado a la versión inestable de Debian la serie del kernel 2.6.24, este contiene el nuevo modulo iwl3945 que reemplaza al viejo ipw3945. Una de las ventajas de este cambio es que ya no hay necesidad de tener activo el demonio ipw3945d. Sin embargo, aun se necesita del firmware que se encuentra en la sección non-free del repositorio de Debian.
Hasta donde he leído el plan será remover los paquetes ipw3945-modules-* e ipw3945d de los repositorios de Debian (al menos en testing y en unstable) una vez que la serie 2.6.24 del kernel llegue a la versión de pruebas (testing). Aquellos que se encuentren hoy día en la versión inestable (unstable) de Debian deberán cambiar el driver desde ipw3945 a iwl3945. Para aquellos que trabajan en etch también es posible usar el driver iwl3945 si actualiza su versión del kernel por medio del repositorio etch-backports (el nuevo stack mac80211 que usa iwlwifi se encuentra a partir de la versión del kernel 2.6.22).
Las instrucciones que verá a continuación se han aplicado en Debian inestable, si usted desea instalar iwlwifi en etch puede seguir estas instrucciones.
Obteniendo algunos datos de interés antes de proceder con la actualización.
Versión del kernel:
$ uname -r
2.6.22-3-686
Verifique que en realidad tiene una tarjeta Intel Corporation PRO/Wireless 3945 $ lspci -nn | grep Wireless 03:00.0 Network controller [0280]: Intel Corporation PRO/Wireless 3945ABG Network Connection [8086:4227] (rev 02)
Paquetes necesarios
Ahora bien, es necesario instalar el nuevo kernel y el firmware necesario para hacer funcionar a iwlwifi
# aptitude install linux-image-2.6-686 \\
linux-image-2.6.24-1-686 \\
firmware-iwlwifi
Evitando problemas
Verifique que no existe alguna entrada que haga referencia al modulo ipw3945 en el fichero /etc/modules. Para ello recurrimos a Perl que nos facilita la vida.
# perl -i -ne 'print unless /^ipw3945/' /etc/modules
Debido a algunos problemas que se presentan en el paquete network-manager si anteriormente ha venido usando el modulo ipw3945 se recomienda eliminar la entrada que genera udev para dicho modulo en el fichero /etc/udev/rules.d/z25_persistent-net.rules, la entrada es similar a la siguiente:
# PCI device 0x8086:0x4227 (ipw3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTRS{address}=="00:13:02:4c:12:12", NAME="eth2"
Fichero /etc/network/interfaces
Este paso es opcional, agregamos la nueva interfaz wlan0 al fichero /etc/network/interfaces y procedemos a configurarla de acuerdo a nuestras necesidades.
auto lo
iface lo inet loopback
auto wlan0
iface wlan0 inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-key-mgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
En este caso particular se está indicando que nos vamos a conectar a un Access Point cuyo ssid es foo con tipo de cifrado WPA-PSK/WPA2-PSK, haciendo uso del driver wext que funciona como backend para wpa_supplicant. Es de hacer notar que el driver wext es utilizado por todos los adaptadores Intel Pro Wireless, eso incluye ipw2100, ipw2200 e ipw3945.
Para hacer funcionar WPA recuerde que debe haber instalado previamente el paquete wpasupplicant.
# aptitude install wpasupplicant
De igual manera se le recuerda adaptar todos aquellos parámetros como wpa-ssid y wpa-psk a aquellos adecuados en su caso. En particular el campo wpa-psk lo puede generar con el siguiente comando:
$ wpa_passphrase su_ssid su_passphrase
Aunque mi recomendación es usar el comando wpa_passphrase de la siguiente manera.
$ wpa_passphrase su_ssid
Posteriormente deberá introducir su_passphrase desde la entrada estándar, esto evitará que su_passphrase quede en el historial de comandos.
Para mayor detalle de los campos expuestos en la configuración del fichero /etc/network/interfaces se le recomienda leer la documentación expuesta en /usr/share/doc/wpasupplicant/README.modes.gz.
Una vez concluidos estos pasos reiniciamos el sistema y seleccionamos en nuestro Gestor de Arranque (ej. GRUB) la versión del kernel recien instalada. Al momento de iniciar su sesión verifique que su tarjeta inalámbrica esté funcionando, de lo contrario haga las revisiones que se indican en la siguiente sección.
En caso de persistir los problemas
Remueva y reinserte el modulo iwl3945
# modprobe -r iwl3945
# modprobe iwl3945
De manera adicional compruebe que udev haya generado una nueva entrada para iwl3945.
$ cat /etc/udev/rules.d/z25_persistent-net.rules
...
# PCI device 0x8086:0x4227 (iwl3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTR{address}=="00:13:02:4c:12:12", ATTR{type}=="1", NAME="wlan0"
Finalmente, reestablecemos la interfaz de red.
# ifdown wlan0
# ifup wlan0
Elimine ipw3945
Una vez verificado el correcto funcionamiento del módulo iwl3945 puede eliminar con seguridad todo aquello relacionado con el modulos ipw3945.
# aptitude --purge remove firmware-ipw3945 \\
ipw3945-modules-$(uname -r) \\
ipw3945-source ipw3945d
Estas instrucciones también aplican para el modulo iwl4965. Mayor información en Debian Wiki § iwlwifi.
iso
Construyendo de manera efectiva y rápida imágenes ISO de Debian con jigdo
Si usted desea el conjunto de CD o DVD para instalar Debian, tiene muchas posibilidades, desde la compra de los mismos, muchos de los vendedores contribuyen con Debian. También puede realizar descargas vía HTTP/FTP, vía torrent o rsync. Pero en este artículo se discutirá sobre un método para construir las imágenes ISO de Debian de manera eficiente, sobretodo si cuenta con un repositorio local de paquetes, dicho método se conoce de manera abreviada como jigdo o Jigsaw Download.
Las ventajas que ofrece jigdo están bien claras en el portal de Debian, cito:
¿Por qué jigdo es mejor que una descarga directa?
¡Porque es más rápido! Por varias razones, hay muchas menos réplicas para imágenes de CDs que para el archivo «normal» de Debian. Consecuentemente, si descarga desde una réplica de imágenes de CD, esa réplica no sólo estará más lejos de su ubicación, además estará sobrecargada, especialmente justo después de una publicación.
Además, algunos tipos de imágenes no están disponibles para descarga completa como .iso porque no hay suficiente espacio en nuestros servidores para alojarlas.
Considero que la pregunta pertinente ahora es: ¿Cómo descargo la imagen con jigdo?.
En primer lugar, instalamos el paquete jigdo-file.
# aptitude install jigdo-file
Mi objetivo era generar los 2 primeros CD para Debian Lenny, para la fecha de publicación de este artículo la versión más reciente es la 5.0.7. La lista de imágenes oficiales para jigdo las puede encontrar acá.
milmazz@manaslu /tmp $ cat files
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.template
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.template
milmazz@manaslu /tmp $ wget -c -i files
--2010-12-02 12:39:52-- http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
Resolving cdimage.debian.org... 130.239.18.163, 130.239.18.173, 2001:6b0:e:2018::173, ...
Connecting to cdimage.debian.org|130.239.18.163|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 31737 (31K) [text/plain]
Saving to: `debian-507-i386-CD-1.jigdo'
100%[===================================================================================================================>] 31.737 44,7K/s in 0,7s
...
FINISHED --2010-12-02 12:50:15--
Downloaded: 4 files, 27M in 10m 21s (44,7 KB/s)
milmazz@manaslu /tmp $ ls
debian-507-i386-CD-1.jigdo debian-507-i386-CD-1.template debian-507-i386-CD-2.jigdo debian-507-i386-CD-2.template files
Una vez descargados los ficheros necesarios, es hora de ejecutar el comando
jigdo-lite, siga las instrucciones del asistente.
milmazz@manaslu ~ $ jigdo-lite debian-507-i386-CD-2.jigdo
Jigsaw Download "lite"
Copyright (C) 2001-2005 | jigdo@
Richard Atterer | atterer.net
Loading settings from `/home/milmazz/.jigdo-lite'
-----------------------------------------------------------------
Images offered by `debian-507-i386-CD-2.jigdo':
1: 'Debian GNU/Linux 5.0.7 "Lenny" - Official i386 CD Binary-2 20101127-16:55 (20101127)' (debian-507-i386-CD-2.iso)
Further information about `debian-507-i386-CD-2.iso':
Generated on Sat, 27 Nov 2010 17:02:14 +0000
-----------------------------------------------------------------
If you already have a previous version of the CD you are
downloading, jigdo can re-use files on the old CD that are also
present in the new image, and you do not need to download them
again. Mount the old CD ROM and enter the path it is mounted under
(e.g. `/mnt/cdrom').
Alternatively, just press enter if you want to start downloading
the remaining files.
Files to scan:
El comando despliega información acerca de la imagen ISO que generará, en este
caso particular, debian-507-i386-CD-2.iso. Además, jigdo-lite puede
reutilizar ficheros que se encuentren en CD viejos y así no tener que
descargarlos de nuevo. Sin embargo, este no era mi caso así que presione la
tecla ENTER.
-----------------------------------------------------------------
The jigdo file refers to files stored on Debian mirrors. Please
choose a Debian mirror as follows: Either enter a complete URL
pointing to a mirror (in the form
`ftp://ftp.debian.org/debian/'), or enter any regular expression
for searching through the list of mirrors: Try a two-letter
country code such as `de', or a country name like `United
States', or a server name like `sunsite'.
Debian mirror [http://debian.example.com/debian/]:
En esta fase jigdo-lite solicita la dirección URL completa de un
repositorio, aproveche la oportunidad de utilizar su repositorio local si es que
cuenta con uno. Luego de presionar la tecla ENTER es tiempo de relajarse y
esperar que jigdo descargue todos y cada uno de los ficheros que componen la
imagen ISO.
Luego de descargar los paquetes y realizar las operaciones necesarias para la
construcción de la imagen ISO jigdo le informará los resultados.
FINISHED --2010-12-01 14:43:50--
Downloaded: 6 files, 2,5M in 1,8s (1,39 MB/s)
Found 6 of the 6 files required by the template
Successfully created `debian-507-i386-CD-2.iso'
-----------------------------------------------------------------
Finished!
The fact that you got this far is a strong indication that `debian-507-i386-CD-2.iso'
was generated correctly. I will perform an additional, final check,
which you can interrupt safely with Ctrl-C if you do not want to wait.
OK: Checksums match, image is good!
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
milmazz@manaslu ~ $ time jigdo-lite debian-507-i386-CD-2.jigdo
...
real 8m35.704s
user 0m13.101s
sys 0m16.569s
Nada mal, ¿no les parece?.
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
Referencias
iwl3945
Haciendo el cambio de ipw3945 a iwl3945
Si usted es de esas personas que cuenta con una tarjeta inalámbrica Intel Corporation PRO/Wireless 3945, seguramente sabrá que existen al menos dos proyectos que le dan soporte. El primero de ellos es ipw3945 y se encuentra obsoleto, el desarrollo pasó al proyecto iwlwifi.
Aprovechando que recientemente ha ingresado a la versión inestable de Debian la serie del kernel 2.6.24, este contiene el nuevo modulo iwl3945 que reemplaza al viejo ipw3945. Una de las ventajas de este cambio es que ya no hay necesidad de tener activo el demonio ipw3945d. Sin embargo, aun se necesita del firmware que se encuentra en la sección non-free del repositorio de Debian.
Hasta donde he leído el plan será remover los paquetes ipw3945-modules-* e ipw3945d de los repositorios de Debian (al menos en testing y en unstable) una vez que la serie 2.6.24 del kernel llegue a la versión de pruebas (testing). Aquellos que se encuentren hoy día en la versión inestable (unstable) de Debian deberán cambiar el driver desde ipw3945 a iwl3945. Para aquellos que trabajan en etch también es posible usar el driver iwl3945 si actualiza su versión del kernel por medio del repositorio etch-backports (el nuevo stack mac80211 que usa iwlwifi se encuentra a partir de la versión del kernel 2.6.22).
Las instrucciones que verá a continuación se han aplicado en Debian inestable, si usted desea instalar iwlwifi en etch puede seguir estas instrucciones.
Obteniendo algunos datos de interés antes de proceder con la actualización.
Versión del kernel:
$ uname -r
2.6.22-3-686
Verifique que en realidad tiene una tarjeta Intel Corporation PRO/Wireless 3945 $ lspci -nn | grep Wireless 03:00.0 Network controller [0280]: Intel Corporation PRO/Wireless 3945ABG Network Connection [8086:4227] (rev 02)
Paquetes necesarios
Ahora bien, es necesario instalar el nuevo kernel y el firmware necesario para hacer funcionar a iwlwifi
# aptitude install linux-image-2.6-686 \\
linux-image-2.6.24-1-686 \\
firmware-iwlwifi
Evitando problemas
Verifique que no existe alguna entrada que haga referencia al modulo ipw3945 en el fichero /etc/modules. Para ello recurrimos a Perl que nos facilita la vida.
# perl -i -ne 'print unless /^ipw3945/' /etc/modules
Debido a algunos problemas que se presentan en el paquete network-manager si anteriormente ha venido usando el modulo ipw3945 se recomienda eliminar la entrada que genera udev para dicho modulo en el fichero /etc/udev/rules.d/z25_persistent-net.rules, la entrada es similar a la siguiente:
# PCI device 0x8086:0x4227 (ipw3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTRS{address}=="00:13:02:4c:12:12", NAME="eth2"
Fichero /etc/network/interfaces
Este paso es opcional, agregamos la nueva interfaz wlan0 al fichero /etc/network/interfaces y procedemos a configurarla de acuerdo a nuestras necesidades.
auto lo
iface lo inet loopback
auto wlan0
iface wlan0 inet dhcp
wpa-driver wext
wpa-ssid foo
wpa-psk baz
wpa-key-mgmt WPA-PSK
wpa-pairwise TKIP CCMP
wpa-group TKIP CCMP
wpa-proto WPA RSN
En este caso particular se está indicando que nos vamos a conectar a un Access Point cuyo ssid es foo con tipo de cifrado WPA-PSK/WPA2-PSK, haciendo uso del driver wext que funciona como backend para wpa_supplicant. Es de hacer notar que el driver wext es utilizado por todos los adaptadores Intel Pro Wireless, eso incluye ipw2100, ipw2200 e ipw3945.
Para hacer funcionar WPA recuerde que debe haber instalado previamente el paquete wpasupplicant.
# aptitude install wpasupplicant
De igual manera se le recuerda adaptar todos aquellos parámetros como wpa-ssid y wpa-psk a aquellos adecuados en su caso. En particular el campo wpa-psk lo puede generar con el siguiente comando:
$ wpa_passphrase su_ssid su_passphrase
Aunque mi recomendación es usar el comando wpa_passphrase de la siguiente manera.
$ wpa_passphrase su_ssid
Posteriormente deberá introducir su_passphrase desde la entrada estándar, esto evitará que su_passphrase quede en el historial de comandos.
Para mayor detalle de los campos expuestos en la configuración del fichero /etc/network/interfaces se le recomienda leer la documentación expuesta en /usr/share/doc/wpasupplicant/README.modes.gz.
Una vez concluidos estos pasos reiniciamos el sistema y seleccionamos en nuestro Gestor de Arranque (ej. GRUB) la versión del kernel recien instalada. Al momento de iniciar su sesión verifique que su tarjeta inalámbrica esté funcionando, de lo contrario haga las revisiones que se indican en la siguiente sección.
En caso de persistir los problemas
Remueva y reinserte el modulo iwl3945
# modprobe -r iwl3945
# modprobe iwl3945
De manera adicional compruebe que udev haya generado una nueva entrada para iwl3945.
$ cat /etc/udev/rules.d/z25_persistent-net.rules
...
# PCI device 0x8086:0x4227 (iwl3945)
SUBSYSTEM=="net", DRIVERS=="?*", ATTR{address}=="00:13:02:4c:12:12", ATTR{type}=="1", NAME="wlan0"
Finalmente, reestablecemos la interfaz de red.
# ifdown wlan0
# ifup wlan0
Elimine ipw3945
Una vez verificado el correcto funcionamiento del módulo iwl3945 puede eliminar con seguridad todo aquello relacionado con el modulos ipw3945.
# aptitude --purge remove firmware-ipw3945 \\
ipw3945-modules-$(uname -r) \\
ipw3945-source ipw3945d
Estas instrucciones también aplican para el modulo iwl4965. Mayor información en Debian Wiki § iwlwifi.
jigdo
Construyendo de manera efectiva y rápida imágenes ISO de Debian con jigdo
Si usted desea el conjunto de CD o DVD para instalar Debian, tiene muchas posibilidades, desde la compra de los mismos, muchos de los vendedores contribuyen con Debian. También puede realizar descargas vía HTTP/FTP, vía torrent o rsync. Pero en este artículo se discutirá sobre un método para construir las imágenes ISO de Debian de manera eficiente, sobretodo si cuenta con un repositorio local de paquetes, dicho método se conoce de manera abreviada como jigdo o Jigsaw Download.
Las ventajas que ofrece jigdo están bien claras en el portal de Debian, cito:
¿Por qué jigdo es mejor que una descarga directa?
¡Porque es más rápido! Por varias razones, hay muchas menos réplicas para imágenes de CDs que para el archivo «normal» de Debian. Consecuentemente, si descarga desde una réplica de imágenes de CD, esa réplica no sólo estará más lejos de su ubicación, además estará sobrecargada, especialmente justo después de una publicación.
Además, algunos tipos de imágenes no están disponibles para descarga completa como .iso porque no hay suficiente espacio en nuestros servidores para alojarlas.
Considero que la pregunta pertinente ahora es: ¿Cómo descargo la imagen con jigdo?.
En primer lugar, instalamos el paquete jigdo-file.
# aptitude install jigdo-file
Mi objetivo era generar los 2 primeros CD para Debian Lenny, para la fecha de publicación de este artículo la versión más reciente es la 5.0.7. La lista de imágenes oficiales para jigdo las puede encontrar acá.
milmazz@manaslu /tmp $ cat files
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.template
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.jigdo
http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-2.template
milmazz@manaslu /tmp $ wget -c -i files
--2010-12-02 12:39:52-- http://cdimage.debian.org/debian-cd/5.0.7/i386/jigdo-cd/debian-507-i386-CD-1.jigdo
Resolving cdimage.debian.org... 130.239.18.163, 130.239.18.173, 2001:6b0:e:2018::173, ...
Connecting to cdimage.debian.org|130.239.18.163|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 31737 (31K) [text/plain]
Saving to: `debian-507-i386-CD-1.jigdo'
100%[===================================================================================================================>] 31.737 44,7K/s in 0,7s
...
FINISHED --2010-12-02 12:50:15--
Downloaded: 4 files, 27M in 10m 21s (44,7 KB/s)
milmazz@manaslu /tmp $ ls
debian-507-i386-CD-1.jigdo debian-507-i386-CD-1.template debian-507-i386-CD-2.jigdo debian-507-i386-CD-2.template files
Una vez descargados los ficheros necesarios, es hora de ejecutar el comando
jigdo-lite, siga las instrucciones del asistente.
milmazz@manaslu ~ $ jigdo-lite debian-507-i386-CD-2.jigdo
Jigsaw Download "lite"
Copyright (C) 2001-2005 | jigdo@
Richard Atterer | atterer.net
Loading settings from `/home/milmazz/.jigdo-lite'
-----------------------------------------------------------------
Images offered by `debian-507-i386-CD-2.jigdo':
1: 'Debian GNU/Linux 5.0.7 "Lenny" - Official i386 CD Binary-2 20101127-16:55 (20101127)' (debian-507-i386-CD-2.iso)
Further information about `debian-507-i386-CD-2.iso':
Generated on Sat, 27 Nov 2010 17:02:14 +0000
-----------------------------------------------------------------
If you already have a previous version of the CD you are
downloading, jigdo can re-use files on the old CD that are also
present in the new image, and you do not need to download them
again. Mount the old CD ROM and enter the path it is mounted under
(e.g. `/mnt/cdrom').
Alternatively, just press enter if you want to start downloading
the remaining files.
Files to scan:
El comando despliega información acerca de la imagen ISO que generará, en este
caso particular, debian-507-i386-CD-2.iso. Además, jigdo-lite puede
reutilizar ficheros que se encuentren en CD viejos y así no tener que
descargarlos de nuevo. Sin embargo, este no era mi caso así que presione la
tecla ENTER.
-----------------------------------------------------------------
The jigdo file refers to files stored on Debian mirrors. Please
choose a Debian mirror as follows: Either enter a complete URL
pointing to a mirror (in the form
`ftp://ftp.debian.org/debian/'), or enter any regular expression
for searching through the list of mirrors: Try a two-letter
country code such as `de', or a country name like `United
States', or a server name like `sunsite'.
Debian mirror [http://debian.example.com/debian/]:
En esta fase jigdo-lite solicita la dirección URL completa de un
repositorio, aproveche la oportunidad de utilizar su repositorio local si es que
cuenta con uno. Luego de presionar la tecla ENTER es tiempo de relajarse y
esperar que jigdo descargue todos y cada uno de los ficheros que componen la
imagen ISO.
Luego de descargar los paquetes y realizar las operaciones necesarias para la
construcción de la imagen ISO jigdo le informará los resultados.
FINISHED --2010-12-01 14:43:50--
Downloaded: 6 files, 2,5M in 1,8s (1,39 MB/s)
Found 6 of the 6 files required by the template
Successfully created `debian-507-i386-CD-2.iso'
-----------------------------------------------------------------
Finished!
The fact that you got this far is a strong indication that `debian-507-i386-CD-2.iso'
was generated correctly. I will perform an additional, final check,
which you can interrupt safely with Ctrl-C if you do not want to wait.
OK: Checksums match, image is good!
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
milmazz@manaslu ~ $ time jigdo-lite debian-507-i386-CD-2.jigdo
...
real 8m35.704s
user 0m13.101s
sys 0m16.569s
Nada mal, ¿no les parece?.
Ahora bien, haciendo uso de un repositorio local, es bueno preguntarse en cuanto
tiempo aproximadamente puedes construir tu imagen ISO, en mi caso el tiempo de
construcción de debian-507-i386-CD-2.iso fue de:
Referencias
jsdoc
How to document your Javascript code
Someone that knows something about Java probably knows about JavaDoc. If you know something about Python you probably document your code following the rules defined for Sphinx (Sphinx uses reStructuredText as its markup language). Or in C, you follow the rules defined for Doxygen (Doxygen also supports other programming languages such as Objective-C, Java, C#, PHP, etc.). But, what happens when we are coding in JavaScript? How can we document our source code?
As a developer that interacts with other members of a team, the need to document all your intentions must become a habit. If you follow some basic rules and stick to them you can gain benefits like the automatic generation of documentation in formats like HTML, PDF, and so on.
I must confess that I’m relatively new to JavaScript, but one of the first things that I implement is the source code documentation. I’ve been using JSDoc for documenting all my JavaScript code, it’s easy, and you only need to follow a short set of rules.
/**
* @file Working with Tags
* @author Milton Mazzarri <[email protected]>
* @version 0.1
*/
var Tag = $(function(){
/**
* The Tag definition.
*
* @param {String} id - The ID of the Tag.
* @param {String} description - Concise description of the tag.
* @param {Number} min - Minimum value accepted for trends.
* @param {Number} max - Maximum value accepted for trends.
* @param {Object} plc - The ID of the {@link PLC} object where this tag belongs.
*/
var Tag = function(id, description, min, max, plc) {
id = id;
description = description;
trend_min = min;
trend_max = max;
plc = plc;
};
return {
/**
* Get the current value of the tag.
*
* @see [Example]{@link http://example.com}
* @returns {Number} The current value of the tag.
*/
getValue: function() {
return Math.random;
}
};
}());
In the previous example, I have documented the index of the file, showing the author and version, you can also include other things such as a copyright and license note. I have also documented the class definition including parameters and methods specifying the name, and type with a concise description.
After you process your source code with JSDoc the result looks like the following:
In the previous image you see the documentation in HTML format, also you see a table that displays the parameters with appropriate links to your source code, and finally, JSDoc implements a very nice style to your document.
If you need further details I recommend you check out the JSDoc documentation.
k2
Actualizando WordPress
Tenía cierto tiempo que no actualizaba la infraestructura que mantiene a MilMazz, el día de hoy he actualizado WordPress a su version 2.0.2, este proceso como siempre es realmente sencillo, no hubo problema alguno.
También he aprovechado la ocasión para actualizar el tema K2, creado por Michael Heilemann y Chris J. Davis, de igual manera, he actualizado la mayoría de los plugins.
Respecto al último punto mencionado en el párrafo anterior, algo extraño sucedió al actualizar el plugin Ultimate Tag Warrior, al revisar su funcionamiento me percaté que al intentar ingresar a una etiqueta particular se generaba un error 404, de inmediato supuse que era la estructura de los enlaces permanentes y las reglas de reescritura, para solucionar el problema simplemente actualice la estructura de enlaces permanentes desde las opciones de la interfaz administrativa de WordPress.
Si nota cualquier error le agradezco me lo haga saber a través de la sección de contacto.
kernel
Vulnerabilidad en el kernel Linux de ubuntu
Este problema de seguridad únicamente afecta a la distribución Ubuntu 5.10, Breezy Badger.
Los paquetes afectados son los siguientes:
linux-image-2.6.12-10-386linux-image-2.6.12-10-686linux-image-2.6.12-10-686-smplinux-image-2.6.12-10-amd64-genericlinux-image-2.6.12-10-amd64-k8linux-image-2.6.12-10-amd64-k8-smplinux-image-2.6.12-10-amd64-xeonlinux-image-2.6.12-10-iseries-smplinux-image-2.6.12-10-itaniumlinux-image-2.6.12-10-itanium-smplinux-image-2.6.12-10-k7linux-image-2.6.12-10-k7-smplinux-image-2.6.12-10-mckinleylinux-image-2.6.12-10-mckinley-smplinux-image-2.6.12-10-powerpclinux-image-2.6.12-10-powerpc-smplinux-image-2.6.12-10-powerpc64-smplinux-patch-ubuntu-2.6.12
El problema puede ser solucionado al actualizar los paquetes afectados a la versión 2.6.12-10.28. Posterior al proceso de actualización debe reiniciar el sistema para que los cambios logren surtir efecto.
Puede encontrar mayor detalle acerca de esta información en el anuncio Linux kernel vulnerability hecho por Martin Pitt a la lista de correos de avisos de seguridad en Ubuntu.
latex
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
lenovo
Configurando el sonido (HDA Intel) en Lenovo 3000 c200 en Debian GNU/Linux
La situación poco común se presentó con un portátil Lenovo, específicamente un 3000 c200; el computador en cuestión mostraba la tarjeta funcionando, como si estuviera todo normal, pero sucede que no había sonido en lo absoluto por más altos que estuvieran los indicadores gráficos del volumen. Indagando por Google me encontré que ya han habido muchos casos similares, no solamente para laptops Lenovo, sino para la mayoría que incluye ese tipo de tarjetas y me encontré con una solución en un foro que me funcionó perfecto. Acá voy a tratar de explicar paso a paso todo lo que hice para que funcionara como debe ser.
Lo primero que se hizo fué asegurarse que se trata realmente de una tarjeta HDA Intel, con la siguiente línea de comandos:
$ lspci | grep High
…a lo que se obtuvo la siguiente respuesta:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
…donde se puede verificar que se trata de la HDA de la familia ICH7 de la Intel. Una vez verificado ésto, se procede a instalar algunos paquetes necesarios para que todo funcione de manera correcta, que son los siguientes:
- build-essentials
- gettext
- libncurses5-dev
Ésto se logró con el aptitude, con la siguiente línea de comandos:
$ sudo aptitude install el_paquete_que_quiero_instalar
Luego hay que descargar las cabeceras del kernel que se está usando. Para ésto, la manera más fácil de hacerlo fué instalando el paquete module-assistant y haciendo lo siguiente en una terminal:
$ sudo m-a update
$ sudo m-a prepare
Y el programa automáticamente va a saber cuáles cabeceras descargar y el directorio donde ponerlas. Cuando estén instalados éstos tres paquetes también se va a necesitar descargar de la página del Proyecto Alsa tres archivos necesarios y que son nombrados a continuación:
Se pueden descargar con un gestor de descargas preferido, ésto se hizo con wget, utilizando la línea de comandos:
$ wget -c http://www.alsa-project.org/alsa-driver-1.0.14.tar.bz2
…y así para cada uno de los archivos. Cuando se tengan los tres archivos, se copian a la carpeta /usr/src/alsa/ la cual, probablemente no existe todavía en el sistema y por lo tanto tendrá que ser creada; ésto se puede lograr con la siguiente línea de comandos:
$ sudo mkdir /usr/src/alsa
…cuando se tenga el directorio, se copian los tres archivos tar.gz al mismo; ésto se puede lograr con:
$ sudo cp alsa* /usr/src/alsa/
Luego hay que descomprimir los ficheros tar.gz con:
$ sudo tar xvf el_archivo_que_vamos_a_descomprimir.tar.gz
Una vez descomprimidos nos ubicamos en la primera carpeta que va a ser alsa-driver-1.0.14/ y compilamos el alsa para las tarjetas HDA Intel con las siguientes líneas de comandos:
$ sudo ./configure --with-cards=hda-intel
$ sudo make
$ sudo make install
Luego vamos a necesitar compilar los otros 2 paquetes restantes, para ello, nos ubicamos en la carpeta correspondiente y hacemos en una terminal lo siguiente:
$ sudo ./configure
$ sudo make
$ sudo make install
Ésto se va a hacer tanto para alsa-lib como para alsa-utils, pues el procedimiento es el mismo. Cuando se hayan compilado los tres paquetes el sistema ya debería ser capaz de reconocer correctamente la tarjeta y por lo tanto debe haber sonido; Ésto puedes ser verificado (1) Abriendo un reproductor de preferencia y reproduciendo algo de musica ó (2) Se puede hacer con la siguiente línea:
$ cat /dev/urandom >> /dev/dsp/
Con lo cual se obtendrá un sonido algo parecido a unos aplausos, pero en realidad son sonidos producidos aleatoriamente.
Ésto debería ser todo. En las máquinas que se configuraron, cuando se conectaban los audífonos en el panel lateral, el sonido salía tanto por los audífonos como por las cornetas y al parecer se solucionó con una reiniciada, pero sino quieres reiniciar entonces lo que tienes que hacer es tumbar los módulos que se crearon y volverlos a cargar, tal cual reiniciaras el sistema:
$ sudo modprobe -r snd_hda_intel652145
$ sudo modprobe -r snd_pcm
$ sudo modprobe -r snd_page_alloc
Luego para cargarlos hacemos las mismas línea, pero sin la opción -r.
logitech
Recuperando una antigua Logitech Quickcam Express
No se porque motivo o razón comencé a revisar en unas cajas de mi cuarto, cuando de repente me encontré con la primera cámara web que compre, de hecho, vino como accesorio a mi máquina de escritorio Compaq Presario 5006LA. Así que me pregunté, ¿será que todavía funciona esta reliquia?.
Lo primero que hice fue conectar el dispositivo en cuestión a mi portátil actual, enseguida ejecuté el comando:
$ lsusb | grep -i logitech
Bus 002 Device 002: ID 046d:0840 Logitech, Inc. QuickCam Express</code>
Una vez conocido el PCI ID (046d:0840) del dispositivo realicé una búsqueda rápida en Google y llegué a un sitio muy interesante, en donde podemos obtener una descripción de los dispositivos USB para Linux, al usar la función de búsqueda en la base de datos del sitio mencionado previamente ingreso el dato correspondiente al Vendor ID (en mi caso, 046d), posteriormente filtre los resultados por el Product ID (en mi caso, 0840), sentía que ya estaba dando con la solución a mi problema, había encontrado información detallada acerca de mi Logitech Quickcam Express. Al llegar acá descubrí el Linux QuickCam USB Web Camera Driver Project.
En la página principal del Linux QuickCam USB Web Camera Driver Project observo que mi vejestorio de cámara es soportada por el driver qc-usb.
Con la información anterior decido hacer uso del manejador de paquetes aptitude y en los resultados avisté el nombre de un paquete qc-usb-source, así que definitivamente nuestra salvación es module-assistant.
# aptitude install qc-usb-source \\
build-essential \\
module-assistant \\
modconf \\
linux-headers-`uname -r`
# m-a update
# m-a prepare
# m-a a-i qc-usb
Una vez realizado el paso anterior recurro a la utilidad de configuración de módulos en Debian modconf e instalo el módulo quickcam, el cual se encuentra en /lib/modules/2.6.18-4-686/misc/quickcam.ko y verificamos.
# tail /var/log/messages
May 14 21:16:57 localhost kernel: Linux video capture interface: v2.00
May 14 21:16:57 localhost kernel: quickcam: QuickCam USB camera found (driver version QuickCam USB 0.6.6 $Date: 2006/11/04 08:38:14 $)
May 14 21:16:57 localhost kernel: quickcam: Kernel:2.6.18-4-686 bus:2 class:FF subclass:FF vendor:046D product:0840
May 14 21:16:57 localhost kernel: quickcam: Sensor HDCS-1000/1100 detected
May 14 21:16:57 localhost kernel: quickcam: Registered device: /dev/video0
May 14 21:16:57 localhost kernel: usbcore: registered new driver quickcam
Como puede observarse el dispositivo es reconocido y se ha registrado en /dev/video0. En este instante que poseemos los módulos del driver qc-sub para nuestro kernel, podemos instalar la utilidad qc-usb-utils, esta utilidad nos permitirá modificar los parámetros de nuestra Logitech QuickCam Express.
# aptitude install qc-usb-utils
Ahora podemos hacer una prueba rápida de nuestra cámara, comienza la diversión, juguemos un poco con mplayer.
$ mplayer tv:// -tv driver=v4l:width=352:height=288:outfmt=rgb24:device=/dev/video0:noaudio -flip
A partir de ahora podemos probar más aplicaciones ;)
lug
gUsLA: Grupo de Usuarios de Software Libre de la Universidad de Los Andes
Un grupo de compañeros de estudio y mi persona por fin hemos iniciado una serie de actividades para formar el Grupo de Usuarios de Software Libre de la Universidad de Los Andes.
El día de hoy, hicimos entrega de una carta al Consejo de Escuela de Ingeniería de Sistemas, solicitando un aval académico para lograr llevar a cabo las siguientes actividades:
- Charlas.
- Festivales de instalación.
- Atención al usuario.
- Otras actividades de naturaleza académica.
Esta solicitud la hicimos ya que consideramos necesaria la creación de un Grupo de Usuarios que se encargue de:
- Difundir y promover el Software Libre en la Universidad de los Andes.
- Difundir las bases filosóficas detrás del modelo del Software Libre.
- Demostrar la calidad técnica del Software Libre.
- Demostrar a los usuarios finales cuan fácil es utilizar GNU/Linux.
- Fomentar el intercambio de conocimientos en Talleres, Foros, Charlas y/o encuentros con grupos de usuarios de otras latitudes.
- Adaptación al proceso de cambio fomentado por el ente público (decreto 3390).
En este momento hemos contactado a ciertos profesores que han mostrado interés en la iniciativa, la idea es involucrar a todas aquellas personas relacionadas con la Universidad de Los Andes.
En resumen, el objetivo principal que pretende alcanzar nuestro grupo es: El estudio, desarrollo, promoción, difusión, educación, enseñanza y uso de sistemas operativos GNU/Linux, GNU/Hurd, FreeBSD, y de las herramientas libres que interactúan con estos, tanto en el ámbito nacional como en el internacional. Es importante resaltar en este instante que No se perseguirán fines de lucro, ni tendremos finalidades o actividades políticas, partidistas ni religiosas; seremos un grupo apolítico, abierto, pluralista y con fines académicos.
Personalmente, debo agradecer a José Parrella por haberme facilitado un borrador del documento constitutivo/estatutario del Grupo de Usuarios de Linux de la Universidad Central de Venezuela (UCVLUG), lo hemos utilizado como base para formar el nuestro, aunque será discutido por ahora en una lista privada de estudiantes y profesores que han manifestado interés en participar.
Esperamos con ansiedad la decisión del Consejo de Escuela de Ingeniería de Sistemas.
m1210
Establecer red inalámbrica en Dell m1210
Hace ya algunos días Ana me comentaba que no le estaba funcionando la configuración que tenía para su red inalámbrica, eso ocurrió una vez que actualizó la versión del kernel de linux, espero entrar en detalle acerca de los pasos que seguí para configurarle todo como se debe bajo Debian Etch.
Lo primero que debía saber era el tipo de componente PCI al que me estaba enfrentando.
$ lspci -nn | grep Wireless
0c:00.0 Network controller [0280]:
Broadcom Corporation Dell Wireless 1390
WLAN Mini-PCI Card [14e4:4311] (rev 01)
Lo anterior dice que nos estamos enfrentando ante una Broadcom cuyo chipset id es el 4311, debemos saber que el módulo para linux de estos chips es el bcm43xx y ha sido incluido al kernel de linux desde la versión 2.6.17-rc2Fuente: http://bcm43xx.berlios.de/, al revisar la lista de dispositivos soportados me percaté que el soporte para este chipset id aún es inestable, así que el siguiente paso era eliminar su presencia si aplicaba.
$ lsmod | grep bcm43xx
bcm43xx 148500 0
ieee80211softmac 40704 1 bcm43xx
ieee80211 39112 2 bcm43xx,ieee80211softmac
Como se puede observar en este caso aplica, así que comenzamos a eliminar su presencia.
# grep -q '^blacklist bcm43xx' /etc/modprobe.d/blacklist \\
|| tee -a 'blacklist bcm43xx' /etc/modprobe.d/blacklist
La inclusión de la línea blacklist bcm43xx al fichero /etc/modprobe.d/blacklist si aplica me permite indicar que dicho módulo no debe cargarse como resultado de la expansión de su alias, es decir, bcm43xx, esto se hace con el propósito de evitar que el subsistema hotplug lo carge, aunque esto no evita que el módulo se carge automáticamente por el kernel.
Luego verifique el fichero /etc/modules, el cual contiene los nombre de los módulos que serán cargados a la hora del inicio del sistema, no había entrada para el módulo bcm43xx, ahora es necesario remover dicho módulo, para lo cual hacemos:
# modprobe -r bcm43xx
Una vez culminado este proceso es necesario hacer uso de ndiswrapper, el cual es un módulo que me permite cargar y ejecutar drivers propietarios de Windows para tarjetas inalámbricas.
# aptitude -r install build-essential \\
module-assistant ndiswrapper-common
# m-a update
# m-a prepare
# m-a a-i ndiswrapper
# modprobe ndiswrapper
Una vez cargado el módulo ndiswrapper es necesario instalar el nuevo driver propietario, para ello debemos encontrar el fichero con extensión inf, este fichero especifica que ficheros necesitan estar presentes o descargarse para que el componente funcione correctamente, para dicho driver. Al consultar en la lista de tarjetas que funcionan con ndiswrapper me percato que han habido problemas de seguridad en algunos de los drivers recomendados para esta tarjeta, así que para asegurarme de obtener las versiones más recientes ingreso al sitio oficial de Dell, bajo la sección USA -> Support search: “m1210” -> Drivers and Downloads -> Network & Internet -> Network Driver, ingreso el campo correspondiente al service tag, y finalmente descargo el fichero R151517.EXE.
El siguiente paso es extraer los ficheros que se encuentran dentro de R151517.EXE, para ello:
unzip R151517.EXE
Ahora nos interesa el fichero bcmwl5.inf que está dentro del directorio DRIVER.
$ tree R151517/DRIVER/
R151517/DRIVER/
|-- bcm43xx.cat
|-- bcm43xx64.cat
|-- bcmwl5.inf
|-- bcmwl5.sys
`-- bcmwl564.sys
Una vez extraídos los ficheros, procedemos a cargar el driver, para ello hacemos lo siguiente:
# ndiswrapper -i R151517/DRIVER/bcmwl5.inf
Comprobamos que el driver se ha instalado correctamente.
# ndiswrapper -l
installed drivers:
bcmwl5 driver installed, hardware (14E4:4324) present (alternate driver: bcm43xx)
Luego verificamos nuestro trabajo al ejecutar el comando dmesg, tal como se muestra a continuación:
$ dmesg
[44093.473325] ndiswrapper version 1.27 loaded (preempt=no,smp=yes)
[44095.311236] ndiswrapper (link_pe_images:577): fixing KI_USER_SHARED_DATA address in the driver
[44093.482777] ndiswrapper: driver bcmwl5 (Broadcom,03/23/2006, 4.40.19.0) loaded
[44093.483250] ACPI: PCI Interrupt 0000:0c:00.0[A] -> GSI 17 (level, low) -> IRQ 177
[44093.483367] PCI: Setting latency timer of device 0000:0c:00.0 to 64
[44093.491760] ndiswrapper: using IRQ 177
[44094.162703] wlan0: vendor:
[44094.162708] wlan0: ethernet device 00:18:f3:6b:fc:3b using NDIS driver bcmwl5, 14E4:4311.5.conf
[44094.162772] wlan0: encryption modes supported: WEP; TKIP with WPA, WPA2, WPA2PSK; AES/CCMP with WPA, WPA2, WPA2PSK
[44094.166554] usbcore: registered new driver ndiswrapper
[44094.167390] ndiswrapper: changing interface name from 'wlan0' to 'eth1'
En este preciso instante el comando ifconfig -a debe mostrarnos la nueva interfaz, y el comando iwlist eth1 scan al ejecutarse como superusuario devolverá la lista de redes que han sido detectadas.
Recuerde que para que todo esto siga funcionando aún después de reiniciar el sistema, es necesario cargar el módulo de ndiswrapper, para ello hago uso del comando modconf.
*[PCI]: Peripheral Component Interconnect
magazine
O3 Magazine
O3 Magazine es una revista distribuida de manera electrónica en formato PDF. El enfoque que pretende O3 es promover el uso/integración de programas basados en Software Libre y Código Abierto (FOSS) en ambientes empresariales.
O3 ha sido creada usando exclusivamente herramientas de código abierto. Como por ejemplo:
Scribus, permite crear publicaciones de escritorio profesionales, es usado para definir el layout y producir los PDFs. The Gimp, usado para la creación y manipulación de imágenes y Open Office, el cual es usado por los escritores para la creación de los artículos.
Cada edición de la revista O3 tratará de cubrir los siguientes tópicos:
- Seguridad
- Internet
- Tecnologías web
- Negocios
- Voz/Multimedia (VoIP)
- Redes
- Aplicaciones para redes
- Seguridad en redes
O3 Magazine pretende demostrar a sus lectores los beneficios y el ahorro que se genera al usar soluciones de código abierto en el ambiente de los negocios. También puede interesar a aquellos dueños de pequeñas y medianas empresas que estén interesados en una infraestructura IT fuerte, segura y escalable sin incurrir en altos costos.
Si desean tener la primera edición de O3 Magazine, pueden hacerlo en: Issue #1 (November 2005)
Como era de esperarse la publicación viene en inglés. De hecho, todas las revistas electrónicas que conozco y leo vienen en este idioma. Por lo descrito previamente me atrevo a preguntarles lo siguiente, ¿conocen alguna publicación electrónica de buena calidad que venga en español?.
marketing
Femfox: una campaña no oficial con mucho glamour
Un pequeño grupo de 3 personas, una “modelo”, un “fotógrafo” y un “programador”, nos deleitan con una campaña no oficial que promueve el uso del premiado y conocido navegador Firefox.
En esta campaña se puede observar una mezcla total entre glamour, seducción, humor, estética y calidad fotográfica. Lo anterior está presentado de un modo original, teniendo cuidado de evitar mostrar contenido explícito, sexual, que puede resultar ofensivo para algunos. De hecho, existe una advertencia en la página principal, en donde usted indica que al entrar a dicho sitio se tienen 16 ó más años de edad.
Este sitio es relativamente reciente, abrio sus puertas el día 1 de Febrero de 2006, la idea de crear una campaña de este tipo vino dada por una mujer de 31 años de edad, quien resulta ser la modelo de esta innovadora e inusual campaña promocional para Firefox.
Todo lo relacionado con dicha campaña lo puede encontrar en el sitio Femfox.com.
merida
Charla sobre el lenguaje de programación Python
La ingeniera Andrea Muñoz me notifica que el día Jueves 23 de Febrero se estará llevando a cabo la charla Carpintería del Software Libre, un enfoque desde el lenguaje de programación Python, en donde el ponente será el profesor Francisco Palm, seguramente estará muy interesante.
La cita es el día 23 de Febrero, a las 8:30 a.m. en el Núcleo La Hechicera, Facultad de Ingeniería, Nivel Patio, Ala Sur, Labtel II, Estado Mérida (Venezuela).
La invitación es realizada por el Consejo de Computación Académica (CCA) de la Universidad de Los Andes, gracias al espacio que ofrecen para la difusión del Software Libre, “Jueves Libre”
Desgraciadamente hasta ahora no puedo asistir a la charla, debo presentar un examen de Ingeniería del Software el mismo día, a la misma hora. Trataré de hablar con Jesús Molina o Andrea Muñoz para ver si puede grabarse en algún medio permanente esta charla.
mkpasswd
Generando contraseñas aleatorias con Perl
El día de hoy se manifestó la necesidad de generar una serie de claves aleatorias para un proyecto en el que me he involucrado recientemente, la idea es que la entrada que tenemos corresponde más o menos al siguiente formato:
username_1
username_2
...
username_n
La salida que se desea obtener debe cumplir con el siguiente formato:
username_1 pass_1
username_2 pass_2
username_3 pass_3
...
username_n pass_n
En este caso debía cumplir un requisito fundamental, las contraseñas deben ser suficientemente seguras.
No pensaba en otra cosa que usar el lenguaje de programación Perl para realizar esta tarea, así fue, hice uso del poderío que brinda Perl+CPAN y en menos de 5 minutos ya tenía la solución al problema planteado, el tiempo restante me sirvió para comerme un pedazo de torta que me dió mi hermana, quien estuvo de cumpleaños el día de ayer.
En primer lugar, debemos instalar el módulo String::MkPasswd, el cual nos permitirá generar contraseñas de manera aleatoria. Si usted disfruta de una distribución decente como DebianRecuerde, Debian es inexorable la instalación del módulo es realmente trivial.
# aptitude install libstring-mkpasswd-perl
Además, si usted se detiene unos segundos y lee la documentación del módulo String::MkPasswd Este modulo en particular no solo se encuentra perfectamente integrado con nuestra distribución favorita, sino que además sus dependencias están resueltas. Esto es una simple muestra del poderío que ofrece una distribución como Debian., se dará cuenta que la función mkpasswd() toma un hash de argumentos opcionales. Si no le pasa ningún argumento a esta función estará generando constraseñas aleatorias con las siguientes características:
- La longitud de la contraseña será de 9.
- El número mínimo de dígitos será de 2.
- El número mínimo de caracteres en minúsculas será de 2.
- El número mínimo de caracteres en mayúsculas será de 2.
- El número mínimo de caracteres no alfanuméricos será de 1.
- Los caracteres no serán distribuidos entre los lados izquierdo y derecho del teclado.
Ahora bien, asumiendo que el fichero de entrada es users.data, la tarea con Perl es resumida en una línea de la siguiente manera.
perl -MString::MkPasswd=mkpasswd -nli -e 'print $_, " ", mkpasswd()' users.data
La línea anterior hace uso de la función mkpasswd del módulo String::MkPasswd para generar las contraseñas aleatorias para cada uno de los usuarios que se encuentran en el fichero de entrada users.data, además, la opción -iPara mayor información acerca de las distintas opciones usadas se le sugiere referirse a man perlrun permite editar el fichero de entrada in situ, ahora bien, quizá para algunos paranoicos (me incluyo) no sea suficiente todo esto, así que vamos a generar contraseñas aleatorias aún más complicadas.
#!/usr/bin/perl -li
use strict;
use warnings;
use String::MkPasswd qw(mkpasswd);
while(<>){
chomp;
print $_, " ", mkpasswd(
-length => 16,
-minnum => 5,
-minlower => 5,
-minupper => 3,
-minspecial => 3,
-distribute => 1
);
}En esta ocasión el la función mkpasswd() generará claves aún más complejas, dichas claves cumplirán con las siguientes condiciones.
-
-length: La longitud total de la contraseña, 16 en este caso. -
-minnum: El número mínimo de digitos. 5 en este caso. -
-minlower: El número mínimo de caracteres en minúsculas, en este caso 5. -
-minupper: El número mínimo de caracterés en mayúsculas, en este caso 3. -
-minspecial: El número mínimo de caracteres no alfanuméricos, en este caso será de 3. -
-distribute: Los caracteres de la contraseña serán distribuidos entre el lado izquierdo y derecho del teclado, esto hace más díficil que un fisgón vea la contraseña que uno está escribiendo. El valor predeterminado es falso, en este caso el valor es verdadero.
El script mostrado anteriormente lo podemos reducir a una línea, aunque preferí guardarlo en un fichero al que denomine genpasswd.pl por cuestiones de legibilidad.
mongodb
MongoDB University: M101P
A finales del año pasado finalice satisfactoriamente el curso en línea M101P: MongoDB for Python Developers de MongoDB University (otrora conocido como 10gen Education). Sin embargo, no me había tomado el tiempo para compartirles la experiencia, sino hasta ahora.
Cualquier persona sin práctica en el área puede tomar este curso, pues es un abreboca al mundo detrás de MongoDB y explora un buen número de temas relacionados a esta base de datos NoSQL. Aunque está orientado a desarrolladores en Python lo exigido por el curso es mínimo en este lenguaje, incluso dentro de los temas está contemplado una introducción a este lenguaje. Sin embargo, para aquellos que decidan explorar otros lenguajes de programación, MongoDB University ofrece alternativas para programadores en Java, Node.js y también para DBAs.
La duración del curso es de 7 semanas, en base al conocimiento previo que se maneje de las tecnologías puede necesitar de unas 4 a 6 horas semanales de dedicación. La estructura del curso permite ver inicialmente varios videos introductorios que hacen referencia a un tópico en particular, luego podrá reforzar lo visto con una serie de quizzes, en este punto siempre es recomendable contrastar lo visto con la documentación oficial en línea y no dejar de responder todas las tareas de cada semana pues tienen un peso total del 50%, el plazo de respuesta es más que aceptable, se da una semana de plazo para responder. En la última semana será el examen final, el cual consta de 10 preguntas, con ello se obtiene el otro 50%.
En mi caso aprovechaba el tiempo al ser trasladado hacia/desde el trabajo y veía fuera de línea los videos ofrecidos por MongoDB University. Luego, al retornar a casa en las noches o los fines de semana respondía los quizzes y las asignaciones, de ese modo me fue posible lograr aprobar sin problemas el curso, además, al final recibes un certificado de aprobación, aunque lo más importante para mi fue aprender algunas cuestiones que aún desconocía de MongoDB, las semanas podrían resumirse como siguen:
En la primera semana se ve una introducción a MongoDB, se compara en cierta medida con el esquema relacional y se plasma un bosquejo del desarrollo de aplicaciones con MongoDB. También se explora el shell y se introduce la notación JSON, a partir de acá se crean arrays, documentos y subdocumentos, entre otros detalles de la especificación. También se comienza a preparar el ambiente de trabajo futuro, es decir, se explica como instalar MongoDB en diversas plataformas, así como Python, Bottle (microframework para desarrollo Web en Python) y pymongo, éste último ofrece un conjunto de herramientas para interactuar con MongoDB desde Python. Ya para finalizar las sesiones de la semana, se da una introducción al lenguaje de programación Python y manejo básico del framework Bottle.
La segunda semana se tiene mayor interacción con el shell de MongoDB, se
inicia el proceso de CRUD, se podrán ejecutar consultas por medio de find,
findOne. Se comienza el uso de operadores de comparación de campos como $gt y $lt, operadores lógicos como $or, $and, uso de operadores
$exists, $type, conteo de consultas sobre colecciones con el
método count(), uso de expresiones regulares (compatibles a las usadas
en Perl) a través del operador $regex1, consultas sobre elementos
dentro de arrays con los operadores $in y $all, actualizaciones
de arrays a través de $push, $pop, $pull,
$pullAll y $addToSet. Además, uso de operadores de
actualización $set y $unset para establecer o eliminar campos de
un documento respectivamente. Actualización de documentos existentes y
la posibilidad de utilizar opciones como upsert (operación que permite hacer
una actualización si el documento en cuestión existe, de lo contrario, se
realiza una inserción automática) o multi (actualización múltiple). Ya para
finalizar la segunda semana se deja de lado un poco el shell y se comienza el
mismo proceso de interacción descrito previamente pero en esta ocasión desde
pymongo.
La tercera semana nos podemos encontrar con temas enfocados al área de modelado de datos, pues MongoDB ofrece un esquema flexible, incluso cada documento puede manejar un esquema dinámico. Por lo tanto, resulta conveniente estudiar las posibilidades existentes en el modelaje de datos y que la escogencia de un esquema particular apunte a cubrir los requerimientos de la aplicación, explotación de las características propias del motor de base de datos y los mecanismos comunes de obtención de dichos datos. En el transcurso de la tercera semana, se contrasta como ejemplo el modelado de datos relacional de las tablas que pueden estar asociadas a un blog y como cambia dicho modelado desde la visión no relacional, también se cubren temas como las relaciones uno a uno, uno a muchos con referencias a otros documentos, uno a muchos con documentos embebidos, en qué casos puede ser beneficioso embeber datos. Finalmente se explora GridFS para el manejo de blobs, ficheros que normalmente superen el límite de tamaño de cada documento (16MB).
El tema principal de la cuarta semana es el rendimiento, lo cual puede estar influenciado por muchos factores, desde el sistema de gestión de ficheros, hasta la memoria, CPU, tipos de discos, entre otros. Sin embargo, en esta semana se concentrarán en explorar los algoritmos que dependiendo de la situación puede ejecutar rápidamente o no las consultas. Por lo tanto, es necesario explorar conceptos básicos como índices, su creación y descubrimiento, índices con múltiples claves hasta temas como la detección de posible cuellos de botella al no utilizar índices o mala utilización de los mismos. Al finalizar se comienza a explorar los shardings, básicamente es una técnica que permite dividir largas colecciones de datos en múltiples servidores.
La quinta semana se explora una de las funcionalidades mas atractivas de
MongoDB: Aggregation framework. Para los que vienen del mundo SQL
puede parecerles una respuesta a la agrupación de resultados por grupos, en
donde se pueden obtener sumas ($sum), conteos ($count), promedios ($avg) y
otras funciones sobre un conjunto de colecciones agrupadas por ciertos valores
particulares.
La sexta semana se cubren interesantes temas como la replicación y sharding. La última semana se tiene acceso a 2 casos de estudio, en particular, la primera entrevista es con Jon Hoffman (@Hoffrocket) de Foursquare y la segunda con Ryan Bubinski (@ryanbubinski) de Codecademy.
Después de las entrevistas viene el examen final, el cual cubre el 50% del curso. ¡Éxitos! y recuerde siempre reforzar lo visto en el curso con la documentación oficial, también existen recursos adicionales2 en la red que podrían servirles.
Ya para finalizar quisiera decirles que se animen a intentar unirse al curso que se ofrece de MongoDB, vale la pena intentarlo y verán que son semanas bien aprovechadas.
través del operador $regex, tenga en cuenta que solo podrá hacer uso eficiente
del índice cuando la expresión regular incluye el ancla de inicio de cadena: ^
(acento cincunflejo) y sea case-sensitive.
MongoDB Book]the-little-mongodb-book de Karl Seguin, también existen guías y presentaciones adicionales que pueden ayudarle a comprender aún más MongoDB, por ejemplo, esta presentación sobre distintas consultas y uso del aggregation framework para explorar datos de resultados la NBA.
mp3
mp3wrap: Concatenando ficheros mp3
mp3wrap es una utilidad en línea de comando que nos permite fusionar o concatenar dos o más ficheros mp3, todo esto sin perder los nombres de ficheros y la información de los ID3, estándar que permite la inclusión de metadatos en contenedores multimedia. También es posible añadir otros ficheros que no sean mp3, como por ejemplo, listas de reproducción, ficheros de información, imágenes de portada. Claro, este proceso es posible revertirlo gracias a mp3splt, el cual describiré en un próximo artículo.
Con mp3wrap, usted puede fácilmente fusionar hasta un máximo de 255 ficheros en uno solo, lo cual pareciese ser suficiente para la mayoría. De igual manera, como se mencionó previamente, usted puede añadir ficheros que no sean mp3, pero hay algunas consideraciones al respecto.
- Si el fichero es de texto, como pueden ser las listas de reproducción, los ficheros de información, entre otros, se recomienda que estos se ubiquen al principio del fichero a generar, puesto que el reproductor los descartará rápidamente.
- Si el fichero es binario, como las imágenes por ejemplo, usted debe colocarlas al final del fichero a generar, de esta manera el reproductor se los encontrará después de reproducir y no los confundirá con ficheros
mp3.
Instalación del programa
Para poder instalar esta aplicación en Ubuntu, en primer lugar debemos tener activo en nuestro fichero /etc/apt/sources.list el repositorio universe, después de haber verificado esto procedemos a instalarlo.
$ sudo aptitude install mp3wrap
A continuación explicaré el uso de mp3wrap a través de un ejemplo.
En primer lugar, mostraré la lista de ficheros a fusionar.
$ ls
01.mp3 02.mp3 03.mp3 04.mp3
Ahora fusionaré las 2 primeras canciones.
$ mp3wrap album.mp3 01.mp3 02.mp3
He obviado el mensaje que nos muestra mp3wrap para evitar extender más de lo necesario este artículo. También es importante acotar que el fichero generado no se llamará album.mp3 (lo que pareciese lógico), sino album_MP3WRAP.mp3, es recomendable no borrar la cadena MP3WRAP, ésta le indicará al programa mp3splt, el cual nos permite separar de nuevo los ficheros fusionados, que dicho fichero fué fusionado utilizando mp3wrap, lo anterior nos facilitará su extracción con mp3splt, en caso de darse.
Ahora bien, voy a añadir las otras dos canciones, que conste que este paso lo hago solamente para demostrar como añadir otros ficheros a una compilación previamente hecha con mp3wrap.
$ mp3wrap -a album_MP3WRAP.mp3 03.mp3 04.mp3
Si deseamos conocer cuales son los archivos que contiene el fichero generado por mp3wrap, simplemente debemos hacer lo siguiente.
mp3wrap -l album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
01.mp3
02.mp3
03.mp3
04.mp3
Si en la instrucción anterior hubiesemos hecho uso de la opción -v (verbose), mp3wrap nos mostraría información adicional acerca de los ficheros. Por ejemplo:
mp3wrap -lv album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
# Size Name
--- -------- --------
1) 6724962 01.mp3
2) 9225205 02.mp3
--- -------- --------
15950240 2 files
Pueden observar en el ejemplo anterior que se nos muestra el tamaño en bytes de cada uno de los ficheros, así como el número total de ficheros que han sido fusionados y su tamaño correspondiente en bytes.
Como se ha podido ver a través del articulo el uso de mp3wrap es bastante sencillo, si tiene alguna duda acerca de su uso consulte el manual de mp3wrap, man mp3wrap, o la sección de preguntas mas frecuentes acerca de mp3wrap.
mp3splt
mp3wrap: Concatenando ficheros mp3
mp3wrap es una utilidad en línea de comando que nos permite fusionar o concatenar dos o más ficheros mp3, todo esto sin perder los nombres de ficheros y la información de los ID3, estándar que permite la inclusión de metadatos en contenedores multimedia. También es posible añadir otros ficheros que no sean mp3, como por ejemplo, listas de reproducción, ficheros de información, imágenes de portada. Claro, este proceso es posible revertirlo gracias a mp3splt, el cual describiré en un próximo artículo.
Con mp3wrap, usted puede fácilmente fusionar hasta un máximo de 255 ficheros en uno solo, lo cual pareciese ser suficiente para la mayoría. De igual manera, como se mencionó previamente, usted puede añadir ficheros que no sean mp3, pero hay algunas consideraciones al respecto.
- Si el fichero es de texto, como pueden ser las listas de reproducción, los ficheros de información, entre otros, se recomienda que estos se ubiquen al principio del fichero a generar, puesto que el reproductor los descartará rápidamente.
- Si el fichero es binario, como las imágenes por ejemplo, usted debe colocarlas al final del fichero a generar, de esta manera el reproductor se los encontrará después de reproducir y no los confundirá con ficheros
mp3.
Instalación del programa
Para poder instalar esta aplicación en Ubuntu, en primer lugar debemos tener activo en nuestro fichero /etc/apt/sources.list el repositorio universe, después de haber verificado esto procedemos a instalarlo.
$ sudo aptitude install mp3wrap
A continuación explicaré el uso de mp3wrap a través de un ejemplo.
En primer lugar, mostraré la lista de ficheros a fusionar.
$ ls
01.mp3 02.mp3 03.mp3 04.mp3
Ahora fusionaré las 2 primeras canciones.
$ mp3wrap album.mp3 01.mp3 02.mp3
He obviado el mensaje que nos muestra mp3wrap para evitar extender más de lo necesario este artículo. También es importante acotar que el fichero generado no se llamará album.mp3 (lo que pareciese lógico), sino album_MP3WRAP.mp3, es recomendable no borrar la cadena MP3WRAP, ésta le indicará al programa mp3splt, el cual nos permite separar de nuevo los ficheros fusionados, que dicho fichero fué fusionado utilizando mp3wrap, lo anterior nos facilitará su extracción con mp3splt, en caso de darse.
Ahora bien, voy a añadir las otras dos canciones, que conste que este paso lo hago solamente para demostrar como añadir otros ficheros a una compilación previamente hecha con mp3wrap.
$ mp3wrap -a album_MP3WRAP.mp3 03.mp3 04.mp3
Si deseamos conocer cuales son los archivos que contiene el fichero generado por mp3wrap, simplemente debemos hacer lo siguiente.
mp3wrap -l album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
01.mp3
02.mp3
03.mp3
04.mp3
Si en la instrucción anterior hubiesemos hecho uso de la opción -v (verbose), mp3wrap nos mostraría información adicional acerca de los ficheros. Por ejemplo:
mp3wrap -lv album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
# Size Name
--- -------- --------
1) 6724962 01.mp3
2) 9225205 02.mp3
--- -------- --------
15950240 2 files
Pueden observar en el ejemplo anterior que se nos muestra el tamaño en bytes de cada uno de los ficheros, así como el número total de ficheros que han sido fusionados y su tamaño correspondiente en bytes.
Como se ha podido ver a través del articulo el uso de mp3wrap es bastante sencillo, si tiene alguna duda acerca de su uso consulte el manual de mp3wrap, man mp3wrap, o la sección de preguntas mas frecuentes acerca de mp3wrap.
mp3wrap
mp3wrap: Concatenando ficheros mp3
mp3wrap es una utilidad en línea de comando que nos permite fusionar o concatenar dos o más ficheros mp3, todo esto sin perder los nombres de ficheros y la información de los ID3, estándar que permite la inclusión de metadatos en contenedores multimedia. También es posible añadir otros ficheros que no sean mp3, como por ejemplo, listas de reproducción, ficheros de información, imágenes de portada. Claro, este proceso es posible revertirlo gracias a mp3splt, el cual describiré en un próximo artículo.
Con mp3wrap, usted puede fácilmente fusionar hasta un máximo de 255 ficheros en uno solo, lo cual pareciese ser suficiente para la mayoría. De igual manera, como se mencionó previamente, usted puede añadir ficheros que no sean mp3, pero hay algunas consideraciones al respecto.
- Si el fichero es de texto, como pueden ser las listas de reproducción, los ficheros de información, entre otros, se recomienda que estos se ubiquen al principio del fichero a generar, puesto que el reproductor los descartará rápidamente.
- Si el fichero es binario, como las imágenes por ejemplo, usted debe colocarlas al final del fichero a generar, de esta manera el reproductor se los encontrará después de reproducir y no los confundirá con ficheros
mp3.
Instalación del programa
Para poder instalar esta aplicación en Ubuntu, en primer lugar debemos tener activo en nuestro fichero /etc/apt/sources.list el repositorio universe, después de haber verificado esto procedemos a instalarlo.
$ sudo aptitude install mp3wrap
A continuación explicaré el uso de mp3wrap a través de un ejemplo.
En primer lugar, mostraré la lista de ficheros a fusionar.
$ ls
01.mp3 02.mp3 03.mp3 04.mp3
Ahora fusionaré las 2 primeras canciones.
$ mp3wrap album.mp3 01.mp3 02.mp3
He obviado el mensaje que nos muestra mp3wrap para evitar extender más de lo necesario este artículo. También es importante acotar que el fichero generado no se llamará album.mp3 (lo que pareciese lógico), sino album_MP3WRAP.mp3, es recomendable no borrar la cadena MP3WRAP, ésta le indicará al programa mp3splt, el cual nos permite separar de nuevo los ficheros fusionados, que dicho fichero fué fusionado utilizando mp3wrap, lo anterior nos facilitará su extracción con mp3splt, en caso de darse.
Ahora bien, voy a añadir las otras dos canciones, que conste que este paso lo hago solamente para demostrar como añadir otros ficheros a una compilación previamente hecha con mp3wrap.
$ mp3wrap -a album_MP3WRAP.mp3 03.mp3 04.mp3
Si deseamos conocer cuales son los archivos que contiene el fichero generado por mp3wrap, simplemente debemos hacer lo siguiente.
mp3wrap -l album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
01.mp3
02.mp3
03.mp3
04.mp3
Si en la instrucción anterior hubiesemos hecho uso de la opción -v (verbose), mp3wrap nos mostraría información adicional acerca de los ficheros. Por ejemplo:
mp3wrap -lv album_MP3WRAP.mp3
List of wrapped files in album_MP3WRAP.mp3:
# Size Name
--- -------- --------
1) 6724962 01.mp3
2) 9225205 02.mp3
--- -------- --------
15950240 2 files
Pueden observar en el ejemplo anterior que se nos muestra el tamaño en bytes de cada uno de los ficheros, así como el número total de ficheros que han sido fusionados y su tamaño correspondiente en bytes.
Como se ha podido ver a través del articulo el uso de mp3wrap es bastante sencillo, si tiene alguna duda acerca de su uso consulte el manual de mp3wrap, man mp3wrap, o la sección de preguntas mas frecuentes acerca de mp3wrap.
mplayer
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
music
Cowbell: Organiza tu música
Cowbell, es una aplicación que te permite organizar tus compilaciones musicales de una manera fácil y divertida, ya no tienes que aburrirte por horas al intentar organizar tus colección musical manualmente.
Una de las cosas que me han agradado de este programa es que aparte de poder editar las etiquetas manualmentede en una interfaz bastante agradable y sencilla, también puedes obtener toda la información necesaria a través de Amazon Web Services, lo anterior incluye: Número, Título, Año, Estilo, Portada y demás información relacionada con las canciones. Al utilizar este servicio cuentas con una amplia bases de datos, lo anterior en realidad permite ahorrar mucho tiempo.
Dentro de las preferencias de este programa nos encontraremos con opciones que nos permitirán renombrar ficheros de acuerdo a un patrón, el cual lo podemos generar al combinar cualquiera de las siguientes palabras claves.
- Artist
- Album
- Title
- Track
- Genre
- Year
Las palabras claves anteriores se explican por sí solas. Simplemente escoge el patrón que más se ajuste a tus necesidades. Entre otras de las características de este programa, cabe mencionar la posibilidad de generar un fichero de lista de reproducción del álbum.
¿Tienes una larga colección de música cuyas etiquetas debes arreglar?, no te preocupes, Cowbell también puedes usar desde la línea de comandos, la manera de invocar el comando es la siguiente:
$ cowbell --batch /ruta/a/tu/musica
Donde evidentemente debes modificar el directorio /ruta/a/tu/musica de acuerdo a tus necesidades.
Para instalar esta aplicación en ubuntu debes tener activo el repositorio universe en tu fichero /etc/apt/sources.list. Una vez actualizada la lista de repositorios, puedes instalar Cowbell de la siguiente manera:
$ sudo aptitude cowbell
nautilus
Restaurando la vieja barra de localización en nautilus
Si usted al igual que yo no le gusta la nueva manera en que se presenta la barra de localización en nautilus bajo Breezy, en donde se emplean las barras de rutas, es posible regresar a la vieja configuración (tal cual como en Hoary) en donde se especificaba de manera textual la ruta actual en la barra de localización.
Si ud. quiere cambiar este comportamiento, es tan sencillo como dirijirse a /apps/nautilus/preferences/ y proceder a marcar la casilla de verificación always_use_location_entry.
Lo anterior lo puede hacer desde el Editor de configuración, el cual lo puede encontrar en Aplicaciones -> Herramientas del Sistema.
ndiswrapper
Establecer red inalámbrica en Dell m1210
Hace ya algunos días Ana me comentaba que no le estaba funcionando la configuración que tenía para su red inalámbrica, eso ocurrió una vez que actualizó la versión del kernel de linux, espero entrar en detalle acerca de los pasos que seguí para configurarle todo como se debe bajo Debian Etch.
Lo primero que debía saber era el tipo de componente PCI al que me estaba enfrentando.
$ lspci -nn | grep Wireless
0c:00.0 Network controller [0280]:
Broadcom Corporation Dell Wireless 1390
WLAN Mini-PCI Card [14e4:4311] (rev 01)
Lo anterior dice que nos estamos enfrentando ante una Broadcom cuyo chipset id es el 4311, debemos saber que el módulo para linux de estos chips es el bcm43xx y ha sido incluido al kernel de linux desde la versión 2.6.17-rc2Fuente: http://bcm43xx.berlios.de/, al revisar la lista de dispositivos soportados me percaté que el soporte para este chipset id aún es inestable, así que el siguiente paso era eliminar su presencia si aplicaba.
$ lsmod | grep bcm43xx
bcm43xx 148500 0
ieee80211softmac 40704 1 bcm43xx
ieee80211 39112 2 bcm43xx,ieee80211softmac
Como se puede observar en este caso aplica, así que comenzamos a eliminar su presencia.
# grep -q '^blacklist bcm43xx' /etc/modprobe.d/blacklist \\
|| tee -a 'blacklist bcm43xx' /etc/modprobe.d/blacklist
La inclusión de la línea blacklist bcm43xx al fichero /etc/modprobe.d/blacklist si aplica me permite indicar que dicho módulo no debe cargarse como resultado de la expansión de su alias, es decir, bcm43xx, esto se hace con el propósito de evitar que el subsistema hotplug lo carge, aunque esto no evita que el módulo se carge automáticamente por el kernel.
Luego verifique el fichero /etc/modules, el cual contiene los nombre de los módulos que serán cargados a la hora del inicio del sistema, no había entrada para el módulo bcm43xx, ahora es necesario remover dicho módulo, para lo cual hacemos:
# modprobe -r bcm43xx
Una vez culminado este proceso es necesario hacer uso de ndiswrapper, el cual es un módulo que me permite cargar y ejecutar drivers propietarios de Windows para tarjetas inalámbricas.
# aptitude -r install build-essential \\
module-assistant ndiswrapper-common
# m-a update
# m-a prepare
# m-a a-i ndiswrapper
# modprobe ndiswrapper
Una vez cargado el módulo ndiswrapper es necesario instalar el nuevo driver propietario, para ello debemos encontrar el fichero con extensión inf, este fichero especifica que ficheros necesitan estar presentes o descargarse para que el componente funcione correctamente, para dicho driver. Al consultar en la lista de tarjetas que funcionan con ndiswrapper me percato que han habido problemas de seguridad en algunos de los drivers recomendados para esta tarjeta, así que para asegurarme de obtener las versiones más recientes ingreso al sitio oficial de Dell, bajo la sección USA -> Support search: “m1210” -> Drivers and Downloads -> Network & Internet -> Network Driver, ingreso el campo correspondiente al service tag, y finalmente descargo el fichero R151517.EXE.
El siguiente paso es extraer los ficheros que se encuentran dentro de R151517.EXE, para ello:
unzip R151517.EXE
Ahora nos interesa el fichero bcmwl5.inf que está dentro del directorio DRIVER.
$ tree R151517/DRIVER/
R151517/DRIVER/
|-- bcm43xx.cat
|-- bcm43xx64.cat
|-- bcmwl5.inf
|-- bcmwl5.sys
`-- bcmwl564.sys
Una vez extraídos los ficheros, procedemos a cargar el driver, para ello hacemos lo siguiente:
# ndiswrapper -i R151517/DRIVER/bcmwl5.inf
Comprobamos que el driver se ha instalado correctamente.
# ndiswrapper -l
installed drivers:
bcmwl5 driver installed, hardware (14E4:4324) present (alternate driver: bcm43xx)
Luego verificamos nuestro trabajo al ejecutar el comando dmesg, tal como se muestra a continuación:
$ dmesg
[44093.473325] ndiswrapper version 1.27 loaded (preempt=no,smp=yes)
[44095.311236] ndiswrapper (link_pe_images:577): fixing KI_USER_SHARED_DATA address in the driver
[44093.482777] ndiswrapper: driver bcmwl5 (Broadcom,03/23/2006, 4.40.19.0) loaded
[44093.483250] ACPI: PCI Interrupt 0000:0c:00.0[A] -> GSI 17 (level, low) -> IRQ 177
[44093.483367] PCI: Setting latency timer of device 0000:0c:00.0 to 64
[44093.491760] ndiswrapper: using IRQ 177
[44094.162703] wlan0: vendor:
[44094.162708] wlan0: ethernet device 00:18:f3:6b:fc:3b using NDIS driver bcmwl5, 14E4:4311.5.conf
[44094.162772] wlan0: encryption modes supported: WEP; TKIP with WPA, WPA2, WPA2PSK; AES/CCMP with WPA, WPA2, WPA2PSK
[44094.166554] usbcore: registered new driver ndiswrapper
[44094.167390] ndiswrapper: changing interface name from 'wlan0' to 'eth1'
En este preciso instante el comando ifconfig -a debe mostrarnos la nueva interfaz, y el comando iwlist eth1 scan al ejecutarse como superusuario devolverá la lista de redes que han sido detectadas.
Recuerde que para que todo esto siga funcionando aún después de reiniciar el sistema, es necesario cargar el módulo de ndiswrapper, para ello hago uso del comando modconf.
*[PCI]: Peripheral Component Interconnect
network-manager
Network Manager: Facilitando el manejo de redes inalámbricas
En la entrada previa, Establecer red inalámbrica en Dell m1210, comencé a describir el proceso que seguí para lograr hacer funcionar la tarjeta Broadcom Corporation Dell Wireless 1390 WLAN Mini-PCI Card (rev 01) en una portátil Dell m1210. El motivo de esta entrada se debe a que muchos usuarios hoy día no les interesa ni debe interesarles estar lidiando con la detección de redes inalámbricas, por eso les pasaré a comentar acerca de NetworkManager.
NetworkManager es una aplicación cuyo objetivo es que el usuario nunca tenga que lidiar con la línea de comandos o la edición de ficheros de configuración para manejar sus redes (ya sea cableada o inalámbrica), haciendo que la detección de dichas redes simplemente funcione tanto como se pueda y que interrumpa lo menos posible el flujo de trabajo del usuario. De manera que cuando usted se dirija a áreas en las cuales usted ha estado antes, NetworkManager se conectará automáticamente a la última red que haya escogido. Asimismo, cuando usted esté de vuelta al escritorio, NetworkManager cambiará a la red cableada más rápida y confiable.
Por los momentos, NetworkManager soporta redes cifradas WEP, el soporte para el cifrado WPA está contemplado para un futuro cercano. Respecto al soporte de VPN, NetworkManager soporta hasta ahora vpnc, aunque también está contemplado darle pronto soporte a otros clientes.
Para hacer funcionar NetworkManager en Debian los pasos que debemos seguir son los siguientes. En primera instancia instalamos el paquete.
# aptitude -r install network-manager-gnome
Que conste que NetworkManager funciona para entornos de escritorios como GNOME, KDE, XFCE, entre otros. En este caso particular estoy instalando el paquete disponible en Debian para GNOME en conjunto con sus recomendaciones.
De acuerdo al fichero /usr/share/doc/network-manager/README.Debian NetworkManager consiste en dos partes: uno a nivel del demonio del sistema que se encarga de manejar las conexiones y recoge información acerca de las nuevas redes. La otra parte es un applet que el usuario emplea para interactuar con el demonio de NetworkManager, dicha interacción se lleva a cabo a través de D-Bus.
En Debian por seguridad, los usuarios que necesiten conectarse al demonio de NetworkManager deben estar en el grupo netdev. Si usted desea agregar un usuario al grupo netdev utilice el comando adduser usuario netdev, luego de ello tendrá que recargar dbus haciendo uso del comando /etc/init.d/dbus reload.
Es necesario saber que NetworkManager manejará todos aquellos dispositivos que no estén listados en el fichero /etc/network/interfaces, o aquellos que estén listados en dicho fichero con la opción auto o dhcp, de esta manera usted puede establecer una configuración para un dispositivo que sea estática y puede estar seguro que NetworkManager no tratará de sobreescribir dicha configuración. Para mayor información le recomiendo leer detenidamente el fichero /usr/share/doc/network-manager/README.Debian.
Si usted desea que NetworkManager administre todas las interfaces posibles en su ordenador, lo más sencillo que puede hacer es dejar solo lo siguiente en el fichero /etc/network/interfaces.
$ cat /etc/network/interfaces
auto lo
iface lo inet loopback
Una vez que se ha modificado el fichero /etc/network/interfaces reiniciamos NetworkManager con el comando service network-manager restart. El programa ahora se encargará de detectar las redes inalámbricas disponibles. Para ver una lista de las redes disponibles, simplemente haga clic en el icono, tal como se muestra en la figura al principio de este artículo.
Había mencionado previamente que NetworkManager se conectará automáticamente a las redes de las cuales tiene conocimiento con anterioridad, pero usted necesitará conectarse manualmente a una red al menos una vez. Para ello, simplemente seleccione una red de la lista y NetworkManager automáticamente intentará conectarse. Si la red requiere una llave de cifrado, NetworkManager le mostrará un cuadro de dialogo en el cual le preguntará acerca de ella. Una vez ingresada la llave correcta, la conexión se establecerá.
Para cambiar entre redes, simplemente escoja otra red desde el menú que le ofrece el applet.
nvidia
nVIDIA en Ubuntu 6.04
Hace unos días actualicé mi Ubuntu 5.10 a una de sus últimas versiones de testing: Flight 5. Debo admitir que quedé anonadado por lo cambios en la distribución, ya que con todas las mejoras que tiene parece que hubiera pasado, no sólo 6 meses sino años. El Dapper Drake (Flight 5, Ubuntu 6.04) es mucho mejor que sus antecesores. Pero la razón por la cual me decidí a escribir éste artículo es otra: la instalación de los drivers de mi tarjeta nVIDIA y su puesta en funcionamiento a punto.
Cuando actualicé mi sistema no hubo ningún problema, y lo digo en serio, ningún problema de ninguna índole. Toda mi configuración de escritorio quedó intacta; pero empecé a notar que la configuración de la tarjeta de video no se cargaba con el sistema. Entonces supe que, por alguna razón, los drivers de la tarjeta habían cambiado, es decir, el sistema asignó el driver por defecto para la tarjeta, más no los drivers de la tarjeta misma. Entonces tuve que ponerme a configurar la tarjeta.
Lo primero que hice fué verificar que los drivers vinieran con la distribución. Lo hice con la siguiente línea:
$ sudo aptitude search nvidia
Con lo cual obtuve lo siguiente:
i nvidia-glx - NVIDIA binary XFree86 4.x/X.Org driver
v nvidia-kernel-1.0.7174 -
v nvidia-kernel-1.0.8178 -
i nvidia-kernel-common - NVIDIA binary kernel module common files
Entonces ya sabía que los drivers venían con la distro, lo cual me pareció fascinante, ya que en realidad el Flight 5, no es la versión definitiva del Dapper Drake. Luego procedí a verificar la documentación de dicho paquete. Ésto lo hice con la siguiente línea de comandos:
$ sudo aptitude show nvidia-glx
Esto lo hice para verificar que no haya alguna clase de conflictos con otros paquetes, pero en realidad no es un paso necesario, ya que aptitude resuelve todo tipo de conflictos y dependencias. Después de verificar que todo estaba en orden me decidí a instalar los drivers. Ésto lo hice con la siguiente linea de comandos:
$ sudo aptitude install nvidia-glx
Con lo cual quedaron instalados los drivers de la tarjeta de manera trasparente y rápida. Lo siguiente que debía hacer, era activar la configuración de la tarjeta. Lo cual hice con la siguiente línea de comandos:
$ sudo nvidia-glx-config enable
Una vez hecho ésto ya podía configurar la tarjeta. Algo que hay que hacer notar es que, para las distribuciones anteriores de Ubuntu, había que instalar de manera separada el paquete nvidia-glx y el nvidia-settings, sin embargo, aquí queda todo instalado de una vez. Lo que sigue es iniciar la configuración de la tarjeta, lo cual hice con la siguiente línea de comandos:
$ nvidia-settings
Y ya tenía acceso a la configuración de mi tarjeta. Sin embargo, al hacer todo ésto, la configuración no se carga al iniciar el sistema, pero no fué problema, porque lo solucioné colocando en los programas de inicio del gnome-session-manager los siguiente:
nvidia-settings -l
Este comando carga la configuración de nvidia-settings que tengamos actualmente. Es lo mismo que, una vez que haya cargado el sistema, ejecutemos en la consola éste comando, sólo que ahora se va a ejecutar apenas inicie el sistema operativo.
Otros ajustes…
Si quieren colocar un lanzador en los menús del panel de gnome deben hacer los siguiente:
$ sudo gedit /usr/share/applications/NVIDIA-Settings.desktop
Y luego insertar lo siguiente en dicho fichero:
[Desktop Entry]
Name=Configuración nVIDIA
Comment=Abre la configuración de nVIDIA
Exec=nvidia-settings
Icon=(el icono que les guste)
Terminal=false
Type=Application
Categories=Application;System;
Y ya tendrán un lanzador en los menús del panel de gnome. Una opción sería utilizar el editor de menús Alacarte.
nvidia-xconf
nvidia-xconf es una utilidad diseñada para hacer fácil la edición de la configuración de X. Para ejecutarlo simplemente debemos escribir en nuestra consola lo siguiente:
$ sudo nvidia-xconfig
Pero en realidad, ¿qué hace nvidia-xconfig? nvidia-xconfig, encontrará el fichero de configuración de X y lo modificará para usar el driver nVIDIA X. Cada vez que se necesite reconfigurar el servidor X se puede ejecutar desde la terminal. Algo interesante es que cada vez que modifiquemos el fichero de configuración de X con nvidia-xconfig, éste hará una copia de respaldo del fichero y nos mostrará el nombre de dicha copia. Algo muy parecido a lo que sucede cada vez que hacemos:
dpkg-reconfigure xserver-xorg
Una opción muy útil de nvidia-xconfig es que podemos añadir resoluciones al fichero de configuración de X simplemente haciendo:
$ sudo nvidia-xconfig --mode=1280x1024
…por ejemplo.
pam
Fortaleciendo nuestras contraseñas
Si una de las promesas que tiene para este cierre de año es fortalecer las
contraseñas en sus equipos personales, cambiarlas mensualmente y no repetir la
misma contraseña en al menos doce cambios. En este artículo se le explicará como
hacerlo sin tener que invertir una uva en ello, todo esto gracias al paquete
libpam-cracklib en Debian, el procedimiento mostrado debe aplicarse a otras
distribuciones derivadas de Debian.
Pareciese lógico que algunas de las mejores prácticas para el fortalecimiento de las contraseñas son las siguientes:
- Cambiar las contraseñas periódicamente.
- Establecer una longitud mínima en las contraseñas.
- Establecer buenas reglas para las nuevas contraseñas, es decir, mezcla entre letras mayúsculas, minúsculas, dígitos y caracteres alfanuméricos.
- Mantener un histórico de las contraseñas usadas previamente, de ese modo, alentamos a los usuarios establecer nuevas contraseñas.
- Indicarle a los usuarios que es inaudito que se anoten las contraseñas en un post-it y se dejen pegadas en los monitores o incluso en las gavetas de sus archivadores.
El primer paso es instalar el paquete libpam-cracklib
# apt-get install libpam-cracklib
A partir de la versión 1.0.1-6 de PAM se recomienda manejar la configuración vía
pam-auth-update. Por lo tanto, por favor tome un momento y lea la sección 8
del manual del comando pam-auth-update para aclarar su uso y ventajas.
$ man 8 pam-auth-update
Ahora establezca una configuración similar a la siguiente, vamos primero con la
exigencia en la fortaleza de las contraseñas, para ello edite o cree el fichero
/usr/share/pam-configs/cracklib.
Name: Cracklib password strength checking
Default: yes
Priority: 1024
Conflicts: unix-zany
Password-Type: Primary
Password:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
Password-Initial:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
NOTA: Le recomiendo leer la sección 8 del manual de pam_cracklib para
encontrar un mayor numero de opciones de configuración. Esto es solo un ejemplo.
En versiones previas el modulo pam_cracklib hacia uso del fichero
/etc/security/opasswd para conocer si la propuesta de cambio de contraseña no
había sido utilizada previamente. Dicha funcionalidad ahora corresponde al nuevo
modulo pam_pwhistory
Definamos el funcionamiento de pam_pwhistory a través del fichero
/usr/share/pam-configs/history.
Name: PAM module to remember last passwords
Default: yes
Priority: 1023
Password-Type: Primary
Password:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
Password-Initial:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
NOTA: Para mayor detalle de las opciones puede revisar la sección 8 del
manual de pam_pwhistory
Seguidamente proceda a actualizar la configuración de PAM vía pam-auth-update.
Una vez cubierta la fortaleza de las contraseñas nuevas y de evitar la reutilización de las ultimas 12, de acuerdo al ejemplo mostrado, resta cubrir la definición de los periodos de cambio de las contraseñas.
Para futuros usuarios debemos ajustar ciertos valores en el fichero
/etc/login.defs
#
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 30
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Las reglas previas no aplicaran para los usuarios existentes, pero para este
tipo de usuarios podremos hacer uso del comando chage de la siguiente manera:
# chage -m 0 -M 30 -W 5 ${user}
Donde el valor de ${user} debe ser reemplazo por el username.
pbuilder
Instalando dependencias no-libres de JAVA en ambientes pbuilder
El día de hoy asumí la construcción de unos paquetes internos compatibles con
Debian 5.0 (a.k.a. Lenny) que anteriormente eran responsabilidad de
ex-compañeros de labores. El paquete en cuestión posee una dependencia
no-libre, sun-java6-jre. En este artículo se describirá como lograr
adecuar su configuración de pbuilder para la correcta construcción del
paquete.
Asumiendo que tiene un configuración similar a la siguiente:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
Para mayor información sobre estas opciones sírvase leer:
$ man 5 pbuilderrc
Mientras intenta compilar su paquete en el ambiente proporcionado por pbuilder
el proceso fallará ya que no se mostró la ventana para aceptar la licencia de
JAVA. Podrá observar en el registro de la construcción del build un mensaje
similar al siguiente:
Unpacking sun-java6-jre (from .../sun-java6-jre_6-20-0lenny1_all.deb) ...
sun-dlj-v1-1 license could not be presented
try 'dpkg-reconfigure debconf' to select a frontend other than noninteractive
dpkg: error processing /var/cache/apt/archives/sun-java6-jre_6-20-0lenny1_all.deb (--unpack):
subprocess pre-installation script returned error exit status 2
Para evitar esto altere la configuración del fichero pbuilderrc de la
siguiente manera:
$ cat /etc/pbuilderrc
MIRRORSITE=http://example.com/debian
DEBEMAIL="Maintainer Name <[email protected]>"
DISTRIBUTION=lenny
DEBOOTSTRAP="cdebootstrap"
COMPONENTS="main contrib non-free"
export DEBIAN_FRONTEND="readline"
Una vez alterada la configuración podrá interactuar con las opciones que le
ofrece debconf.
Ahora bien, si usted constantemente tiene que construir paquetes con dependencias no-libres como las de JAVA, es probable que le interese lo que se menciona a continuación.
Si lee detenidamente la página del manual de pbuilder en su sección 8 podrá
encontrar lo siguiente:
$ man 8 pbuilder
...
--save-after-login
--save-after-exec
Save the chroot image after exiting from the chroot instead of deleting changes. Effective for login and execute session.
...
Por lo tanto, usaremos esta funcionalidad que ofrece pbuilder para insertar
valores por omisión en la base de datos de debconf para que no se nos pregunte
si deseamos aceptar la licencia de JAVA:
# pbuilder login --save-after-login
I: Building the build Environment
I: extracting base tarball [/var/cache/pbuilder/base.tgz]
I: creating local configuration
I: copying local configuration
I: mounting /proc filesystem
I: mounting /dev/pts filesystem
I: Mounting /var/cache/pbuilder/ccache
I: policy-rc.d already exists
I: Obtaining the cached apt archive contents
I: entering the shell
File extracted to: /var/cache/pbuilder/build//27657
pbuilder:/# cat > java-license << EOF
> sun-java6-bin shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jdk shared/accepted-sun-dlj-v1-1 boolean true
> sun-java6-jre shared/accepted-sun-dlj-v1-1 boolean true
> EOF
pbuilder:/# debconf-set-selections < java-license
pbuilder:/# exit
logout
I: Copying back the cached apt archive contents
I: Saving the results, modifications to this session will persist
I: unmounting /var/cache/pbuilder/ccache filesystem
I: unmounting dev/pts filesystem
I: unmounting proc filesystem
I: creating base tarball [/var/cache/pbuilder/base.tgz]
I: cleaning the build env
I: removing directory /var/cache/pbuilder/build//27657 and its subdirectories
perl
Perl y su poderío
Al igual que José, considero que el hilo de discusión Borrar línea X de un archivo es bastante interesante, este hilo fué discutido en la lista de correos técnica l-linux es la la lista de correos para Consultas Técnicas sobre Linux y Software Libre en VELUG del Grupo de Usuarios de Linux de Venezuela (VELUG), el problema planteado por quien inicio el hilo de discusión, José Luis Bazo Villasante, consistía en eliminar un registro completo, en donde se pasara como argumento el primer campo (tal vez el identificador) de dicho registro.
Suponga que el fichero tiene la siguiente estructura:
:(123
... # otros campos
)
:(234
... # otros campos
)
:(456
... # otros campos
)
Se dieron soluciones en lenguajes como Bash y C ¿Con intención de autoflagelación? y ciertas en Perl, éstas últimas son las que llaman mi atención, vamos por partes Diría Jack El Destripador.
José propuso lo siguiente:
#!/usr/bin/perl -n
$deadCount = 7 if ($_ =~ /${ARGV[0]}/);
--$deadCount if ($deadCount);
print unless ($deadCount);El programa debe ejecutarse así:
$ perl script.pl archivo 123
Este programa hace el trabajo, pero al final emitirá un error porque cree que el argumento 123 es otro fichero, y por supuesto, no lo encuenta.
Mi solución fue la siguiente:
perl -ne 'print unless /:\\(123/../\\)/' input.data > output.dataPor supuesto, en este caso solamente estaría eliminando el registro cuyo primer elemento es 123, funciona, pero genera un problema al igual que el hecho por José, se deja una línea de espacio vacía adicional en los registros, cuando el separador de los grupos de datos debe ser una No dos, ni tres, … línea en blanco, tal cual como apunto Ernesto Hernández en una de sus respuestas.
Otro apunte realizado por el profesor Ernesto, fué que las soluciones presentadas hasta el momento de su intervención fué el análisis de fondo que estabamos haciendo, el problema no consistía en procesar cada una de las líneas, el trabajo en realidad consistía en analizar un registro multilínea (o párrafo), en términos más sencillos, cada grupo de datos (registros) está separado por una línea en blanco.
El profesor continuaba su excelente explicación diciendo que el problema se reduce al analizarlo de esta manera en lo siguiente:
…si se cuenta con un lenguaje de programación que está preparado para manejar el concepto de “registro” y puede definir el separador de registro como una línea en blanco, simplemente se trata de ignorar aquellos registros que tengan la expresión regular (X, donde X es la secuencia de dígitos que no nos interesa preservar.
La solución presentada por el profesor Ernesto fue:
perl -000 -i -ne 'print unless /\\(XXX/' archivoEn donde se debe sustituir las XXX por los dígitos cuyo bloque no nos interesa conservar.
De este hilo aprendí cosas nuevas de Perl, en realidad estoy comenzando, muchos pensarán que este código es críptico, por ello considero conveniente aclarar algunas cosas.
Lo críptico de un código no es inherente a un lenguaje particular, eso depende más del cómo se programe.
En este caso particular una sola línea de código nos proporciona mucha información, evidentemente para comprender dicho contenido es necesario leer previamente cierta documentación del lenguaje, pero ¿quien comienza a programar en un lenguaje en particular sin haber leído primero la documentación?, la respuesta parece lógica, ¿cierto?.
La existencia de opciones predefinidas y maneras de ejecutar el interprete de Perl permiten enfocarse únicamente en la resolucion de tareas, cero burocracia.
Un ejemplo de lo mencionado en el párrafo anterior es el siguiente, un bucle lo puedo reducir con la opción de ejecución -n del interprete Perl, simplemente leyendo un poco perlrunman perlrun, perlrun se incluye en la documentación de Perl, en sistemas Debian lo encontramos en el paquete perl-doc, para instalar simplemente hacer ejecutar el comando aptitude install perl-doc como superusuario nos enteramos del asunto, eso quiere decir que podemos reducir a una simple opción de ejecución del interprete de Perl todo esto:
#!/usr/bin/perl
while(<>){
#...
}¿Qué es ese operador que parece un “platillo volador”, según nos conto José Luis Rey, el profesor Ernesto Hernández le llama así de manera informal (null filehandle)?, bueno, lea perlop, en especial la sección I/O Operators.
La opción -i me permite editar (reescribir) in situ el fichero que vamos a procesar, en el caso de no añadir una extensión no se realizara un respaldo del fichero, el fichero original se sobreescribe. Mayor detalle en perlrun.
Lo que si no sabía hasta ahora, es lo explicado por el profesor acerca de los párrafos (registros multilínea) en Unix, la opción -0 tiene un valor especial, el cual es 00, si este valor es suministrado hace que Perl entre en “modo párrafo”, en pocas palabras, se reconoce una línea en blanco como el separador de los registros.
El resto del código es solo manejo de una sencilla expresión regular, se asume que el lector conoce algo del tema, solo indica el registro que queremos ignorar.
Así que podemos concluir lo siguiente, Perl no es críptico, asumiendo que el programador ha leido suficiente documentación acerca del lenguaje en cuestión, evitamos la burocracia y atendemos el problema de raíz en el menor tiempo posible.
La solución que propone Perl con el lema Hay más de una manera de hacerlo, es ofrecerle al programador libertad en su forma de expresarse, ¿acaso todos hablamos el mismo idioma?, ¿acaso debemos seguir las malas prácticas que intenta difundir el maligno Java?, coartar el pensar del programador y obligarlo a hacer las cosas al estilo Java, ¿dónde queda la imaginación? De hecho, se dice que, un programador experto en Java está muy cerca de convertirse en un autómata, ¿paso a ser un lujo?.
A todos los que lo deseen, les invito a participar en la lista de correos técnica (l-linux) del Grupo de Usuarios de Linux de Venezuela (VELUG), les recomiendo leer detenidamente las normas de uso antes de inscribirse en la lista.
postgresql
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
presentaciones
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
proxy
apt-get detrás de proxy con autenticación NTLM
Por motivos que no vienen al caso discutir en este artículo tuve que instalar Debian GNU/Linux detrás de un proxy que aún utiliza NTLM como medio de autenticación, aunque NTLM ya no es recomendado por Microsoft desde hace años en pro de usar Kerberos.
Una vez instalada la distribución quería utilizar apt-get para actualizarla e
instalar nuevos paquetes, el resultado fue que apt-get no funciona de manera
transparente detrás de un proxy con autenticación NTLM. La solución fue
colocar un proxy interno que esté atento a peticiones en un puerto particular
en el host, el proxy interno se encargará de proveer de manera correcta las
credenciales al proxy externo.
La solución descrita previamente resulta sencilla al utilizar cntlm. En
principio será necesario instalarlo vía dpkg, posteriormente deberá editar los
campos apropiados en el fichero /etc/cntlm.conf
- Username
- Domain
- Password
- Proxy
Seguidamente reinicie el servicio:
# /etc/init.d/cntlm restart
Ahora solo resta configurar apt-get para que utilice nuestro proxy interno,
para ello edite el fichero /etc/apt.conf.d/02proxy
Acquire::http::Proxy "http://127.0.0.1:3128";
NOTA: Se asume que el puerto de escucha de cntlm es el 3128.
Ahora puede hacer uso correcto de apt-get:
# apt-get update
# apt-get upgrade
...
NOTA FINAL: Es evidente que cualquier comando o herramienta que necesite
autenticarse contra el proxy externo deberá configurarlo para que utilice el
proxy interno, lo explicado en este artículo no solo aplica para el comando
apt-get.
python
libturpial needs your help
Do you want to begin to contribute into libturpial codebase but you don’t know where to start?, that’s ok, it also happens to me sometimes, but today, the reality is that we need your help to fix some errors reported by our style checker (flake8)
root
Vulnerabilidad grave corregida en ubuntu
La vulnerabilidad en ubuntu donde cualquiera con acceso al shell podía ver la contraseña del instalador del sistema ha sido reparada.
Los paquetes afectados son base-config y passwd en Ubuntu 5.10 (Breezy Badger), el problema puede ser corregido al actualizar los paquetes afectados a las versiones 2.67ubuntu20 (base-config) y 1:4.0.3-37ubuntu8 (passwd). En general, una actualización del sistema es suficiente para que los cambios surtan efecto.
La vulnerabilidad en donde era posible ver la constraseña del instalador de ubuntu y así tener acceso a privilegios de superusuario (por supuesto, si la contraseña no había sido cambiada desde la instalación) fue descubierta por Karl Øie, el instalador de Ubuntu 5.10 falla en la limpieza de contraseñas en los ficheros de registros de instalación. Dichos ficheros pueden ser leidos por cualquiera, de este modo cualquier usuario local pudiese ver las contraseñas del primer usuario, el cual tiene privilegios por completo en una instalación por defecto.
El paquete actualizado eliminará las contraseñas almacenadas en texto plano en los ficheros de registro de instalación y adicionalmente hará que los registros sean leídos únicamente por el superusuario.
Esta vulnerabilidad no afecta a los instaladores de las versiones 4.10, 5.04, o la que está por llegar, 6.04. Sin embargo, considere necesario aplicar el parche si usted ha actualizado su sistema desde Ubuntu 5.10 a la actual versión en desarrollo 6.04 (Dapper Drake), en este caso verifique que ha actualizado el paquete passwd a la versión 1:4.0.13-7ubuntu2.
rss
Proporcionando medios alternativos a las suscripciones RSS
Según un estudio de Nielsen//NetRatings, quienes se dedican al estudio de mercados y medios en internet, afirma que apenas el 11% de los lectores habituales de blogs, utilizan RSS (acrónimo de Sindicación Realmente Simple, Really Simple Syndication en inglés) para clasificar la lectura de la gran cantidad de blogs disponibles hoy día.
Del mismo estudio se desprende que apenas cerca del 5% de los lectores de blogs utiliza software de escritorio para leer sus suscripciones, mientras que un poco más del 6% utiliza un agregador en línea para ser notificado de los nuevos artículos existentes en los blogs.
A lo descrito previamente, tenemos que agregarle que se estima que el 23% de los lectores entiende lo qué es y para que sirven los RSS, pero en realidad no lo utilizan, mientras que el 66% de las personas en realidad no entienden de que trata la tecnología en discusión o nunca han escuchado de ella.
Ante esta situación, tendremos que buscar alternativas que quizás sean más efectivas que el uso de la sindicación de contenidos vía RSS para mantener informados a nuestros lectores acerca de los nuevos artículos disponibles en nuestras bitácoras.
¿Qué podemos hacer?, solamente tenemos que pensar en ofrecer un mecanismo alternativo, que sirva para que ese 89% pueda suscribirse a los contenidos que ofrecemos. En este artículo discutiremos sobre las suscripciones por correo electrónico.
Algunas ventajas del ofrecer suscripciones por correo son las siguientes:
- El usuario no necesita de una agregador de noticias, ya sea instalable en el escritorio o un servicio en línea. Lo anterior puede ser molesto o complejo para muchos usuarios.
- La mayoría de las personas reconocen lo que es un correo electrónico, incluso, manejan sus cuentas.
- Tanto teléfonos, como PDAs y otros dispositivos que pueden conectarse a la red pueden enviar y recibir correos electrónicos.
- El e-mail se ofrece como un medio alternativo en donde no es posible tener agregadores RSS.
- Puede realizar búsquedas de entradas antiguas, puesto que existen registros en su cuenta, tal cual como hace comúnmente con su correo electrónico.
- Hoy en día no deberiamos preocuparnos en borrar nuestros correos electrónicos, puesto que existen servicios que nos ofrecen gran capacidad de almacenamiento.
- Si el usuario lo desea, ¿por qué no ofrecerle otro medio de suscripción?.
Existen varios servicios que nos facilitan el ofrecer suscripciones a nuestros blogs por medio del correo electrónico. En este artículo discutiremos acerca de FeedBlitz.
FeedBlitz, es un servicio que convierte tus feeds (RSS y ATOM) en un correo electrónico y procederá a enviarlo a todas aquellas personas que se suscriban a este servicio.
Si estás familiarizado con el concepto de newsletter, puedes verlo como tal, pero el contenido de dicho newsletter son las entradas de los blogs a los que estás suscrito.
Algunos puntos que me parecen favorables del servicio es que el proceso de suscripción es muy sencillo, simplemente debe rellenarse un campo en el formulario, esto automáticamente registrará a los usuarios siempre y cuando estos sean nuevos con el servicio, generará una contraseña aleatoria para su cuenta. El usuario deberá simplemente responder al e-mail enviado por FeedBlitz y ¡eso es todo!. Con lo anterior nos aseguramos de obtener una cuenta de correo válida, este modo de verificación es común en muchos servicios que se ofrecen en la red.
Otro punto que me gusta de FeedBlitz es que te envia un solo correo diario, con el contenido actual de los blogs a los que estás suscrito, esto no lo hace por ejemplo RssFwd, el cual te envia un correo por cada nueva entrada existente en los blogs a los cuales estás suscrito, esto puede resultar frustrante (sobretodo en blogs muy activos) para muchos usuarios, me incluyo.
Además, FeedBlitz esta totalmente integrado con FeedBurner, servicio que utilizo para gestionar los RSS de esta bitácora.
Desde FeedBlitz puedes elegir el formato (Texto o HTML) en el que prefieras recibir las notificaciones en tu cuenta de correo electrónico.
¿No le gusto el servicio que ofrece FeedBlitz?, usted en cualquier momento puede dejar de recibir las notificaciones vía correo electrónico, en cada mensaje tiene la información necesaria para darse de baja del servicio.
rufus
Clientes BitTorrent
Desde mi punto de vista Azureus es un cliente BitTorrent que cae en los excesos, aparte de ello es demasiado lento y por si fuera poco consume una gran cantidad de recursos del sistema.
Si usted es usuario de Ubuntu Linux, seguramente estará preguntándose, ¿por qué buscar un cliente BitTorrent si Breezy incluye uno? , bueno, si le soy sincero, ese cliente apesta, tiene muy pocas opciones.
En los siguientes párrafos veremos dos alternativas, que desde mi punto de vista tienen ciertas virtudes, las cuales muestro a continuación.
- No caen en los excesos.
- Son rápidos.
- No consumen gran cantidad de recursos del sistema.
- Ofrecen muchas opciones.
Sin mas preámbulos, les presento a Rufus y freeloader, clientes BitTorrents alternativos de gran envergadura.
FreeLoader
Freeloader, es un manejador de descargas escrito en Python y brinda soporte a torrents.
Para instalar freeloader debemos seguir los siguientes pasos en Breezy.
sudo aptitude install python-gnome2-extras python2.4-gamin
Seguidamente diríjase al sitio oficial de freeloader y descargue las fuentes del programa, para la fecha en la cual se redactó este artículo la versión más reciente de este programa es la 0.3.
wget http://www.ruinedsoft.com/freeloader/freeloader-0.3.tar.bz2
Luego de haber descargado el paquete proceda de la siguiente manera:
$ tar xvjf freeloader-0.3.tar.bz2
$ cd freeloader-0.3
$ ./configure
$ make
$ sudo make install
Recuerde que para poder compilar paquetes desde las fuentes necesita tener instalado previamente el paquete build-essential
Rufus
Rufus es otro cliente BitTorrent escrito en Python.
Vamos a aprovecharnos del hecho que existe una versión estable (0.6.9) compilada * para Breezy, los pasos son los siguientes:
$ wget http://strikeforce.dyndns.org/files/breezy/rufus.0.6.9/rufus_0.6.9-0ubuntu1_i386.deb
$ sudo dpkg -i rufus_0.6.9-0ubuntu1_i386.deb
- Esta versión ha sido compilada por strikeforce, para mayor información lea el hilo Rufus .deb Package.
scm
Instalación básica de Trac y Subversion
En este artículo se pretenderá mostrarle el proceso de instalación de un ambiente de desarrollo que le permitirá hacerle seguimiento a su proyecto personal, de igual manera se le indicará el modo en el cual puede comenzar a utilizar un sistema de control de versiones. Todas las indicaciones mostradas en este documento han sido probadas en la distribución Debian GNU/Linux 5.0 (nombre código Lenny).
La herramienta de seguimiento o manejo del proyecto que se procederá a instalar es Trac, el sistema de control de versiones que se presentará será Subversion. Todo lo anterior se presentará vía Web haciendo uso del servidor Apache, de manera adicional se utilizará el servidor de bases de datos PostgreSQL como backend de Trac.
Dependencias
En primer lugar proceda a instalar las siguientes dependencias.
# aptitude install apache2 \
libapache2-mod-python \
postgresql \
subversion \
python-psycopg2 \
libapache2-svn \
python-subversion \
trac
La versión de Trac que se encuentra en los archivos de Debian Lenny es estable (0.11.1). Sin embargo, si usted compara esta versión con lo publicado en el sitio oficial de Trac, podrá encontrar que existen nuevas versiones estables de mantenimiento que contienen correcciones a errores de programación y algunas nuevas funcionalidades de bajo impacto, para el momento de la redacción de este artículo se encuentra la versión 0.11.7. Es recomendable que utilice el paquete trac desde el archivo backports de Debian.
# aptitude -t lenny-backports install trac
Si desea usar el paquete proveniente del archivo backports le recomiendo leer las instrucciones de uso de este repositorio de paquetes.
Con el fin de mantener este artículo lo más sencillo y conciso posible se describirá la versión que viene por defecto con la distribución utilizada en este caso.
Versión de desarrollo de Trac
Si desea conocer algunas características interesantes que se han agregado a Trac en las nuevas versiones, o si su interés particular es
examinar las bondades que le ofrece Trac en su versión de desarrollo puede hacer uso del comando pip, si no tiene instalado pip proceda como sigue:
# aptitude install python-setuptools
# easy_install pip
Proceda a instalar la versión de desarrollo de Trac.
# pip install https://svn.edgewall.org/repos/trac/trunk
Creación de usuario y base de datos
Antes de proceder con la instalación de Trac se debe establecer el usuario y la base de datos que se utilizará para trabajar.
En el siguiente ejemplo el usuario de la base de datos PostgreSQL que utilizará Trac será trac_user, su contraseña será trac_passwd. El uso de la contraseña lo del usuario trac_user lo veremos más tarde al proceder a configurar el ambiente de Trac.
# su postgres
$ createuser \
--no-superuser \
--no-createdb \
--no-createrole \
--pwprompt \
--encrypted trac_user
Enter password for new role:
Enter it again:
CREATE ROLE
Nótese que se debe utilizar el usuario postgres (u otro usuario con los privilegios necesarios) del sistema para proceder a crear los usuarios.
Ahora procedemos a crear la base de datos trac_dev, cuyo dueño será el usuario trac_user.
$ createdb --encoding UTF8 --owner trac_user trac_dev
Ambiente de Trac
Creamos el directorio /srv/www que será utilizado para prestar servicios Web, para mayor referencia acerca de esta elección se le recomienda leer el documento Filesystem Hierarchy Standard en su versión 2.3.
$ sudo mkdir -p /srv/www
$ cd /srv/www
Generamos el ambiente de Trac. Básicamente se deben contestar ciertas preguntas como:
- Nombre del proyecto.
- Enlace con la base de datos que se utilizará.
- Sistema de control de versiones a utilizar (por defecto será SVN).
- Ubicación absoluta del repositorio a utilizar.
- Ubicación de las plantillas de Trac.
En el siguiente ejemplo se omitirán los comentarios brindados por el comando trac-admin.
# trac-admin project initenv
Creating a new Trac environment at /srv/www/project
...
Project Name [My Project]> Demo
...
Database connection string [sqlite:db/trac.db]>
postgres://trac_user:trac_passwd@localhost:5432/trac_dev
...
Repository type [svn]>
...
Path to repository [/path/to/repos]> /srv/svn/project
...
Templates directory [/usr/share/trac/templates]>
Creating and Initializing Project
Installing default wiki pages
...
---------------------------------------------------------
Project environment for 'Demo' created.
You may now configure the environment by editing the file:
/srv/www/project/conf/trac.ini
...
Congratulations!
Se ha culminado la instalación del ambiente de Trac, ahora procederemos a crear el ambiente de subversion.
Subversion: Sistema Control de Versiones
La puesta a punto del sistema de control de versiones es bastante sencilla, se resume en los siguientes pasos.
Creación del espacio para prestar el servicio SVN, de igual manera se seguirá los lineamientos planteados en el FHS v2.3 mencionado previamente.
# mkdir -p /srv/svn
Seguidamente crearemos el proyecto subversion project y haremos un importe inicial con la estructura básica de un proyecto de desarrollo de software.
$ cd /srv/svn
# svnadmin create project
$ mkdir -p /tmp/project/{trunk,tags,branches}
$ tree /tmp/project/
/tmp/project/
├── branches
├── tags
└── trunk
# svn import /tmp/project/ \
file:///srv/svn/project/ \
-m 'Importe inicial'
Adding /tmp/project/trunk
Adding /tmp/project/branches
Adding /tmp/project/tags
Committed revision 1.
Apache: Servidor Web
Es hora de configurar los sitios virtuales que utilizaremos tanto para Trac como para subversion.
A continuación se presenta la configuración básica de Trac.
# cat > /etc/apache2/sites-available/trac.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName trac.example.com
> CustomLog /var/log/apache2/trac.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/trac.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/www/project
> <Location />
> SetHandler mod_python
> PythonInterpreter main_interpreter
> PythonHandler trac.web.modpython_frontend
> PythonOption TracEnv /srv/www/project
> PythonOption TracUriRoot /
> </Location>
> </VirtualHost>
> EOF
Ahora veamos la configuración básica de nuestro proyecto subversion.
# cat > /etc/apache2/sites-available/svn.example.com <<EOF
> <VirtualHost *>
> ServerAdmin webmaster@localhost
> ServerName svn.example.com
> CustomLog /var/log/apache2/svn.example.com/access.log combined
> ServerSignature Off
> ErrorLog /var/log/apache2/svn.example.com/error.log
> LogLevel warn
> DocumentRoot /srv/svn/project
> <Location />
> DAV svn
> SVNPath /srv/svn/project
> </Location>
> </VirtualHost>
> EOF
De acuerdo a la configuración mostrada es necesario crear los directorios /var/log/apache2/svn.example.com y /var/log/apache2/trac.example.com para mantener por separado el registro de accesos y errores de los sitios virtuales recién creados. De
lo contrario no podremos iniciar el servidor Web Apache.
# mkdir /var/log/apache2/{svn,trac}.example.com
Activamos el módulo DAV necesario para cumplir con la configuración mostrada para el sitio virtual svn.example.com.
# a2enmod dav
Activamos los sitios virtuales recién creados.
# a2ensite trac.example.com
# a2ensite svn.example.com
Como la puesta en marcha y configuración de un servidor DNS escapa a los fines de este artículo, simplemente definiremos los hosts en la tabla estática que se encuentra definida en el archivo /etc/hosts de la siguiente manera.
# cat >> /etc/hosts <<EOF
> 127.0.0.1 trac.example.com trac
> 127.0.0.1 svn.example.com svn
> EOF
Finalmente debemos forzar la recarga de la configuración del servidor Web Apache, esto con el fin de cargar el módulo DAV y los sitios virtuales definidos, es decir, trac.example.com y svn.example.com.
# /etc/init.d/apache2 force-reload
¡Felicitaciones!, ya puede ir a su navegador favorito y colocar cualquiera de los sitios virtuales que acaba de definir.
Recomendaciones
Una vez que haya llegado a este sección deberá comenzar a modificar adecuadamente los permisos para el usuario y grupo www-data (Servidor Web Apache) para que escriba en las ubicaciones que sea necesario tanto en Trac como en subversion.
La configuración de Trac podrá encontrarla en /srv/www/project/conf/trac.ini, para mayor detalle acerca de la configuración de este fichero se le recomienda leer el documento TracIni.
Si en su proyecto prevé que participarán otras personas, es recomendable establecer notificaciones de tickets y cambios en el
repositorio subversion, para esto último deberá revisar el hook post-commit y la documentación del paquete libsvn-notify-perl que le ofrece una extraordinaria cantidad de opciones.
Conozca el entorno de Trac y Subversion. Si desea agregar nuevas funciones a su instalación le recomiendo visitar el sitio Trac Hacks.
Espero poder mostrarles en próximos artículos algunas configuraciones más avanzadas en Trac, incluyendo la instalación, configuración y uso de plugins.
scripting
Perl: Primeras experiencias
La noche del sábado pasado, después de terminar de estudiar con Ana la cátedra Programación Paralela y Distribuida, me dispuse a revisar las distintas instancias de Planeta Linux, como normalmente hago, pero eso no fué suficiente, me puse a validar el feed que se estaba generando en ese momento (en particular, el feed de la instancia venezolana). Me percate de varios errores y advertencias, entre ellos me llamo la atención:
This feed does not validate.
In addition, this feed has an issue that may cause problems for some users. We recommend fixing this issue.
line 11, column 71: title should not contain HTML (20 occurrences) [help]
Luego de leer la ayuda noto que es recomendable cambiar todos los nombres de las entidades html a su equivalente decimal, es decir, si tenemos por ejemplo: © debe modificarse ©, de igual manera con el resto.
Tenía varias opciones, una de ellas era realizar el reemplazo masivo desde vim, pero esta tarea es realmente ineficiente por el hecho de tener que reemplazar todos los nombres de las entidades html a su equivalente decimal uno por uno, además de eso, debía hacerlo para las tres instancias presentes en Planeta Linux, primera opción descartada de entrada.
Aprovechando que la semana pasada, al igual que el profesor Francisco Palm, estuve presente en un curso sobre el lenguaje de programación Perl, el cual fué dictado por José Luis Rey con la ayuda de Daniel Rodríguez en las instalaciones de Fundacite Mérida, quería poner en práctica algunas de las cosas que aprendí en dicho curso.
Antes de continuar debo agradecer al profesor José Aguilar, a la ingeniera Blanca Abraham, y a la Sra. Tauka Shults por la oportunidad que me brindaron.
Una de las cosas que nos recalcó José Luis fué acerca de las virtudes que debía tener un programador, una de ellas debe ser la flojera, es decir, comenzar a escribir código realmente útil de inmediato, sin ningún requerimiento adicional como ocurre en lenguajes de programación como el C/C++, en donde es necesario realizar una serie de procedimientos antes de comenzar a escribir código útil.
Como mencione en el párrafo anterior, la idea es llegar a ser lo más productivo en el menor tiempo posible. Generar un hash de entidades de nombres html no me parecía el camino idóneo, así que recorde el tema de la flojera, sin pensarlo dos veces comence a buscar en search.cpan.org un módulo que me permitiera convertir los nombres de las entidades html a su equivalente decimal, como primer resultado obtuve lo que buscaba, el módulo HTML::Entities::Numbered, había encontrado mi salvación, leo un poco acerca de su uso y es más sencillo de lo que pensaba, siguiente paso, proceder a instalarlo.
Para debianizar un módulo en Perl es muy sencillo, en primer lugar debemos recurrir al comando dh-make-perl, si no lo tenemos instalado ya, debemos proceder como sigue:
# aptitude install dh-make-perl
Ahora ya podemos debianizar el módulo que requerimos, para ello tuve que realizar lo siguiente:
# dh-make-perl --build --cpan HTML::Entities::Numbered
Como lo puede apreciar, su uso es realmente sencillo, para una mejor explicación acerca de este último comando le recomiendo leer la entrada Instalando módulos de Perl en Debian escrita por Christian Sánchez, como era la primera vez que hacia uso del comando cpan tuve que configurarlo, esto no tomo mucho tiempo, el asistente ofrece explicaciones bastante detalladas.
Una vez realizado el proceso más complicado de toda la operación, el resto era escribir el código fuente que me permitiese convertir los nombres de las entidades html a su equivalente decimal, he aquí el resultado.
#!/usr/bin/perl -l
use strict;
use warnings;
use HTML::Entities::Numbered;
unless(open(INPUT, $ARGV[0])) { die "ERROR: No se especifico archivo para abrir. $!"; }
open(OUTPUT, ">$ARGV[0].bak");
while(<INPUT>){ print OUTPUT name2decimal($_) if chomp; }
¡Listo!, en tan pocas líneas de código he logrado resolver el problema, por supuesto, todo se redujo a buscar el módulo apropiado, una vez hecho los cambios a los ficheros de configuración de Planeta Linux procedí a actualizar la última versión en subversion.
Puede apreciar el antes y después de los cambios realizados.
solve
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
spam
¡Maldito Spam!, nos invade
Según las estadísticas del plugin Akismet para el día de hoy, solamente 7.961 de 523.708 son comentarios, trackbacks o pingbacks válidos, mientras que el resto es Spam, eso quiere decir que aproximadamente el 1.5% es aceptable, el resto es escoria.
Seguramente alguno de mis 3 lectores en este instante se estará preguntando como funciona Akismet, en la sección de respuestas a preguntas frecuentes podrá resolver esta interrogante.
When a new comment, trackback, or pingback comes to your blog it is submitted to the Akismet web service which runs hundreds of tests on the comment and returns a thumbs up or thumbs down.
No sé que estara sucediendo con dichas pruebas últimamente, puesto que en los comentarios de mi blog han aparecido muchos trackbacks escoria. Ante el abrumador aumento (se puede observar que el aumento es prácticamente exponencial según las estadísticas proporcionadas en sitio oficial de Akismet) del spam, muchos han decidido cerrar sus comentarios, solo basta darse una vuelta por technorati bajo el tag spam y ver las acciones de algunos.
No puedo negar que el funcionamiento de Akismet en general es excelente, de hecho, antes de probar Akismet contaba con 2 ó más alternativas para combatir el spam, después de probarlo, no fue necesario mantener ningún otro plugin, pero creo que bajo esta situación es necesario comenzar a evaluar otras posibilidades que ayuden a Akismet.
Algunas de las cosas que podemos hacer bajo WordPress son las siguientes:
Mejorar nuestras listas de moderación o listas negras
En el área administrativa, bajo Opciones -> Discusión, sección Moderación de comentarios, colocar una lista de palabras claves que aparezcan en estos comentarios escoria. Algunos de ellos no tienen sentido, otros te felicitan por tu trabajo, por ejemplo: Good design, Nice site, todo ese conjunto de palabras clave deben incluirse, si le gusta ser radical incluya dichas palabras clave en la sección Lista negra de comentarios, tenga cuidado si decide elegir esta última opción.
Desactivar los trackbacks
En mi caso, Akismet ha fallado en la detección de trackbacks escoria, por lo tanto, si usted quiere ser realmente radical, puede cerrarlos.
Para desactivar las entradas futuras puede ir a Opciones -> Discusión, y desmarcar la casilla de verificación que dice Permitir notificaciones de enlace desde otros weblogs (pingbacks y trackbacks).
Ahora bien, a pesar de que la oleada de spam está atacando entradas recientes, podemos asegurarnos de cerrar los trackbacks para entradas anteriores ejecutando una sencilla consulta SQL:
UPDATE wp_posts SET ping_status = 'closed';
Moderar comentarios
Puede decidir si todos los comentarios realizados en su bitácora, deberán ser aprobados por el administrador, está acción quizá le evite que se muestren trackbacks escoria en su sitio, pero no le evitará la ardua tarea de eliminarlos uno por uno o masivamente. Si quiere establecer está opción puede hacerlo desde Opciones -> Discusión, en la sección de Para que un comentario aparezca deberá marcar la casilla de verificación Un administrador debe aprobar el comentario (independientemente de los valores de abajo)
Eliminar un rango considerable de comentarios escoria
Esta solución la encontre después de buscar la manera más sencilla de eliminar cientos de mensajes escoria desde una consulta en SQL.
En primer lugar debemos ejecutar la siguiente consulta:
SELECT * FROM wp_comments ORDER BY comment_ID DESC
En ella debemos observar el rango de comentarios recientes y que sean considerados spam. Por ejemplo, supongamos que los comentarios cuyos ID’s están entre los números 2053 y 2062 son considerados spam. Luego de haber anotado el rango de valores, debe proceder como sigue:
UPDATE wp_comments SET comment_approved = 'spam' WHERE comment_ID BETWEEN 2053 AND 2062
Recuerde sustituir apropiadamente los valores correspondientes al inicio y final de los comentarios a ser marcados como spam. Debe recordar también que los comentarios marcados como spam no desaparecerán de su base de datos, por lo tanto, estarán ocupando un espacio que puede llegar a ser considerable, le recomiendo borrarlos posteriormente.
Utilizar plugins compatibles con Akismet
En la sección de respuestas a preguntas frecuentes de Akismet podrán resolver esta interrogante.
We ask that you turn off all other spam plugins as they may reduce the effectiveness of Akismet. Besides, you shouldn’t need them anymore! :) But if you are investigating alternatives, we recommend checking out Bad Behavior and Spam Karma, both which integrate with Akismet nicely.
Ya había probado con anterioridad Bad Behavior, de hecho, lo tuve antes de probar Akismet y funcionaba excelente, ahora, falta probar como se comporta al combinarlo con Spam Karma 2. Las instrucciones de instalación y uso son sencillas.
Referencias:
spam-karma
¡Maldito Spam!, nos invade
Según las estadísticas del plugin Akismet para el día de hoy, solamente 7.961 de 523.708 son comentarios, trackbacks o pingbacks válidos, mientras que el resto es Spam, eso quiere decir que aproximadamente el 1.5% es aceptable, el resto es escoria.
Seguramente alguno de mis 3 lectores en este instante se estará preguntando como funciona Akismet, en la sección de respuestas a preguntas frecuentes podrá resolver esta interrogante.
When a new comment, trackback, or pingback comes to your blog it is submitted to the Akismet web service which runs hundreds of tests on the comment and returns a thumbs up or thumbs down.
No sé que estara sucediendo con dichas pruebas últimamente, puesto que en los comentarios de mi blog han aparecido muchos trackbacks escoria. Ante el abrumador aumento (se puede observar que el aumento es prácticamente exponencial según las estadísticas proporcionadas en sitio oficial de Akismet) del spam, muchos han decidido cerrar sus comentarios, solo basta darse una vuelta por technorati bajo el tag spam y ver las acciones de algunos.
No puedo negar que el funcionamiento de Akismet en general es excelente, de hecho, antes de probar Akismet contaba con 2 ó más alternativas para combatir el spam, después de probarlo, no fue necesario mantener ningún otro plugin, pero creo que bajo esta situación es necesario comenzar a evaluar otras posibilidades que ayuden a Akismet.
Algunas de las cosas que podemos hacer bajo WordPress son las siguientes:
Mejorar nuestras listas de moderación o listas negras
En el área administrativa, bajo Opciones -> Discusión, sección Moderación de comentarios, colocar una lista de palabras claves que aparezcan en estos comentarios escoria. Algunos de ellos no tienen sentido, otros te felicitan por tu trabajo, por ejemplo: Good design, Nice site, todo ese conjunto de palabras clave deben incluirse, si le gusta ser radical incluya dichas palabras clave en la sección Lista negra de comentarios, tenga cuidado si decide elegir esta última opción.
Desactivar los trackbacks
En mi caso, Akismet ha fallado en la detección de trackbacks escoria, por lo tanto, si usted quiere ser realmente radical, puede cerrarlos.
Para desactivar las entradas futuras puede ir a Opciones -> Discusión, y desmarcar la casilla de verificación que dice Permitir notificaciones de enlace desde otros weblogs (pingbacks y trackbacks).
Ahora bien, a pesar de que la oleada de spam está atacando entradas recientes, podemos asegurarnos de cerrar los trackbacks para entradas anteriores ejecutando una sencilla consulta SQL:
UPDATE wp_posts SET ping_status = 'closed';
Moderar comentarios
Puede decidir si todos los comentarios realizados en su bitácora, deberán ser aprobados por el administrador, está acción quizá le evite que se muestren trackbacks escoria en su sitio, pero no le evitará la ardua tarea de eliminarlos uno por uno o masivamente. Si quiere establecer está opción puede hacerlo desde Opciones -> Discusión, en la sección de Para que un comentario aparezca deberá marcar la casilla de verificación Un administrador debe aprobar el comentario (independientemente de los valores de abajo)
Eliminar un rango considerable de comentarios escoria
Esta solución la encontre después de buscar la manera más sencilla de eliminar cientos de mensajes escoria desde una consulta en SQL.
En primer lugar debemos ejecutar la siguiente consulta:
SELECT * FROM wp_comments ORDER BY comment_ID DESC
En ella debemos observar el rango de comentarios recientes y que sean considerados spam. Por ejemplo, supongamos que los comentarios cuyos ID’s están entre los números 2053 y 2062 son considerados spam. Luego de haber anotado el rango de valores, debe proceder como sigue:
UPDATE wp_comments SET comment_approved = 'spam' WHERE comment_ID BETWEEN 2053 AND 2062
Recuerde sustituir apropiadamente los valores correspondientes al inicio y final de los comentarios a ser marcados como spam. Debe recordar también que los comentarios marcados como spam no desaparecerán de su base de datos, por lo tanto, estarán ocupando un espacio que puede llegar a ser considerable, le recomiendo borrarlos posteriormente.
Utilizar plugins compatibles con Akismet
En la sección de respuestas a preguntas frecuentes de Akismet podrán resolver esta interrogante.
We ask that you turn off all other spam plugins as they may reduce the effectiveness of Akismet. Besides, you shouldn’t need them anymore! :) But if you are investigating alternatives, we recommend checking out Bad Behavior and Spam Karma, both which integrate with Akismet nicely.
Ya había probado con anterioridad Bad Behavior, de hecho, lo tuve antes de probar Akismet y funcionaba excelente, ahora, falta probar como se comporta al combinarlo con Spam Karma 2. Las instrucciones de instalación y uso son sencillas.
Referencias:
stardict
StarDict: El diccionario que buscaba
Leyendo el ejemplar #14 de la revista Tux Magazine me encuentro con un interesante artículo, Learning Foreign Languages with jVLT and StarDict, la segunda aplicación descrita en dicho artículo, StartDict, llamó mi atención, así que a continuación se dará una breve revisión de la aplicación en cuestión.
¿Qué es StarDict?
StarDict es un diccionario internacional multiplataforma escrito en Gtk2, puede ser utilizado sin conexión a la web.
Características
-
Búsqueda de patrones: Usted puede buscar patrones de cadenas o caracteres usando comodines, por ejemplo, podrá usar el comodín
*para buscar una cadena arbitraria, el resultado puede ser vacío, mientras que con el uso del comodín?buscará una coincidencia con un carácter arbitrario. e.g. Suponiendo que tiene instalado el diccionario Inglés – Español, al buscar el patrón hell? encontrará como resultado la traducción de hello, mientras que con el uso del patrón hell* encontrará todas aquellas posibles coincidencias que comiencen con la cadena hell, hell (infierno en inglés), hell (suerte en noruego), los resultados encontrados dependerá de los diccionarios que haya instalado. - Búsqueda difusa: Si usted por casualidad no recuerda exactamente como deletrear una palabra, podrá intentar realizar dicha búsqueda desde StarDict, éste utilizará el algoritmo de la Distancia de Levenshtein El algoritmo de la Distancia de Levenshtein o la distancia de edición entre dos cadenas, se refiere al número mínimo de operaciones necesarias para transformar una cadena en otra, bajo éste algoritmo se considera una operación a la inserción, eliminación o substitución de un carácter. Para mayor información le recomiendo leer el artículo Levenshtein Distance, in Three Flavors.. Para utilizar esta característica simplemente comience la búsqueda con el carácter /, e.g., suponga que tiene instalado el diccionario Español – Inglés, usted cree que la palabra acero realmente se escribe así: asero, simplemente introduzca en el formulario la cadena /asero, obtendrá el resultado deseado.
-
Búsqueda por palabras seleccionadas: Si usted desea activar esta característica, deberá marcar la casilla de verificación que se encuentra en la parte inferior izquierda de la ventana principal de la aplicación. StarDict automáticamente buscará palabras o frases que usted haya seleccionado en cualquier aplicación, esto incluye navegadores, OpenOffice.org, etc., usted obtendrá un cuadro de dialogo que le mostrará la definición acerca de la palabra seleccionada.
-
Manejo de diccionarios: StarDict le permite activar (desactivar) aquellos diccionarios que necesite (no necesite), también puede establecer el orden de búsqueda en los distintos diccionarios instalados. Todo lo anterior podrá realizarlo desde la sección Manage Dictionaries (Recurso: Imagen).
- ¿No encuentra lo que necesita?: StarDict le permite realizar búsquedas en la web, solo deberá seleccionar el botón de búsqueda en Internet y escoger cualquiera de las 10 opciones actuales de búsqueda.
Ahora bien, seguramente esta aplicación resultará útil para muchas personas, si usted es uno de ellos y está interesado en instalarlo, es muy sencillo.
¿Cómo instalar StarDict?
Si usted es tan afortunado como yo, debe estar usando Debian, así que simplemente tendrá que hacer:
# aptitude install stardict
Ahora bien, si usted utiliza por ejemplo, Ubuntu, también puede instalarlo fácilmente, ¿cómo?, en primer lugar debe activar el repositorio universe (recuerde actualizar la lista de paquetes disponibles), posteriormente debe hacer:
$ sudo aptitude install stardict
Si usted utiliza otra distribución de GNU+Linux o es usuario de Windows, lea la documentación de la página oficial del proyecto, lamento informarle que este artículo es una revisión breve de la aplicación StarDict.
¿Cómo instalar diccionarios?
Primero que nada, debe descargar los diccionarios que necesite, para ello le recomiendo ir a la página de Descarga de Diccionarios del proyecto.
Una vez que haya descargado los diccionarios, debe proceder como sigue:
tar -C /usr/share/stardict/dic -x -v -j -f \\
diccionario.tar.bz2
Personalizando la aplicación
Ya para finalizar, usted puede personalizar la aplicación desde la sección de preferencias, desde ella podrá modificar el comportamiento del programa.
Una característica de StarDict que puede resultar realmente molesta es cuando se encuentra activo el modo Scan, es decir, toda palabra o frase resaltada con el ratón generará un cuadro de dialogo con la definición de dicha palabra o frase, si usted desea controlar este comportamiento, le recomiendo activar las siguientes casillas de verificación:
- Only do scanning while modifier key being pressed.
- Hide floating window when modifier key pressed.
Las casillas de verificación previamente mencionadas podrá encontrarlas bajo la sección Dictionary -> Scan Selection.
Si usted esta inconforme con las opciones de búsqueda en Internet, puede agregar las que usted desea desde la sección Main Window -> Search Website.
suse
Instalinux: Instalando Linux de manera desatentida
Instalar GNU/Linux de manera desatendida ahora es realmente fácil haciendo uso de instalinux, esta interfaz web a través de unas preguntas acerca de como deseamos configurar nuestro sistema, nos permitirá crear una imagen que facilitará la instalación del sistema GNU/Linux de manera desatendida. Usted lo inserta, escribe install, y luego cuando regrese más tarde, tendrá un sistema GNU/Linux (la distribución de su escogencia) totalmente funcional esperando por usted.
Para todo lo descrito previamente, instalinux hace uso de scripts escritos en Perl que son parte del proyecto de código abierto LinuxCOE, desarrollado por Hewlett Packard.
Hasta ahora este servicio web gratuito permite crear métodos de instalación desatendida para las siguientes distribuciones:
- Fedora Core 4
- Debian
- SUSE
- Ubuntu
Instalinux nos permite seleccionar aquellos componentes que deseamos, posteriormente se crea una imagen de aproximadamente 30MB, la cual es clave para realizar la instalacion desatendida. Una vez culminado el proceso debemos descargar dicha imagen a nuestro disco duro.
Hasta ahora la propuesta que trae dicha interfaz gráfica me fascina, quizá el único punto débil que le veo es que posterior a la descarga de los aproximadamente 30MB usted deberá descargar los paquetes que solicite la instalación en su caso, esto último puede generar trauma en aquellas personas que no cuenten con conexiones de banda ancha.
sysadmin
Fortaleciendo nuestras contraseñas
Si una de las promesas que tiene para este cierre de año es fortalecer las
contraseñas en sus equipos personales, cambiarlas mensualmente y no repetir la
misma contraseña en al menos doce cambios. En este artículo se le explicará como
hacerlo sin tener que invertir una uva en ello, todo esto gracias al paquete
libpam-cracklib en Debian, el procedimiento mostrado debe aplicarse a otras
distribuciones derivadas de Debian.
Pareciese lógico que algunas de las mejores prácticas para el fortalecimiento de las contraseñas son las siguientes:
- Cambiar las contraseñas periódicamente.
- Establecer una longitud mínima en las contraseñas.
- Establecer buenas reglas para las nuevas contraseñas, es decir, mezcla entre letras mayúsculas, minúsculas, dígitos y caracteres alfanuméricos.
- Mantener un histórico de las contraseñas usadas previamente, de ese modo, alentamos a los usuarios establecer nuevas contraseñas.
- Indicarle a los usuarios que es inaudito que se anoten las contraseñas en un post-it y se dejen pegadas en los monitores o incluso en las gavetas de sus archivadores.
El primer paso es instalar el paquete libpam-cracklib
# apt-get install libpam-cracklib
A partir de la versión 1.0.1-6 de PAM se recomienda manejar la configuración vía
pam-auth-update. Por lo tanto, por favor tome un momento y lea la sección 8
del manual del comando pam-auth-update para aclarar su uso y ventajas.
$ man 8 pam-auth-update
Ahora establezca una configuración similar a la siguiente, vamos primero con la
exigencia en la fortaleza de las contraseñas, para ello edite o cree el fichero
/usr/share/pam-configs/cracklib.
Name: Cracklib password strength checking
Default: yes
Priority: 1024
Conflicts: unix-zany
Password-Type: Primary
Password:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
Password-Initial:
requisite pam_cracklib.so retry=3 minlen=8 difok=3
NOTA: Le recomiendo leer la sección 8 del manual de pam_cracklib para
encontrar un mayor numero de opciones de configuración. Esto es solo un ejemplo.
En versiones previas el modulo pam_cracklib hacia uso del fichero
/etc/security/opasswd para conocer si la propuesta de cambio de contraseña no
había sido utilizada previamente. Dicha funcionalidad ahora corresponde al nuevo
modulo pam_pwhistory
Definamos el funcionamiento de pam_pwhistory a través del fichero
/usr/share/pam-configs/history.
Name: PAM module to remember last passwords
Default: yes
Priority: 1023
Password-Type: Primary
Password:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
Password-Initial:
requisite pam_pwhistory.so use_authtok enforce_for_root remember=12 retry=3
NOTA: Para mayor detalle de las opciones puede revisar la sección 8 del
manual de pam_pwhistory
Seguidamente proceda a actualizar la configuración de PAM vía pam-auth-update.
Una vez cubierta la fortaleza de las contraseñas nuevas y de evitar la reutilización de las ultimas 12, de acuerdo al ejemplo mostrado, resta cubrir la definición de los periodos de cambio de las contraseñas.
Para futuros usuarios debemos ajustar ciertos valores en el fichero
/etc/login.defs
#
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 30
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Las reglas previas no aplicaran para los usuarios existentes, pero para este
tipo de usuarios podremos hacer uso del comando chage de la siguiente manera:
# chage -m 0 -M 30 -W 5 ${user}
Donde el valor de ${user} debe ser reemplazo por el username.
tecnologia
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
tecnologia+libre
Foro: Software Libre vs. Software Privativo en el gobierno electrónico
El día de hoy se realizó en el Palacio Federal Legislativo de la Asamblea Nacional el foro Software Libre vs. Software Privativo en el gobierno electrónico, el cual fué organizado por los diputados de la Comisión Permanente de Ciencia, Tecnología y Medios de Comunicación del parlamento venezolano.
Como representantes de la comunidad de Software Libre venezolana se encontraban el economista Felipe Pérez Martí, ex ministro de Planificación y Desarrollo, y Ernesto Hernández Novich, ingeniero en computación y profesor de la Universidad “Simón Bolívar”.
Este foro es el primero de una serie que se realizarán con el fin de ayudar a aclarar todas aquellas dudas que presenten los diputados para la correcta redacción del proyecto de Ley de Tecnologías de Información. Dicho proyecto de ley ha sido propuesto por los diputados: Angel Rodríguez, Luís Tascón, Oscar Pérez Cristancho y Julio Moreno.
El objeto del proyecto de Ley de Tecnologías de Información es el siguiente:
…establecer las normas, principios, sistemas de información, planes, acciones, lineamientos y estándares, aplicables a las tecnologías de información que utilicen los sujetos a que se refiere el artículo 5 de esta Ley y estipular los mecanismos que impulsarán su extensión, desarrollo, promoción y masificación en todo el ámbito del Estado.
Si usted desea escuchar lo discutido en el foro Software Libre vs. Software Privativo en el gobierno electrónico, puede hacerlo en:
- 7 Ponencias (MP3 16kbps), mirror (XpolinuX), mirror (gusl).
- 7 Ponencias (baja calidad)
- Ponencia de Ernesto Hernández Novich
Todos estos ficheros han sido codificados por Luigino Bracci Roa. La mayoría del evento fué cubierto en vivo por ANTV (es una lástima que utilicen flash, ASP y estén alojados en un servidor con Windows Server 2003).
testing
Ubuntu Dapper Drake Flight 6
Flight 6, es la última versión alpha disponible de Ubuntu Dapper Drake, esta versión ha sido probada razonablemente, pero recuerde que a pesar de ello todavía es una versión alpha, así que no se recomienda su uso en medios en producción. Esta versión puede descargarla desde:
- Europa:
- Reino unido y el resto del mundo:
- Bittorent: Se recomienda su uso si es posible.
- Sitios Espejos: Una lista de sitios espejos puede encontrarse en: Ubuntu Mirror System.
Una lista con los cambios notables en esta sexta versión alpha pueden ser encontrados en Dapper Flight 6.
transmission
Transmission 0.72 en Debian y Ubuntu GNU/Linux AMD64
Bien, en realidad, no he podido esperar a tenerlo trabajando al 100%, se trata de la versión 0.72 de Transmission, el que a mi parecer, es el mejor cliente BitTorrent que jamás haya existido. Según lo describen en la página, cito textualmente:
Transmission has been built from the ground up to be a lightweight, yet powerful BitTorrent client. Its simple, intuitive interface is designed to integrate tightly with whatever computing environment you choose to use. Transmission strikes a balance between providing useful functionality without feature bloat. Furthermore, it is free for anyone to use or modify.
Su instalación es muy fácil, ya que lo único que tenemos que hacer, es bajarnos el .deb (sí, el .deb, imagínense lo fácil que nos va a resultar) de la página de nuestros amígos de GetDeb y luego usar una terminal ó el instalador de paquetes GDebi (aún más fácil) para instalar el paquete.
En el primer de los casos, usando la terminal, lo único que tenemos que hacer en escribir la siguiente línea de comandos:
$ sudo dpkg -i transmission_0.72-0~getdeb1_amd64.deb
`` …esperar a que termine el proceso de instalación y ya podrás ejecutar el Transmission desde Aplicaciones –> Internet –> Transmission.
Para el segundo de los casos, usando el instalador GDebi, tan sólo hay que hacer click encima del .deb con el botón derecho del ratón y seleccionamos la opción Abrir con “Instalador de paquetes GDebi” y luego click en el botón Instalar el paquete, finalmente esperar a que finalice la instalación del paquete y listo!. Una de las cosas que, debo admitir, más me gusta de ésta nueva versión, es que ahora podemos minimizar la aplicación en la bandeja del sistema :) .
Para más información de Transmission, visite su Página Oficial.
trucos
Creando listas de reproducción para XMMS y MPlayer
Normalmente acostumbro a respaldar toda la información que pueda en medios de almacenamiento ópticos, sobretodo audio digital, ya sea en ficheros Ogg Vorbis o en MPEG 1 Layer 3. Desde hace poco más de un año hasta la actualidad me he acostumbrado a mantener una estructura lógica, la cual es más o menos como sigue:
/music/
Pero hace mucho tiempo no era tan organizado en cuanto a la estructura de los respaldos, entonces, la pregunta en cuestión es, ¿cómo lograr detectar la presencia de ficheros de audio digital almacenados de manera persistente en un dispositivo óptico de manera automática?
Al igual que lo expresado en la entrada Eliminando ficheros inútiles de manera
recursiva,
haremos uso del comando find.
Antes de entrar en detalle debo aclarar que voy a realizar una búsqueda recursiva de ficheros en el path correspondiente a mi unidad lectora de CDs. Usted debe ajustar el path por uno apropiado en su caso particular.
Si solo desea buscar ficheros MPEG 1 Layer 3:
find /media/cdrom1/ -name \*.mp3 -fprint playlist
Pero si usted acostumbra a almacenar ficheros Ogg Vorbis en conjunto con ficheros MPEG 1 Layer 3, debería proceder así:
find /media/cdrom1/ \( -name \*.mp3 -or -name \*.ogg \) -fprint playlist
El comando anterior también es aplicable para generar listas de reproducción de video digital, en cuyo caso lo único que debe cambiar es la extensión de los ficheros que desea buscar. El fichero que contendrá la lista de reproducción generada en los casos expuestos previamente será playlist.
Reproduciendo la lista generada
Para hacerlo desde XMMS es realmente sencillo, acá una muestra:
xmms --play playlist --toggle-shuffle=on
Si usted no desea que las pistas en la lista de reproducción se reproduzcan
de manera aleatoria, cambie el argumento on de la opción
--toggle-shuffle por off, quedando como --toggle-shuffle=off.
Si desea hacerlo desde MPlayer es aún más sencillo:
mplayer --playlist playlist -shuffle
De nuevo, si no desea reproducir de manera aleatoria las pistas que se
encuentran en la lista de reproducción, elimine la opción del reproductor
MPlayer -shuffle del comando anterior.
Si usted desea suprimir la cantidad de información que le ofrece MPlayer al
reproducir una pista le recomiendo utilizar alguna de las opciones -quiet o
-really-quiet.
turpial
Presentaciones
Desde hace algunos meses he decidido recopilar y organizar algunas de las presentaciones que he dado hasta ahora en eventos de Software Libre, Universidades y empresas privadas.
El software que regularmente utilizo para realizar mis presentaciones es Beamer, una clase LaTeX que facilita enormente la producción de presentaciones de alta calidad, este software trabaja de la mano con pdflatex, también con dvips.
La lista de presentaciones que he recopilado hasta la fecha son las siguientes:
- Análisis estático del código fuente en Python: Describe el concepto del análisis estático del código, se indica los pasos a seguir para la detección de errores mediante la herramienta Pylint, se exponen sus funcionalidades, reportes y se muestran ejemplos para corregir los errores encontrados por la herramienta.
- Desarrollo colectivo en Turpial: Describe la visión del cliente para Twitter Turpial, sus funcionalidades actuales, el uso de herramientas como Transifex, PyBabel, Distutils, Sphinx, dichas herramientas facilitan y mejoran la calidad del software que se desarrolla.
- Canaima GNU/Linux: Una introducción, se describe la historia, definición del proyecto Canaima, principales características, procesos para colaborar, enlaces de interés, entre otros.
- Novela gráfica creada con el motor Ren’Py: Relata la experiencia del desarrollo de una novela gráfica para niños de 5to. grado de educación, de acuerdo a currículo impartido en las escuelas venezolanas.
- Trac: Herramientas libres para el apoyo en el proceso de desarrollo de software, se discute las características y funcionalidades que ofrece el software. Además del proceso de personalización por medio de complementos o plugins.
- GnuPG, GNU Privacy Guard: Importancia del cifrado de la información, diferencias entre llaves simétricas y asimétricas, criptografía, fiestas de firmado de llaves, beneficios. Instalación y suo práctico de GnuPG.
- Uso de
dbconfig-common: Presentación que es parte de la serie mejores prácticas para el empaquetamiento de aplicaciones en Debian, se describe el uso de la herramienta y su respectiva integración con el asistente debhelper - Conociendo el framework web Django: Introducción, historia, características, primeros pasos, instalación y demostración de desarrollo de una aplicación sencilla bajo este excelente framework basado en el lenguaje de Programación Python
Las fuentes en LaTeX de las presentaciones, así como su licencia de uso y proceso de conversión al formato PDF se describe en el proyecto Presentations que he creado en github.
Agradezco enormemente cualquier comentario que pueda hacer respecto a los temas presentados puesto que en el próximo mes trataré de actualizar el contenido, así como incluir nuevas presentaciones. ¿Desearía poder conocer más sobre un tema en particular?, ¿cuál sería ese tema?.
Nota final: Si encuentra algún error por favor notificarlo vía issues del proyecto Presentations.
ubuntuchannel
Actualizado Planeta #ubuntu-es
El hecho de haber dejado de utilizar ubuntu, como lo he manifestado en entradas anteriores, no implica que deba dejar de lado a los amigos del canal #ubuntu-es en el servidor Freenode, además, tampoco debo dejar de cumplir mis deberes de administrador del Planeta #ubuntu-es, por ello, he realizado los siguientes cambios:
- Se actualiza WordPress a su versión 2.0.2.
- Se actualiza el plugin FeedWordPress, basicamente este plugin es un agregador de contenidos Atom/RSS.
- Ahora el dominio principal del Planeta #ubuntu-es es http://www.ubuntuchannel.org/, aunque se han establecido reglas de redirección en el fichero .htaccess para hacer el cambio lo menos traumático posible.
Aún faltan muchos detalles, en este preciso instante no puedo resolverlos debido a un viaje que debo realizar fuera del estado dentro de una hora, el lunes cuando regrese a casa continuare la labor, mientras tanto, le agradezco que si percibe algún error en el nuevo sitio o tiene alguna sugerencia en particular, por favor deje un comentario en esta entrada.
Para quienes deseen suscribirse al Planeta #ubuntu-es, el URI del feed ha cambiado a http://www.ubuntuchannel.org/feed/. Para aquellas personas que estaban suscritas, este cambio no debería afectarles, puesto que se han establecido reglas de redirección.
Si deseas ser miembro, por favor envia un mensaje a través de la sección de contacto del Planeta #ubuntu-es.
ulanix
ULAnix
Hace ya algún tiempo que la beta #3 de esta distribución LiveCD basada en Debian salió.
Podría decirse que ULAnix es la primera distribución GNU + Linux que nace dentro de una universidad venezolana, Universidad de Los Andes. Aunque muchos afirman que la primera distro venezolana con aval universitario fue Cachapa, no es cierto, Antonio Lopez, el creador de Cachapa, realizó dicho proyecto como una meta personal, posteriormente la Universidad de Carabobo se interesó en Cachapa. Al final, lo importante no es ser el primero, lo importante es que estas distribuciones han sido fruto del trabajo de venezolanos.
ULAnix es una iniciativa del Parque Tecnológico de Mérida.
Básicamente el equipo de trabajo está conformado por los profesores: Gilberto Díaz y Jacinto Dávila, el desarrollo está a cargo del bachiller Jesús Molina.
Si usted desea una copia de esta distribución puede obtenerla desde el repositorio: http://ftp.ula.ve/linux/distribuciones/ulanix/ o desde el mirror que he habilitado en http://ulanix.milmazz.com/.
El equipo de trabajo alrededor de ULAnix agradece que la mayor cantidad de personas se haga con esta distribución, la pruebe e informen los errores que vayan consiguiendo. Aún no existe una página oficial para el proyecto, aunque al parecer se está trabajando en ello, opcionalmente, puede notificar los errores de software en el foro de ULAnux.
Próximamente espero estar probando intensivamente esta distribución y realizar las observaciones que considere pertinentes.
utw
Actualizando WordPress
Tenía cierto tiempo que no actualizaba la infraestructura que mantiene a MilMazz, el día de hoy he actualizado WordPress a su version 2.0.2, este proceso como siempre es realmente sencillo, no hubo problema alguno.
También he aprovechado la ocasión para actualizar el tema K2, creado por Michael Heilemann y Chris J. Davis, de igual manera, he actualizado la mayoría de los plugins.
Respecto al último punto mencionado en el párrafo anterior, algo extraño sucedió al actualizar el plugin Ultimate Tag Warrior, al revisar su funcionamiento me percaté que al intentar ingresar a una etiqueta particular se generaba un error 404, de inmediato supuse que era la estructura de los enlaces permanentes y las reglas de reescritura, para solucionar el problema simplemente actualice la estructura de enlaces permanentes desde las opciones de la interfaz administrativa de WordPress.
Si nota cualquier error le agradezco me lo haga saber a través de la sección de contacto.
velug
Perl y su poderío
Al igual que José, considero que el hilo de discusión Borrar línea X de un archivo es bastante interesante, este hilo fué discutido en la lista de correos técnica l-linux es la la lista de correos para Consultas Técnicas sobre Linux y Software Libre en VELUG del Grupo de Usuarios de Linux de Venezuela (VELUG), el problema planteado por quien inicio el hilo de discusión, José Luis Bazo Villasante, consistía en eliminar un registro completo, en donde se pasara como argumento el primer campo (tal vez el identificador) de dicho registro.
Suponga que el fichero tiene la siguiente estructura:
:(123
... # otros campos
)
:(234
... # otros campos
)
:(456
... # otros campos
)
Se dieron soluciones en lenguajes como Bash y C ¿Con intención de autoflagelación? y ciertas en Perl, éstas últimas son las que llaman mi atención, vamos por partes Diría Jack El Destripador.
José propuso lo siguiente:
#!/usr/bin/perl -n
$deadCount = 7 if ($_ =~ /${ARGV[0]}/);
--$deadCount if ($deadCount);
print unless ($deadCount);El programa debe ejecutarse así:
$ perl script.pl archivo 123
Este programa hace el trabajo, pero al final emitirá un error porque cree que el argumento 123 es otro fichero, y por supuesto, no lo encuenta.
Mi solución fue la siguiente:
perl -ne 'print unless /:\\(123/../\\)/' input.data > output.dataPor supuesto, en este caso solamente estaría eliminando el registro cuyo primer elemento es 123, funciona, pero genera un problema al igual que el hecho por José, se deja una línea de espacio vacía adicional en los registros, cuando el separador de los grupos de datos debe ser una No dos, ni tres, … línea en blanco, tal cual como apunto Ernesto Hernández en una de sus respuestas.
Otro apunte realizado por el profesor Ernesto, fué que las soluciones presentadas hasta el momento de su intervención fué el análisis de fondo que estabamos haciendo, el problema no consistía en procesar cada una de las líneas, el trabajo en realidad consistía en analizar un registro multilínea (o párrafo), en términos más sencillos, cada grupo de datos (registros) está separado por una línea en blanco.
El profesor continuaba su excelente explicación diciendo que el problema se reduce al analizarlo de esta manera en lo siguiente:
…si se cuenta con un lenguaje de programación que está preparado para manejar el concepto de “registro” y puede definir el separador de registro como una línea en blanco, simplemente se trata de ignorar aquellos registros que tengan la expresión regular (X, donde X es la secuencia de dígitos que no nos interesa preservar.
La solución presentada por el profesor Ernesto fue:
perl -000 -i -ne 'print unless /\\(XXX/' archivoEn donde se debe sustituir las XXX por los dígitos cuyo bloque no nos interesa conservar.
De este hilo aprendí cosas nuevas de Perl, en realidad estoy comenzando, muchos pensarán que este código es críptico, por ello considero conveniente aclarar algunas cosas.
Lo críptico de un código no es inherente a un lenguaje particular, eso depende más del cómo se programe.
En este caso particular una sola línea de código nos proporciona mucha información, evidentemente para comprender dicho contenido es necesario leer previamente cierta documentación del lenguaje, pero ¿quien comienza a programar en un lenguaje en particular sin haber leído primero la documentación?, la respuesta parece lógica, ¿cierto?.
La existencia de opciones predefinidas y maneras de ejecutar el interprete de Perl permiten enfocarse únicamente en la resolucion de tareas, cero burocracia.
Un ejemplo de lo mencionado en el párrafo anterior es el siguiente, un bucle lo puedo reducir con la opción de ejecución -n del interprete Perl, simplemente leyendo un poco perlrunman perlrun, perlrun se incluye en la documentación de Perl, en sistemas Debian lo encontramos en el paquete perl-doc, para instalar simplemente hacer ejecutar el comando aptitude install perl-doc como superusuario nos enteramos del asunto, eso quiere decir que podemos reducir a una simple opción de ejecución del interprete de Perl todo esto:
#!/usr/bin/perl
while(<>){
#...
}¿Qué es ese operador que parece un “platillo volador”, según nos conto José Luis Rey, el profesor Ernesto Hernández le llama así de manera informal (null filehandle)?, bueno, lea perlop, en especial la sección I/O Operators.
La opción -i me permite editar (reescribir) in situ el fichero que vamos a procesar, en el caso de no añadir una extensión no se realizara un respaldo del fichero, el fichero original se sobreescribe. Mayor detalle en perlrun.
Lo que si no sabía hasta ahora, es lo explicado por el profesor acerca de los párrafos (registros multilínea) en Unix, la opción -0 tiene un valor especial, el cual es 00, si este valor es suministrado hace que Perl entre en “modo párrafo”, en pocas palabras, se reconoce una línea en blanco como el separador de los registros.
El resto del código es solo manejo de una sencilla expresión regular, se asume que el lector conoce algo del tema, solo indica el registro que queremos ignorar.
Así que podemos concluir lo siguiente, Perl no es críptico, asumiendo que el programador ha leido suficiente documentación acerca del lenguaje en cuestión, evitamos la burocracia y atendemos el problema de raíz en el menor tiempo posible.
La solución que propone Perl con el lema Hay más de una manera de hacerlo, es ofrecerle al programador libertad en su forma de expresarse, ¿acaso todos hablamos el mismo idioma?, ¿acaso debemos seguir las malas prácticas que intenta difundir el maligno Java?, coartar el pensar del programador y obligarlo a hacer las cosas al estilo Java, ¿dónde queda la imaginación? De hecho, se dice que, un programador experto en Java está muy cerca de convertirse en un autómata, ¿paso a ser un lujo?.
A todos los que lo deseen, les invito a participar en la lista de correos técnica (l-linux) del Grupo de Usuarios de Linux de Venezuela (VELUG), les recomiendo leer detenidamente las normas de uso antes de inscribirse en la lista.
venezuela
Más propuestas para la campaña en contra de la gestión del CNTI
David Moreno Garza (a.k.a. Damog) se ha unido a la campaña que apoya a la Asociación de Software Libre de Venezuela (SoLVe), la cual rechaza (al igual que nosotros) el acuerdo entre IBM Venezuela y el Centro Nacional de Tecnologías de Información (CNTI).
Damog nos sorprende con un script escrito en Perl que genera un botón personalizado con cierto mensaje.
Para la puesta en funcionamiento del script necesitaremos en primera instancia instalar la variante gd2 del módulo en Perl que contiene a la librería libgd, ésta última librería nos permite manipular ficheros PNG.
Tanto en Debian como en su hijo Ubuntu el procedimiento es similar al siguiente:
$ sudo aptitude install libgd-gd2-perl
$ wget http://www.damog.net/files/misc/apoyo-solve-0.1.zip
$ unzip apoyo-solve-0.1.zip
$ cd apoyo-solve-0.1
$ perl apoyo-solve.perl <text>
En donde <text> debe ser reemplazado por su nombre o el de su sitio. Seguidamente proceda a subir la imagen.
Si lo desea, puede ver los diferentes banners de la campaña en contra de la gestión actual del CNTI, únase al llamado de la Asociación de Software Libre de Venezuela (SoLVe).
video
Primer documental de Software Libre hecho en Venezuela
Para todos aquellos que aún no han tenido la oportunidad de ver el primer documental sobre Software Libre realizado en Venezuela, Software Libre, Capítulo Venezuela, ahora pueden hacerlo gracias a la colaboración hecha por Luigino Bracci Roa, quien realizó la codificación del fichero.
El documental, cuya duración es de 25 minutos, fué producido por el Ministerio de la Cultura a través de la Fundación Villa Cine, dicha fundación busca estimular, desarrollar y consolidar la industria cinematográfica a nivel nacional, a su vez, favorece el acercamiento del pueblo venezolano a sus valores e idiosincrasia.
Se pueden observar algunas entrevistas muy interesantes, el documental pretende orientar al ciudadano común, aquel que no domina profundamente los temas de la informática y específicamente el tema del Software Libre, entre otras cosas se explican los conceptos e importancia detrás de él.
A continuación una serie de sitios espejos desde los cuales puede descargar el documental, de igual manera a lo dicho por Ricardo Fernandez: por favor no use siempre el mismo mirror, es para compartir anchos de banda y para dar un mejor servicio a todos.
Formato OGG (aprox. 43.5MB)
- https://www.ututo.org/utiles/torrent/sl-capitulo-vzla-001.ogg.torrent
- ftp://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
- http://ftp.gnu.org/gnu+linux-distros/ututo-e/sl-capitulo-vzla-001.ogg
Free TV
Daniel Olivera nos informa que:
Ya esta en UTUTO FreeTv emitiendose luego de cada video que ya estaba.
Pueden verlo en radio.ututo.org:8000/ o en WebConference en el sitio de UTUTO.
Esta las 24 horas funcionando FreeTv.
Formato AVI (aprox. 170MB)
- http://blog.milmazz.com.ve/soft-libre-venezuela.avi
- http://koshrf.fercusoft.com/koshrf/soft-libre-venezuela.avi
- http://www.xpolinux.org/soft-libre-venezuela.avi
- http://two.fsphost.com/softlibre/soft-libre-venezuela.avi
- http://www.conexionsocial.cl/video/soft-libre-venezuela.avi
- http://ieac.faces.ula.ve/files/fpalm/soft-libre-venezuela.avi
- http://heartagram.com.ve/soft-libre-venezuela.avi
Puede encontrar mayor información acerca del tema en los siguientes artículos:
- ¡Descarga el documental sobre Software Libre en Venezuela!
- Video de Software Libre hecho en Venezuela
Actualización: Se añaden nuevos sitios espejos para el formato AVI, además, Daniel Olivera ha facilitado algunos enlaces de gran ancho de banda para el formato OGG. ¡Gracias Daniel!.
vim
Vim al rescate
Al examinar el día de hoy el último fichero de respaldo de la base de datos de este blog, me percate que existe una cantidad inmensa de registros que en realidad no me hacen falta, sobretodo respecto a las estadísticas, es increible que los registros de una simple base de datos llegara a ocupar unos 24MB, dicha información no tiene mayor relevancia para los lectores puesto que dichos datos suelen ser visualizados en la interfaz administrativa del blog, pero al ocupar mayor espacio en la base de datos, pueden retardar las consultas de los usuarios. Por lo tanto, era necesario realizar una limpieza y eliminar unos cuantos plugins que generaban los registros de las estadísticas.
Ahora bien, imagínese abrir un documento de 266.257 líneas, 24.601.803 carácteres desde algun editor de textos gráfico, eso sería un crimen. ¿Qué podemos hacer?, la única respuesta razonable es utilizar Vim.
Vim es un avanzado editor de textos que intenta proporcionar todas las funcionalidades del editor de facto en los sistemas *nix, Vi. De manera adicional, proporciona muchas otras características interesantes. Mientras que Vi funciona solo bajo ambientes *nix, Vim es compatible con sistemas Macintosh, Amiga, OS/2, MS-Windows, VMS, QNX y otros sistemas, en donde por supuesto se encuentran los sistemas *nix.
A continuación detallo más o menos lo que hice:
En primer lugar respalde la base de datos del blog, enseguida procedí a descomprimir el fichero y revisarlo desde Vim.
$ vim wordpress.sql
Comence a buscar todos los CREATE TABLE que me interesaban. Para realizar esto, simplemente desde el modo normal de Vim escribí lo siguiente:
/CREATE TABLE <strong><Enter></strong>
Por supuesto, el
Con todo la información necesaria, lo único que restaba por hacer era copiar la sección que me interesaba en otro fichero, para ello debemos proceder como sigue desde el modo normal de Vim:
:264843,266257 w milmazz.sql
El comando anterior es muy sencillo de interpretar: Copia todo el contenido encontrado desde la línea 264.843 hasta la línea 266.257 y guardalo en el fichero milmazz.sql.
Inmediatamente restaure el contenido de mi base de datos y listo.
Algunos datos interesantes.
Fichero original
- Tamaño: 24MB
- Número total de líneas: 266.257
Fichero resultado
- Tamaño: 1.2MB
- Número total de líneas: 1.415
Tiempo aproximado de trabajo: 4 minutos.
¿Crees que tu editor favorito puede hacer todo esto y más en menos tiempo?. Te invito a que hagas la prueba ;)
That’s All Folks!
vlc
Reproducir de manera automática los CDs o DVDs con XMMS y VLC
Si desea reproducir automáticamente los CDs de audio (o DVDs) al ser insertados con XMMS (o con VLC) simplemente cumpla los siguientes pasos:
En primer lugar diríjase a Sistema -> Preferencias -> Unidades y soportes extraíbles, desde la lengüeta Multimedia proceda de la siguiente manera:
Si desea reproducir automáticamente un CD de sonido al insertarlo:
- Marque la casilla de verificación Reproducir CD de sonido al insertarlo
- En la sección de comando escriba lo siguiente:
xmms -p /media/cdrom0
Si desea reproducir automáticamente un DVD de vídeo al insertarlo
- Marque la casilla de verificación Reproducir DVD de vídeo al insertarlo
- En la sección de comando escriba lo siguiente:
wxvlc dvd:///dev/dvd
Nota: En XMMS puede ser necesario configurar el plugin de entrada de audio que se refiere al Reproductor de CD de audio (libcdaudio.so), puede configurarlo desde las preferencias del programa.